目录
方案一:转换链接为download模式
方案二:获取源链接后下载
附录:HumanVid链接
方案一:转换链接为download模式
将下载链接的后缀加入 /download 然后用下面的脚本下载:
import argparse
import json
import os
import time
import requests
import tqdm
from pexels_api import API
PEXELS_API_KEY = os.environ['PEXELS_KEY']
MAX_IMAGES_PER_QUERY = 100
RESULTS_PER_PAGE = 10
PAGE_LIMIT = MAX_IMAGES_PER_QUERY / RESULTS_PER_PAGE
def get_sleep(t):
def sleep():
time.sleep(t)
return sleep
def main(args):
sleep = get_sleep(args.sleep)
api = API(PEXELS_API_KEY)
query = args.query
page = 1
counter = 0
photos_dict = {}
# Step 1: Getting urls and meta information
while page <= PAGE_LIMIT:
api.search(query, page=page, results_per_page=RESULTS_PER_PAGE)
photos = api.get_entries()
for photo in tqdm.tqdm(photos):
photos_dict[photo.id] = vars(photo)['_Photo__photo']
counter += 1
if not api.has_next_page:
break
page += 1
sleep()
print(f"Finishing at page: {page}")
print(f"Images were processed: {counter}")
# Step 2: Downloading
if photos_dict:
os.makedirs(args.path, exist_ok=True)
# Saving dict
with open(os.path.join(args.path, f'{query}.json'), 'w') as fout:
json.dump(photos_dict, fout)
for val in tqdm.tqdm(photos_dict.values()):
url = val['src'][args.resolution]
fname = os.path.basename(val['src']['original'])
image_path = os.path.join(args.path, fname)
if not os.path.isfile(image_path): # ignore if already downloaded
response = requests.get(url, stream=True)
with open(image_path, 'wb') as outfile:
outfile.write(response.content)
