❝凡事你一旦接纳了,就不存在了;你看不惯它,它就一直折磨你
大家好,我是柒八九。一个专注于前端开发技术/Rust及AI应用知识分享的Coder
❝此篇文章所涉及到的技术有
WebAssemblyRustSIMDLLVMbinaryen
因为,行文字数所限,有些概念可能会一带而过亦或者提供对应的学习资料。请大家酌情观看。
前言
❝提前祝大家国庆节快乐哈!🎇🎇
我们最近不是写了3篇Rust赋能前端的文章吗。
-
Rust 赋能前端:PDF 分页/关键词标注/转图片/抽取文本/抽取图片/翻转...:在里面介绍如何在前端环境中( React/Vue)中使用Mupdf,用于执行各种PDF的操作。 -
Rust 赋能前端: 视频抽帧:在里面介绍如何在前端环境中( React/Vue)中对视频资源进行抽帧处理。 -
Rust 赋能前端:图片OCR识别,以后可以抛弃tesseract了:介绍了在前端环境中( React/Vue)如何使用Rust对图片做Ocr处理。
之前和大家剧透过,本来最近的一篇文章是讲利用AI模型进行音视频文件的语音信息抽离。
但是呢,看到有些粉丝在后台私信我。说想让讲讲如何对WebAssebmly进行打包优化。可能看到我们在Rust 赋能前端:图片OCR识别,以后可以抛弃tesseract了中提过一嘴,然后感觉没尽兴。
你都开口了,我358团不能不帮这个忙。所以,今天我们就来聊聊这个话题。
再啰嗦几句
其实,如果大家做过前端项目的打包优化(Webpack/Vite)的话,对这块就不会很陌生。
对于打包优化来讲,可能有很多优化方向。但是,无论如何处理,其实最核心的一点就是减少资源大小。
所以,今天就来从这个角度来讲讲如何为我们的WebAssembly做瘦身处理。
对了,如果大家想了解如何针对Webpack做打包优化,可以翻看我们之前的文章前端工程化之Webpack优化
