文章目录
- 前言
- 云数据库的对比
- 传统云数据库:
- TDSQL-C Serverless:
- 智能体与TDSQL-C的结合思路
- 算力服务器与数据库服务器申请与部署
- 购买 TDSQL-C Mysql Serverless 实例
- 购买HAI高算力服务器
- 准备工作
- 准备数据
- 下载依赖
- 案例开发
- 创建数据库
- 开启智能体与TDSQL-C结合
- 总结
前言
TDSQL-C MySQL 版(TDSQL-C for MySQL)是腾讯云自研的新一代云原生关系型数据库。融合了传统数据库、云计算与新硬件技术的优势,为用户提供具备高弹性、高性能、海量存储、安全可靠的数据库服务。TDSQL-C MySQL 版100%兼容 MySQL 5.7、8.0。实现超百万级 QPS 的高吞吐,最高 PB 级智能存储,保障数据安全可靠。
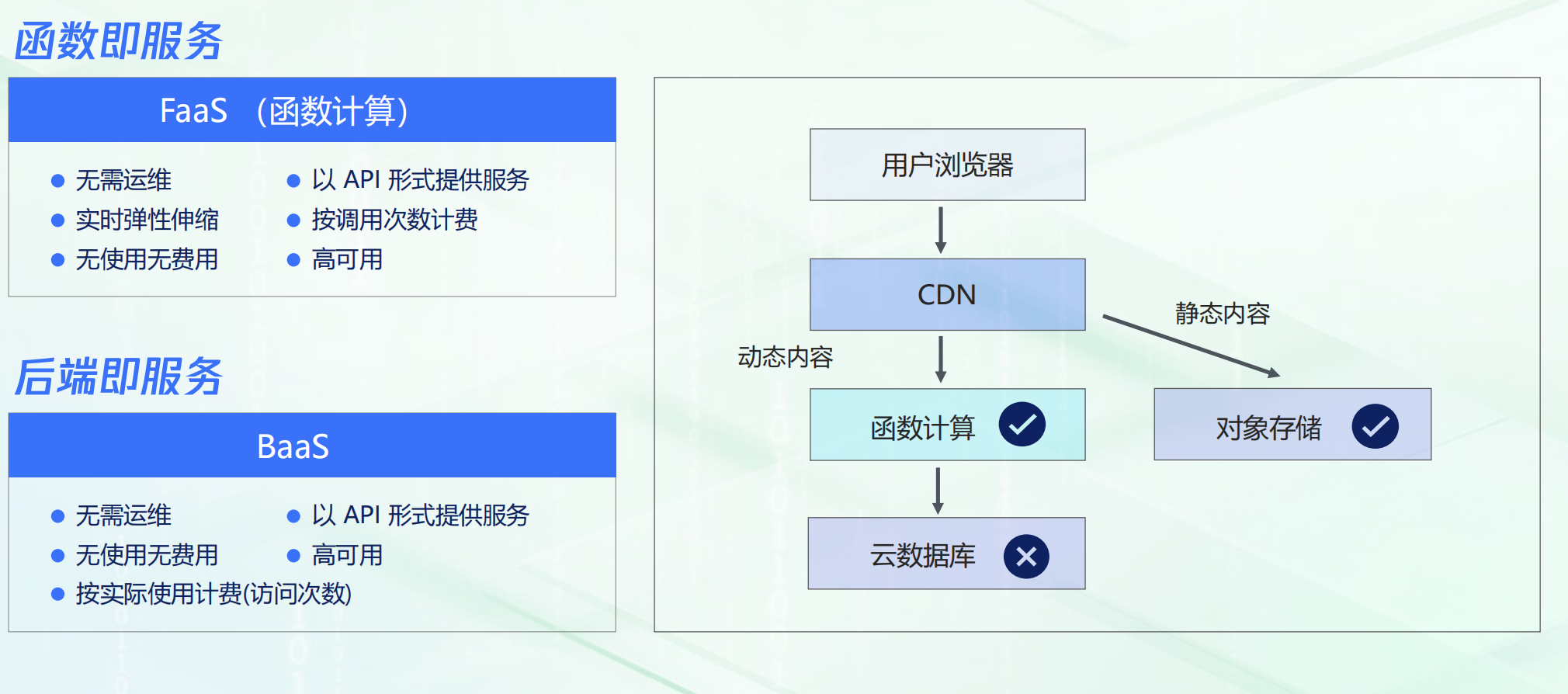
TDSQL-C MySQL 版采用存储和计算分离的架构,所有计算节点共享一份数据,提供秒级的配置升降级、秒级的故障恢复,单节点可支持百万级 QPS,自动维护数据和备份,最高以GB/秒的速度并行回档。
TDSQL-C MySQL 版既融合了商业数据库稳定可靠、高性能、可扩展的特征,又具有开源云数据库简单开放、高效迭代的优势。TDSQL-C MySQL 版引擎完全兼容原生 MySQL,您可以在不修改应用程序任何代码和配置的情况下,将 MySQL 数据库迁移至 TDSQL-C MySQL 版引擎。
本篇文章我们将一步一步的实现 如何利用腾讯云的高性能应用服务
HAI和TDSQL-C MySQL Serverless版构建人才可视化数据分析
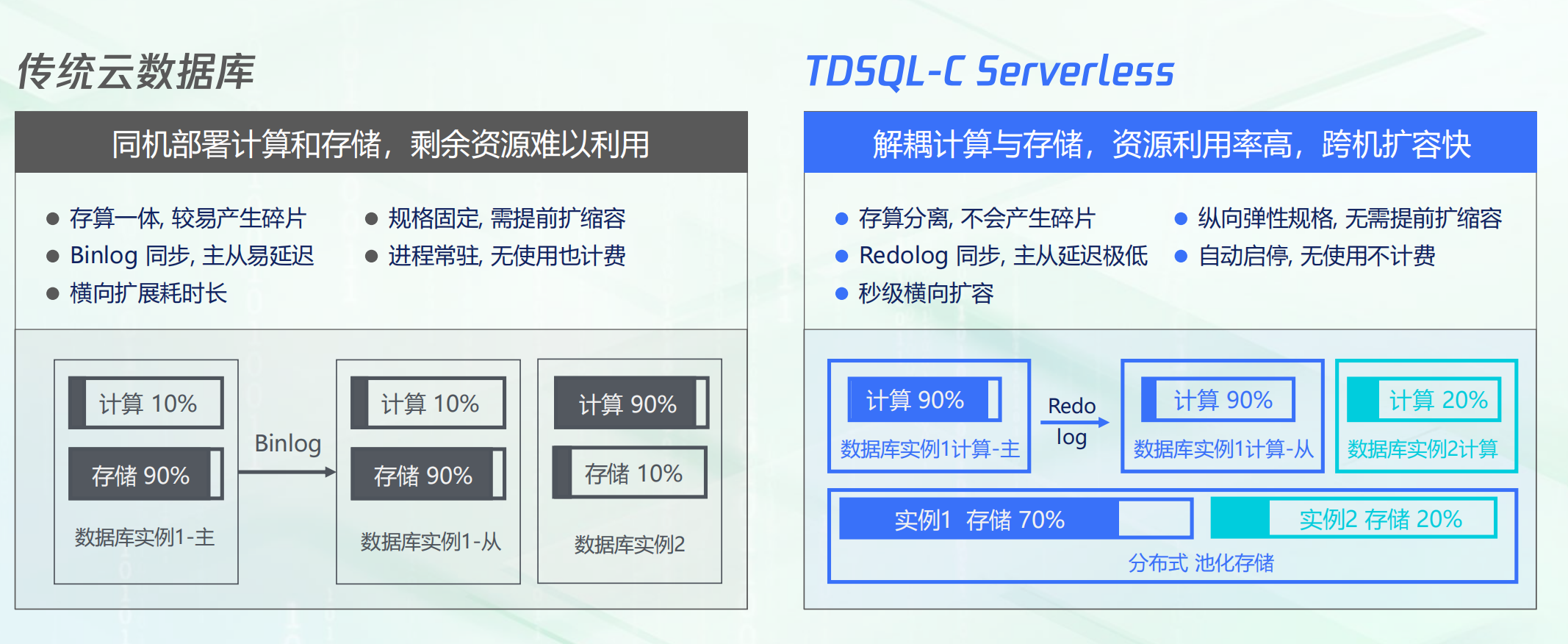
云数据库的对比
传统云数据库:
- 同机部署计算和存储,剩余资源难以利用
- 存算一体,较易产生碎片
- 规格固定,需提前扩缩容
- Binlog同步,主从易延迟
- 进程常驻,无使用也计费
- 横向扩展耗时长
TDSQL-C Serverless:
- 解耦计算与存储,资源利用率高,跨机扩容快 存算分离,不会产生碎片
- 纵向弹性规格,无需提前扩缩容
- Redolog 同步,主从延迟极低
- 自动启停,无使用不计费
- 秒级横向扩容
智能体与TDSQL-C的结合思路
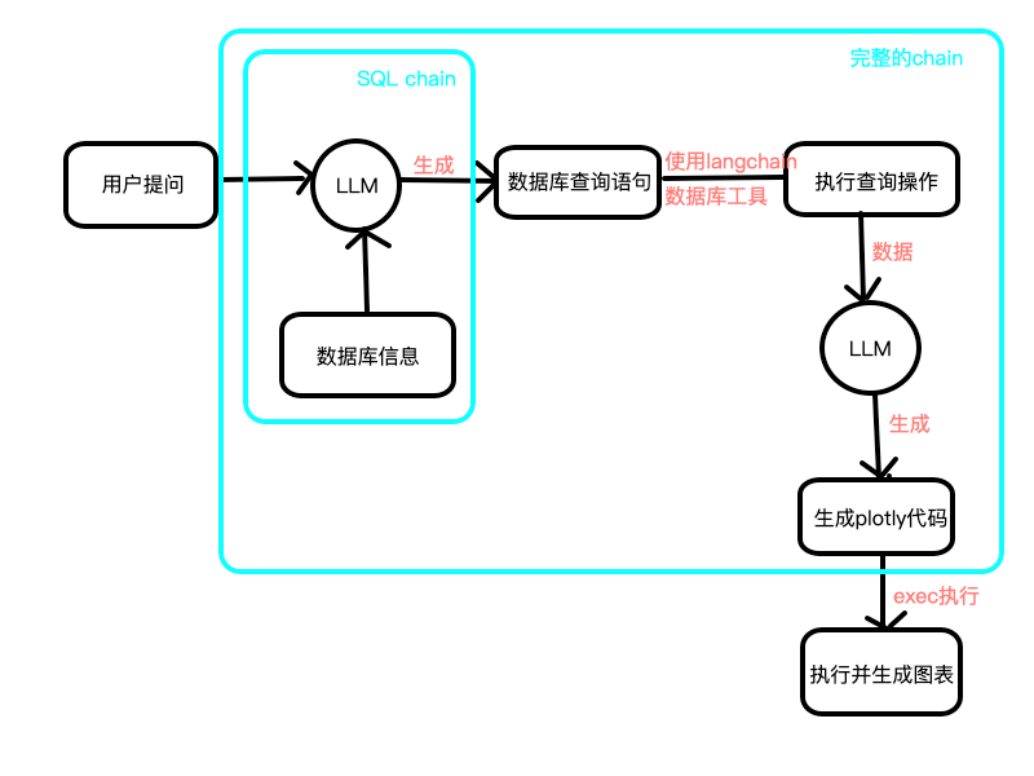
算力服务器与数据库服务器申请与部署
购买 TDSQL-C Mysql Serverless 实例
- 访问腾讯云官网申请
