我们熟知,ChatGPT能聊天画图,能编程啃论文,那么,这个聊天机器人到底是怎么学会与人类交流的呢?
经过这段时间的琢磨+方神倾情板书输出讲解+回头翻阅各种资料,也终于明白了个大概,在这尽量给大家用我拙劣的语言说得明白些。
ChatGPT是怎么学习的?
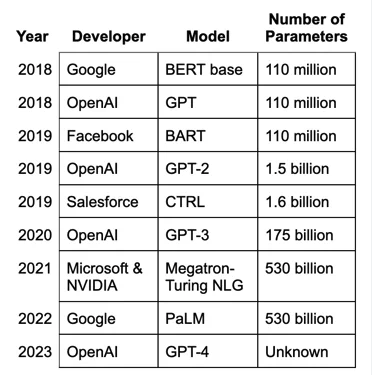
先说说ChatGPT的核心部分:GPT(全称是Generative Pre-trained Transformer,里面的P和T我们一会儿会讲到),这是一个由OpenAI开发的大语言模型(LLM)。
接下来,理解ChatGPT的原理得先了解它的核心架构。ChatGPT的核心架构是Transformer(也就是ChatGPT中的T),一种神经网络架构。好比人类大脑的工作方式:神经网络由大量的“神经元”组成,这些神经元相互连接形成一个庞大的网络,经过学习和记忆大量的文本信息来理解生成复杂的人类语言。在这个网络结构里,**参数(Parameters)就像是模型的脑细胞,帮助模型记住和理解语言模式。参数越多,模型的表达能力就越强,就像一个人学的知识越多,思维就越丰富一样。**每个参数在模型中都有特定的作用。比如某些参数可能专门用于识别句子结构,另一些参数则是用于理解上下文关系,让模型能够捕捉细微的语言模式和复杂的语义关系
而GPT-3.5模型有近百亿个这样的参数,就像一个超级大脑。
( 这里补充讲讲ChatGPT用到的神经网络和之前有啥不同,对细节没兴趣的可略过此段:首先,**自注意力(Self-Attention)机制是Transformer模型中的核心。**Transformer架构是17 年谷歌团队发表的《Attention is All You Need》这篇论文引入的,这篇炸裂之作其实等于彻底改变了之前NLP模型的设计:现在在每一层中,模型使用自注意力机制(Self-Attention)来捕捉句子中单词之间的关系,理解上下文。它的原理就是把输入序列的每个元素转换为三种向量:查询(Query)、键(Key)、值(Value),然后每个元素的查询向量会与序列中其他所有元素的键向量进行点积运算,产生一个注意力分数(Attention Score)。这些分数决定了在生成输出时,每个元素应该给予其他元素多少“注意力”。**这种计算方式允许模型同时处理输入序列中的所有位置,从而捕捉距离远的单词或概念之间的关系,无论它们在文本中的位置如何。