好了,天不早了,干点正事哇。

我们能所学到的知识点
❝
准备工作 前置知识点 常规编译 优化编译详解 最终方案
1. 准备工作
前端项目
❝由于我们今天的主要任务是做
WebAssembly的优化处理,前端项目不是我们重点
针对于我来说,我直接就用之前的OCR前端项目了。当然,你如果不想翻看之前的文章,你也可以使用f_cli_f[1]来构建的前端Vite+React+TS项目。
然后在src/pages构建一个文件上传的页面,在src目录下构建一个wasm目录来存放在前端项目中要用到的各种wasm。
Rust项目
我们是用之前的OCR的Rust项目。当然,你也可以拿你自己的项目来进行验证。因为,我们此篇文章的内容,都不涉及具体的业务逻辑。
2. 前置知识点
❝之所以将后面可能涉及到的知识点和概念提前写出来,是想让行文更加明了。也是为了照顾不同阶段的同学。如果你对这些概念都熟悉,那么可以直接跳过该节内容。如果你还是
Rust新手,那么这节内容也算是一种知识的巩固。
2.1 Rust Channel
Rust 被发布到三个不同的channel:
-
stable(稳定版):稳定版本每 6 周发布一次 -
beta(测试版):测试版是即将成为下一个稳定版的版本 -
nightly(夜间版):夜间版则是每天晚上构建的最新版本
我们在安装Rust后,它会安装一个名为rustup的工具,这个工具能让我们管理多个不同版本的 Rust。
❝默认情况下,
rustup会安装stable版本到我们本机环境
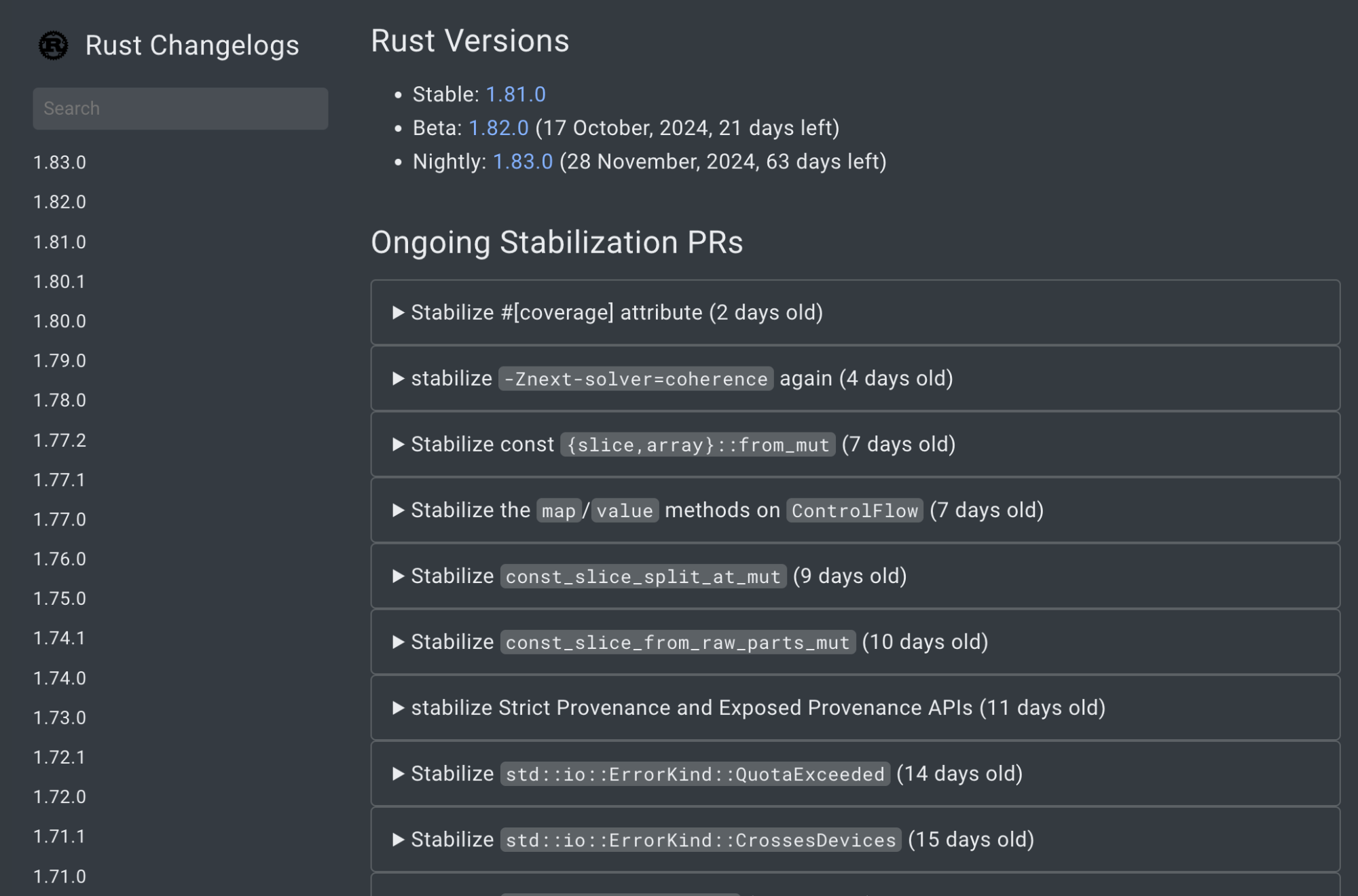
我们可以在rust 版本信息[2]中查看每个版本的各种信息。
2.2 安装nightly版本
❝
Nightly版本,可以帮助我们尝试Rust的最新特性,我们后面在编译的时候,需要用到该版本
我们可以通过下面命令来安装nightly.
