背景
如果要在开发、运维和工程层面持续改进一个涉及多服务的应用,以链路追踪、日志检索、指标收集、用户体验监测、性能剖析、关联分析等作为代表性技术的可观测性必不可少,这一看法已成为共识,但在采用这项技术的过程中,如何分析相关数据对很对人来说任然存在一些困难和误区,本文尝试通过几个浅显的例子说明分析链路追踪数据时会遇到的一些问题,并不会严谨论述相关概念。
示例应用
本文采用一个部署在 K8s 的前后端分离应用 RuoYi-Vue 作为案例介绍相关议题,应用拓扑如下:
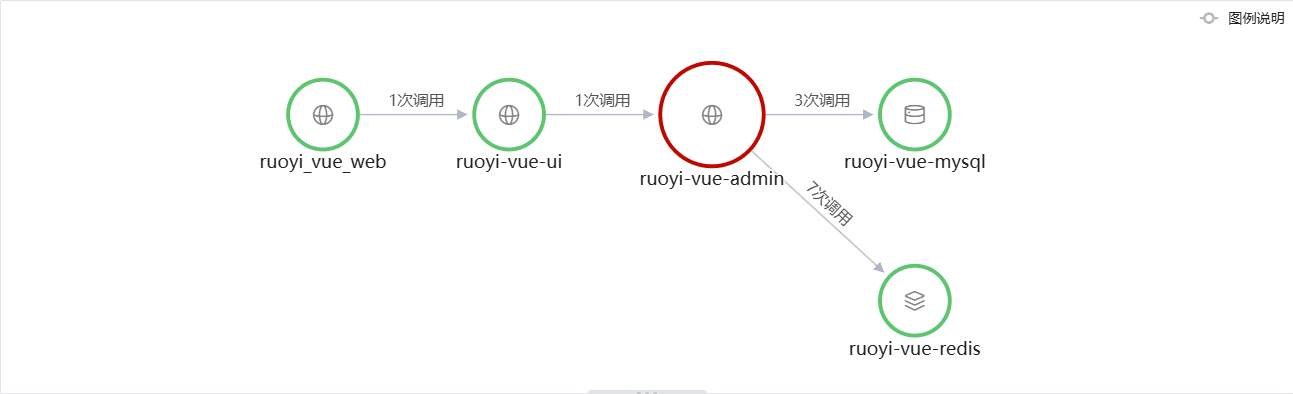
各个组件介绍如下:
- ruoyi_vue_web,WEB SPA 应用,用户通过浏览器访问,引入观测云用户体验监测 SDK;
- ruoyi-vue-ui,前端应用,Vue 框架,运行于 Nginx,引入 DataDog ddtrace 探针;
- ruoyi-vue-admin,后端应用,SpringBoot 框架,引入 DataDog ddtrace 探针;
- ruoyi-vue-mysql,持久存储;
- ruoyi-vue-redis,缓存;
观测云作为一个数据平台,支持接入市面上主流的开源探针,并将数据转换为观测云定义的规范,指出这一点的原因是,不同探针在链路传播细节、Span 粒度上存在差异,本例将遵循 DataDog ddtrace 探针的 Span 粒度设定。
实验场景
我们将分析示例应用在用户登录过程中产生的追踪信息,用户视角的具体操作为:
- 浏览器访问应用;
- 输入用户名、错误密码和验证码;
- 点击登录按钮;
- 输入用户名、正确密码和验证码;
- 点击登录按钮;
基本概念
当我们以用户视角执行实验场景中指出的操作时,整个过程产生以下 Trace:
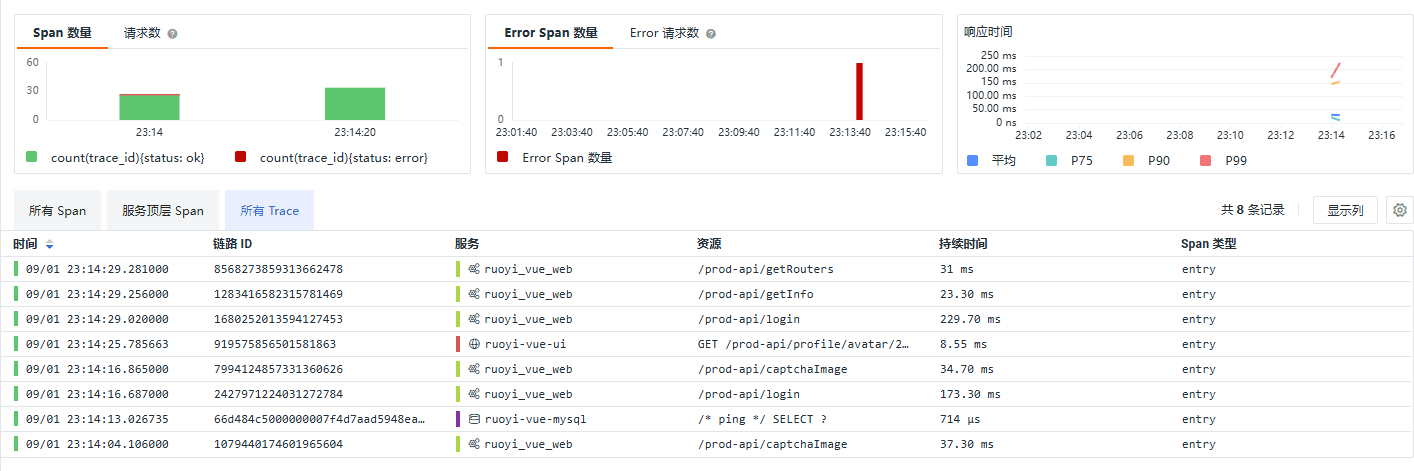
它们并不能全部映射到用户在浏览器上的每一次操作。实际上,Trace 是一个事务,这就意味着它有一个明确的开始,可能还具有一些可拆分的细节,在传统的链路追踪中,将从对某后端接口的调用开始追踪,假设一个登录接口作为事务的开始被调用,那么查询会话缓存、验证密码等都将作为这个事务的细节,直到该登录接口定义的逻辑被全部完成时事务结束(错误终止也是逻辑的一部分),这些细节在追踪中被称为 Span,具备明确的开始和结束时间,显然,第一个 Span 就是对登录接口的调用,被称为 Root Span,以图形化的语言简单描述 Trace 和 Span 的关系如下:
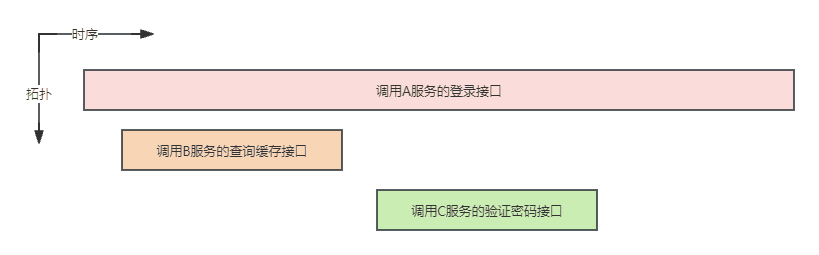
简单分析可知,追踪体系中包含以下维度:
- Trace 中涉及的服务;
- 不同 Span 的执行时序,表现为横轴;
- Trace 中 Span 的拓扑结构,表现为纵轴;
时序方面比较容易理解,它的挑战在于无法跨基础设施维持时间同步,因此引入了拓扑来描述 Trace 的结构,具备相同 Trace ID 的 Span 之间通过父子标识进行关联,即每个 Span 除自身的 Span ID 外,还包含其父级 Span 的 ID,当某个 Span 的父级 Span ID 为 0 时,它将被认为是整个 Trace 的开始,即 Root Span,但 Root Span 并不作为一种 Span 的类型存在,而是被视为父级 Span ID 为 0 的 Entry Span,Entry Span 是调用进入某个服务时的第一个 Span,即观测云界面中的顶层 Span,我们将在后续的分析实践中详细说明这些问题。
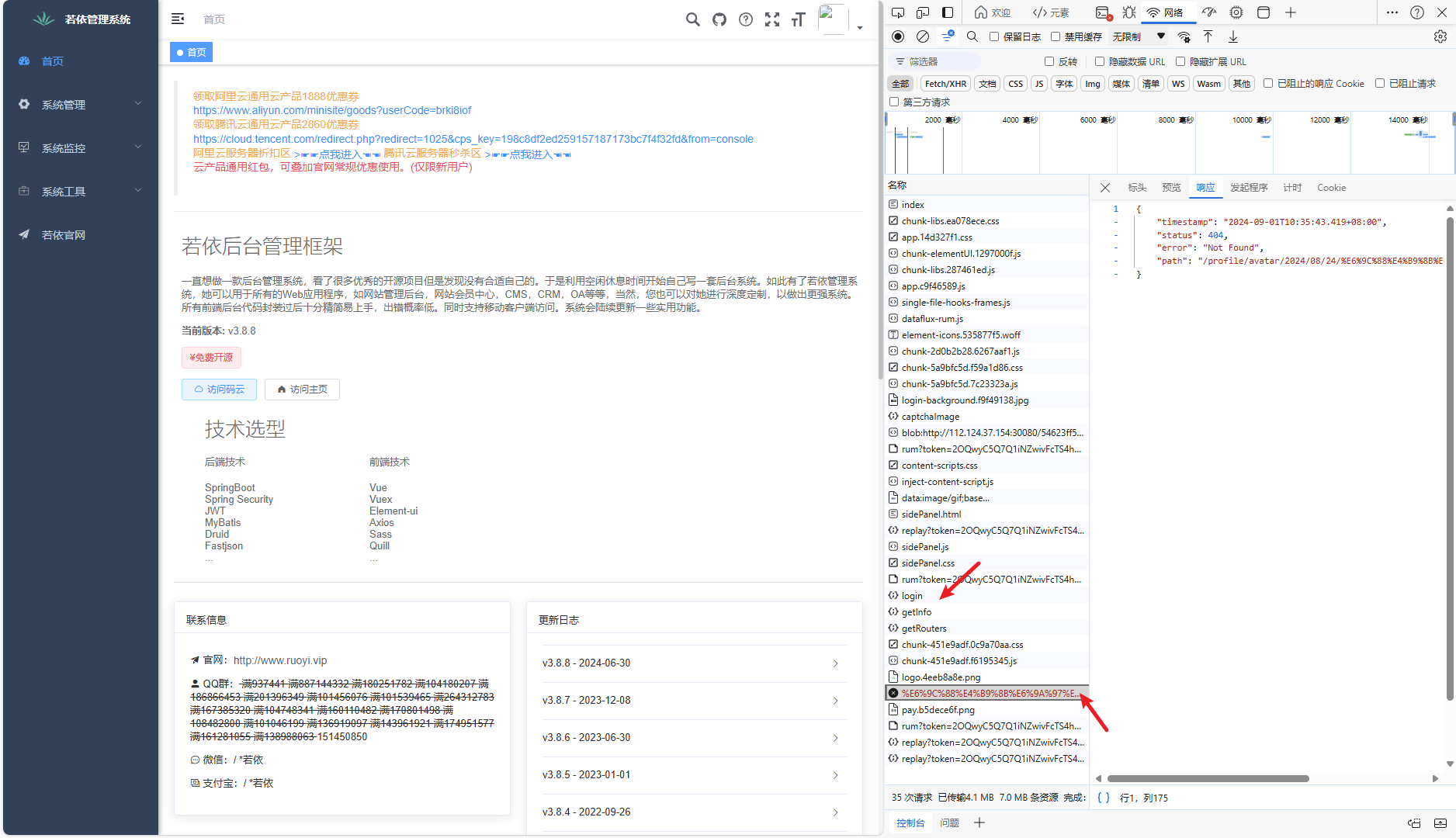
本场景的不同之处在于,追踪的起始点前移至 WEB 应用,用户在页面的点击、浏览器运行 js 程序、前端应用逻辑执行等都可能触发接口调用作为链路的起始点,比如 Trace 列表中资源名为“GET /prod-api/profile/avatar/2024/08/24/月之暗面_20240824210241A001.jpg”的 Trace 就是由前端应用的逻辑触发的,它完成了获取用户头像的行为,其他 Trace 在浏览器端触发。
我们已经基本讨论完了 Trace 内 Span 的顺序问题,接下来讨论下 Trace 之间的顺序问题,系统的真实行为是按照前文 Trace 列表中的顺序发生的吗?可以看到获取用户头像竟然提前到了成功登录之前,其实这并不是一个安全漏洞,原因之前已经提到,获取用户头像是前端应用发起的链路,而其他是浏览器发起的链路,当浏览器与前端应用所在服务器的时间不同步时就会出现这种混乱的情况,这并不是链路追踪应该解决的问题,实际上也很难解决,通过更丰富的上下文降低判断这种情况下 Trace 顺序的难度是一种解决方案,不再展开。那么真实的顺序是怎样的呢,RuoYi-Vue 是一个开源项目,相关逻辑在文件 ruoyi-ui/src/store/modules/user.js 中:
...