else:
print(f"File exists: {image_path}")
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--query', type=str, required=True)
parser.add_argument('--path', type=str, default='./results_pexels')
parser.add_argument('--resolution', choices=['original', 'large2x', 'large',
'medium', 'small', 'portrait',
'landscape', 'tiny'], default='original')
parser.add_argument('--sleep', type=float, default=0.1)
args = parser.parse_args()
main(args)方案二:获取源链接后下载
例如这个链接:
https://www.pexels.com/video/5901660/浏览器打开:

然后单击右键,获取视频链接地址:
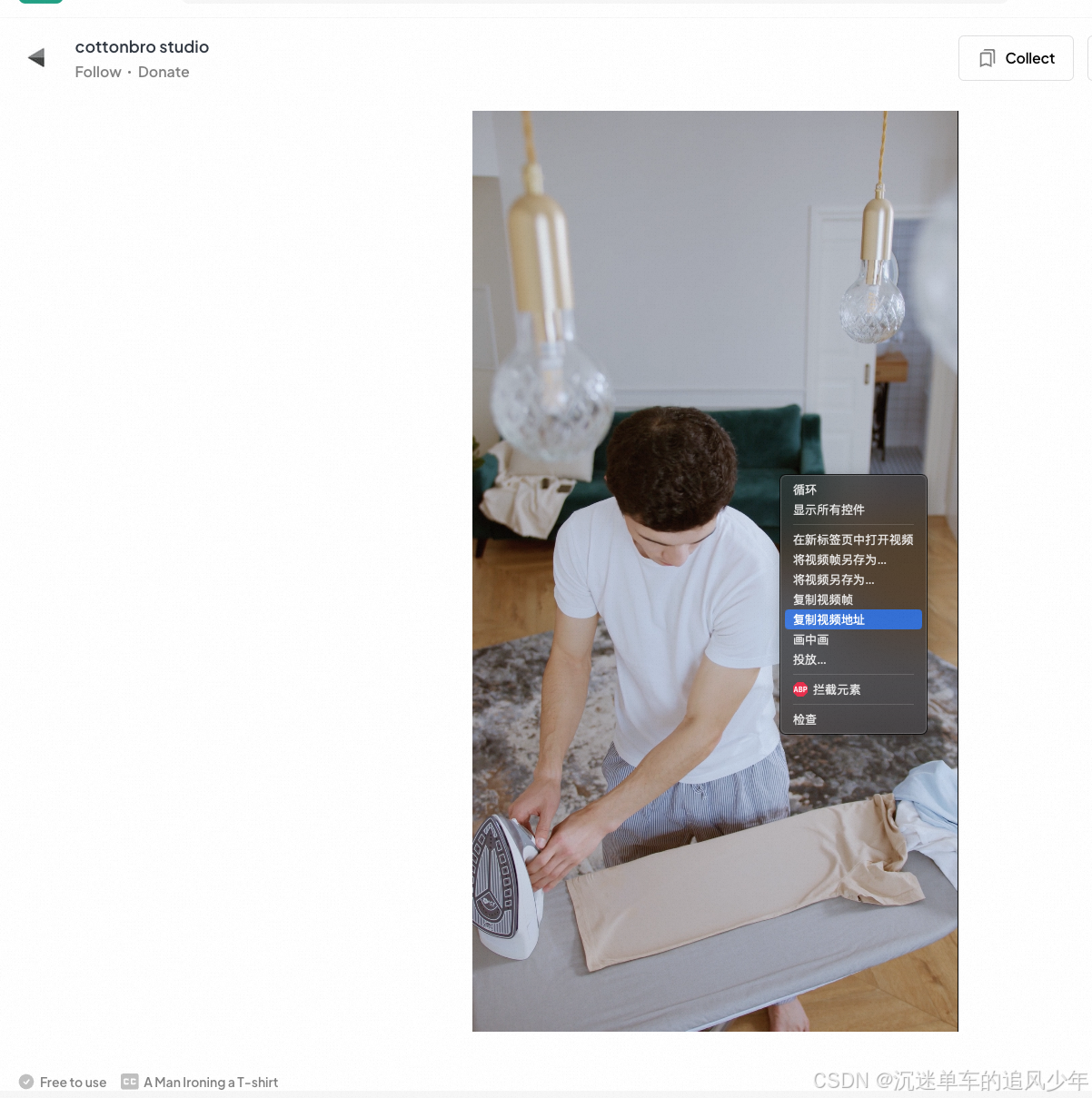
这个链接地址就是原视频的链接地址了,因此可以直接wget下载,也可以用response下载。
那么用脚本如何批量下载呢?以下是源代码:
import os
import requests
from tqdm import tqdm
folder_path = "./videos/vertical1"
os.makedirs(folder_path, exist_ok=True)
url_path = "./pexels-vertical-urls.txt"
headers = {"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
def get_video(video_id, url):
response = requests.get(url , stream=True, headers=headers)
if response.status_code == 200:
with open(save_path, 'wb') as outfile:
outfile.write(response.content)
return True
else:
return False
if __name__ == "__main__":
error_cnt = 0
error_list = []
with open(url_path, 'r', encoding='utf-8') as file:
for line in tqdm(file):
try:
origin_url = line.strip()
video_id = origin_url.split('/')[-2]
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-hd_1080_1920_30fps.mp4"
save_path = os.path.join(folder_path, str(video_id)+".mp4")
if os.path.exists(save_path):