rustup toolchain install nightly
系统将下载所需组件,包括 rustc、rust-std、cargo 等,最后安装它们。
然后我们可以通过rustup toolchain list来查看我们本机安装的Rust版本。
下面是我本机的各个Rust信息。
stable-x86_64-apple-darwin (default) (override)
stable-x86_64-unknown-linux-gnu
nightly-x86_64-apple-darwin
1.75.0-x86_64-apple-darwin
细心的同学,可以看到在stable-x86_64-apple-darwin后面有default/override的字样。
2.3 切换工具链
❝
使用 rustup default切换工具链使用 rustup override在特定项目中使用不同的工具链。
我们可以使用 rustup default 命令来切换到指定的工具链。
例如,要切换到 stable-x86_64-apple-darwin:
rustup default stable-x86_64-apple-darwin
或者如果切换到 nightly 版本:
rustup default nightly-x86_64-apple-darwin
我们可以使用以下命令,检查 rustc 当前使用的版本:
rustc -V
然后它就会返回当前使用的版本信息。例如我本机的返回信息为rustc 1.81.0 (eeb90cda1 2024-09-04)
临时使用不同工具链
如果我们只想在某个项目使用不同的工具链,不改变全局的默认设置,可以使用:
rustup override set <toolchain>
例如:
rustup override set nightly-x86_64-apple-darwin
这个命令只会在当前目录下使用指定的工具链,不会影响其他项目或全局的默认设置。
切换为特定版本的 Rust
我们也可以切换到已安装的特定版本,比如 1.75.0:
rustup default 1.75.0-x86_64-apple-darwin
2.4 SIMD
在v8官网中有这么一篇文章 - Fast, parallel applications with WebAssembly SIMD[3]里面就介绍了很多关于SIMD的内容,我们来将与我们相关的内容做一下总结。
❝
SIMD(单指令多数据)指令是一类特殊指令,能够通过同时对多个数据元素执行相同操作来利用数据并行性。这类指令广泛应用于计算密集型应用中,比如音频/视频编解码器、图像处理器等,能够加速性能。大多数现代体系结构都支持某种形式的 SIMD 指令。
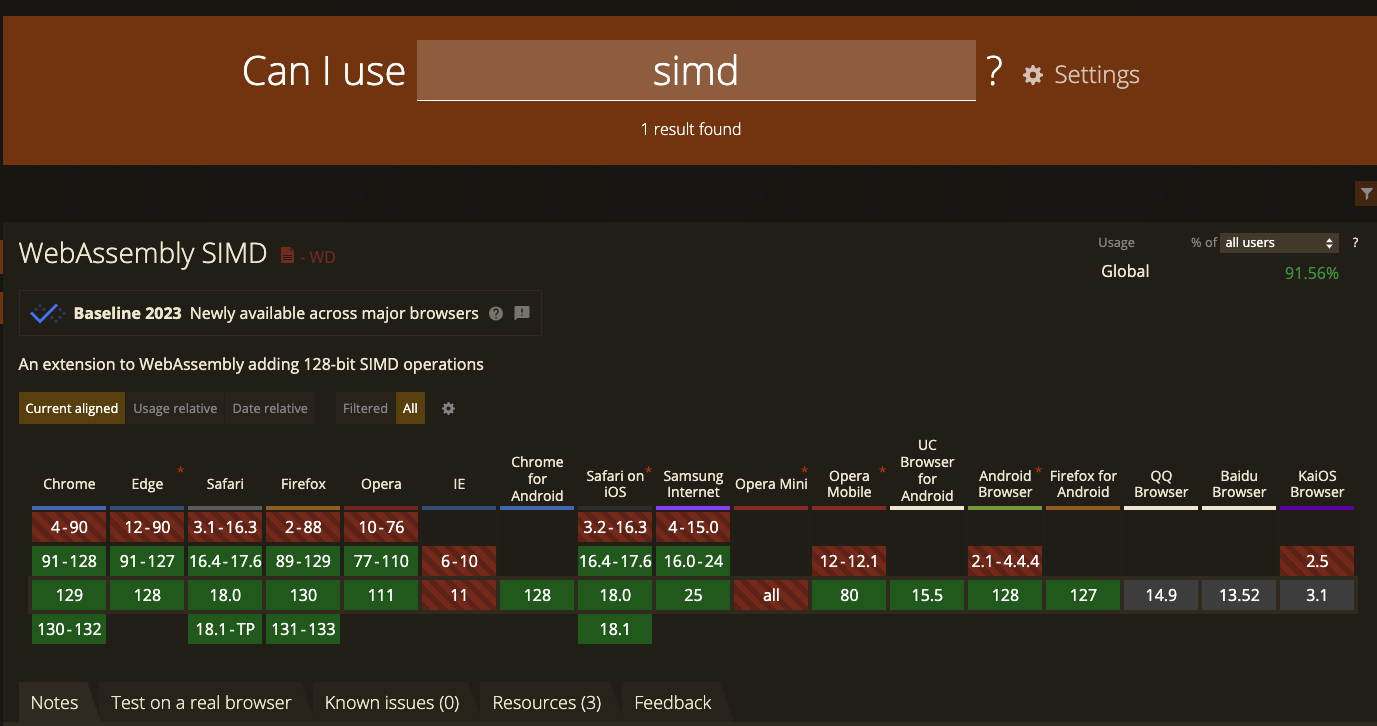
我们可以从caniuse[4]中看到它的兼容性情况。
将Rust编译为WebAssembly SIMD
在Fast, parallel applications with WebAssembly SIMD文章中,它介绍了如何将c/c++的代码编译为SIMD以供前端环境使用。当然,也有将Rust编译为SIMD的方式。其实我们比较关心这部分。
❝此举有助于将
Rust代码高效地编译为WebAssembly并利用底层硬件的并行性
当我们将 Rust 代码编译为目标 WebAssembly SIMD 时,需要启用simd128 LLVM 特性[5]。
我们可以直接控制 rustc 的标志或通过环境变量 RUSTFLAGS,可以传递 -C target-feature=+simd128:
rustc … -C target-feature=+simd128 -o out.wasm
或者使用 Cargo:
RUSTFLAGS="-C target-feature=+simd128" cargo build
当启用了 simd128 特性时,LLVM 的自动矢量化器会默认在优化代码时启用。
2.5 binaryen
❝Binaryen[6] 是一个为
WebAssembly设计的编译器和工具链基础库,由C++编写。它旨在让编译为WebAssembly变得简单、快速且高效
Binaryen为我们提供了很多优化工具,而今天我们选择其中的一个也就是-wasm-opt。
安装wasm-opt
wasm-opt 是 Binaryen 工具的一部分,可以通过多种方式安装,下面列出了几种常用的安装方法:
-