GetInfo({ commit, state }) {
return new Promise((resolve, reject) => {
getInfo().then(res => {
const user = res.user
const avatar = (user.avatar == "" || user.avatar == null) ? require("@/assets/images/profile.jpg") : process.env.VUE_APP_BASE_API + user.avatar;
...
可知,获取用户头像发生在“/prod-api/getInfo”之后,如果用户头像为空则使用静态资源中的默认头像。从浏览器开发者工具的输出中很容易发现这些行为发生的正确时序:
链路分析
在这个章节,我们将具体分析实验场景中的一些 Trace,除了使用真实数据验证基本概念中的内容,还会说明一些数据分析过程中容易产生的困惑。
前端服务向后端服务请求用户头像
先从获取用户头像的过程说起,这是一则获取用户头像失败的例子,当 ruoyi-vue-ui 请求头像图片时,返回了 404 响应码,我们分析一下这个过程。
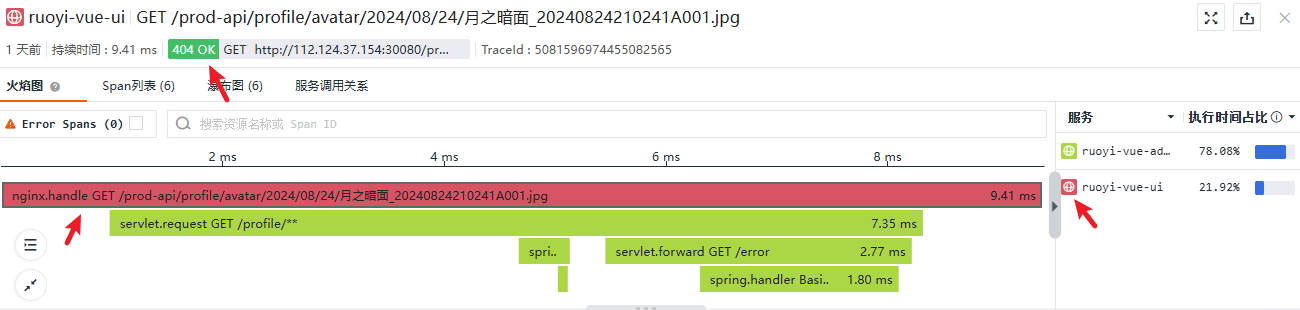
此 Trace 涉及两个服务,ruoyi-vue-ui 使用 HTTP 方式向 ruoyi-vue-admin 请求头像图片,Root Span 在 ruoyi-vue-ui 创建,它的状态被标记为绿色的“404 OK”,需要注意的是, Span 被填充为红色与 404 或任何错误无关,只是用于区分不同的服务。熟悉 HTTP 的人知道,404 意味着一个客户端错误,请求了一个不存在的资源,既然是错误,为什么会显示为“404 OK”,这与通常的“200 OK”在直觉上相悖,我们需要分析这个 Span 的细节,可以将 Span 在形式上简单理解为一个 Json,观测云界面的“链路详情”页签显示了它,摘取一些本例中需要的关键信息:
{
"service": "ruoyi-vue-ui",
"resource": "GET /prod-api/profile/avatar/2024/08/24/月之暗面_20240824210241A001.jpg",
"http_status_code": "404",
"http_status_group": "4xx",
"trace_id": "5081596974455082565",