TDSQL-C Mysql服务器, 点击链接 进行访问, 如下图所示,点击立即选购

- 选购
如下图所示,选购我们所需的Serverless
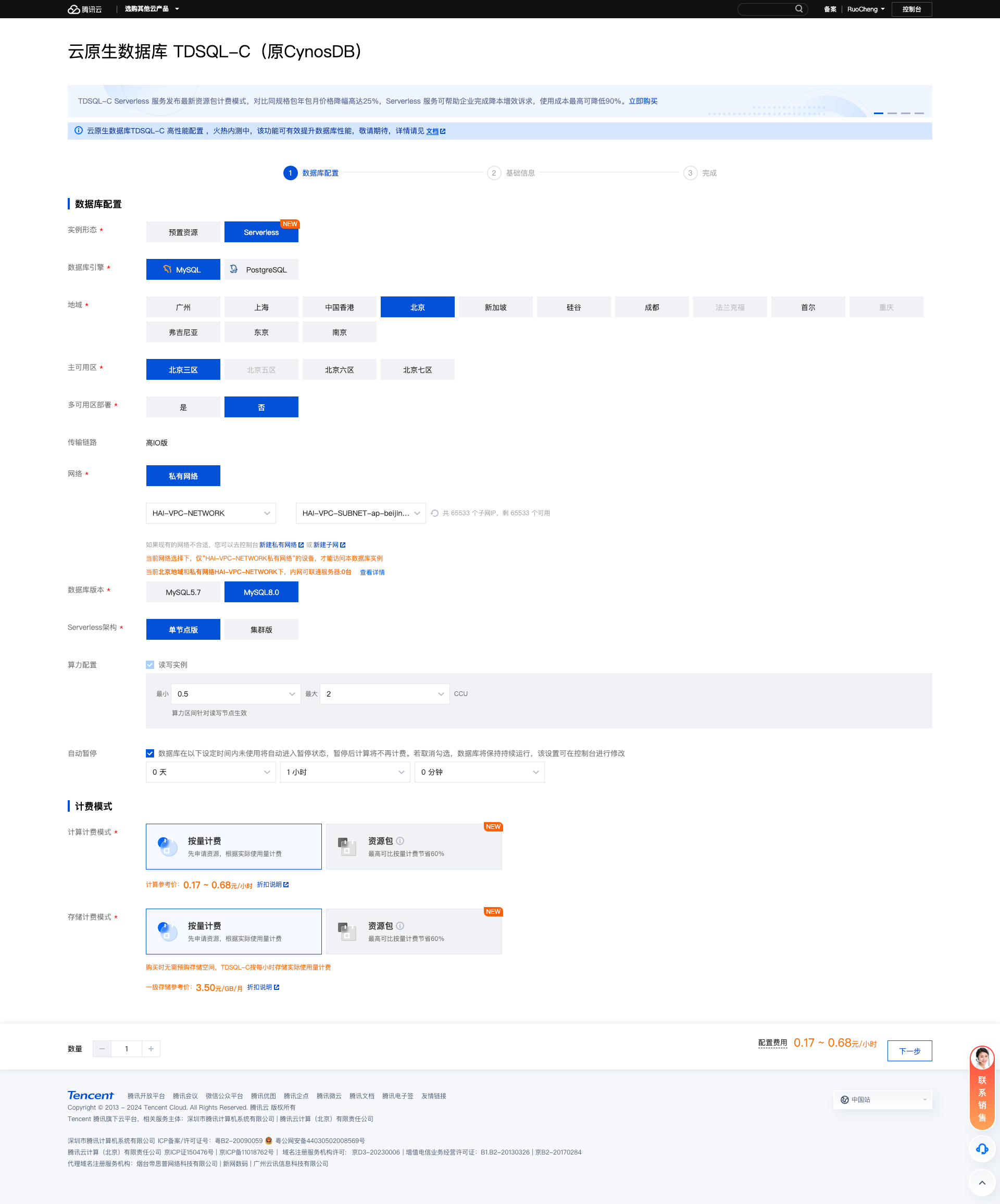
- 设置数据库密码与配置信息
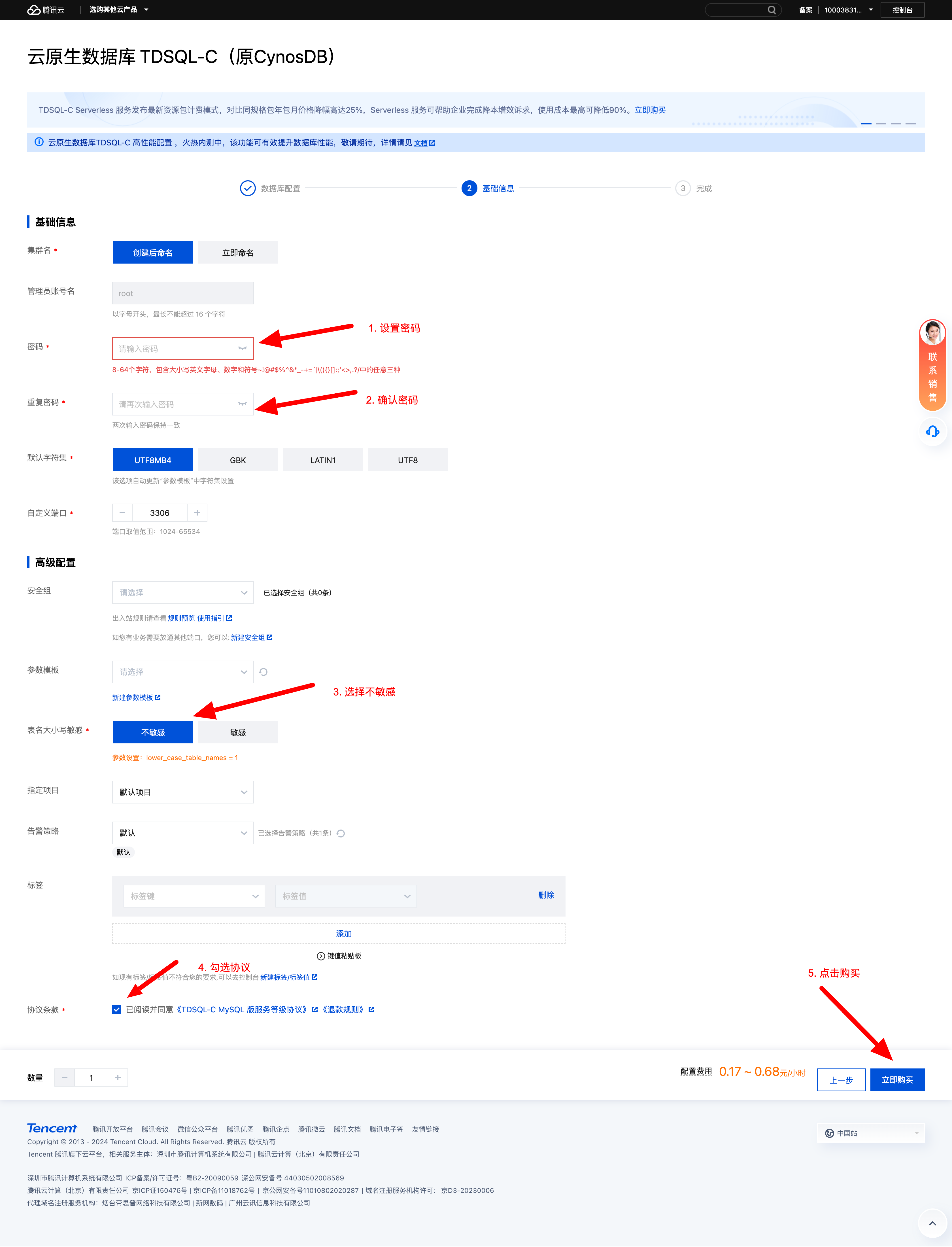
按照上述操作完成之后点击立即购买即可
购买HAI高算力服务器
- 点击链接 访问腾讯云
HAI官网,如下图所示点击立即使用
- 点击新建按钮,新建服务器(费用会在新建服务器并使用后才开始计费)
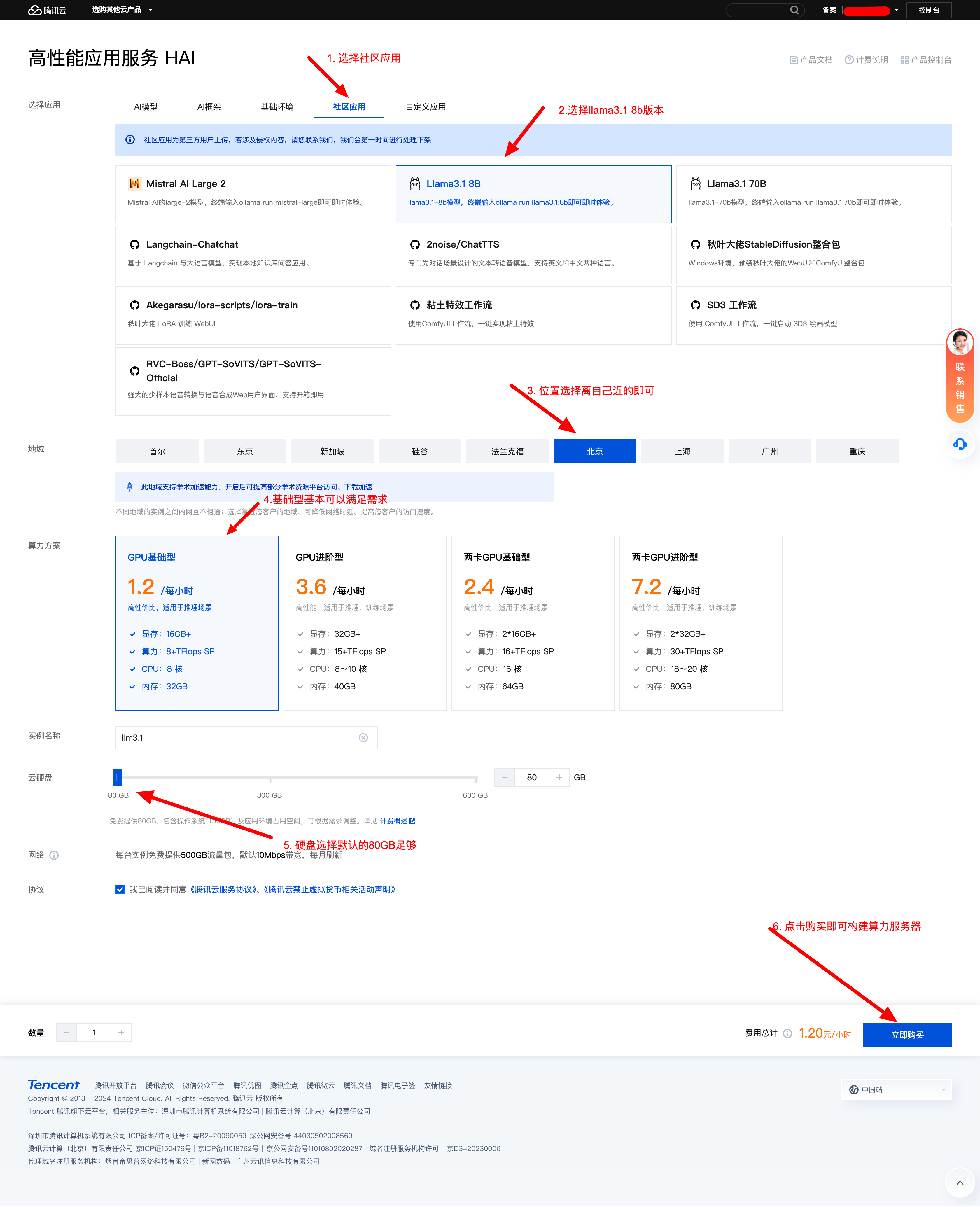
- 根据配置需求选择算力服务器
- 查看
HAI算力服务器的llama对外端口
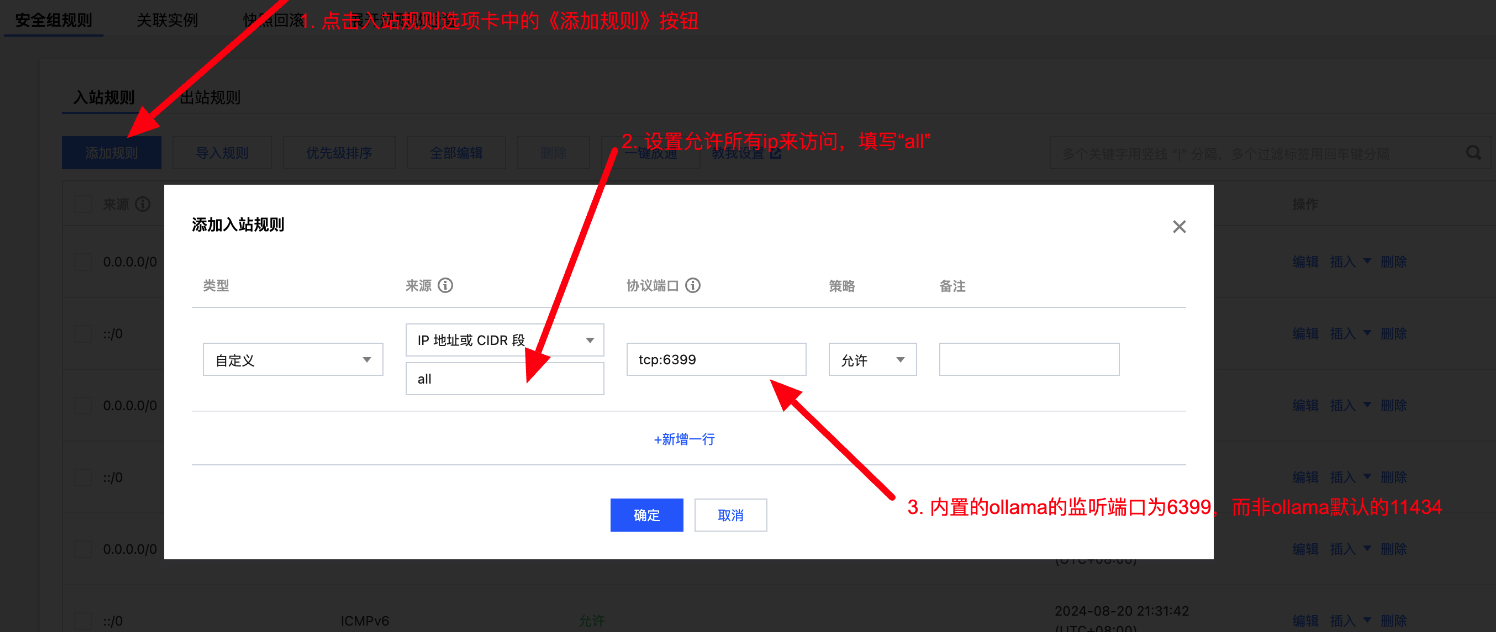
检查是否已经默认开放 6399端口,如果没有开放的话需要手动点击端口配置在入站规则中添加协议端口
配置完成之后可以在浏览器中输入 ip:6399 进行访问,查看浏览器页面中是否有 ollama is running 的输出, 如果有输出的话,则表示此时的配置没有问题,外部链接是可以访问的。
准备工作
准备数据
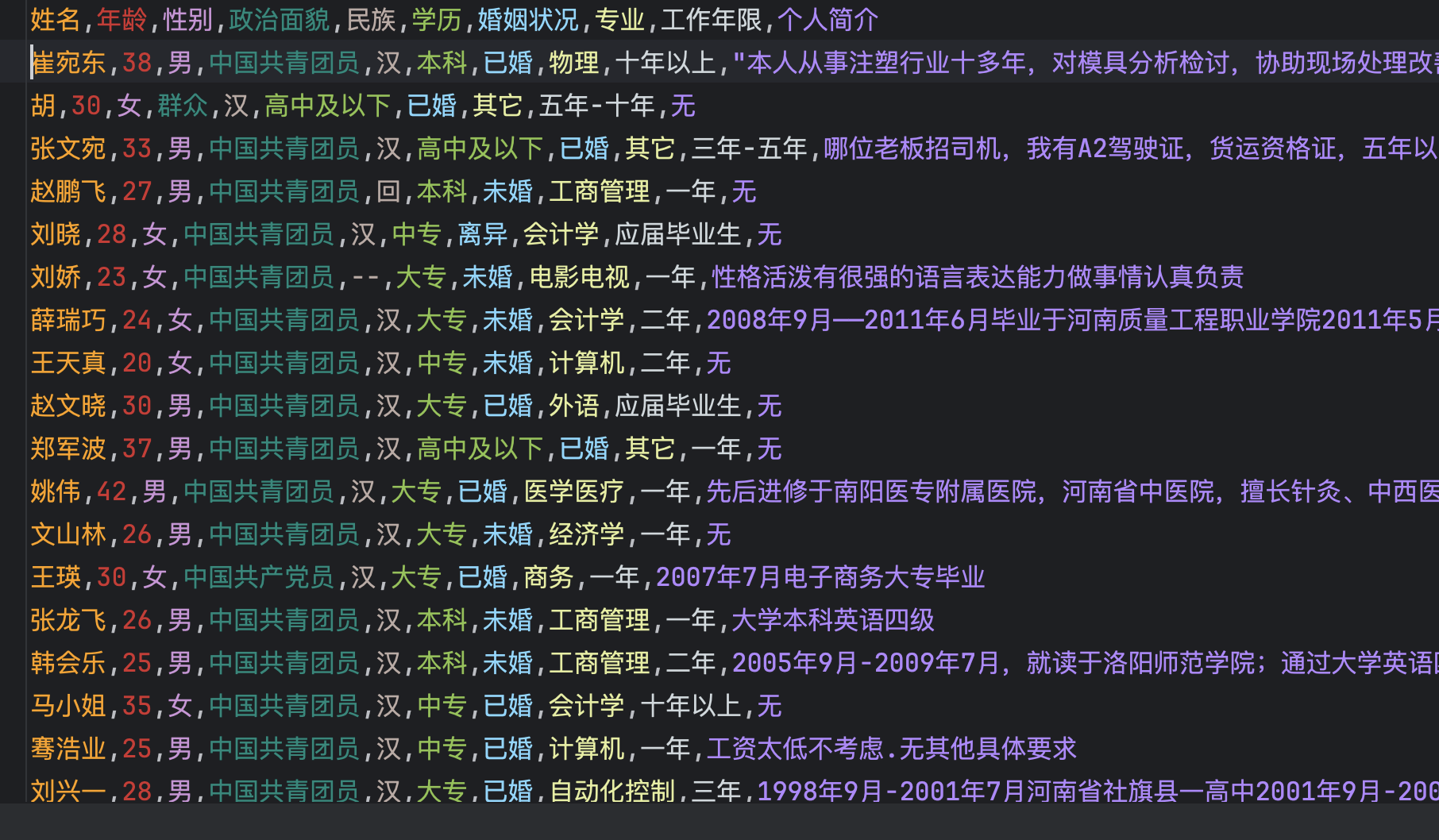
如下图所示我们准备的是部分人原型信息的csv数据, 目前准备了155条数据,用于我们本次的测试使用
下载依赖
如下图所示在终端输入指令,下载所需的依赖
pip install openai
pip install langchain
pip install langchain-core
pip install langchain-community
pip install mysql-connector-python
pip install streamlit
pip install plotly
pip install numpy
pip install pandas
pip install watchdog
pip install matplotlib
pip install kaleido
pip install wordcloud
安装的插件作用:
以下是对每个插件的作用描述:
pip install openai- 作用:用于安装OpenAI的Python SDK,这个库允许开发者使用OpenAI的API来访问各种AI模型和服务,如GPT-3、文本生成、文本分类等。
pip install langchain- 作用:
langchain是一个可能用于构建语言模型链的库,但具体的细节可能因项目而异。它可能提供构建复杂对话系统或语言处理任务的工具。
- 作用:
pip install langchain-core- 作用:类似于
langchain,这个库可能是langchain的核心组件或扩展,用于处理更高级的语言模型链构建。
- 作用:类似于
pip install langchain-community- 作用:这个库可能是针对社区或特定领域定制的
langchain扩展,提供了特定用途的工具或功能。
- 作用:这个库可能是针对社区或特定领域定制的
pip install mysql-connector-python- 作用:用于安装MySQL连接器,这是一个用于Python语言与MySQL数据库进行通信的库。
pip install streamlit- 作用:用于安装Streamlit,这是一个开源的Python库,可以快速构建和共享数据应用。
pip install plotly- 作用:用于安装Plotly,这是一个开源的图表库,可以创建交互式图表。
pip install numpy- 作用:用于安装NumPy,这是一个强大的Python库,用于进行科学计算,特别是涉及大型数组和矩阵的操作。
pip install pandas- 作用:用于安装Pandas,这是一个Python数据分析库,提供了高性能、易用的数据结构和数据分析工具。
pip install watchdog- 作用:用于安装Watchdog,这是一个Python库和shell工具,用于监控文件系统事件。
pip install matplotlib- 作用:用于安装Matplotlib,这是一个Python的2D绘图库,可以生成高质量的图形和图表。
pip install kaleido- 作用:用于安装Kaleido,这是一个Plotly的依赖库,用于将Plotly图表导出为静态图像文件。
pip install wordcloud- 作用:用于安装WordCloud,这是一个Python库,用于生成词云图像,可以直观地展示文本数据中的关键词频率。
案例开发
创建数据库
登录云数据库,创建tdsql 数据库如下图所示
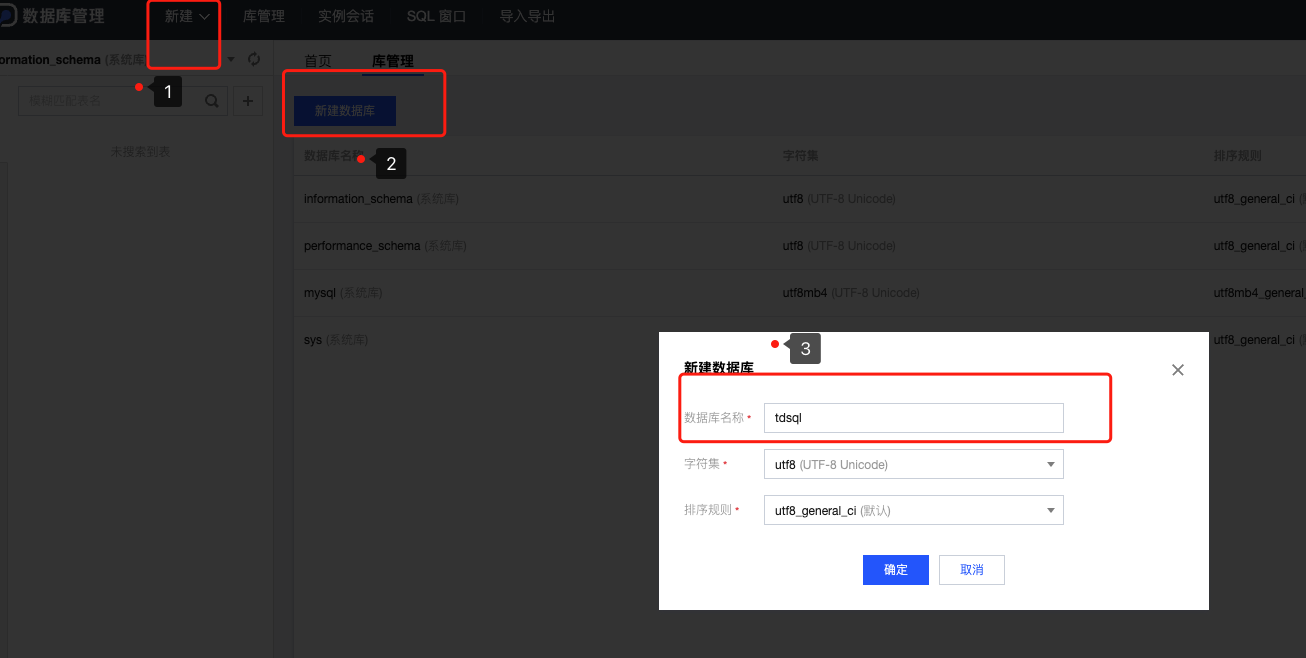
点击SQL窗口,在窗口中输入框中选择tdsql 数据库,然后创建users 数据表,如下图所示
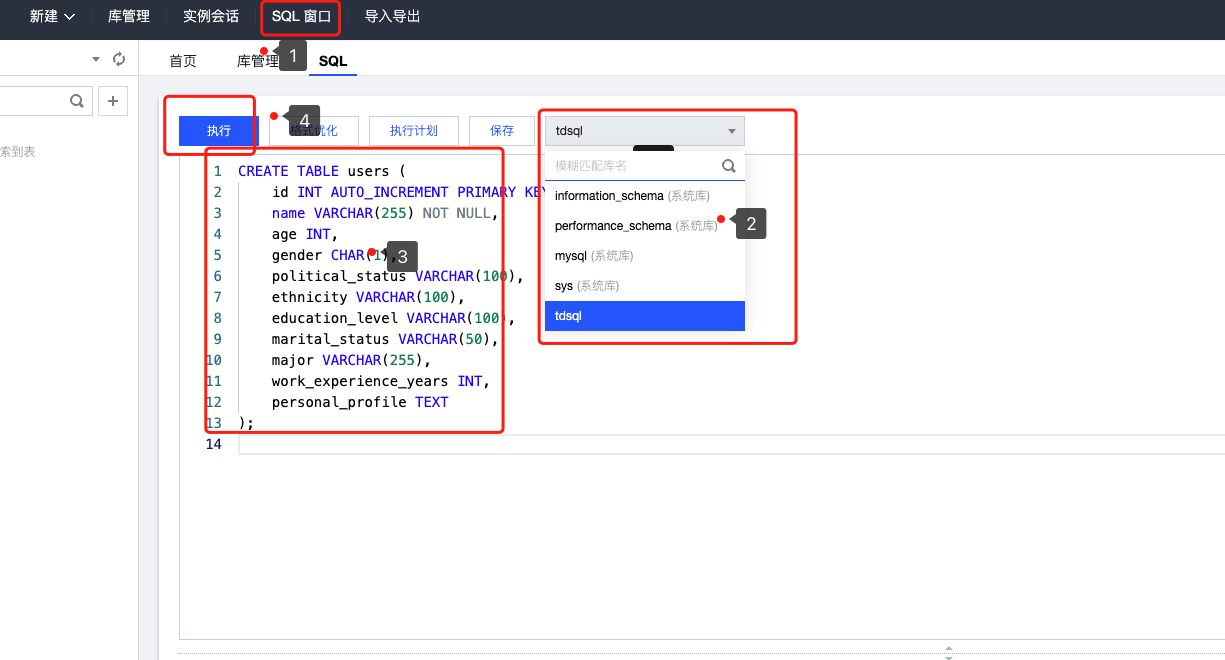
sql语句如下:
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