使用 npm安装:安装完成后,wasm-opt会成为全局命令,直接在终端中使用npm install -g binaryen -
通过 Homebrew安装(适用于macOS和Linux)brew install binaryen -
通过预编译二进制文件安装:前往 Binaryen的GitHub releases 页面 [7],下载与你的操作系统相匹配的压缩包。
验证安装
安装完成后,我们可以通过以下命令检查 wasm-opt 是否安装成功:
wasm-opt --version
// wasm-opt version 119 (version_119)
如果返回版本号,说明安装成功。
3. 常规编译
我们之前在Rust 编译为 WebAssembly 在前端项目中使用就介绍过,如何将一个Rust项目编译为WebAssembly。
当时我们使用常规的编译方式。
cargo build --release --target wasm32-unknown-unknown --package xxx
wasm-bindgen target/wasm32-unknown-unknown/release/xxx.wasm --out-dir yyy --target web
上面我们是通过cargo和wasm-bindgen编译Rust文件为WebAssembly,然后在yyy的文件下生成相关的文件资源。
-
xxx.wasm -
xxx.js -
xxx.d.ts
然后,我们就可以将yyy的相关文件引入到前端项目中,通过配置Webpack/Vite的Wasm相关内容,就可以通过import引入对应的实例或者方法了。
release的默认profiles配置
在Cargo Book[8]中对release的默认profiles配置有相关介绍。
当我们在使用cargo build --release对项目进行打包处理时候,它内部默认是根据下面的配置优化相关项目的。
[profile.release]
opt-level = 3
debug = false
split-debuginfo = '...' # Platform-specific.
strip = "none"
debug-assertions = false
overflow-checks = false
lto = false
panic = 'unwind'
incremental = false
codegen-units = 16
rpath = false
针对上面各个属性的解释,大家可以翻看release相关解释[9]去了解更多,这里就不在赘述了。
效果展示
❝下面的所有的效果展示,和自己的本机环境息息相关,也就是如果你在编译/执行项目时,电脑资源被占用的很多或者电脑过热。这个时间也是有波动的。 最终的时间对比,按自己的情况而定。
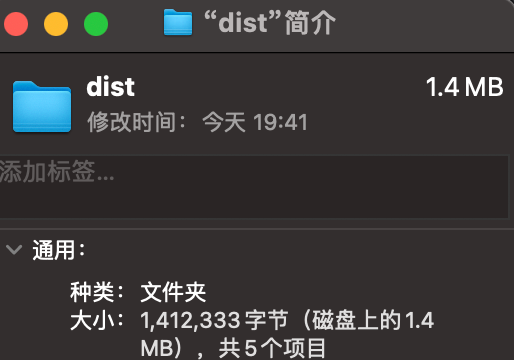
资源大小
首先,我们先看编译后的文件大小
编译时间

运行时间
我们将上面编译好的文件引入到之前我们的OCR的前端项目。然后,运行相关代码。
 在执行相关的操作后,整体的运行时间为
在执行相关的操作后,整体的运行时间为4秒
4. 优化编译详解
❝写在最前面,下面的一些配置,有最大力度的优化方案,但是可能根据项目性质的不同,你使用了,却没达到想要的效果。这就是一个取舍问题,也是一个实践出真知的问题。要想将自己的项目配置成最好,下面的配置方案可能适用你,也可能不使用。如果不适用,你可以根据下面的配置方向,找出符合你的最佳方案。
我们来针对上面的打包做一次优化处理。我们先把相关的优化方案列举出来,然后最后给一个最终的解决方案。
4.1 删除符号或调试信息
这部分,我们可以通过设置release-strip的信息来优化编译结果。
[profile.release]
strip = true
在 Rust 项目中,strip它决定了 rustc是否从生成的二进制文件中删除符号或调试信息。这个选项主要用于减小生成文件的大小,特别是在发布(release)模式下打包时。
strip 的选项
-
"none": 不剥离任何信息(默认设置) -
"debuginfo": 剥离调试信息,但保留符号。 -
"symbols": 剥离符号信息,保留调试信息。
除了字符串值外,还可以使用布尔值进行设置:
-
strip = true 等同于 strip = "symbols"。 -
strip = false 等同于 strip = "none",完全禁用剥离
场景说明