"parent_id": "0",
"span_type": "entry",
"span_id": "5081596974455082565",
"status": "ok",
"operation": "nginx.handle",
"message": {
"meta": {
"component": "nginx",
"nginx.worker_pid": "29",
"upstream.name": "ruoyi-vue-admin.ruoyi-vue",
}
}
}
可以看到,请求资源、HTTP 响应码等以键值对的形式存在于 Span 中,span_id 指当前 Span 的 ID,由于它是进入 ruoyi-vue-ui 服务的第一个 Span,所以它被标记为 entry 类型,parent_id 指当前 Span 的父级 Span,为 0 表示当前 Span 是整个链路的 Root Span,status 字段表示了当前 Span 的状态,ok 代表此 Span 未发生错误。
实际上,观测云界面显示的“404 OK”是 HTTP 响应码和 Span 状态的组合,他们并不存在冲突,关键是理解两种状态的含义和习惯用法,当服务端返回 404 时,只是在按照约定向客户端报告没有找到相关的资源,这可能是因为资源被意外删除(本文所示的情况),也可能是因为请求的资源路径存在错误,无论如何,习惯上服务端不会为 404 抛出异常,这也是 SpringBoot 的默认行为,实际上抛出错误时的栈追踪是要付出一定成本的。不过这种页面标记并不影响我们为 404 配置告警规则。
看下一个 Span:
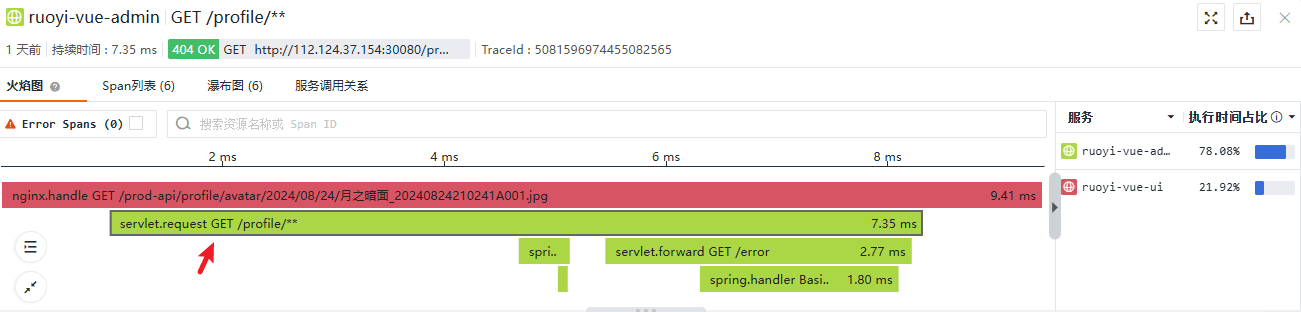
照例,从链路详情页签中摘取一些关键信息:
{
"service": "ruoyi-vue-admin",
"resource": "GET /prod-api/profile/avatar/2024/08/24/月之暗面_20240824210241A001.jpg",
"http_status_code": "404",
"http_status_group": "4xx",
"trace_id": "5081596974455082565",
"parent_id": "5081596974455082565",
"span_type": "entry",
"span_id": "3515512906328470393",