# print(f"{save_path} exists!")
continue
if not get_video(video_id, url):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-hd_1080_1920_25fps.mp4"
if not get_video(video_id, url):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-uhd_1440_2732_25fps.mp4"
if not get_video(video_id, url):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-uhd_1440_2560_24fps.mp4"
if not get_video(video_id, url):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-hd_1066_1920_25fps.mp4"
if not get_video(video_id, url):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-hd_720_1280_24fps.mp4"
if not get_video(video_id, url):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-hd_720_1280_20fps.mp4"
if not get_video(video_id, url):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-hd_1080_1902_24fps.mp4"
if not get_video(video_id, url):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-uhd_1440_2732_24fps.mp4"
if not get_video(video_id, url):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-hd_720_1280_25fps.mp4"
if not get_video(video_id, url):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-uhd_1440_2496_30fps.mp4"
if not get_video(video_id, url):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-uhd_1440_2732_30fps.mp4"
if not get_video(video_id, url):
url = f"https://videos.pexels.com/video-files/{video_id}/uhd_25fps.mp4"
if not get_video(video_id, url):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-hd_1080_1830_25fps.mp4"
if not get_video(video_id, url):
print(f"The url is {url} response error! the response. The video id is: {video_id}")
error_cnt += 1
error_list.append(video_id)
except Exception as e:
print(e)
error_cnt += 1
error_list.append(video_id)
continue
print(f"error_cnt: {error_cnt}")
print(error_list)import os
import requests
from tqdm import tqdm
folder_path = "./videos/horizontal1"
os.makedirs(folder_path, exist_ok=True)
url_path = "./pexels-horizontal-urls.txt"
headers = {"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
def get_video(video_id, url, save_path):
response = requests.get(url , stream=True, headers=headers)
if response.status_code == 200:
with open(save_path, 'wb') as outfile:
outfile.write(response.content)
return True
else:
return False
if __name__ == "__main__":
error_cnt = 0
error_list = []
with open(url_path, 'r', encoding='utf-8') as file:
for line in tqdm(file):
try:
origin_url = line.strip()
video_id = origin_url.split('/')[-2]
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-uhd_2732_1440_25fps.mp4"
save_path = os.path.join(folder_path, str(video_id)+".mp4")
if os.path.exists(save_path):
# print(f"{save_path} exists!")
continue
# https://videos.pexels.com/video-files/5547220/5547220-hd_1280_720_25fps.
# https://videos.pexels.com/video-files/4156500/4156500-hd_1608_1080_30fps.mp4
# https://videos.pexels.com/video-files/8142750/uhd_25fps.mp4
# https://videos.pexels.com/video-files/4536510/4536510-hd_1280_720_50fps.mp4
if not get_video(video_id, url, save_path):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-uhd_2732_1440_30fps.mp4"
if not get_video(video_id, url, save_path):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-uhd_2560_1440_24fps.mp4"
if not get_video(video_id, url, save_path):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-uhd_2560_1440_25fps.mp4"
if not get_video(video_id, url, save_path):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-uhd_2560_1440_30fps.mp4"
if not get_video(video_id, url, save_path):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-hd_1920_1080_25fps.mp4"
if not get_video(video_id, url, save_path):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-uhd_2732_1440_24fps.mp4"
if not get_video(video_id, url, save_path):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-hd_1920_1080_24fps.mp4"
if not get_video(video_id, url, save_path):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-hd_1920_1080_30fps.mp4"
if not get_video(video_id, url, save_path):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-uhd_2560_1080_25fps.mp4"
if not get_video(video_id, url, save_path):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-uhd_2732_1318_30fps.mp4"
if not get_video(video_id, url, save_path):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-uhd_2732_1122_25fps.mp4"
if not get_video(video_id, url, save_path):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-2732_1026_25fps.mp4"
if not get_video(video_id, url, save_path):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-hd_1280_720_25fps.mp4"