在 Linux 和 macOS 系统上,编译生成的 .elf 文件中默认会包含符号信息。这些符号信息通常不需要在执行二进制文件时使用,因此可以选择剥离,以减小文件大小。尤其是在发布模式下,剥离符号信息是常见的做法,用来生成更小、更优化的可执行文件。
4.2 设置opt-level
Rust 的 opt-level 设置控制 rustc 的 -C opt-level 标志,它用于决定编译时的优化级别。
❝优化级别越高,生成的代码在运行时可能越快,但同时也会增加编译时间,并且更高的优化级别可能会对代码进行重排和改动,这可能会使调试更加困难。
可用的优化级别
-
0: 无优化,适合快速编译,常用于开发阶段。 -
1: 基础优化,平衡编译速度和性能,适合某些性能需求不高的场景。 -
2: 中度优化,进行一些优化,提供较好的性能,通常用于测试环境。 -
3: 完全优化,进行所有可能的优化,适合需要最高性能的发布代码,但编译时间会增加。 -
"s": 优化二进制文件大小,通过减少代码体积来优化。 -
"z": 进一步优化二进制大小,并关闭循环向量化,使得编译产物更小。
这里我们选择大力出奇迹直接使用最高级别的优化。
[profile.release]
opt-level = "s"
❝其实,每个项目的优化力度是不同的,这个需要根据自己项目去决定
4.3 Link Time Optimization (LTO)
Link Time Optimization (LTO) 是一种优化技术,它将编译单元在链接阶段进行优化。通常情况下,Cargo 会将每个编译单元独立编译和优化,而 LTO 允许在整个程序的链接阶段对其进行优化。这可以去除不需要的代码(例如死代码),并且在许多情况下会减小二进制文件的大小。这个和我们前端的TreeSharke是一个道理。
lto 设置的选项
-
false: 执行“局部精简 LTO”,即在本地 crate的代码生成单元上执行精简 LTO。如果codegen-units是 1 或者opt-level为 0,则不会进行LTO。 -
true 或 "fat": 执行“胖 LTO”,尝试对整个依赖图中的所有 crate进行跨crate优化。 -
"thin": 执行“精简 LTO”,类似于“胖 LTO”,但消耗的时间大大减少,同时仍能获得类似的性能提升。 -
"off": 禁用 LTO。
这里我们也是下猛药。直接使用最大力度的优化方案。
LTO 的配置方法
[profile.release]
lto = true
4.4 设置并行代码生成单元
在 Rust 中,代码生成单元(codegen-units) 是编译器将 crate 拆分为多个部分并行处理的机制。通过增加代码生成单元,编译器可以并行处理多个部分,从而加快编译速度。然而,更多的代码生成单元会限制某些全局优化的能力,从而可能导致较大的二进制文件或运行速度稍慢的代码。
❝减少代码生成单元数,尤其是在发布模式下,将有助于
Rust编译器执行更深入的全局优化,生成更高效和更小的二进制文件。在性能需求高或者文件大小敏感的场景下,将codegen-units设置为 1 是一种常见的优化手段。
并行代码生成单元的设置
Rust 默认在发布构建中将 crate 分成 16 个并行代码生成单元。这种设置有助于加快编译速度,特别是在多核 CPU 上,因为多个单元可以同时生成代码。然而,这会限制编译器进行某些全局优化,例如跨模块优化,影响代码运行时的性能或二进制文件的大小。
权衡
-
更多并行单元:编译速度更快,但可能会损失全局优化的机会。 -
更少并行单元(如 1):编译速度较慢,但生成的代码经过更多全局优化,可能运行速度更快,并且二进制文件更小。
我们的选择
我们选择将codegen-units设置为1,牺牲编译速度,减少文件大小。
[profile.release]
codegen-units = 1
4.5 修改panic!()行为
当 Rust 代码执行 panic!() 时,默认的行为是 展开栈(unwinding the stack),从而生成有用的回溯信息(backtrace),以帮助我们定位问题。然而,栈展开过程需要额外的代码,这增加了二进制文件的大小。
❝为了减少二进制文件的大小,
Rust提供了另一种策略,即在程序出现panic!()时,立即 终止进程(abort),而不是展开栈。通过启用这种行为,可以完全去掉栈展开代码,显著减少程序的二进制大小。
启用 Abort on Panic
在 Cargo.toml 中通过在发布配置下设置 panic = "abort" 来启用此功能:
[profile.release]