"status": "ok",
"operation": "servlet.request",
"message": {
"meta": {
"component": "tomcat-server",
"thread.name": "http-nio-8080-exec-40",
}
}
}
可以看到,当前 Span 是 ruoyi-vue-admin 服务的顶层 Span,Servlet 分配线程 http-nio-8080-exec-40 来完成请求,它的 parent_id 指向上一个 Span。
继续向下看,Span 的粒度不止于服务,而是深入了线程内部的细节:
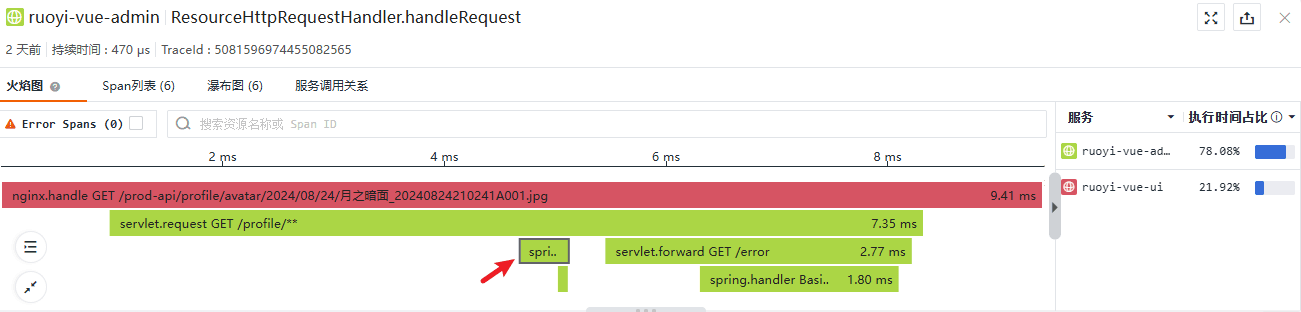
{
"service": "ruoyi-vue-admin",
"resource": "ResourceHttpRequestHandler.handleRequest",
"trace_id": "5081596974455082565",
"parent_id": "3515512906328470393",
"span_type": "local",
"span_id": "338096583765508850",
"status": "ok",
"operation": "spring.handler",
"message": {
"meta": {
"component": "spring-web-controller",
"thread.name": "http-nio-8080-exec-40",
}
}
}
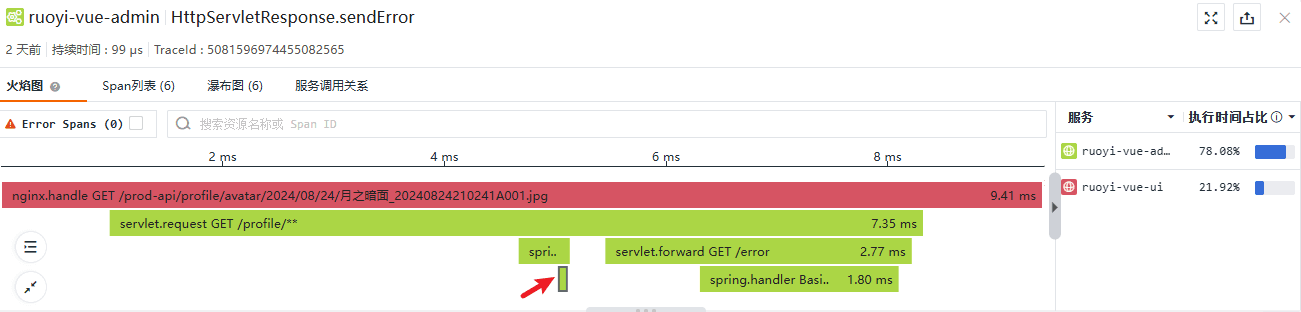
{
"service": "ruoyi-vue-admin",
"resource": "HttpServletResponse.sendError",
"trace_id": "5081596974455082565",
"parent_id": "338096583765508850",
"span_type": "exit",
"span_id": "3996052880274433699",
"status": "ok",
"operation": "servlet.response",
"message": {
"meta": {
"component": "java-web-servlet-response",
"thread.name": "http-nio-8080-exec-40",