if not get_video(video_id, url, save_path):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-hd_1608_1080_30fps.mp4"
if not get_video(video_id, url, save_path):
url = f"https://videos.pexels.com/video-files/{video_id}/uhd_25fps.mp4"
if not get_video(video_id, url, save_path):
url = f"https://videos.pexels.com/video-files/{video_id}/{video_id}-hd_1280_720_50fps.mp4"
if not get_video(video_id, url, save_path):
print(f"The url is {url} response error! The video id is: {video_id}")
error_cnt += 1
error_list.append(video_id)
except Exception as e:
print(e)
error_cnt += 1
error_list.append(video_id)
print(f"error_cnt: {error_cnt}")
print(error_list)附录:HumanVid链接
pexels-vertical-urls.txt
https://www.pexels.com/video/7080900/download
https://www.pexels.com/video/6952520/download
https://www.pexels.com/video/6349070/download
https://www.pexels.com/video/7331390/download
https://www.pexels.com/video/7570280/download
https://www.pexels.com/video/6860990/download
https://www.pexels.com/video/6944620/download
https://www.pexels.com/video/6764050/download
https://www.pexels.com/video/8873210/download
https://www.pexels.com/video/6389830/download
https://www.pexels.com/video/6565400/download
https://www.pexels.com/video/6930970/download
https://www.pexels.com/video/8469970/download
https://www.pexels.com/video/7326810/download
https://www.pexels.com/video/4325510/download
https://www.pexels.com/video/7169950/download
https://www.pexels.com/video/8926860/download
https://www.pexels.com/video/5995130/download
https://www.pexels.com/video/8217050/download
https://www.pexels.com/video/8224270/download
https://www.pexels.com/video/8371250/download
https://www.pexels.com/video/6455330/download
https://www.pexels.com/video/9947050/download
https://www.pexels.com/video/9047370/download
https://www.pexels.com/video/6688050/download
https://www.pexels.com/video/4838220/download
https://www.pexels.com/video/7239800/download
https://www.pexels.com/video/5999210/download
https://www.pexels.com/video/9187960/download
https://www.pexels.com/video/6487450/download
https://www.pexels.com/video/7140160/download
https://www.pexels.com/video/5999650/download
https://www.pexels.com/video/7077040/download
https://www.pexels.com/video/3894700/download
https://www.pexels.com/video/6082570/download
https://www.pexels.com/video/7579880/download
https://www.pexels.com/video/8401740/download
https://www.pexels.com/video/8217240/download
https://www.pexels.com/video/8944110/download
https://www.pexels.com/video/5683800/download
https://www.pexels.com/video/7551190/download
https://www.pexels.com/video/6732430/download
https://www.pexels.com/video/8027280/download
https://www.pexels.com/video/6347120/download
https://www.pexels.com/video/8216940/download
https://www.pexels.com/video/7424400/download
https://www.pexels.com/video/8436000/download
https://www.pexels.com/video/6446180/download
https://www.pexels.com/video/6799740/download
https://www.pexels.com/video/6935810/download
https://www.pexels.com/video/7957280/download
https://www.pexels.com/video/8382490/download
https://www.pexels.com/video/6306030/download
https://www.pexels.com/video/8456640/download
https://www.pexels.com/video/8113110/download
https://www.pexels.com/video/7673610/download
https://www.pexels.com/video/6197560/download
https://www.pexels.com/video/6198550/download
https://www.pexels.com/video/9371260/download
https://www.pexels.com/video/12910150/download
https://www.pexels.com/video/5834600/download
https://www.pexels.com/video/7730520/download
https://www.pexels.com/video/7140210/download
https://www.pexels.com/video/5716220/download
https://www.pexels.com/video/7706010/download
https://www.pexels.com/video/6172960/download
https://www.pexels.com/video/7644230/download
https://www.pexels.com/video/7173140/download
https://www.pexels.com/video/6578980/download
https://www.pexels.com/video/6774470/download
https://www.pexels.com/video/6570560/download
https://www.pexels.com/video/7484280/download
https://www.pexels.com/video/7896900/download
https://www.pexels.com/video/6617220/download
https://www.pexels.com/video/6944280/download
https://www.pexels.com/video/8416580/download
https://www.pexels.com/video/8511010/download
https://www.pexels.com/video/8076890/download
https://www.pexels.com/video/5981910/download
https://www.pexels.com/video/6707470/download
https://www.pexels.com/video/5901660/download