panic = "abort"
❝使用 "abort" 策略可以有效减少二进制文件的大小,特别适合生产环境和资源受限的场景,但会牺牲部分调试能力和安全性,所以这就要求我们在前端环境做一些容错机制。
4.6 移除位置信息
在 Rust 中,默认情况下,panic!() 和 #[track_caller] 特性会生成文件、行号和列号的位置信息,用于在代码运行出错时提供更有用的回溯信息(traceback)。这些信息对调试非常有帮助,但也会增加二进制文件的大小。
为了进一步减小生成的二进制文件的大小,Rust 提供了一个实验性的功能,可以移除这些位置信息。这通过使用 rustc 的不稳定选项 -Zlocation-detail 来实现。
有效的 location-detail 选项:
-
none:移除所有文件、行号和列号信息。适合在不需要回溯信息的环境中使用。 -
file:仅保留文件信息。 -
file,line:保留文件和行号信息。 -
file,line,column(默认值):保留完整的文件、行号和列号信息,用于调试。
移除位置信息
通过设置 RUSTFLAGS 环境变量并将其值设为 -Zlocation-detail=none,我们可以在构建二进制时移除这些位置信息,从而减少文件大小。这种优化特别适用于生产环境,或者对二进制文件大小有较高要求的项目。
示例命令如下:
$ RUSTFLAGS="-Zlocation-detail=none" cargo +nightly build --release
❝从上面可以看到,有一段
cargo +nightly。这说明啥,这需要我们切换到nightly版本。
4.7 移除 fmt::Debug
在 Rust 中,#[derive(Debug)] 和 {:?} 格式化符号用于调试输出,帮助我们打印结构体和枚举的内部信息。然而,调试功能会在生成的二进制文件中包含大量类型信息和格式化函数,这可能会增加文件大小。
fmt-debug 选项说明:
-
** full**(默认):#[derive(Debug)]递归打印类型及其字段的详细信息。 -
** shallow**:仅打印类型名称或枚举的变体名称,不打印详细的类型字段信息。此行为不稳定,未来可能会有变化。 -
** none**:完全不打印任何信息,{:?}格式化符号也不起作用。此选项可以显著减少二进制文件大小,并移除没有被符号剥离移除的类型名称,但可能导致panic!和assert!消息不完整。
移除 fmt::Debug:
Rust 提供了一个实验性选项 -Zfmt-debug,允许将 #[derive(Debug)] 和 {:?} 格式化操作变成空操作(no-op),即不输出任何调试信息。通过这种方式,派生的 Debug 实现和相关的字符串将被移除,从而减小二进制文件的大小。
可以使用如下命令启用该功能:
$ RUSTFLAGS="-Zfmt-debug=none" cargo +nightly build --release
和之前的location-detail一样,开启该项目功能,我们也需要使用Rust的nightly版本。
4.8 进一步优化 panic
panic_immediate_abort,旨在彻底移除 panic!() 相关的字符串格式化逻辑。这是 panic = "abort" 选项的进一步优化,即便已指定了 panic = "abort",Rust 仍然会默认将一些与 panic!() 相关的字符串和格式化代码包含在最终的二进制文件中。这会导致二进制文件中存在不必要的占用空间,尤其是在极致优化二进制大小的场景下。
如何使用
配置方式如下:
$ cargo +nightly build \
-Z build-std=std,panic_abort \
-Z build-std-features=panic_immediate_abort
-
**使用
build-std重新构建libstd**:按照build-std的流程,重新编译标准库,同时启用panic_abort行为。 -
进一步缩小二进制大小:启用
panic_immediate_abort特性后,所有与panic!()相关的字符串信息和格式化逻辑都将被移除。
4.9 开启simd128
之前我们就说过,我们可以对Rust开启simd128。
RUSTFLAGS="-C target-feature=+simd128" cargo build
这里就不在过多解释了。
4.10 优化wasm-bindgen