}
}
}
可以看到,线程内非入口或末端的 Span 被标记为 local 类型,末端 Span 被标记为 exit 类型。我们不再详细查看剩余的两个 Span,他们实质上指出了 SpringBoot 将 404 错误返回为一个 Json 的处理过程,在基本概念章节的浏览器开发者工具截图中已经体现了这个 Json。
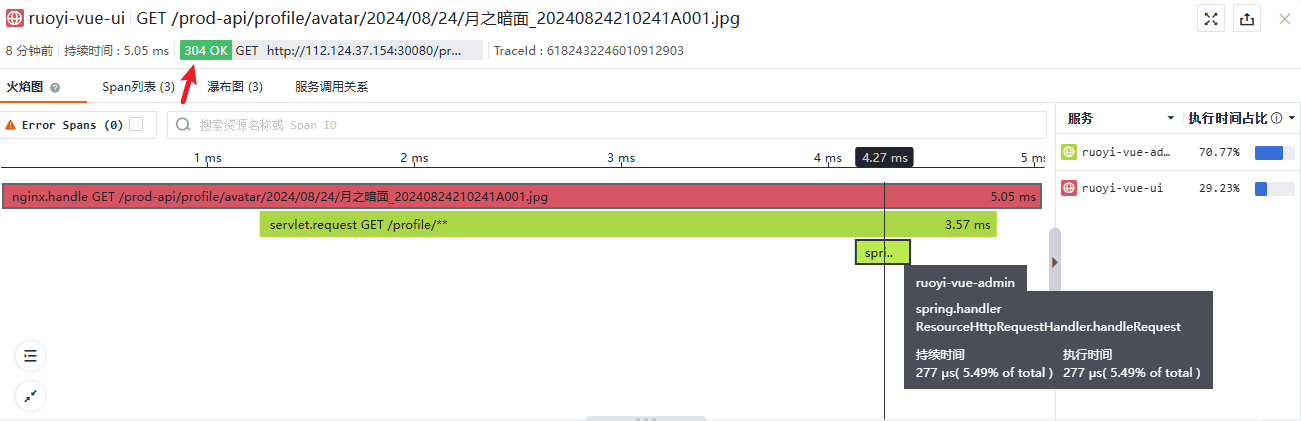
本节的最后,再来看下能够正常获取头像的两种情况:
1、客户端缓存了头像的图片资源,携带缓存资源的最后更新时间请求服务端,服务端发现缓存资源任然是最新的,响应码是 304,告知客户端使用缓存的资源:
2、客户端缓存的资源已被更新,返回更新后的资源,响应码是 200:
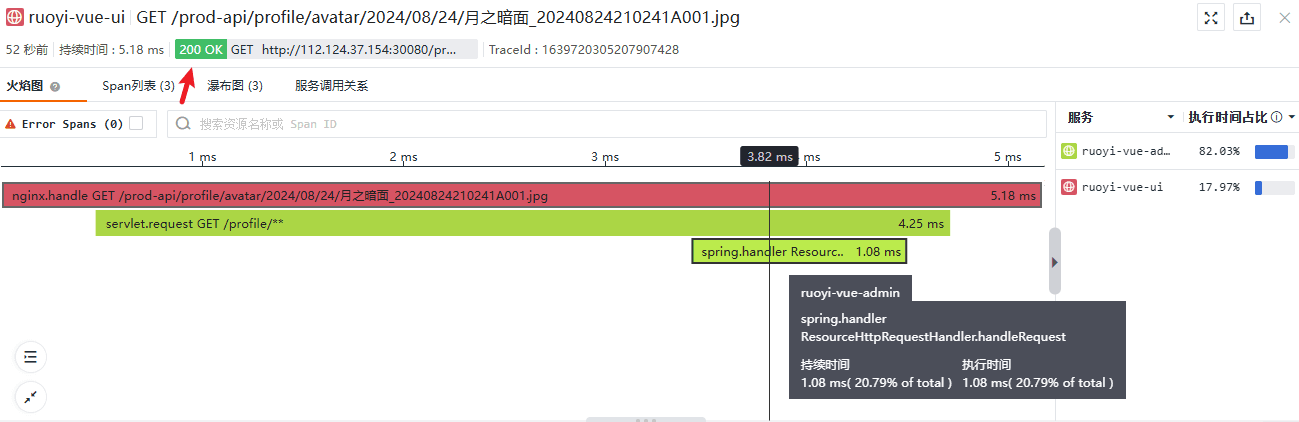
完成对这个 Trace 的分析后,一个重要的结论是:我们可以通过追踪了解请求在服务间和服务内触发的行为,并能获得过程中性能相关的统计数据,细致程度有赖于 Span 的粒度,不过越细的粒度就要付出越多的性能成本,权衡这种付出和收益是组织采用链路追踪技术时的考虑点之一。对于开发和运维角色来说,追踪的锋芒才刚刚展现。
使用错误的密码登录
接下来我们看一个更加复杂的 Trace,它的复杂性体现在以下几个方面:
- 由用户在浏览器中的应用界面触发;
- 对 Redis 和 MySQL 有多次调用;
- Redis 和 MySQL 中并未引入探针;
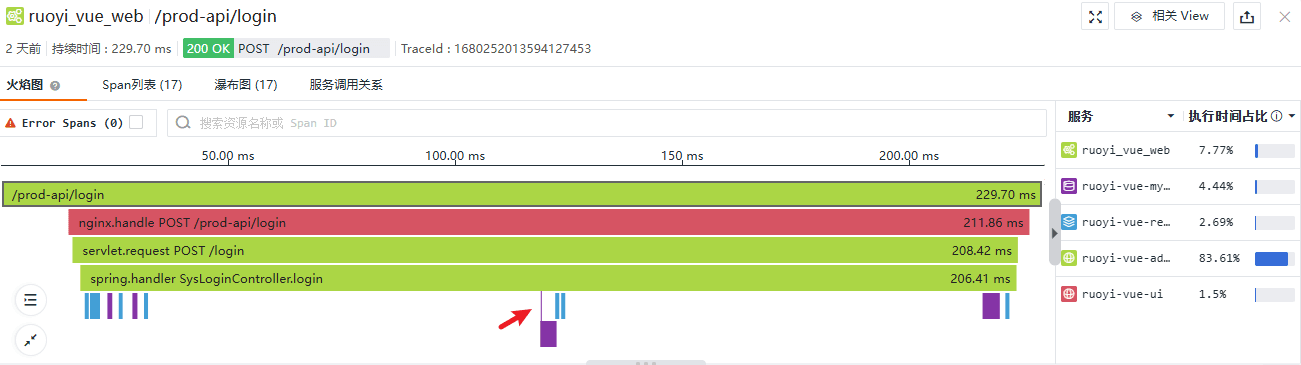
我们将使用多种视图进行链路分析。火焰图快速揭示了一个完整的用户登录过程:
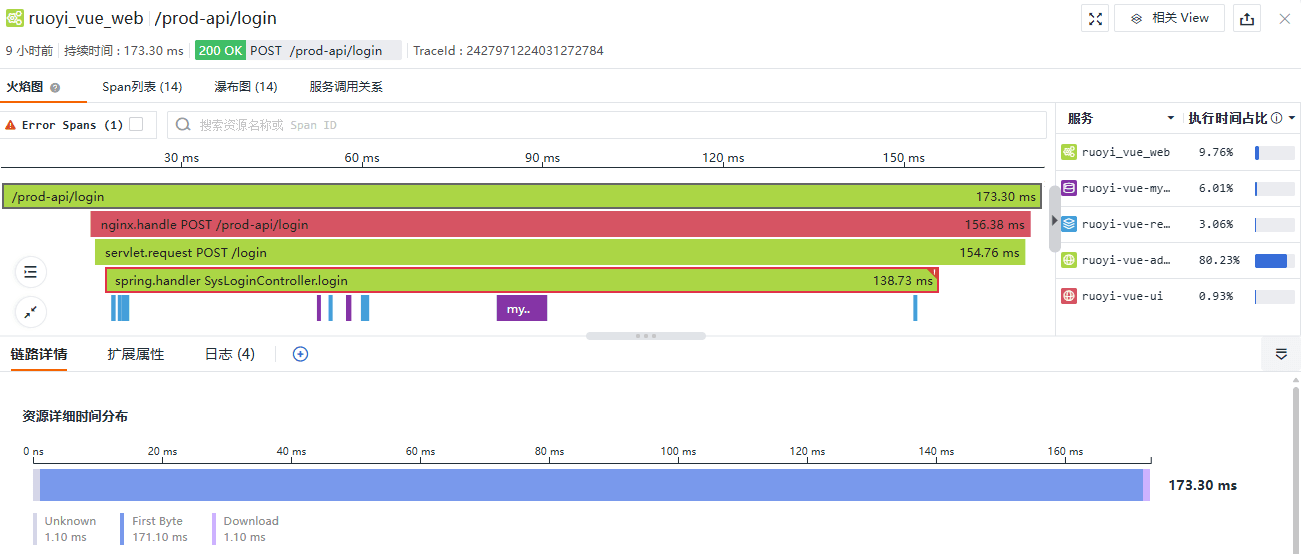
Trace 从前端 WEB 应用 ruoyi_vue_web 开始,经过了 WEB 服务器 ruoyi-vue-ui、后端服务 ruoyi-vue-admin,后端服务多次调用缓存 ruoyi-vue-redis 和存储 ruoyi-vue-mysql,校验用户名和密码的 Span 被标记为错误 Span。此例 Root Span 与上例最大的不同是下方显示了浏览器端资源加载的时间分布,例如建立连接用时、返回数据等待用时等,该 Span 包含了从前端收集的众多信息。
直接分析请求进入后端的入口 Span:
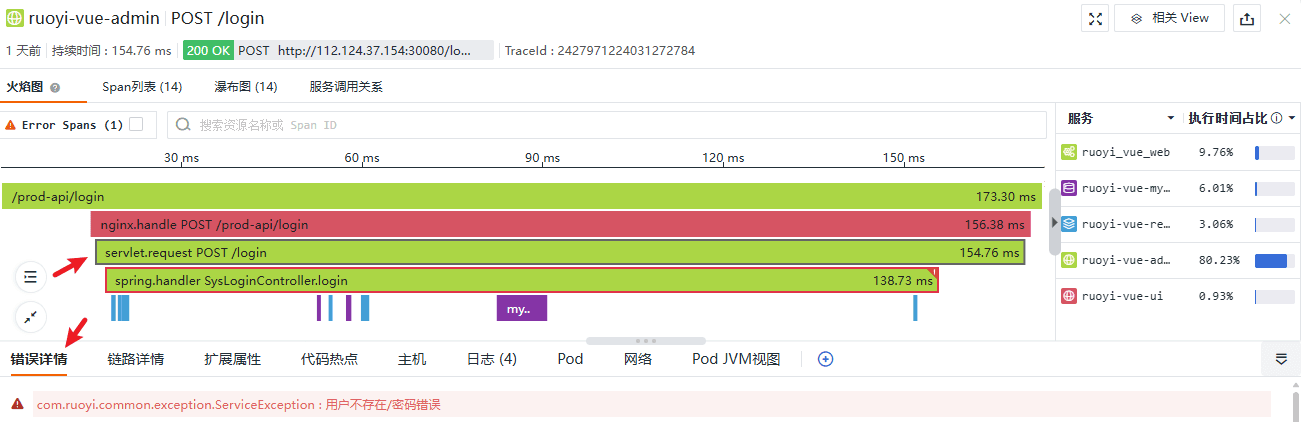