age INT,
gender CHAR(1),
political_status VARCHAR(100),
ethnicity VARCHAR(100),
education_level VARCHAR(100),
marital_status VARCHAR(50),
major VARCHAR(255),
work_experience_years VARCHAR(100),
personal_profile TEXT
);
将csv 数据插入到数据库中py语法如下:
import mysql.connector
import csv
# 数据库连接信息
config = {
'user': 'root',
'password': 'Pytosql123',
'host': 'bj-cynosdbmysql-grp-7a0yrx5e.sql.tencentcdb.com',
'database': 'tdsql',
'port': 23893,
'raise_on_warnings': True
}
file_path = "users.csv"
def insert_csv_data_to_db(config, file_path):
# 创建连接
creatConnector = mysql.connector.connect(**config)
# 获取游标
cursor = creatConnector.cursor()
try:
# 读取csv 数据, 并将数据插入到数据库
with open(file_path, mode='r', encoding='utf-8') as csv_file:
reader = csv.DictReader(csv_file)
rows = list(reader) # 将CSV行转换为列表,以便批量插入
# 定义SQL插入语句模板
query_template = """
INSERT INTO users (
name,
age,
gender,
political_status,
ethnicity,
education_level,
marital_status,
major,
work_experience_years,
personal_profile
) VALUES (
%s, %s, %s, %s, %s, %s, %s, %s, %s, %s
)
"""
# 将每行数据转换成元组格式,并处理空字段
values_tuples = []
for row in rows:
