目前端到端自动驾驶的定义可以简单分为狭义端到端和广义端到端。
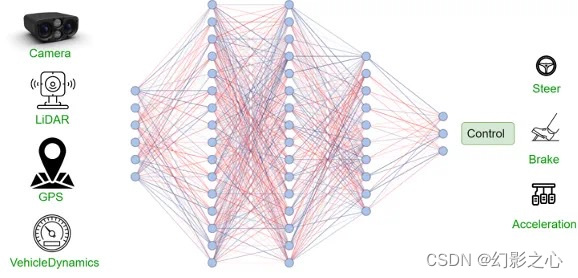
狭义端到端:传感器数据进入神经
网络处理后,直接输出方向盘、油门、刹车等执行器的控制信号,该模式通过单一神经网络模型实现,是严格意义上的端到端。
广义端到端:广义上的端到端具有两个特点:信息无损传递;可以实现数据驱动的整体优化。从广义角度理解端到端,可以看到目前主流的方案仍有差异。主要方案包括通过神经网络模型实现感知与决策规划,不包括控制模块;感知和决策规划使用神经网络,模块之间仍有人工设计的数据接口等方式。
模仿学习(Imitation Learning)和强化学习(Reinforcement Learning)是当前用于训练端到端神经网络的两种主要方法。模仿学习通过逆最优控制(Inverse Optimal Control)和行为克隆(Behavior Cloning)来实现,其核心理念是让智能体通过模仿专家的行为来学习最优策略。而强化学习则是一种通过试错来学习的领域,其中奖励函数的设计是一个关键挑战。
从端到端的最终实现上,通过感知“端到端”,模块化“端到端”,再到 OneModel/单一模型“端到端”是一种相对平滑的过渡形式。而当前感知“端到端”已经是主流的感知模型,展望后续技术发展,自动驾驶算法向“端到端”收敛,有望成为行业的一大趋势。
不同迭代阶段之间的区别:
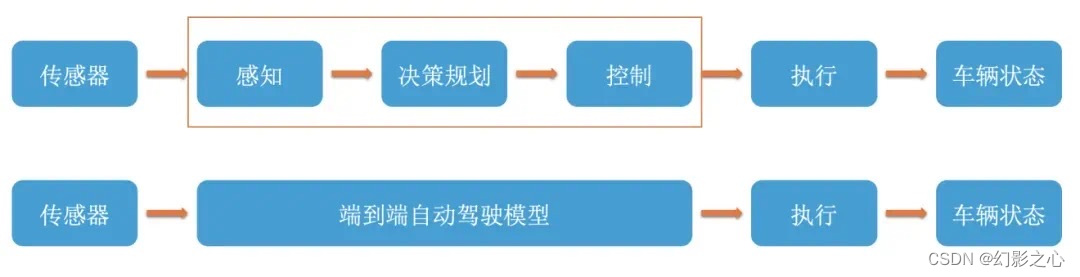
感知“端到端”:当前的主流感知算法路线大多数都是用神经网络模型,通过基于多传感器融合的
BEV(Bird Eye View,鸟瞰图视角)+Transformer 基本实现了感知模块的端到端,感知输出检测结果的精度及稳定性相对之前的感知方案都有比较大的提升,但在决策规划控制模块仍然以 rule-based 为主。
模块化“端到端”:与感知“端到端”相比,感知端算法没有太大变化,决策规划控制模块有望通过深度学习实现,取代原有的 rule-based 方案,从这一阶段开始,端到端的雏形逐渐形成。并且感知与决策规划控制模块之间的数据传递有望由人为定义的结果抽象为特征向量,避免数据损耗与误差累计等问题,决策规划控制模块的综合模型基于特征向量输出运动规划的结果。
One Model/单一模型“端到端”:这一阶段不再有感知、决策规划等模块的明确划分。从原始信号输入到最终规划轨迹的输出直接采用单一深度神经网络实现。One Model 可以基于强化学习(Reinforcement Learning,RL)或模仿学习(Imitation Learning,IL)的端到端模型,也可以通过世界模型这类生成式模型衍生。
受益于有效数据规模的提升,智能驾驶端到端模型有望成为高阶智能驾驶解决方案。从发展路线来看,2019 年至今 CARLA 数据集不断丰富,基于数据集完成数据泛化、增强可解释性、数据融合、基于人类定义规则的预训练。2023 年受益于数据量积累和底层数据类型的升级,充分满足大规模训练需求。通过数据规模提升和数据间关联性可读性的提升,2023 年开始模块化的端到端规划模式加速,逐步成为代表智能驾驶未来发展的主要方向。端到端大模型在最终功能表现上有更高的上限,未来受益于数据规模持续扩张和评价体系的完善,智能驾驶端到端大模型有望加速落地。
“端到端神经网络”,神经网络本来就是“端到端”的(end to end),即从原始数据可以直接到输出结果,比如从车辆周边视频数据、道路数据、车身数据等,可以直接产生下一时刻车辆操控措施。这也是神经网络区别于机器学习算法的特性之一。
所以,如果特斯拉是能把训练好的神经网络模型(可能很大、也需要较好运算能力),部署到车辆上作为操控核心(运算能力有限),那确实是新“应用”了一种技术,完全不同于以往的基于预置规则的自动驾驶策略。
现在开始,没有规则代码,只有神经网络。相比此前的模型通常会加入人类编写的“if else”类的规则,端到端其整个算法几乎全部采用神经网络构建,输入端为传感器感知信息,输出端为控制结果。
AI算法自己处理,最后输出驾驶决策,控制车辆。这期间无论是训练还是实操,都是靠数据驱动。数据是否完全安全可靠,算法漏洞如何弥补,都是一个问题,测不准原理提示我们要心怀敬畏,时间会检验一切。
甲辰年8月廿五 与君共勉