PSO粒子群算法手搓实现版🚀
读了博士之后,送算法方向转到了控制方向,然后最近接触到的项目,要用到粒子群算法,然后秉持着我自己一贯的把基础代码自己手写一遍的原则,我自己上网找了一些视频,然后自己根据自己的理解重新写了一份出来,然后又让智普清言,帮我优化了一些细节,最后得到一份符合我自己风格的一个版本,之后如果工作任务上又需要,我也会进一步在我自己的代码上优化修改,给予我自己一份安全感。
粒子群算法(Particle Swarm Optimization,简称PSO)是一种基于群体智能的优化技术。它模拟鸟群或鱼群的社会行为,通过群体中个体之间的信息共享与协同搜索来寻找问题的最优解。在PSO中,每个粒子代表问题空间中的一个候选解,粒子通过跟踪自己的历史最佳位置和整个群体的最佳位置来调整自己的飞行轨迹。这种算法通过迭代过程不断更新粒子的速度和位置,直到找到满足优化目标的最优解或近似最优解。粒子群算法因其实现简单、参数少、收敛速度快等优点,在许多优化问题中得到了广泛应用。
文章目录
- PSO粒子群算法手搓实现版🚀
- 1.问题定义
- 2.粒子群算法参数表
- 3.粒子群算法流程图
- 4.完整代码&结果图
- 4.1 完整代码
- 4.2 迭代曲线
- 4.3 全局最优解和最优适应度(函数值)
- 5.代码分解详解
- 5.1参数初始化部分
- 5.2迭代部分
- 6.结束
1.问题定义
首先就是定义这个问题,这里用一个求函数最小值的问题,这里使用的是b站上,青青草原灰太狼同学的例子非常感谢这里引用下。
当前有一个函数,函数定义如下。
f
(
x
)
=
x
s
i
n
(
x
)
c
o
n
(
2
x
)
−
2
x
s
i
n
(
x
)
+
3
x
i
n
(
4
x
)
f(x)=xsin(x)con(2x)-2xsin(x)+3xin(4x)
f(x)=xsin(x)con(2x)−2xsin(x)+3xin(4x)
目标:在
x
∈
[
0
,
50
]
x\in[0,50]
x∈[0,50]区间内找到令
f
(
x
)
f(x)
f(x)的值最小的点,
x
∗
x^*
x∗表示满足条件的最优解(最小值)。
x
∗
=
arg
min
x
∈
[
0
,
50
]
f
(
x
)
x^* = \arg \min_{x \in [0, 50]} f(x)
x∗=argx∈[0,50]minf(x)
函数图像如下:

可以看到实际上值最小的点应该是在45左右的一个点。
2.粒子群算法参数表
这个表方便大家之后看流程图和代码的时候进行对照。
| 参数名称 | 本文使用的符号 | 参数解释 |
|---|---|---|
| 总群大小 | N N N | 粒子的数量 |
| 维度 | d d d | 每个粒子有多少个参数 |
| 迭代次数 | g e r ger ger | 多少次搜索之后算法停止 |
| 位置限制 | l i m i t \boldsymbol{limit} limit | 限制每个粒子参数搜索区间 |
| 速度限制 | v _ l i m i t \boldsymbol{v\_limit} v_limit | 限制每个粒子搜索速度的上下限 |
| 惯性权重 | w w w | 受粒子当前的状态影响的程度 |
| 自学习因子 | c 1 c_1 c1 | 受粒子自己历史最优状态影响程度 |
| 群体学习因子 | c 2 c_2 c2 | 受集体搜索到的最优状态的影响程度 |
| 种群位置 | x \boldsymbol{x} x | 记录所有粒子当前的位置状态 |
| 种群速度 | v \boldsymbol{v} v | 记录所有粒子当前的搜索速度 |
| 个体历史最佳位置 | x b e s t _ l o c a t i o n \boldsymbol{x_{best\_location}} xbest_location | 记录每个粒子自己搜索到的最优位置 |
| 个体历史最佳适应度 | x b e s t \boldsymbol{x_{best}} xbest | 记录每个粒子自己搜索到的最优适应度(函数值) |
| 全局最佳位置 | g b e s t _ l o c a t i o n \boldsymbol{g_{best\_location}} gbest_location | 记录群体搜索到的最优位置 |
| 全局最佳适应度 | g b e s t \boldsymbol{g_{best}} gbest | 记录群体搜索到的最优适应度(函数值) |
| 随机系数 | r 1 \boldsymbol{r_1} r1 | 用于调整粒子向其个体历史最佳位置移动的步长 |
| 随机系数 | r 2 \boldsymbol{r_2} r2 | 用于调整粒子向其全局最佳最佳位置移动的步长 |
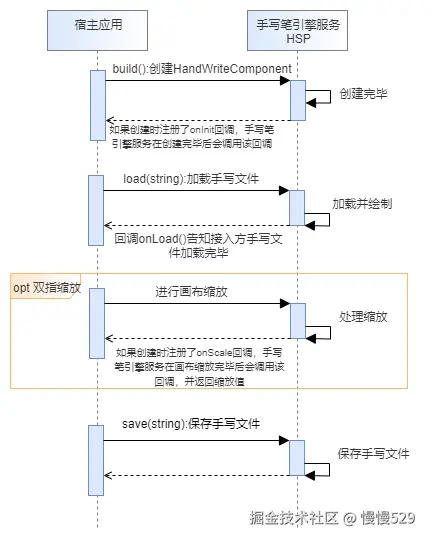
3.粒子群算法流程图

3.1速度 v \boldsymbol{v} v的更新公式
速度更新公式是整个PSO粒子群算法的核心,我使用我的变量命令方式写出了这个公式,之后使用智谱清言辅助我通俗的解释一下。
v
=
w
⋅
v
+
c
1
⋅
r
1
⋅
(
x
b
e
s
t
_
l
o
c
a
t
i
o
n
−
x
)