# 将空字符串转换为None
values = [None if value == '' or value == '暂无数据' else value for value in row.values()]
values_tuples.append(tuple(values))
# 打印前几个元组进行调试
# print(values_tuples[:5])
cursor.executemany(query_template, values_tuples)
# 提交事务
creatConnector.commit()
except mysql.connector.Error as err:
print(f"Database error: {err}")
except Exception as e:
print(f"An error occurred: {e}")
finally:
# 关闭游标
cursor.close()
# 关闭连接
creatConnector.close()
if __name__ == '__main__':
insert_csv_data_to_db(config, file_path)
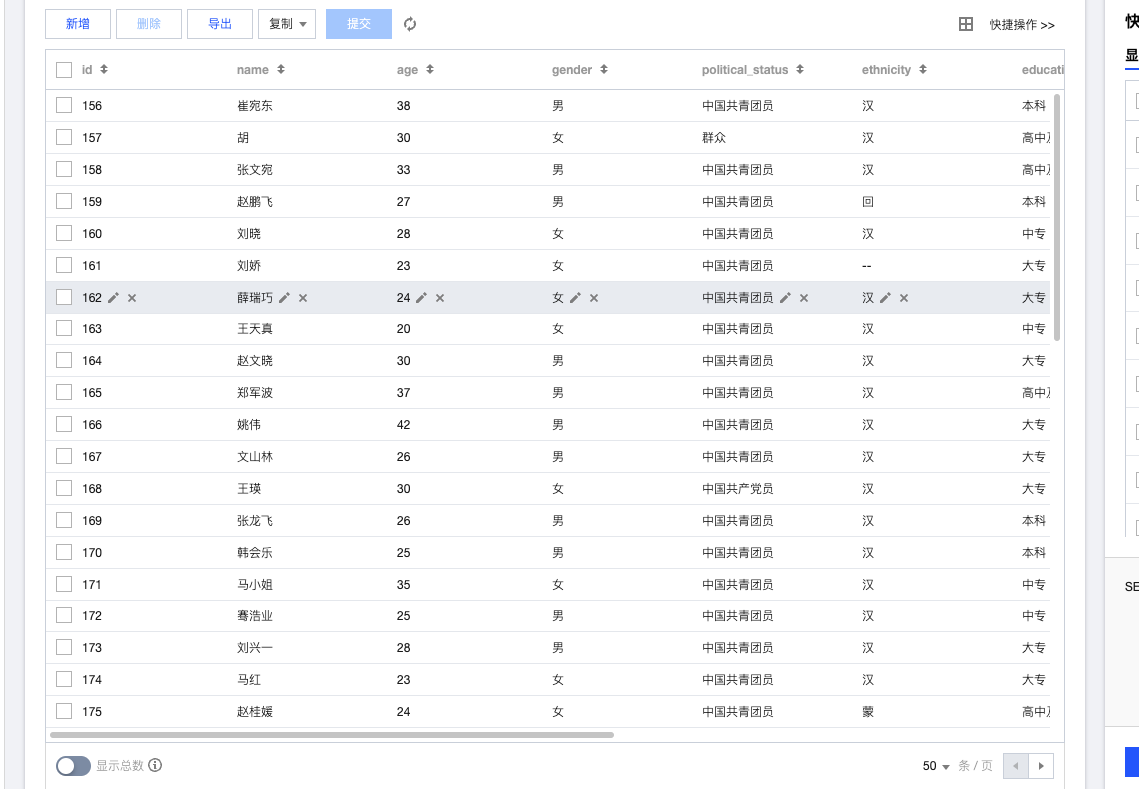
执行完上述代码后,云数据库表内容如下:
开启智能体与TDSQL-C结合
示例代码如下:
import csv
from langchain_community.utilities import SQLDatabase
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
import streamlit as st
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import yaml
import mysql.connector
from decimal import Decimal
import plotly.graph_objects as go
import plotly
import pkg_resources
import matplotlib
import streamlit as st
import mysql.connector
import csv
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
#指定字体文件路径
font_path = 'wendaoshouyuanti.ttf'
# 加载自定义字体文件
custom_font = FontProperties(fname=font_path)