**这是与传统神经网络方法(如RNN或LSTM)最大的不同之处,对长文本的处理尤其受用,让模型可以高效并行处理数据。而以前的循环神经网络 (RNN) 是从左到右这么阅读的,也就是说,当相关的单词或概念在原文中彼此相邻时,这种方法还凑合,但当它们位于句子的两端时就很费劲了。就因为它必须按顺序阅读,导致阅读处理效率不高。)
聊完结构,接着来讲讲模型的预训练阶段,也就是ChatGPT中的P(pretraining)。
大模型的训练主要分为以下3个关键阶段:预训练、微调和优化,这三个阶段就好比大厨养成的几个关键步骤:先是大量阅读食谱和不同基础料理,然后针对某种菜系精修,最后不断通过食客的反馈精进厨艺。

在 GPT 出现之前,大多数 NLP 模型都是使用「监督学习」进行训练的,也就是依赖人工标注文本数据:比如给句子标注语法结构、命名实体、动物照片等等,这些类型的训练数据虽然有效,但制作成本极高,需要大量的人力和时间来标注数据。而GPT则通过无监督学习掌握语言的基本结构和语义,即通过输入大量互联网有记载的文本,比如各种网站、书籍资料、文章论坛等来理解字词语句之间的关系模式,就像一个小孩通过不断地听和读来学习说话和写作。(GPT4/4o的训练方式也类似,不过引入了多模态处理能力,能够学习和处理图像和音频等多种形式的数据)。
我们再来看看模型是怎么看懂句子的。

首先,模型对数字的理解力和处理效率更高。因此,模型会把一句话按照词或字符的边界进行切分(这就是分词的概念)比如,当你输入一个句子:我在一个月黑风高的夜晚,模型会首先将这个句子分成一个个独立的字符,这句话可以切分成‘一个’,‘月黑风高的’,‘夜晚’。然后每个字符都会被映射成一个唯一的数字ID,供模型记忆学习。然后,自注意力技术让模型能够自动注意到输入句子中最重要的部分。比如,在句子“我在一个月黑风高的夜晚”中,“月黑风高”和“夜晚”对于理解整个句子的语义很关键,自注意力机制会让模型自动特别关注这些词。
另外,ChatGPT还加入了位置编码,这是一种告诉模型每个词在句子中位置的方式。这样,模型就不仅知道了词的意义,还知道了它们在句子中的相对位置。
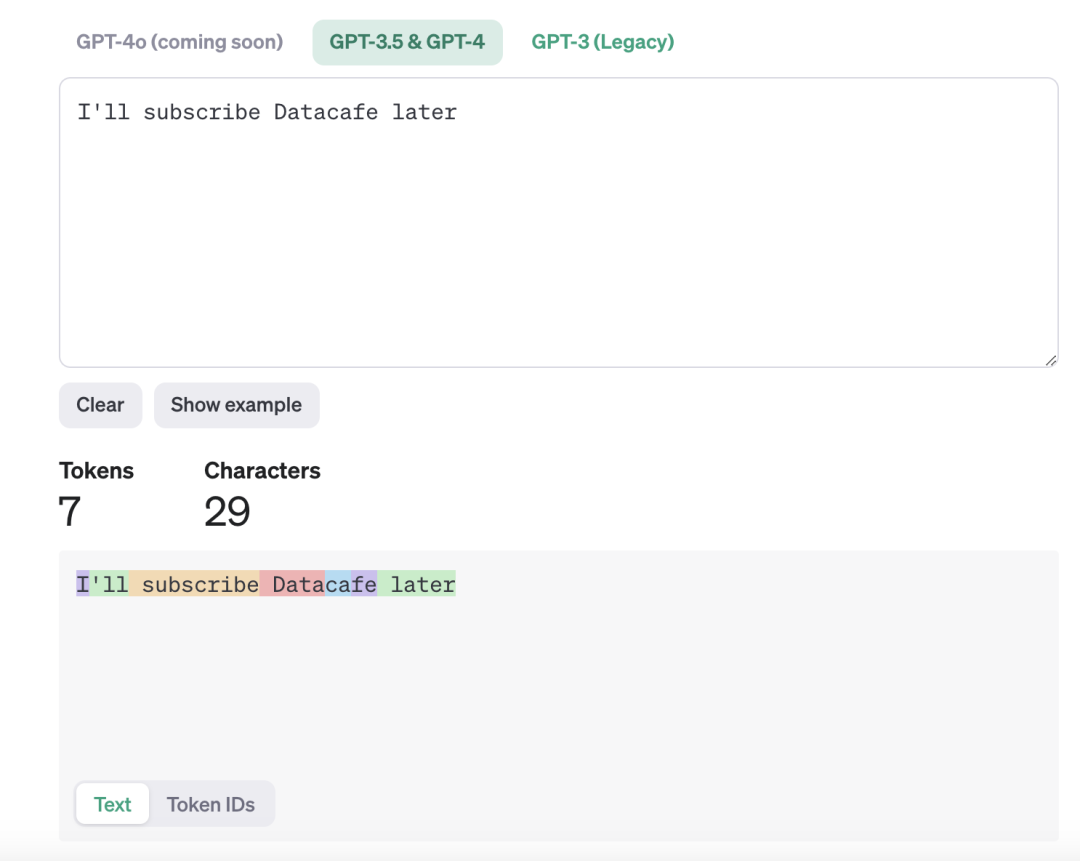
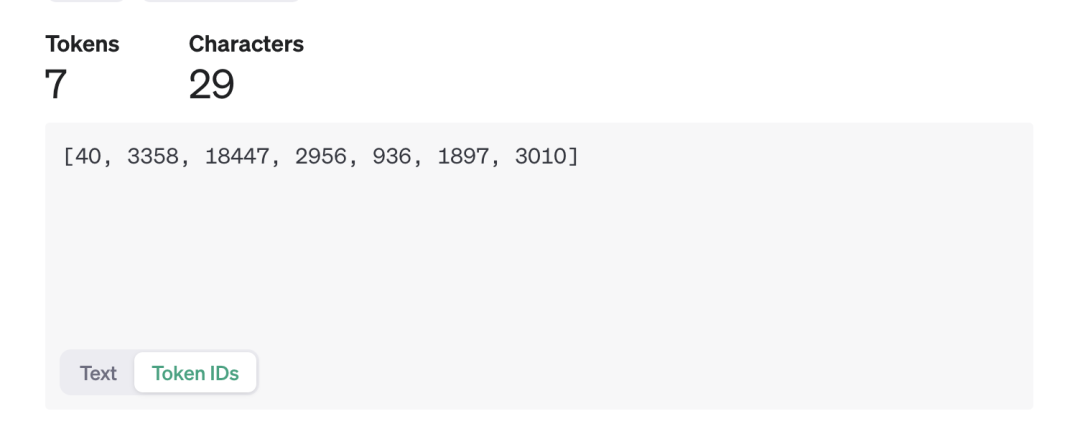
(在官网上可以尝试tokenize一句话,很直观地感受分词与字词的长度以及表现形式的不同)