+
c
2
⋅
r
2
⋅
(
g
b
e
s
t
_
l
o
c
a
t
i
o
n
−
x
)
\boldsymbol{v} = w \cdot \boldsymbol{v} + c_1 \cdot \boldsymbol{r_1} \cdot (\boldsymbol{x_{best\_location}} - \boldsymbol{x}) + c_2 \cdot \boldsymbol{r_2} \cdot (\boldsymbol{g_{best\_location}} - \boldsymbol{x})
v=w⋅v+c1⋅r1⋅(xbest_location−x)+c2⋅r2⋅(gbest_location−x)
- v \boldsymbol{v} v:这是粒子的速度,它决定了粒子在解空间中移动的快慢和方向。
- w w w:这是惯性权重,它决定了粒子保持之前速度的倾向。如果 w \boldsymbol{w} w较大,粒子会更多地保持原来的速度;如果 w \boldsymbol{w} w较小,粒子会更容易改变速度和方向。
- c 1 c_1 c1 和 c 2 c_2 c2:这两个是学习因子,也称为加速常数。它们分别控制粒子向自己的历史最佳位置(个体经验)和全局最佳位置(群体经验)移动的强度。
- r 1 \boldsymbol{r_1} r1 和 r 2 \boldsymbol{r_2} r2:这两个是随机数,它们在 [ 0 , 1 ] [0, 1] [0,1]范围内均匀分布,增加了粒子移动的随机性,帮助算法探索解空间,避免陷入局部最优。
- x b e s t _ l o c a t i o n \boldsymbol{x_{best\_location}} xbest_location:这是粒子自身历史找到的最佳位置,也就是粒子自己认为最好的解。
- g b e s t _ l o c a t i o n \boldsymbol{g_{best\_location}} gbest_location:这是整个粒子群历史找到的最佳位置,也就是整个群体认为最好的解。
现在,让我们来看公式中的各个部分:
- w ⋅ v w \cdot \boldsymbol{v} w⋅v:这部分表示粒子当前的速度,它将影响粒子的下一步移动。
- c 1 ⋅ r 1 ⋅ ( x b e s t _ l o c a t i o n − x ) c_1 \cdot \boldsymbol{r_1} \cdot (\boldsymbol{x_{best\_location}} - \boldsymbol{x}) c1⋅r1⋅(xbest_location−x):这部分表示粒子向自己的最佳位置移动的倾向。粒子会根据随机数r1和学习因子c1来调整移动的幅度。
- c 2 ⋅ r 2 ⋅ ( g b e s t _ l o c a t i o n − x ) c_2 \cdot \boldsymbol{r_2} \cdot (\boldsymbol{g_{best\_location}} - \boldsymbol{x}) c2⋅r2⋅(gbest_location−x):这部分表示粒子向全局最佳位置移动的倾向。同样,粒子会根据随机数r2和学习因子c2来调整移动的幅度。
3.2位置 x \boldsymbol{x} x的更新公式
x = x + v \boldsymbol{x} = \boldsymbol{x}+\boldsymbol{v} x=x+v
4.完整代码&结果图
这次我打算先给出代码结果,然后最后再逐步解释每一步代码的意思。
4.1 完整代码
import numpy as np
import matplotlib.pyplot as plt
# 适应度函数
f = lambda x: x * np.sin(x) * np.cos(2 * x) - 2 * x * np.sin(x) + 3 * x * np.sin(4 * x)
N = 20 # 初始种群大小
d = 1 # 初始化定位粒子维度
ger = 100 # 迭代次数
limit = np.array([0, 50]) # 位置限制:设置粒子运行的位置的限制
v_limit = np.array([-10, 10]) # 速度限制:设置例子移动速度的上下值
w = 0.8 # 惯性权重
c1 = 0.5 # 自学习因子
c2 = 0.5 # 群体学习因子
# 初始化种群位置
x = limit[0] + (limit[1] - limit[0]) * np.random.rand(N, d)
# 初始化种群的速度
v = np.random.rand(N, d) * (v_limit[1] - v_limit[0]) + v_limit[0]
# 初始化每个个体的历史最佳位置
x_best_location = x.copy()
# 初始化个体历史最佳适应度
x_best = np.ones(N) * np.inf
g_best = np.inf # 初始化全局最佳适应度
g_best_location = None # 初始化全局最最佳位置
# 用于存储每一轮的结果
iter_result = []
for i in range(ger):