点击该 Span,下方的标签页新增“错误详情”页签,但该 Span 并未被标记为错误,实际上当前 Span 和后续 Span 都是在同一个线程内发生的,所以线程内其他 Span 的异常会抛出到栈底,也就是当前 Span 这里,真实的错误发生在下级 Span:
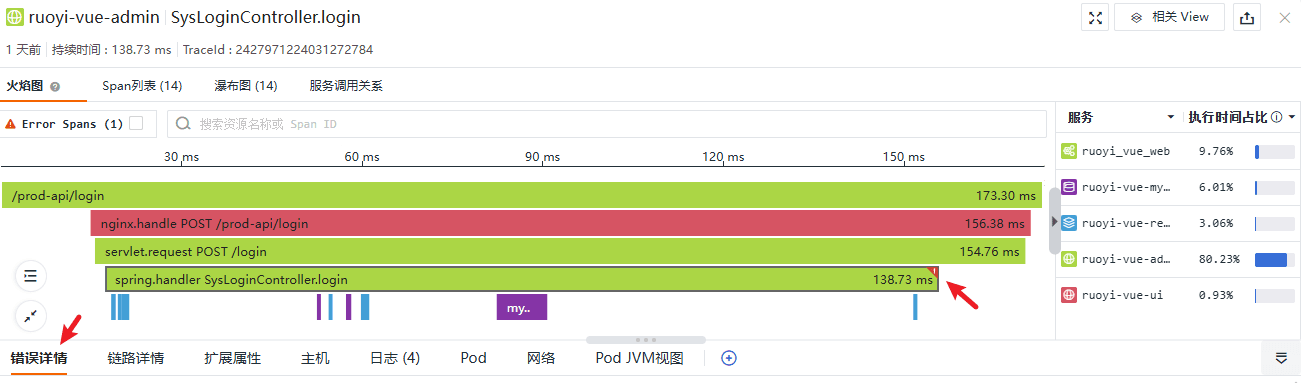
在这个 Span 的链路详情中 status 的值是 error,页面上也做了明显的标记。
以上过程包含了另外一种常见的误解,即用户密码校验环节后端报错,API 响应体中包含的错误码为什么没有体现在 Span 中:
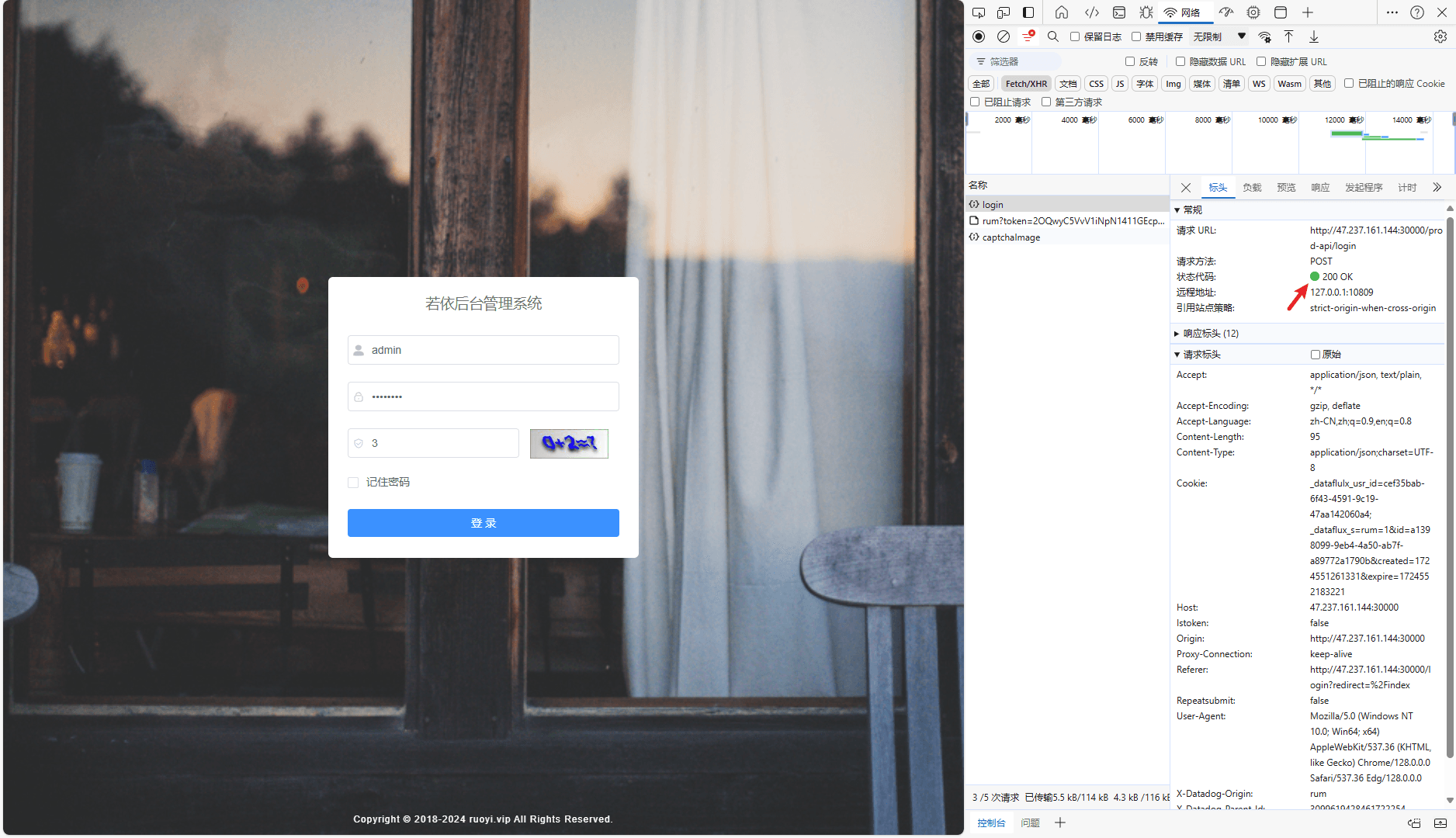
HTTP 返回码 200
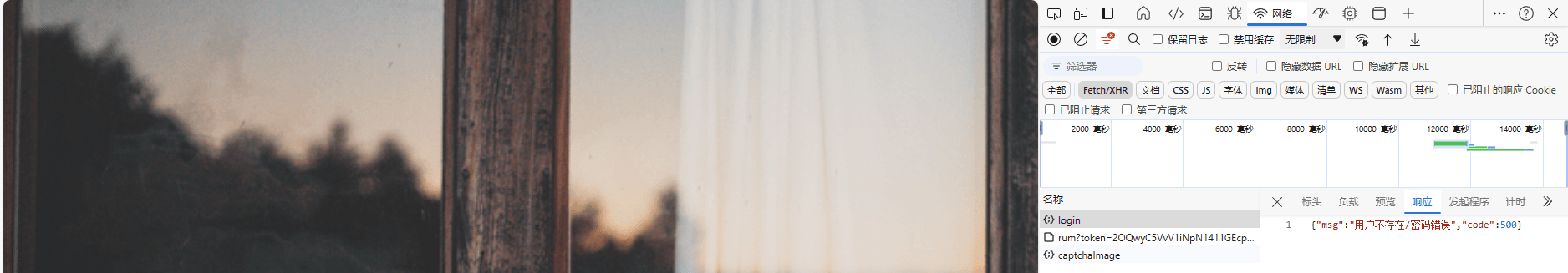
应用返回码 500
这种困惑实际上来自程序设计本身,在 Restful API 设计的过程中错误的使用了 HTTP 响应码,Restful 建议的、符合直觉的使用方法是 HTTP 响应码与应用响应码表达一致的含义,套用到这里就是后端用户名密码校验发生错误时,HTTP 响应码应该是对应此事件的 5xx,而不是 200,这样就可以通过 HTTP 响应码观测后端的错误情况,所以这并不是追踪系统的问题,应用程序设计应该避免混淆 Restful 与 HTTP,采用最佳实践,如果要在 Trace 中观测这种错误,可以分析 Sapn 中的 error_message 字段,以观测云界面的快速分析为例:
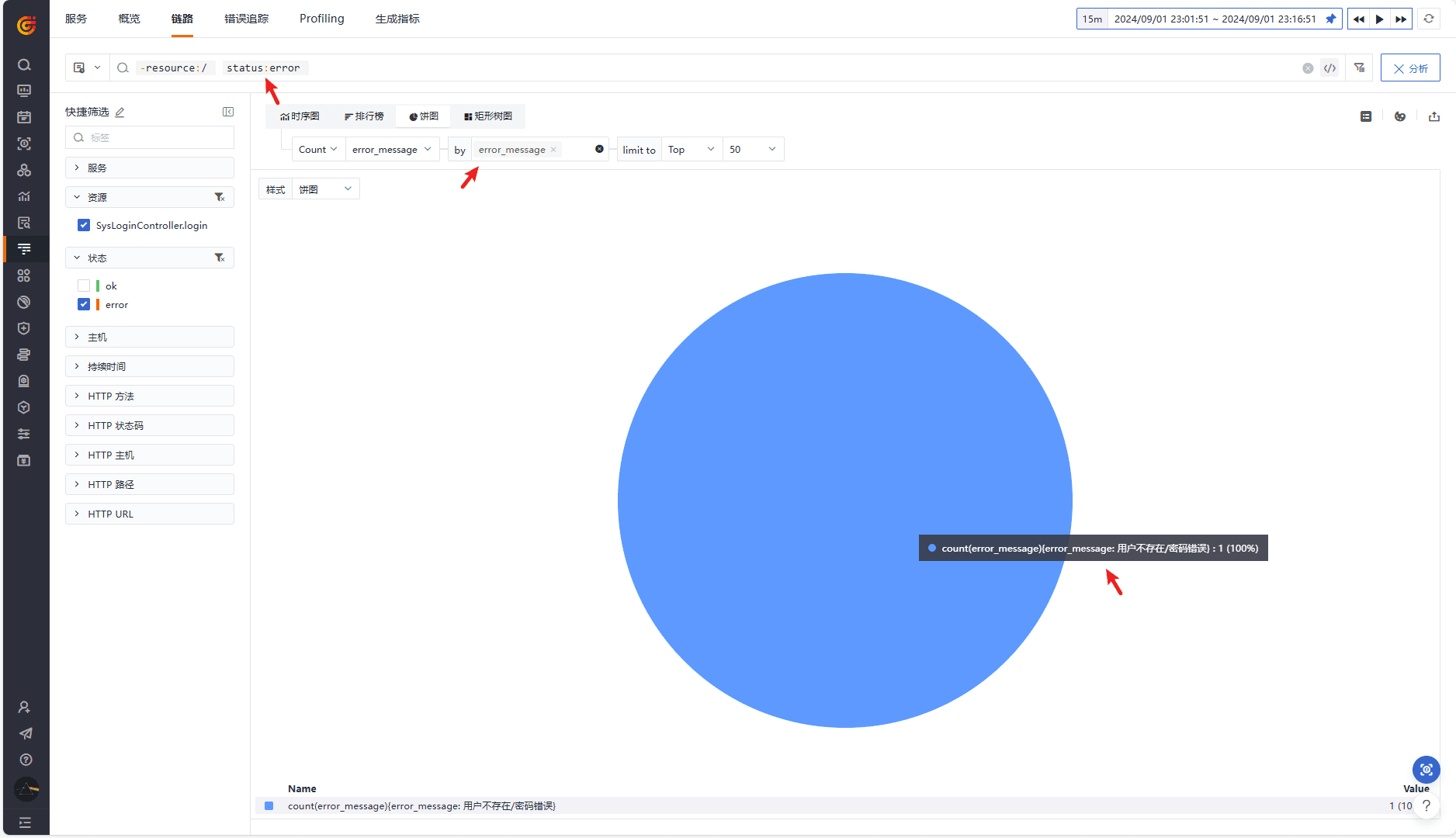
继续分析这个错误 Span,可以看到在校验密码的过程中程序以顺序的方式多次调用了 Redis 与 MySQL,如果需要查看更多的细节,火焰图并不能提供更多的支持,此时可切换到瀑布图,它提供了更多的细节:
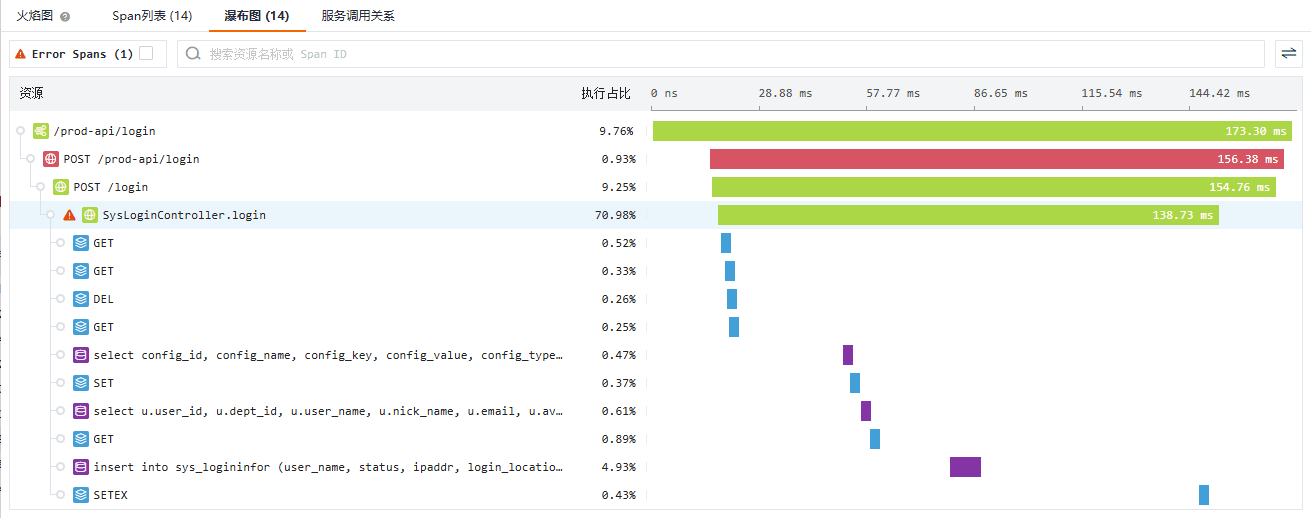
在这个视图里可以更清晰的看到:
- 串行还是并行;
- 并行的具体情况,例如并行数量;
- 不同调用之间的间隔时间;
- 执行的具体操作,例如执行的 Redis 命令和 MySQL 查询;
以上信息可以帮助我们洞察程序执行的细节,持续优化性能问题。如果我们想要了解当前 Trace 中的黄金指标:调用量、耗时和错误,可以切换到服务调用关系:
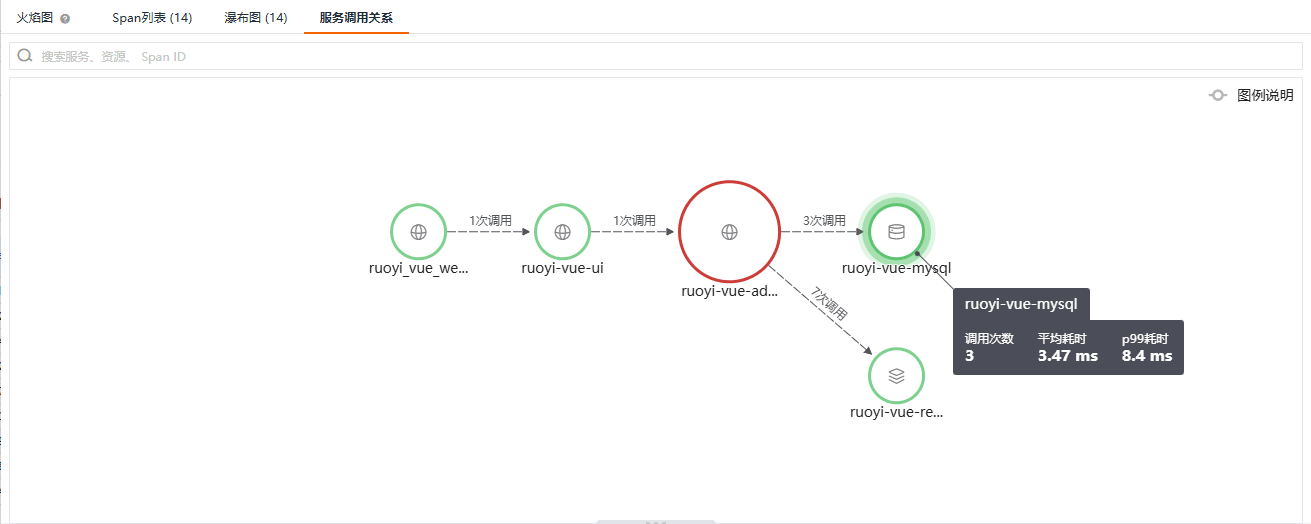