**好了,重点来了!**ChatGPT到底是如何与我们进行“对话”的?
总的来说,其核心原理就是:预测下一个词!ChatGPT的核心任务非常直接——预测接下来会出现的词。
那么,ChatGPT是如何决定在一句话中下一个最合适的词是什么的?
当ChatGPT面对问题时,它的第一步是理解问题并决定如何回答。为了选择下一个词,它会从之前的训练中调用信息,预测哪些词最有可能构成一个合适、有信息量的回答。在ChatGPT中,每一步处理之后,模型会得到一个向量,这个向量包含了所有可能的下一个词的信息,**这时候,softmax函数就像是一个“智能转换器”,它的任务是将这些个词向量转换成一个概率分布。**这里就用到了概率分布的概念。
(非战斗人士可再次选择性撤离)
概率分布是一个统计术语,用来描述某件事发生的可能性。**简单来说,概率分布就是ChatGPT决定“接下来说什么”的一种计算方式。**softmax函数会将任何一组数值转换成概率分布,使得每个数值都被转换成一个介于0到1之间的概率,高分数的词将被转换为更高的概率,而低分数的词转换为更低的概率。
OK,怎么理解这个“转换”?这个转化是怎么发生的?
假设我们处理后得到的向量是一个数值列表,其中每个数值对应输入文本后可能跟随的一个词。例如,对于“今天天气真XX”,我们可能得到一个包含数千个分量的向量,每个分量对应词汇表中一个词。然后Softmax函数会查看这个向量的每个分量,然后用一个数学公式转换这些数值为概率。
这个公式大概长这样:
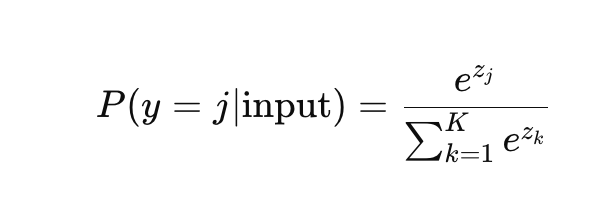
这个公式的意思就是,每个分量先被指数函数处理(作用是放大分量间的差异),然后通过所有处理过的分量的总和来归一化,确保所有的概率加起来是1。得到了这个概率分布后,模型就可以根据每个词的概率来选择下一个词,选择概率最高的词作为输出。
通过softmax函数处理后,每个词都有了一个明确的概率,表明它成为句子中下一个词的可能性。ChatGPT然后选择概率最高的词,将其添加到回答中。这个过程不断重复,直到整个回答构建完成。
这个函数把人类对回答的**“重要性”或“合适性”**的考量转换为具体的概率。
这种方法使得ChatGPT在提供回答时更加贴近人类的思维方式,同时也保证了生成回答的多样性和创造性。
但是,问题来了。
预训练完成后,如果你问ChatGPT一个具体的问题,比如“我怎么学习数据科学?”,它可能还是会给出不着调的答案,比如“你可以先学习数据再学习科学。”

那么,确保ChatGPT不给出太过于匪夷所思的答案就非常重要了!也就是需要确保ChatGPT不只是随机地猜测下一个单词,而是能生成更符合人类期望的回答。
这时候就需要进行微调(Fine-tuning)。
所以,为了让ChatGPT的回答更接近人类的期望,这里会使用一种叫做RLHF(Reinforcement Learning from Human Feedback,可以翻译成基于人类反馈的强化学习)的方法。简单来说,就是让一些“人类模型评委” 来问ChatGPT问题,然后根据这些回答的好坏进行评分,再利用这些评分来训练一个奖励模型。这个奖励模型会告诉ChatGPT哪些答案是好的,哪些是不好的,从而不断引导模型在未来给出更好的回答。
这个RLHF过程大致是这样的:首先,我们让ChatGPT根据它已有的训练生成一些回答。比如我们给它一个问题“如何学习Python编程?”