https://www.pexels.com/video/5319930/download
https://www.pexels.com/video/7329850/download
https://www.pexels.com/video/9613990/download
https://www.pexels.com/video/5384950/download
https://www.pexels.com/video/6437920/download
https://www.pexels.com/video/7148070/download
https://www.pexels.com/video/8111740/download
https://www.pexels.com/video/4540340/download
https://www.pexels.com/video/9001930/download
https://www.pexels.com/video/12331340/download
https://www.pexels.com/video/6784470/download
https://www.pexels.com/video/5515570/download
https://www.pexels.com/video/5973230/download
https://www.pexels.com/video/7198890/download
https://www.pexels.com/video/7267510/download
https://www.pexels.com/video/6730930/download
https://www.pexels.com/video/8057650/download
https://www.pexels.com/video/7424390/download
https://www.pexels.com/video/7550840/download
https://www.pexels.com/video/8362620/download
https://www.pexels.com/video/8376450/download
https://www.pexels.com/video/8056690/download
https://www.pexels.com/video/8087310/download
https://www.pexels.com/video/8544230/download
https://www.pexels.com/video/4860330/download
https://www.pexels.com/video/12433210/download
https://www.pexels.com/video/4753980/download
https://www.pexels.com/video/5184350/download
https://www.pexels.com/video/6323270/download
https://www.pexels.com/video/7945890/download
https://www.pexels.com/video/8777100/download
https://www.pexels.com/video/8170730/download
https://www.pexels.com/video/5370830/download
https://www.pexels.com/video/7671930/download
https://www.pexels.com/video/8224600/download
https://www.pexels.com/video/4098440/download
https://www.pexels.com/video/6153970/download
https://www.pexels.com/video/6615310/download
https://www.pexels.com/video/6892550/download
https://www.pexels.com/video/8087090/download
https://www.pexels.com/video/4976900/download
https://www.pexels.com/video/7354940/download
https://www.pexels.com/video/8345820/download
https://www.pexels.com/video/4671960/download
https://www.pexels.com/video/6875170/download
https://www.pexels.com/video/7699750/download
https://www.pexels.com/video/10536910/download
https://www.pexels.com/video/8217090/download
https://www.pexels.com/video/8729420/download
https://www.pexels.com/video/6913260/download
https://www.pexels.com/video/7329840/download
https://www.pexels.com/video/8448090/download
https://www.pexels.com/video/6890230/download
https://www.pexels.com/video/3201200/download
https://www.pexels.com/video/6447700/download
https://www.pexels.com/video/6245810/download
https://www.pexels.com/video/7187450/download
https://www.pexels.com/video/8322000/download
https://www.pexels.com/video/6324550/download
https://www.pexels.com/video/6525480/download
https://www.pexels.com/video/6389560/download
https://www.pexels.com/video/5974320/download
https://www.pexels.com/video/7545940/download
https://www.pexels.com/video/4507230/download
https://www.pexels.com/video/7480490/download
https://www.pexels.com/video/6132710/download
https://www.pexels.com/video/7525810/download
https://www.pexels.com/video/7901510/download
https://www.pexels.com/video/7016530/download
https://www.pexels.com/video/7680770/download
https://www.pexels.com/video/7793360/download
https://www.pexels.com/video/6202100/download
https://www.pexels.com/video/7809650/download
https://www.pexels.com/video/6984840/download
https://www.pexels.com/video/7540250/download
https://www.pexels.com/video/7253250/download
https://www.pexels.com/video/7804490/download
https://www.pexels.com/video/7728220/download
https://www.pexels.com/video/8047410/download
https://www.pexels.com/video/7597260/download
https://www.pexels.com/video/6951180/download
https://www.pexels.com/video/6297140/download
https://www.pexels.com/video/7957040/download
https://www.pexels.com/video/9511850/download
https://www.pexels.com/video/8987290/download
https://www.pexels.com/video/6930230/download
https://www.pexels.com/video/6245510/download
https://www.pexels.com/video/5124240/download
https://www.pexels.com/video/7576310/download
https://www.pexels.com/video/6547780/download
https://www.pexels.com/video/7881190/download
https://www.pexels.com/video/7969760/download
https://www.pexels.com/video/8160260/download
https://www.pexels.com/video/7551200/download
https://www.pexels.com/video/8043430/download
https://www.pexels.com/video/6063030/download
https://www.pexels.com/video/8192040/download正文放不下了…