yaml_file_path = 'config.yaml'
with open(yaml_file_path, 'r') as file:
config_data = yaml.safe_load(file)
# 获取所有的已安装的pip包
def get_piplist(p):
return [d.project_name for d in pkg_resources.working_set]
# 获取llm用于提供AI交互
ollama = ChatOllama(model=config_data['hai']['model'], base_url=config_data['hai']['base_url'])
db_user = config_data['database']['db_user']
db_password = config_data['database']['db_password']
db_host = config_data['database']['db_host']
db_port = config_data['database']['db_port']
db_name = config_data['database']['db_name']
# 获得schema
def get_schema(db):
schema = mysql_db.get_table_info()
return schema
def getResult(content):
global mysql_db
# 数据库连接
mysql_db = SQLDatabase.from_uri(f"mysql+mysqlconnector://{db_user}:{db_password}@{db_host}:{db_port}/{db_name}")
# 获得 数据库中表的信息
# mysql_db_schema = mysql_db.get_table_info()
# print(mysql_db_schema)
template = """基于下面提供的数据库schema, 根据用户提供的要求编写sql查询语句,要求尽量使用最优sql,每次查询都是独立的问题,不要收到其他查询的干扰:
{schema}
Question: {question}
只返回sql语句,不要任何其他多余的字符,例如markdown的格式字符等:
如果有异常抛出不要显示出来
"""
prompt = ChatPromptTemplate.from_template(template)
text_2_sql_chain = (