fx = f(x).reshape(-1) # 计算当前函数的适应度
better_indices = fx < x_best
x_best_location[better_indices] = x[better_indices]
x_best[better_indices] = fx[better_indices]
# 更新全局最优解
if np.min(x_best) < g_best:
g_best = np.min(x_best)
g_best_location = x_best_location[np.argmin(x_best)]
# 速度更新公式
r1 = np.random.rand(N, d) #随机系数
r2 = np.random.rand(N, d) #随机系数
v = w * v + c1 * r1 * (x_best_location - x) + c2 * r2 * (np.expand_dims(g_best_location, axis=0) - x)
# 粒子移动速度的边界约束处理
v = np.clip(v, v_limit[0], v_limit[1])
# 种群位置的更新
x = x + v
# 位置边界处理
x = np.clip(x, limit[0], limit[1])
iter_result.append(g_best)
print("g_best_location", g_best_location)
print("g_best", g_best)
plt.plot(iter_result,'b')
plt.xlabel("Number of iterations")
plt.ylabel("Fitness")
plt.grid()
plt.show()
4.2 迭代曲线

4.3 全局最优解和最优适应度(函数值)
g_best_location [45.20773182]
g_best -251.0638321801182

把搜索到的点绘制在原来的函数图像上,可以看到收敛的效果还是不错的。

5.代码分解详解
5.1参数初始化部分
- 导入库
import numpy as np
import matplotlib.pyplot as plt
- 使用匿名函数关键字构造适应度函数
# 适应度函数
f = lambda x: x * np.sin(x) * np.cos(2 * x) - 2 * x * np.sin(x) + 3 * x * np.sin(4 * x)
- 基础初始化部分
N = 20 # 初始化种群个数
d = 1 # 每个粒子的数据维度
ger = 100 # 迭代次数
limit = np.array([0, 50]) # 设置粒子运行的位置的限制
v_limit = np.array([-10, 10]) # 设置例子移动速度的上下值
w = 0.8 # 移动的惯性权重
c1 = 0.5 # 自学习因子
c2 = 0.5 # 群体学习因子
- 初始化种群位置
这里要解释下,为什么要用这个公式来初始化种群位置,我之前在我的SMOTE算法的介绍里介绍过这个公式,他的作用是确保所有种群中每一个粒子的初始位置都在我们设定好的搜索区域的范围内,np.random.rand其中numpy的这个方法生成的所有的数都是在0和1之间的,np.random.rand(N, d)生成的的其实是一个维度为
(
N
×
d
)
(N×d)
(N×d)的矩阵,其中所有的元素大小都为在0和1之间,这部分可能稍微难理解一点可以多停下多思考一些。
x = limit[0] + (limit[1] - limit[0]) * np.random.rand(N, d)
-
对于 x 1 , x 2 \quad x_1,x_2\quad x1,x2如果 λ ∈ [ 0 , 1 ] \lambda\in[0,1]\quad λ∈[0,1]则 λ x 1 + ( 1 − λ ) x 2 \lambda x_1+(1-\lambda)x_2\quad λx1+(1−λ)x2一定在 x 1 和 x 2 x_1和x_2 x1和x2的连线上,其中 λ x 1 + ( 1 − λ ) x 2 \lambda x_1+(1-\lambda)x_2 λx1+(1−λ)x2也可以转换为 x 2 + λ ( x 1 − x 2 ) x_2+\lambda(x_1-x_2) x2+λ(x1−x2)或者 x 1 + λ ( x 2 − x 1 ) x_1+\lambda(x_2-x_1) x1+λ(x2−x1)下图中 x 3 x_3 x3为 x 1 x_1 x1和 x 2 x_2 x2连接线上的一点,用初中的移项等知识就一定可以求到一个 λ \lambda λ。

-
初始化种群速度
种群位置好理解的化,这个就也很好理解了和上面的是一样的
v = np.random.rand(N, d) * (v_limit[1] - v_limit[0]) + v_limit[0]
- 初始化每个个体的历史最佳位置的缓存变量。
其实是我们单独需要一个变量来存储历史最佳位置,但是如果直接使用x_best_location = x,会导致两个变量的地址一致,修改一个就等于同时修改两个,因此需要加一个.copy 将数据拷贝到另一块地址,将x_best_loaction和x隔离开,避免后续更新的过程中出现混乱。
