人工智能咨询培训老师叶梓 转载标明出处
尽管通过人类反馈的强化学习(RLHF)在使LLMs与人类偏好对齐方面展现出潜力,但这种方法往往只会导致表面的对齐,优先考虑风格上的变化而非提升LLMs在下游任务中的表现。而且偏好的不明确可能导致模型对齐的方向模糊不清,而缺乏探索则限制了改进模型的有价值输出的识别。为了克服这些挑战,LG AI Research的研究者提出提出了一种新的框架——RLRF( RL from Reflective Feedback)。
方法
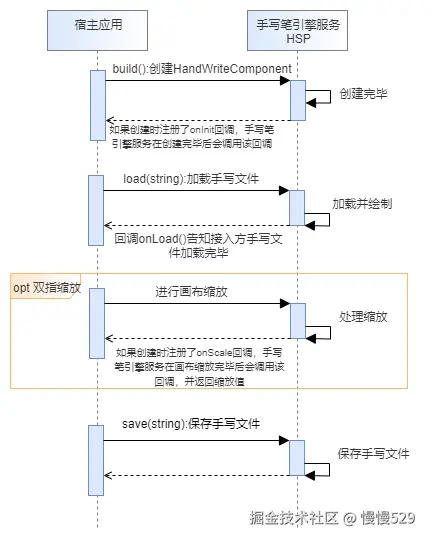
RLRF框架通过利用基于详细标准的细粒度反馈来改进LLMs的核心能力。该框架采用自我反思机制系统地探索和完善LLMs的响应,然后通过强化学习算法与有希望的响应一起微调模型。图1展示了RLRF框架的两个阶段:细致的自我反思阶段和RL微调阶段。在自我反思阶段,LLMs利用细致的反馈模型来搜索高质量的改进响应。在RL微调阶段,使用RL算法对LLM进行微调,利用这些改进的响应和它们的相关分数。

本文提出了一个细粒度反馈模型,它能够在多个方面的细粒度标准上评估大模型的回答。该模型定义了以下八个评估方面的细粒度标准,每个方面都有三个级别的评分标准:事实性、逻辑正确性、元认知、有洞察力、完整性、理解力、易读性、无害性。在定义评分标准时,专注于识别回答是否满足特定标准(分为成功、中等或失败)。为了专注于评估每个指令所必需的方面,反馈模型从整个方面集合中选择前3个相关方面,然后评估所选方面。最后,细粒度反馈模型fp使用所有方面的标准作为提示p,生成关于三个相关方面的反馈fp(x,y)。
为了解决探索受限的挑战,提出了一种细粒度自我反思,它可以在大量可用回答中有效探索高质量的回答。与其他通过温度基础采样探索多样化输出的方法不同,该方法鼓励通过利用大模型的自我反思能力进行有效探索,这种能力提供反馈并用它来改进自己。为了增强自我反思,使用反馈fp(x,yk)作为提示,它提供了模型错误背后的详细原因,促进了更有效的反思和改进。细粒度自我反思首先选择一个有希望的回答y˜进行改进。为了选择一个有希望的回答,为给定的指令x生成一组n个候选回答及其评估。然后,y˜被选为在候选回答中基于偏好的奖励最高的有希望回答。为了有效探索高质量的回答,通过执行自我反思生成m个改进,该自我反思读取反馈fp(x,y˜)并纠正y˜中的错误。
在最后阶段,通过DPO(Rafailov等人,2023)对语言模型(即,策略πϕ)进行微调,这是用于微调大模型的代表性强化学习算法之一。由于DPO直接从成对偏好数据集中优化策略,它需要以可比偏好的形式构建正面-负面对。使用整个数据集D = Dy ∪ Dz构建正面-负面对,这些数据集是从细粒度自我反思中生成的。首先,通过反馈分数将数据集分类为正面数据集D+和负面数据集D−。在D+中,选择最高奖励的top-k回答作为正面示例y+。对于1对1配对匹配,从D−中随机抽取负面示例y−,并丢弃没有正面集合的示例。最后,通过利用y+和y−作为成对数据集来优化DPO目标来微调语言模型。
图1总结了提出的框架的整个过程和细节。框架服务于迭代训练,在细粒度自我反思和RL微调之间交替进行。迭代训练流程首先通过细粒度自我反思阶段生成高质量的回答候选,然后利用这些回答在强化学习微调阶段对模型进行优化。通过这种方式,每一次策略更新都能在自我反思的基础上产生更好的回答,从而实现对模型的逐步改进。该过程一直持续到策略性能收敛,即模型输出的回答质量不再有显著提升为止。这种方法的优势在于能够充分利用模型的自我反思能力,通过不断的反馈和调整,提高模型对指令的响应质量和下游任务的性能。
想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具。实战专家1小时讲解让您轻松上手,学习如何使用 Llama Factory 微调模型。
评论留言“参加”或扫描微信备注“参加”,即可参加线上直播分享,叶老师亲自指导,互动沟通,全面掌握Llama Factory。关注享粉丝福利,限时免费录播讲解。
实验