它可能生成多种不同的回答。
接下来,想象这些回答被展示给一群人类评估员,这些评估员会根据回答的相关性、准确性、可读性等方面给予评分。例如,如果ChatGPT给出的回答是“去报名一个编程课”,这可能会得到较高的评分;而如果它回答“去买台新电脑”,就会得到较低的评分。有了这些评分后,我们就可以构建一个奖励模型。**奖励模型的任务就是根据刚才这些人类评价的结果来学习判断哪些回答是好的,哪些是不好的。也就是把问题和回答扔进去,然后模型会模拟这些评委的偏好输出一个奖励分数,分数越高说明回答越符合人类的期望。**最后,再使用这个奖励模型来训练ChatGPT。在这个阶段每当ChatGPT生成一个回答,奖励模型都会评估这个回答并给出一个分数。然后,ChatGPT会根据这个分数来调整自己,周而复始。通过RLHF,ChatGPT就能慢慢从会“说”,到能够“沟通”。
(
这里简单展开解释一下RLHF常用算法PPO,非细节怪可再次选择性撤离
本段。。
PPO是一种在强化学习领域中十分流行的算法,特别适用于需要处理大量参数的复杂环境,如大规模语言模型和游戏AI等。**它能够帮助训练算法在探索(尝试新的行为)和利用(利用已知的行为)之间找到平衡,**常被用来解决策略梯度方法中策略更新步骤过大导致训练不稳定的问题。PPO是通过限制策略更新前后的差异来实现这一点,大概分为两种方法:
1. 截断的重要性采样(Clipped Surrogate Objective):PPO最常见的形式是使用一个截断的目标函数,这个函数会限制策略更新的步幅。简单来说,PPO算法会计算出一个“重要性权重”来反映新策略与旧策略的相对概率。然后,这个重要性权重会被“截断”,使得其值保持在一定的范围内(比如,0.8到1.2之间)。这种截断操作就保证了新策略不至于与旧策略差异太大,保证了大模型回答的稳定性。
**2. 自适应KL惩罚系数(Adaptive KL Penalty Coefficient):**另一种方法是通过在目标函数中加入一个KL散度项来直接控制策略更新。KL散度是一种度量两个概率分布差异的方法,通过调整KL散度的惩罚系数,可以精细控制策略更新的幅度,从而保持新旧策略之间的接近性。这两种方法都是为了确保新策略不会偏离旧策略太远,从而维持学习过程的稳定性。
另外,温度参数(Temperature Scaling)在生成模型中可以被用来控制输出的**随机性:**温度较高时,模型生成的回答会更加多样化但没那么准确;温度较低时,生成的回答会比较保守,也就是倾向于重复训练数据中常见的回答。调整温度可以帮助找到生成回答的“创造性”与“准确性”之间的平衡点。)
就好比在网抑云翻日推时,系统会确保推给你的歌尽量符合你的品味,也会偶尔在日推混入其他流派的好歌,保证一定的“推荐创新性。
以上,“预训练”,“微调”,“优化”三个阶段就是模型的工作重要过程,当模型不断在这三个阶段往复,ChatGPT也就能不断迭代,变快变好变强。
你可能已经发现,大模型生成输出的整个过程实际上就是在所有可能的输出上形成一个概率分布,所有可能的输出取决于当前的语料和认知。
回答的多样性也反映了现实世界的不确定性,这也是大模型幻觉不完全可控的原因。(果然,科学的尽头是玄学!)那么进一步想,如果训练数据中某些信息被有意过多表示,或者选择性缺失,模型就会固执地坚持错误的判断。—— 它并不是有意为之,而是因为它的“视界”被训练数据(认知)所左右了。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。