之前的优化都是针对Rust部分,下面我们来看看,针对wasm-bindgen的优化角度。
之前我们不是,使用wasm-bindgen为 Rust 编写的 WebAssembly 模块生成 JavaScript 绑定。它可以帮助 Rust 和 JavaScript 之间进行高效的数据交互。
wasm-bindgen target/wasm32-unknown-unknown/release/audioAndVideo.wasm --out-dir js/dist/ --target web
我们还可以在后面添加一下配置,来优化生成的代码。
--reference-types
-
此选项启用了 WebAssembly的引用类型,这允许WebAssembly代码可以直接引用JavaScript对象(如 DOM 元素),无需对这些对象进行包装或转换,从而提高了内存管理和交互的效率。 -
引用类型扩展了 WebAssembly中的基本值类型(如i32,i64,f32,f64),引入了可以引用JavaScript对象(如函数、外部引用)的能力。
❝
--reference-types通过允许WebAssembly直接引用JavaScript对象,提高了效率,减少了不必要的转换。
--weak-refs
-
此选项启用了 WebAssembly中的弱引用。弱引用允许我们引用对象而不会阻止它们被垃圾回收。在JavaScript中,这一特性被用于防止内存泄漏,可以持有对象的弱引用,当没有强引用时,垃圾回收器可以回收这些对象。 -
对于 Rust和WebAssembly,弱引用有助于在跨JS和WebAssembly边界的对象跟踪中进行更有效的内存管理,避免不必要的对象占用内存。
❝
--weak-refs通过启用弱引用,改善了内存管理,防止内存泄漏,确保不必要的对象能被及时回收。
4.11 使用wasm-opt
由于,我们在前面已经下载了wasm-opt了。所以,这里我们就直接上代码了。
我们在Rust项目中构建一个tools/optimize-wasm.sh文件。
内容如下:
#!/bin/sh
set -eu
BIN_PATH="${1:-}"
WASMOPT_BIN=$(which wasm-opt || true)
if [ -z "$BIN_PATH" ]; then
echo "Usage: $(basename "$0") <WASM binary>"
exit 1
fi
if [ -z "$WASMOPT_BIN" ]; then
echo '由于未找到 `wasm-opt` 二进制文件,因此跳过编译后优化。'
exit
fi
if [ -n "${SKIP_WASM_OPT:-}" ]; then
echo "由于设置了 SKIP_WASM_OPT,所以跳过了编译后优化"
exit
fi
wasm-opt --enable-simd --enable-reference-types -O2 "$BIN_PATH" -o "$BIN_PATH".optimized
mv "$BIN_PATH.optimized" "$BIN_PATH"
上面代码,最关键的就是
wasm-opt --enable-simd --enable-reference-types -O2 "$BIN_PATH" -o "$BIN_PATH".optimized
mv "$BIN_PATH.optimized" "$BIN_PATH"
-
使用以下选项运行
wasm-opt对提供的WASM二进制文件进行优化:-
--enable-simd: 启用SIMD支持,以便更快地进行并行数据处理。 -
--enable-reference-types: 启用WASM模块中的引用类型。 -
-O2: 应用中等级别的优化 (O2),在性能和二进制大小之间进行平衡。 -
优化结果写入临时文件 "$BIN_PATH.optimized"。
-
-
最后,通过移动 (
mv) 优化后的文件替换原始文件。
5. 最终方案
配置Cargo.toml
[profile.release]
strip = true
opt-level = 3
lto = true
codegen-units = 1
panic = "abort"
构建shell 文件
❝注意下文中的
xxx需要替换成你项目的名称
build.sh
我们在项目根目录构建一个build.sh文件,内容如下
#!/bin/bash
# 执行 optimize-rust.sh
echo "执行 optimize-rust.sh..."