表1 概述了训练数据集。实验起始于基础模型,对三个独立的模型(反馈模型、奖励模型和初始策略模型)进行了微调,使用了开源数据集以及从OpenAI API提取的额外自定义数据集。在强化学习微调期间,使用了以下三种类型的数据集:(1) 一般指令:ShareGPT,(2) 数学推理:GSM8K、MATH,(3) 事实性(Factuality)。
实验中使用了Llama-2-13b-chat作为基础模型。所有实验都在16个A100 GPU上进行,每个GPU拥有40 GB内存。将反馈模型和初始策略模型的微调学习率设置为2e-5(恒定),DPO的学习率设置为2e-6(余弦衰减)。在DPO微调中,设置β = 0.1。在自我反思阶段,将探索的最大样本数限制为n + m = 30,其中n是Dy的大小,m是Dz的大小。在实验中,选择了最佳的(n = 10, m = 20)组合。
在实验中,选择了最先进的大模型作为比较基准,包括GPT-4-0613、GPT-3.5-turbo-0301和Llama-2-70b-chat。作为RLHF基线,仅使用奖励模型而不使用反馈模型,在Dy中选择最高奖励的正例和随机负例进行学习。作为DPO使用正例和负例的替代方法,可以仅对正例集进行监督微调,称为拒绝采样(Rejection Sampling,RS)。
为了衡量RLRF在多方面的效果,进行了Just-Eval实验,用于GPT-4的细粒度评估。这个基准测试包括来自多个数据集的1000条指令,如AlpacaEval、MT-bench、LIMA、HH-RLHFredteam和MaliciousInstruct。这个基准测试为每个示例提供了任务类型和主题类别,可以对不同类别进行全面分析。在Just-Eval中报告了四个指标:总体(六个方面的平均值)、有用性、深度、事实性、数学(数学问题上的有用性)。
为了评估大模型的任务特定能力,在两个任务上测试了模型:事实性(传记生成)和数学推理任务。按照之前工作的方法,计算了模型回答的FactScore(给定指令“告诉我关于[人]的传记”)。FactScore计算回答中正确和不正确事实的比率。从Wikipedia中提取了10.2k个人名(10k用于训练集,200个实体用于测试集)。对于数学推理,测量了GSM8K测试集上的准确率。虽然其他方法(如Zhao等人,2023;Imani等人,2023)设计用于数学推理的少量样本或链式思考(CoT)提示以提高性能,但实验是在零样本设置下进行的,没有这样的额外提示。

表2 显示了在Just-Eval、FactScore和GSM8K上的主要结果。结果表明,使用DPO和拒绝采样(RS)的RLRF框架从M0到M2改进了整体任务的性能。特别是在FactScore和Math Accuracy方面,该方法逐步提高了性能而没有达到饱和。另一方面,GPT-4在M1的Just-Eval性能饱和,显示出模型在DPO微调过程中的过拟合倾向。比较DPO和RS,DPO在事实性任务上有效提高了性能,而对超参数敏感。RLHF基线略微提高了Just-Eval得分,而在FactScore和Math accuracy方面性能没有提高或略有下降,表明通过基于偏好的奖励的RL无法提高大模型的能力。

为了探究反馈和奖励模型在两个任务上生成回答的成功或失败的检测效果,随机抽取了事实性和GSM8K测试集上的回答,然后根据回答的正确与否进行分组。由于FactScore的范围是0到100%,通过得分的前30%和后30%进行分组。图2 和 图3 显示了正确和不正确示例的奖励和反馈得分的分布。在GSM8K中,奖励模型未能区分正确和不正确的样本,而反馈模型(带参考)很好地捕捉到了它们的正确性。这一发现意味着,仅基于偏好的奖励模型在数学等推理任务中的RLHF可能导致表面对齐。另一方面,与预期相反,奖励模型在事实性任务中表现良好,区分了更具事实性和较不事实性的回答。然而,当没有提供参考(Wikipedia)时,反馈模型未能很好地检测到事实性,尤其是在底部30%的事实性回答中。可以观察到,当没有参考知识可以利用时,基于偏好的奖励模型可以是更好的代理。
由于抽样多样化输出需要大量的计算,因此研究采样过程中每个步骤的资源效率并相应分配资源至关重要。研究了在回答(y)、反馈(fp)和改进回答(z)上变化样本数量对Just-Eval的影响。当改变特定元素的样本数量时,将其他元素的样本数量固定为n=1。图4 显示了Just-Eval上的平均评分(按方面设置)。观察到抽取更多的回答y(即,增加Dy的大小)对性能影响最大,而抽取多样化的反馈fp只显示了轻微差异。基于这一结果,选择为每对(x,y)生成一个反馈样本。

图5 显示了模型在Just-Eval数据集(平均1000个示例)上的平均输出令牌长度。在DPO微调(M0 → M1 → M2)期间,平均长度逐渐增加,而拒绝采样微调略微减少了令牌长度。

GraphiT模型的提出为图结构数据的表示和分析提供了新的可能性。通过在变换器架构中编码图的结构信息,GraphiT不仅在性能上超越了现有的GNNs模型,还提供了一种直观的模型解释方法。
论文链接:https://arxiv.org/pdf/2403.14238