像前一个例子一样,我们来对比下密码正确时正常登录的情况:
可以看到这里指出了一个异步执行:向 MySQL 中插入登录日志。摘取链路详情中的关键信息可以看到:
{
"base_service": "ruoyi-vue-admin",
"service": "ruoyi-vue-mysql",
"resource": "insert into sys_logininfor (user_name, status, ipaddr, login_location, browser, os, msg, login_time) values (?, ?, ?, ?, ?, ?, ?, sysdate())",
"message": {
"meta": {
"thread.name": "schedule-pool-11",
"component": "java-jdbc-prepared_statement",
}
}
}
与其他访问 MySQL 步骤的 thread.name 不同,不再是其父级 Span 的 http-nio-8080-exec-73 而是 schedule-pool-11。
接下来,我们提出本例中的最后一个问题,Redis 和 MySQL 中并未引入追踪相关的组件,我们如何发现这些调用并且收集相关服务的 Span 呢,这就要依赖探针自身的技术栈集成能力了,简单说就是探针支持了应用程序中访问 MySQL 和 Redis 的库,当应用程序调用这些库时相关的数据就会报告为默认服务名的追踪信息,我们需要把默认服务名映射为应用架构中规范的服务名,例如将 mysql 映射为 ruoyi-vue-mysql,上述链路详情中的 base_service 和 service 说明了这种情况,base_service 指出了引入探针的位置。
创建 MySQL 连接
这个例子我们来说明一个不在应用逻辑中定义的 Trace:
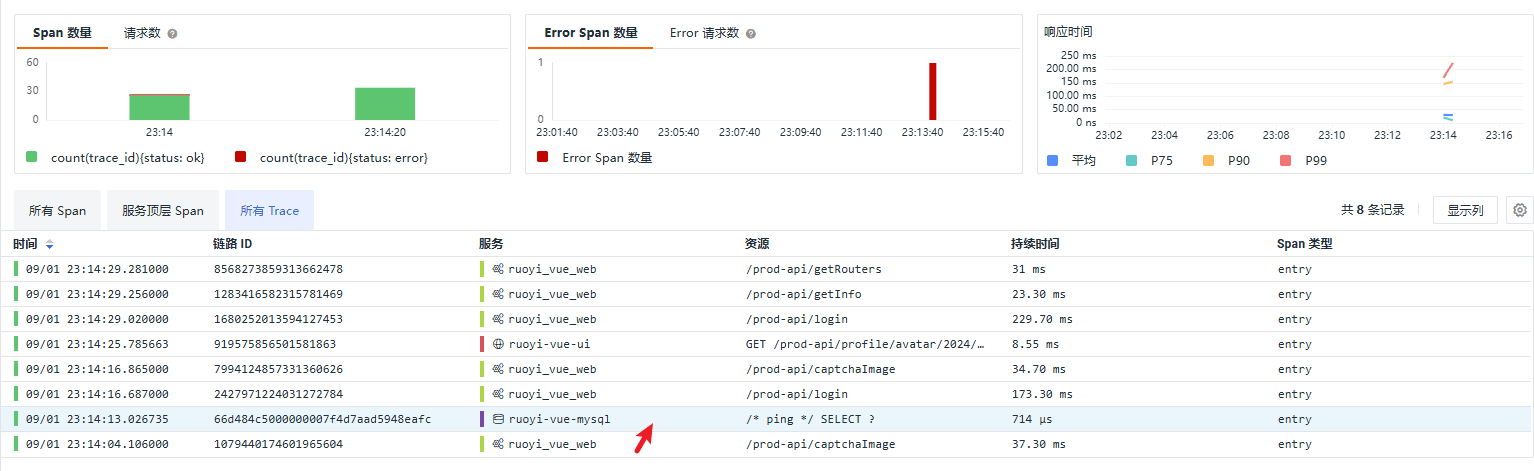
Trace 位置
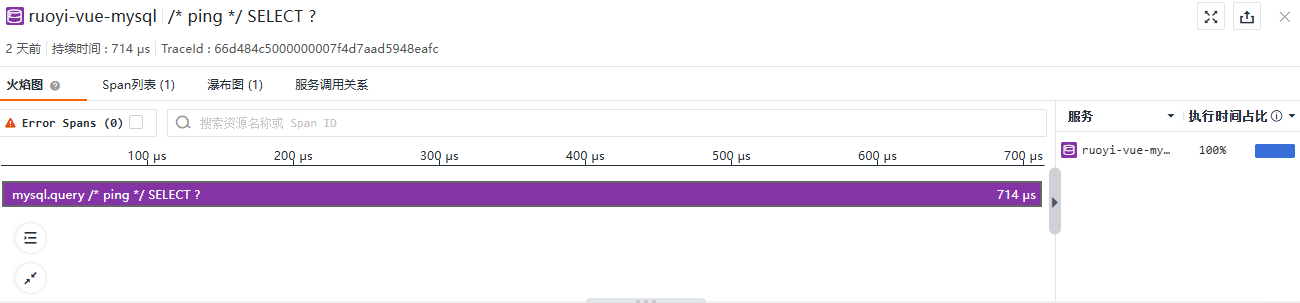
Trace 详情
它只包含一个 Span,从链路详情中的线程名称 Druid-ConnectionPool-Create-75483598 可知,这似乎是 Druid 创建连接的行为,它的 parent_id 为 0,实际上 Span 的连接有赖于跟踪上下文的传播,也就是说,在一个连接父子 Span 的 Trace 中,子 Span 在创建时至少知道父 Span ID,否则 Span 的 parent_id 被置为 0,它也就作为一个 Trace 的 Root Span 出现了,本例就是这种情况。Druid 作为底层的 JDBC 组件库,我们就不再细究其中的细节了。