RunnablePassthrough.assign(schema=get_schema)
| prompt
| ollama
| StrOutputParser()
)
# 执行langchain 获取操作的sql语句
sql = text_2_sql_chain.invoke({"question": content})
print(sql)
# 连接数据库进行数据的获取
# 配置连接信息
conn = mysql.connector.connect(
host=db_host,
port=db_port,
user=db_user,
password=db_password,
database=db_name
)
# 创建游标对象
cursor = conn.cursor()
# 查询数据
cursor.execute(sql.strip("```").strip("```sql"))
info = cursor.fetchall()
# 打印结果
# for row in info:
# print(row)
# 关闭游标和数据库连接
cursor.close()
conn.close()
# 根据数据生成对应的图表
print(info)
template2 = """
以下提供当前python环境已经安装的pip包集合:
{installed_packages};
请根据data提供的信息,生成是一个适合展示数据的plotly的图表的可执行代码,要求如下:
1.不要导入没有安装的pip包代码
2.如果存在多个数据类别,尽量使用柱状图,循环生成时图表中对不同数据请使用不同颜色区分,
3.图表要生成图片格式,保存在当前文件夹下即可,名称固定为:图表.png,
4.我需要您生成的代码是没有 Markdown 标记的,纯粹的编程语言代码。
5.生成的代码请注意将所有依赖包提前导入,
6.不要使用iplot等需要特定环境的代码
7.请注意数据之间是否可以转换,使用正确的代码
8.不需要生成注释
9.自定义字体使用指定字体文件路径: font_path = 'wendaoshouyuanti.ttf';
data:{data}
这是查询的sql语句与文本:
sql:{sql}
question:{question}
返回数据要求:
仅仅返回python代码,不要有额外的字符
"""
prompt2 = ChatPromptTemplate.from_template(template2)
data_2_code_chain = (
RunnablePassthrough.assign(installed_packages=get_piplist)