x_best_location = x.copy()
- 初始化用于保存个体最佳适应度的一个缓存变量。
因为我们的目标是找到最小值,也就是适应度的值越小我们认为适应度更优,发现适应度更优之后去更新粒子的个体最优适应度,所以我们把起始的所有的粒子的最优适应度都设置为无穷大,其实也是可以直接设置成初始函数值,不过那样会在初始化的时候多一步批量计算,直接设置成无穷大,也不影响计算结果。
x_best = np.ones(N) * np.inf
- 初始化全局最优适应度和全局最优位置
上面的理解了,下面的也就差不多一个道理
g_best = np.inf # 初始化全局最优适应度
g_best_location = None # 初始化全局最优解位置
- 定义一个空列表用于存储每一轮的结果,用于最后的绘图
iter_result = []
5.2迭代部分
for i in range(ger):
fx = f(x).reshape(-1) # 计算当前函数的适应度
better_indices = fx < x_best
x_best_location[better_indices] = x[better_indices]
x_best[better_indices] = fx[better_indices]
# 更新全局最优解
if np.min(x_best) < g_best:
g_best = np.min(x_best)
g_best_location = x_best_location[np.argmin(x_best)]
# 速度更新公式
r1 = np.random.rand(N, d)
r2 = np.random.rand(N, d)
v = w * v + c1 * r1 * (x_best_location - x) + c2 * r2 * (np.expand_dims(g_best_location, axis=0) - x)
# 粒子移动速度的边界约束处理
v = np.clip(v, v_limit[0], v_limit[1])
# 种群位置的更新
x = x + v
# 位置边界处理
x = np.clip(x, limit[0], limit[1])
iter_result.append(g_best)
首先,经过匿名函数输出fx之后,fx,的维度是N个1维向量(实际上出来的是2维),不是1个N维的向量,为了方便后面的计算,所以需要加一个.reshape(-1),把输出降成1维。
fx = f(x).reshape(-1)
然后这三个是个体最优适应度和个体最优位置,直接使用的是,numpy内置的索引功能,然后索引复制,有python基础的话,说到这应该能理解了,具体可以打断点然后单步调试一下,每个变量的变化。
better_indices = fx < x_best
x_best_location[better_indices] = x[better_indices]
x_best[better_indices] = fx[better_indices]
然后是更新全局最优解,这个就是基本的逻辑判断,np.argmin()的作用是返回一个数组中最小值的索引,然后x_best_location[np.argmin(x_best)]通过这个索引来获得全局最优的位置。
if np.min(x_best) < g_best:
g_best = np.min(x_best)
g_best_location = x_best_location[np.argmin(x_best)]
然后是速度更新,更新前先随机生成两个随机因子矩阵然后,更新速度的时候乘进去。
r1 = np.random.rand(N, d)
r2 = np.random.rand(N, d)
v = w * v + c1 * r1 * (x_best_location - x) + c2 * r2 * (np.expand_dims(g_best_location, axis=0) - x)
然后就是边界限制np.clip就可以直接对数组内的元素实现上下界约束的功能,比Matlab优雅多了。
# 粒子移动速度的边界约束处理
v = np.clip(v, v_limit[0], v_limit[1])
下面是位置更新,和约束,约束部分和上面同理。
# 种群位置的更新
x = x + v
# 位置边界处理
x = np.clip(x, limit[0], limit[1])
用列表记录这次迭代之后的最优结果。
iter_result.append(g_best)
最后是打印和绘图。
print("g_best_location", g_best_location)
print("g_best", g_best)
plt.plot(iter_result,'b')
plt.xlabel("Number of iterations")
plt.ylabel("Fitness")
plt.grid()
plt.show()
6.结束
虽然之前也接触过,不过这也是第一次完成的记录一个群智能优化算法的使用流程,之后估计在项目中也会用到,如果有需要看看自己再写一些其他的群智能优化算法。