补足追踪中缺少的细节
从前面提到的几个例子可以看出,追踪为我们进行性能分析提供了脉络,但要说清楚其中的细节仍然是困难的,这至少包含几个方面,例如程序中的调用栈、程序运行态的一些信息、网络连接、基础设施、日志情况等,值得高兴的是,目前的技术发展方向已经能够在这些方面提供很好的支持,观测云通过接入 Profilling 和 eBPF 网络数据来填充这些空隙。以前面的成功登录过程为例,在统一视图内查看代码热点的详情信息:
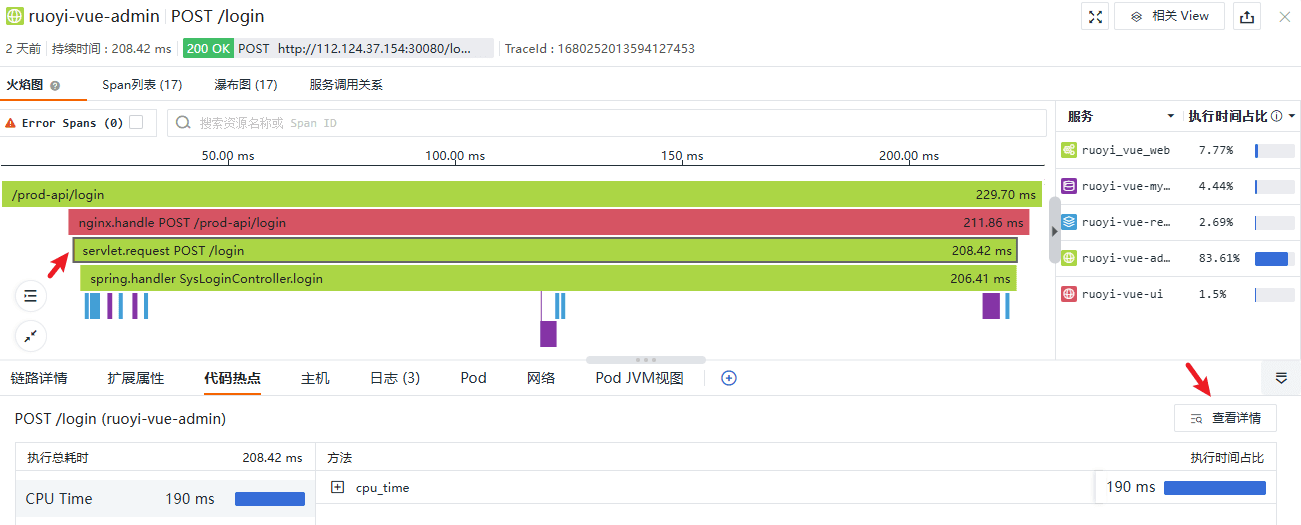
代码热点概览
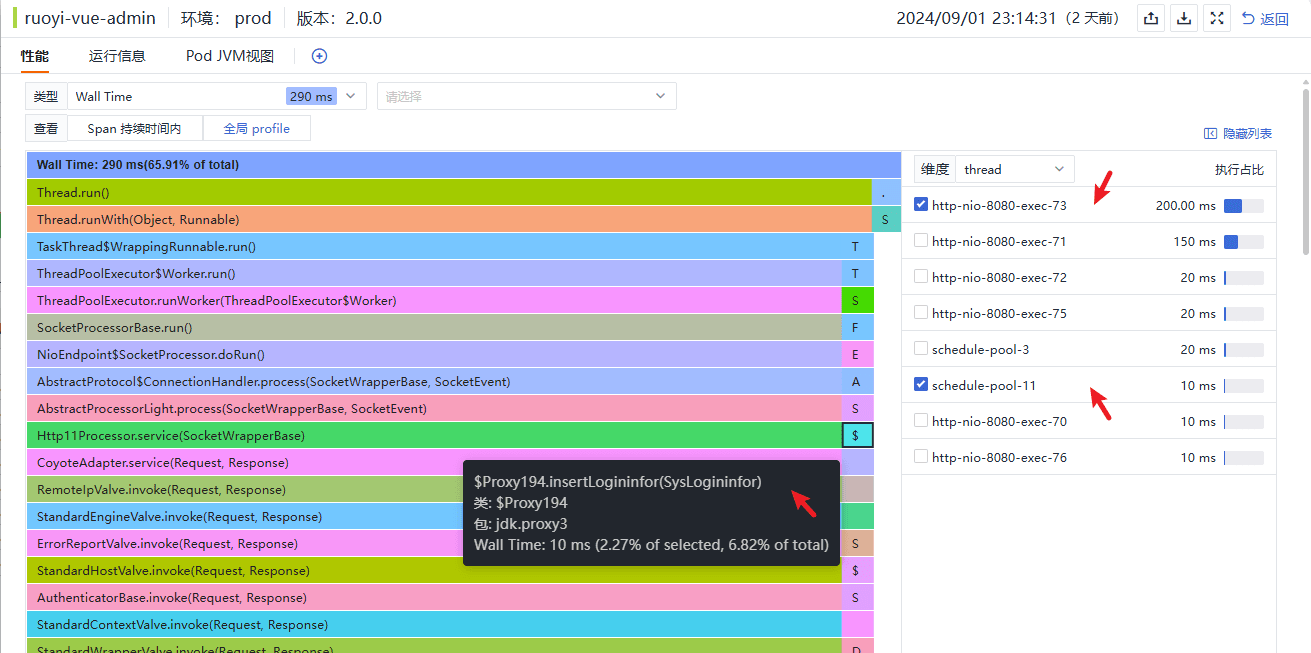
Profilling 详情
可以看到处理请求的线程和写入登录日志的异步线程的调用栈,当然,在 Java 版本支持的情况下我们也能够以这种火焰图的方式看到程序运行时的信息,例如内存分配、堆内对象、异常等。
网络方面,任然在统一视图内下钻四层和七层的网络连接情况和关键指标,例如 TCP 延时、波动、重传等:
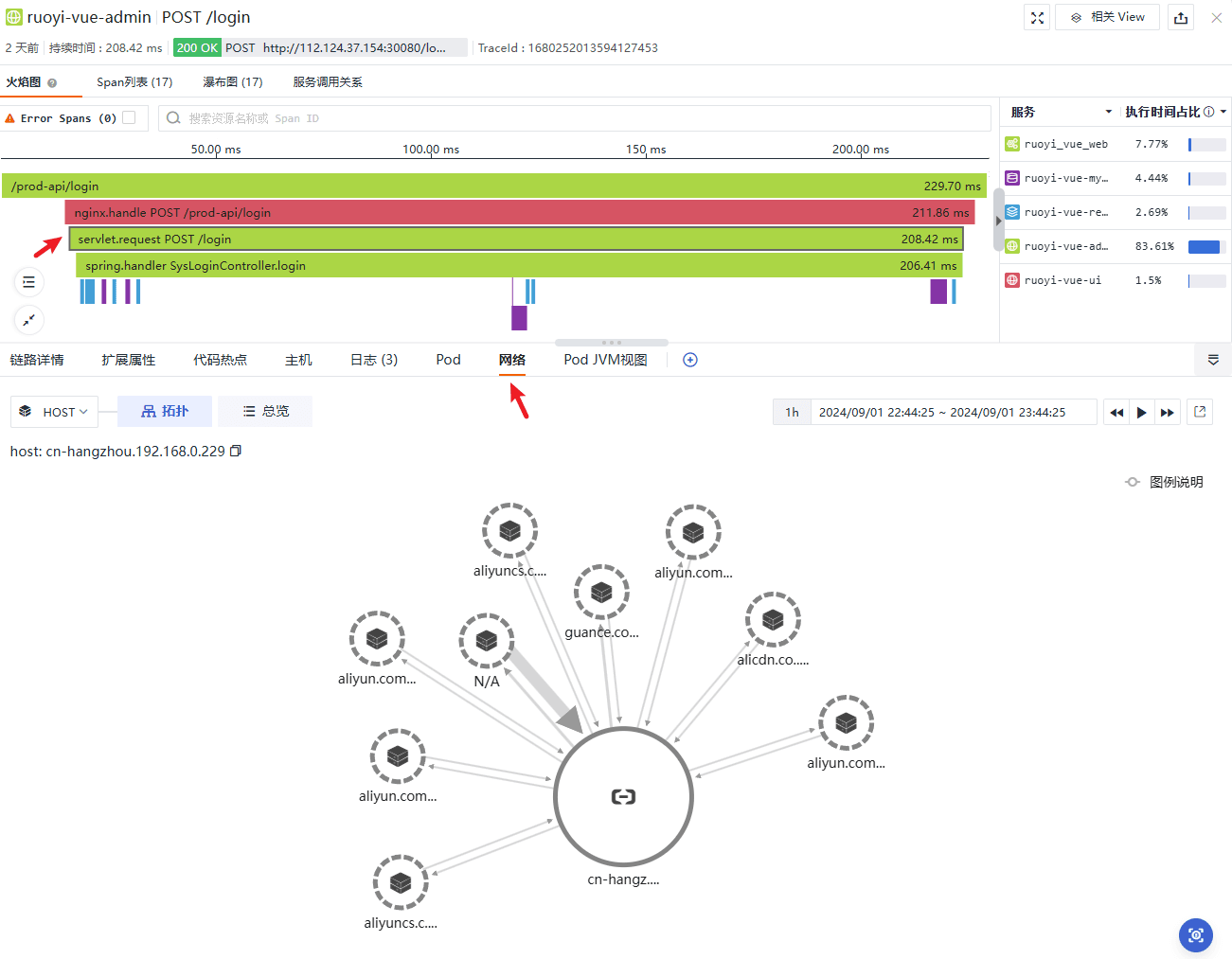
网络拓扑
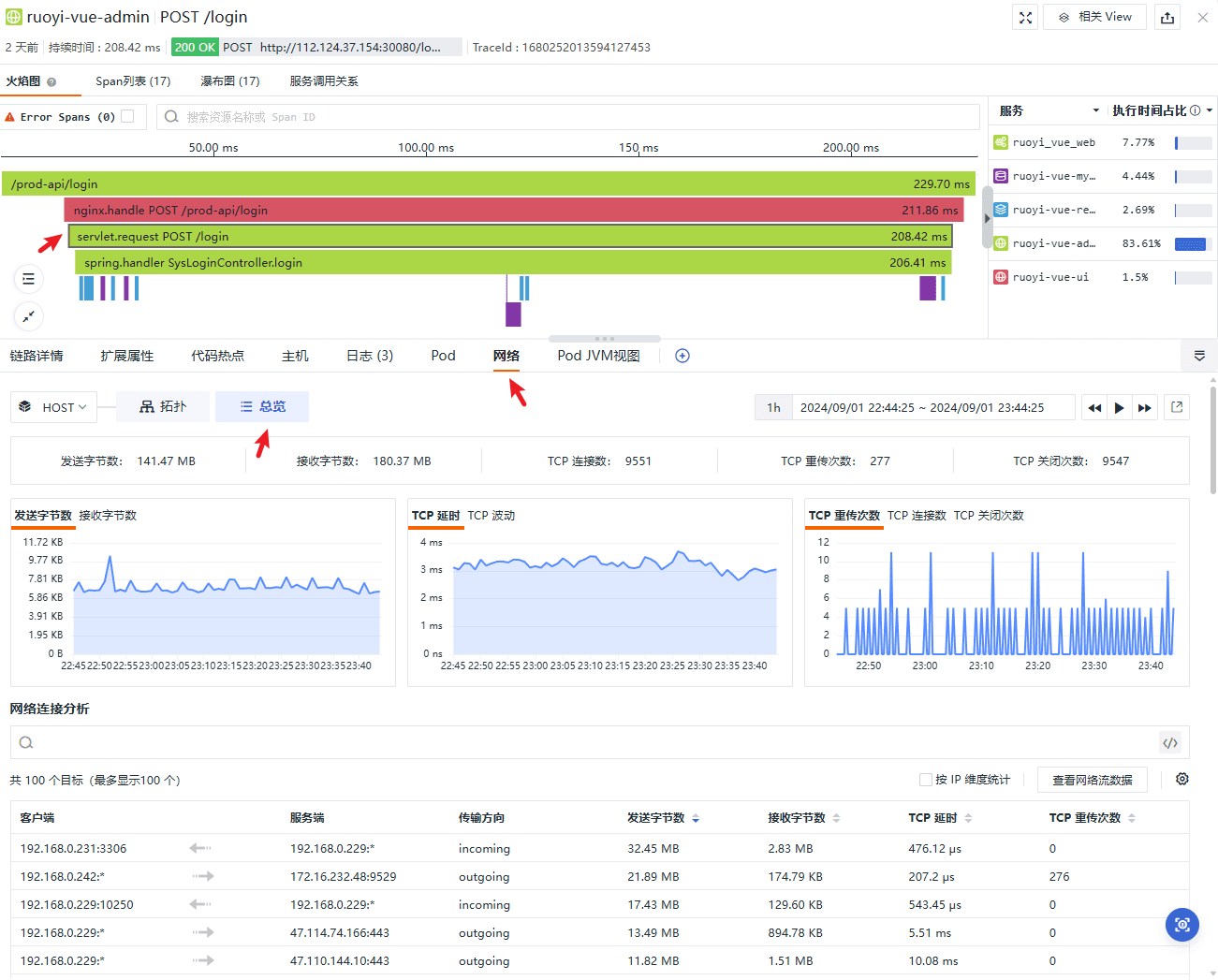
网络指标
基础设施方面,观测云在 Span 的链路详情中附加了相关的字段用以自动关联基础设施和组件的指标:
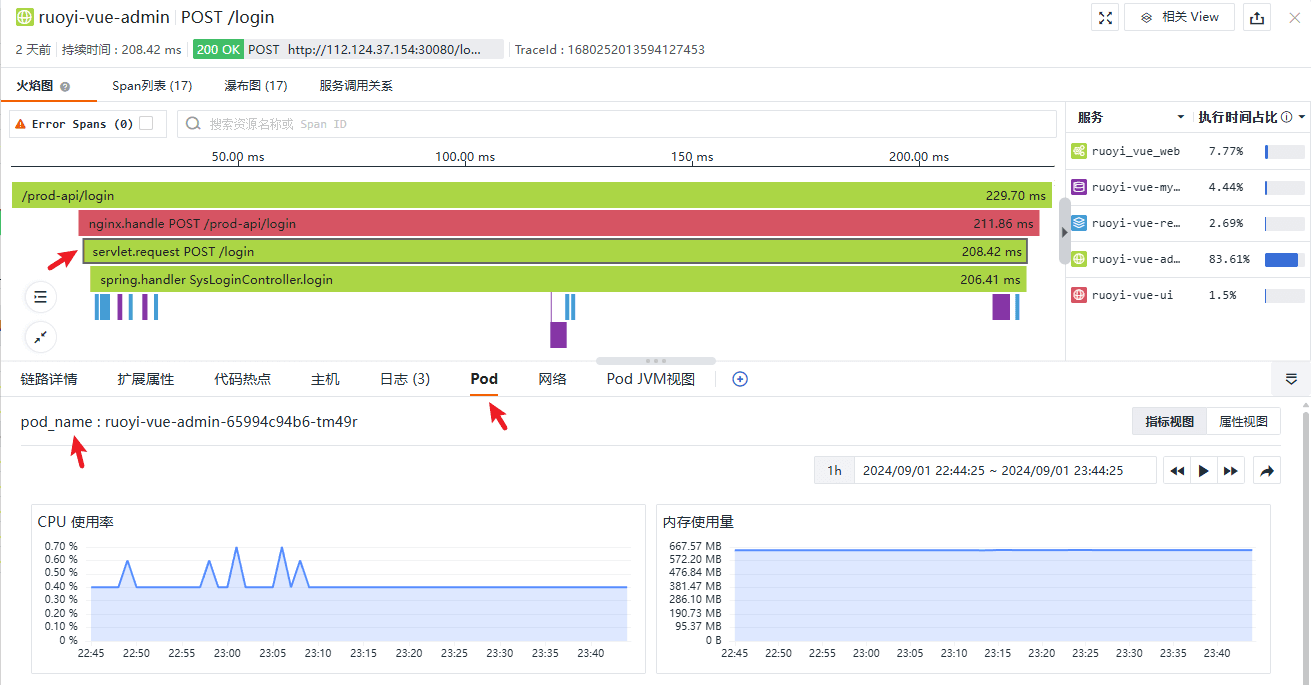
Pod 指标
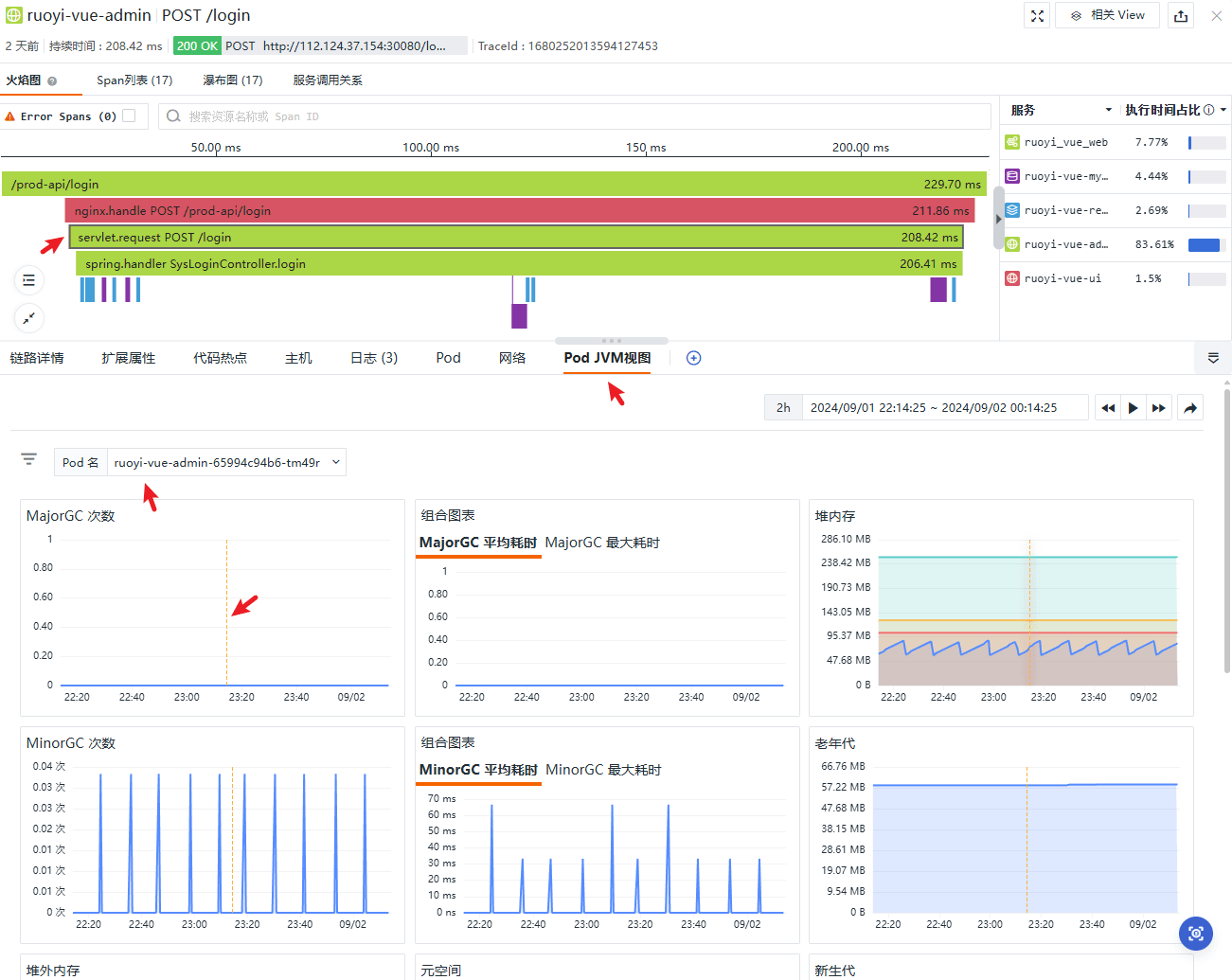
JVM 指标
日志方面,通过 Trace ID 从全局匹配跨服务的日志到统一视图:
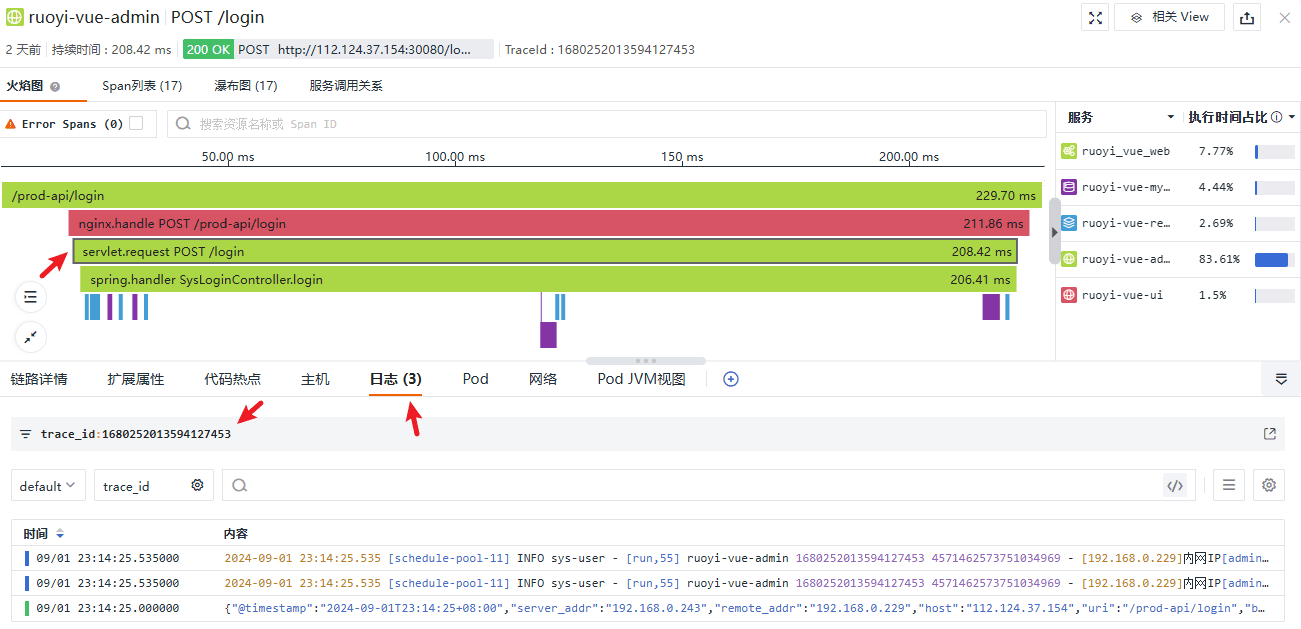
跨服务的日志
总结
本篇文章通过对不同类型可观测数据的分析指出了一个事实,如果想要数据回答运营、故障、反常行为等提出的问题,从多种类型的数据中做关联分析是一个必选项,本例只是展示了可观测技术采用初期的情况。将可观测作为企业价值中的一环时,这种反馈路径将极大的驱动技术和工程能力的迭代,继续深入时,从可观测中受益的各方将通过各种方式暴露更多的数据,可观测性最终成为软件系统的一种特性。