./tools/optimize-rust.sh
# 检查是否成功执行
if [ $? -ne 0 ]; then
echo "optimize-rust.sh 构建失败."
exit 1
fi
# 执行 optimize-wasm.sh
echo "执行 optimize-wasm.sh..."
./tools/optimize-wasm.sh js/dist/xxx_bg.wasm
# 检查是否成功执行
if [ $? -ne 0 ]; then
echo "optimize-wasm.sh 构建失败."
exit 1
fi
echo "Rust 已构建成功,到指定目录查看相关信息."
我们构建一个tools文件,然后新建两个文件
-
optimize-rust.sh -
optimize-wasm.sh
optimize-rust.sh
#!/bin/bash
# 获取项目名称
PACKAGE_NAME="xxx"
# 编译 Rust 代码
RUSTFLAGS="-Zlocation-detail=none -Zfmt-debug=none -C target-feature=+simd128" cargo +nightly build \
-Z build-std=std,panic_abort \
-Z build-std-features=panic_immediate_abort \
--release --target wasm32-unknown-unknown --package "$PACKAGE_NAME"
# 生成 wasm 绑定
wasm-bindgen target/wasm32-unknown-unknown/release/"$PACKAGE_NAME".wasm --out-dir js/dist/ --target web
optimize-wasm.sh
#!/bin/sh
set -eu
BIN_PATH="${1:-}"
WASMOPT_BIN=$(which wasm-opt || true)
if [ -z "$BIN_PATH" ]; then
echo "Usage: $(basename "$0") <WASM binary>"
exit 1
fi
if [ -z "$WASMOPT_BIN" ]; then
echo '由于未找到 `wasm-opt` 二进制文件,因此跳过编译后优化。'
exit
fi
if [ -n "${SKIP_WASM_OPT:-}" ]; then
echo "由于设置了 SKIP_WASM_OPT,所以跳过了编译后优化"
exit
fi
wasm-opt --enable-simd --enable-reference-types -O2 "$BIN_PATH" -o "$BIN_PATH".optimized
mv "$BIN_PATH.optimized" "$BIN_PATH"
然后,我们就可以在Rust项目根目录执行./build.sh来执行编译任务了。
运行结果
文件大小
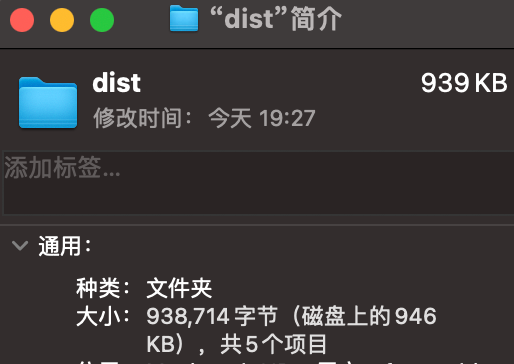
可以看到,我们将之前1.4MB的资源缩小到了900KB。
如果我们还想减少二进制文件的大小,我们还可以继续更改上面的配置信息。如果单纯的追求资源大小的话,我们可以将其缩小到300kb,但是,其运行时间会比没瘦身之前还长
❝鱼和熊掌不能兼得,我们只能根据实际情况而定。也就是实践出真知
运行时间

可以看到,虽然文件大小变小了,但是我们运行性能却没有打折扣。那就充分说明,我们此次的瘦身是成功的。
后记
分享是一种态度。
全文完,既然看到这里了,如果觉得不错,随手点个赞和“在看”吧。

f_cli_f: https://www.npmjs.com/package/f_cli_f
[2]rust 版本信息: https://releases.rs/
[3]Fast, parallel applications with WebAssembly SIMD: https://v8.dev/features/simd
[4]caniuse: https://caniuse.com/?search=simd
[5]LLVM 特性: https://llvm.org/
[6]Binaryen: https://github.com/WebAssembly/binaryen
[7]Binaryen的GitHub releases 页面: https://github.com/WebAssembly/binaryen/releases
[8]Cargo Book: https://doc.rust-lang.org/cargo
[9]release相关解释: https://doc.rust-lang.org/cargo/reference/profiles.html
本文由 mdnice 多平台发布