| prompt2
| ollama
| StrOutputParser()
)
# 执行langchain 获取操作的sql语句
code = data_2_code_chain.invoke({"data": info, "sql": sql, 'question': content})
# 删除数据两端可能存在的markdown格式
print(code.strip("```").strip("```python"))
exec(code.strip("```").strip("```python"))
return {"code": code, "SQL": sql, "Query": info}
# 构建展示页面
import streamlit
# 设置页面标题
streamlit.title('智能体与TDSQL-C结合实现人才的可视化数据分析')
# 设置对话框
content = streamlit.text_area('请输入想查询的信息', value='', max_chars=None)
# 提问按钮 # 设置点击操作
if streamlit.button('提问'):
# 开始ai及langchain操作
if content:
# 进行结果获取
result = getResult(content)
# 显示操作结果
streamlit.write('AI生成的SQL语句:')
streamlit.write(result['SQL'])
streamlit.write('SQL语句的查询结果:')
streamlit.write(result['Query'])
streamlit.write('plotly图表代码:')
streamlit.write(result['code'])
# 显示图表内容(生成在getResult中)
streamlit.image('./图表.png', width=800)
运行效果如图:

效果如下:
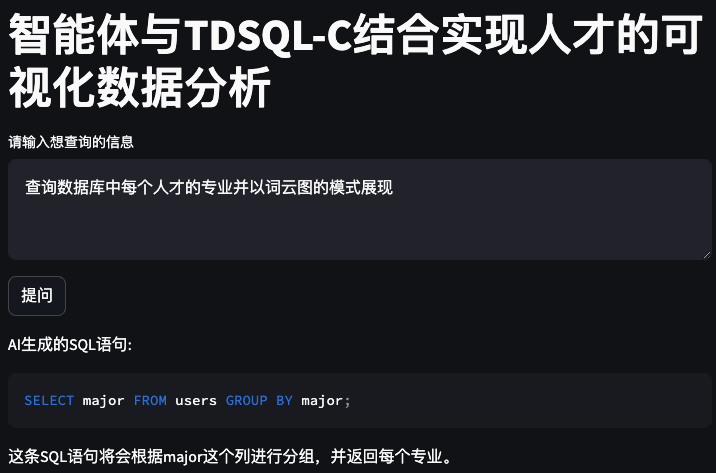

到目前为止我们就已经完整的开发完成啦,赶快去尝试一下吧
总结
本篇博客我们主要通过HAI 与tdsql-c 结合实现了智能化的数据查询以及数据图表的生成,在py中核心的思路如下:
- 成功对接了Llama3.1大型模型,为数据库查询提供了强大的AI支持;
- 构建了SQL-Chain,将TDSQL-C数据库架构信息融入大型语言模型,实现了智能化的数据处理;
- 构建了User-Chain,有效地将用户的查询需求转化为模型可理解的指令,进而生成精确的SQL查询语句。