前沿科技速递🚀
在人工智能领域,模型的性能和可扩展性一直是研究的热点。微软最近推出的GRIN-MoE(Gradient-Informed Mixture-of-Experts)模型,以其独特的架构和显著的性能表现,正引领着AI技术的前沿,特别是在编码和数学任务上展现出强大的能力。GRIN-MoE的发布标志着企业级应用中AI技术的又一次飞跃,旨在提升处理复杂任务的效率和准确性。
来源:传神社区
01 模型简介
GRIN-MoE模型是微软研究院开发的一种先进的人工智能模型,基于Transformer架构,结合了混合专家(Mixture-of-Experts, MoE)设计理念。该模型的核心在于通过稀疏计算来提高效率,使其能够在处理大规模数据时更为高效。
GRIN-MoE的设计理念是通过只激活一部分参数来实现计算资源的优化,极大地提高了模型在推理时的性能。在模型中,输入数据被分割为多个区块(token),并通过门控网络将这些token分配给不同的专家网络进行处理。每个专家网络负责特定的任务,能够并行处理多个输入,充分利用计算能力。
这种架构不仅提升了模型的处理速度,同时也降低了对计算资源的需求,使得大型模型在资源受限的环境中也能高效运行。

02 技术亮点
-
专家路由机制
GRIN-MoE采用了混合专家架构,通过门控网络实现输入token的动态路由,将其分配给专门的专家网络。这种灵活的分配机制使得模型能够根据任务需求有效调动资源,优化计算流程。 -
稀疏梯度估计
传统MoE模型在训练中面临专家路由的离散性挑战,导致难以进行标准的反向传播。GRIN-MoE引入了SparseMixer-v2算法,采用随机采样和Heun's第三阶方法来近似专家路由的梯度。这一创新有效提高了训练效率,使得模型在更新参数时更加高效。 -
模型参数激活机制
GRIN-MoE在推理过程中仅激活66亿个参数,这样不仅提升了计算效率,也减少了资源消耗。相比于同类模型,GRIN-MoE在运行时的资源占用大幅降低,更加适合企业级应用。 -
可扩展性
该模型能够在没有专家并行或令牌丢弃的情况下扩展,解决了大型模型在数据中心容量受限时的应用难题。GRIN-MoE的设计允许企业在不需复杂基础设施的情况下,灵活地使用AI技术。
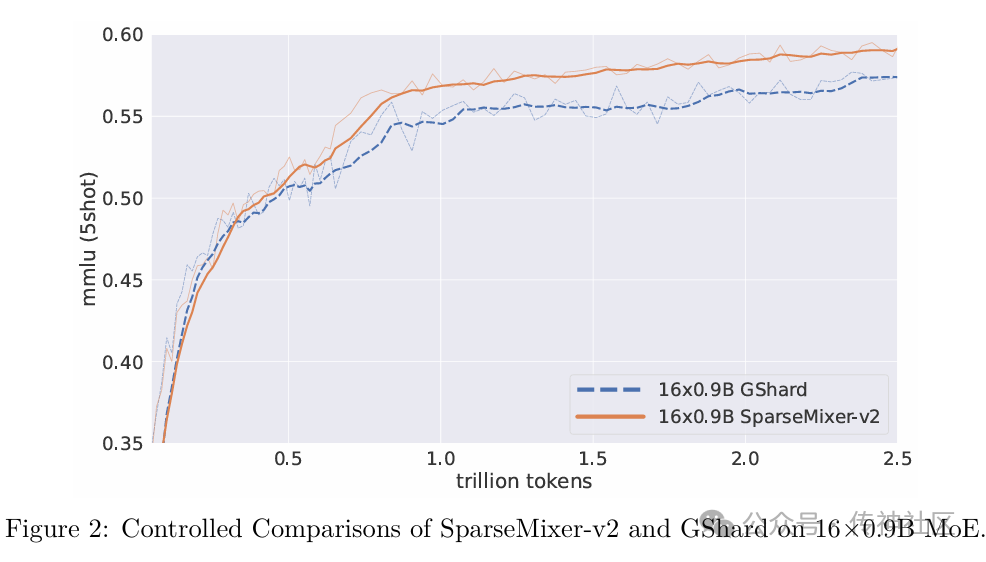
03 卓越性能
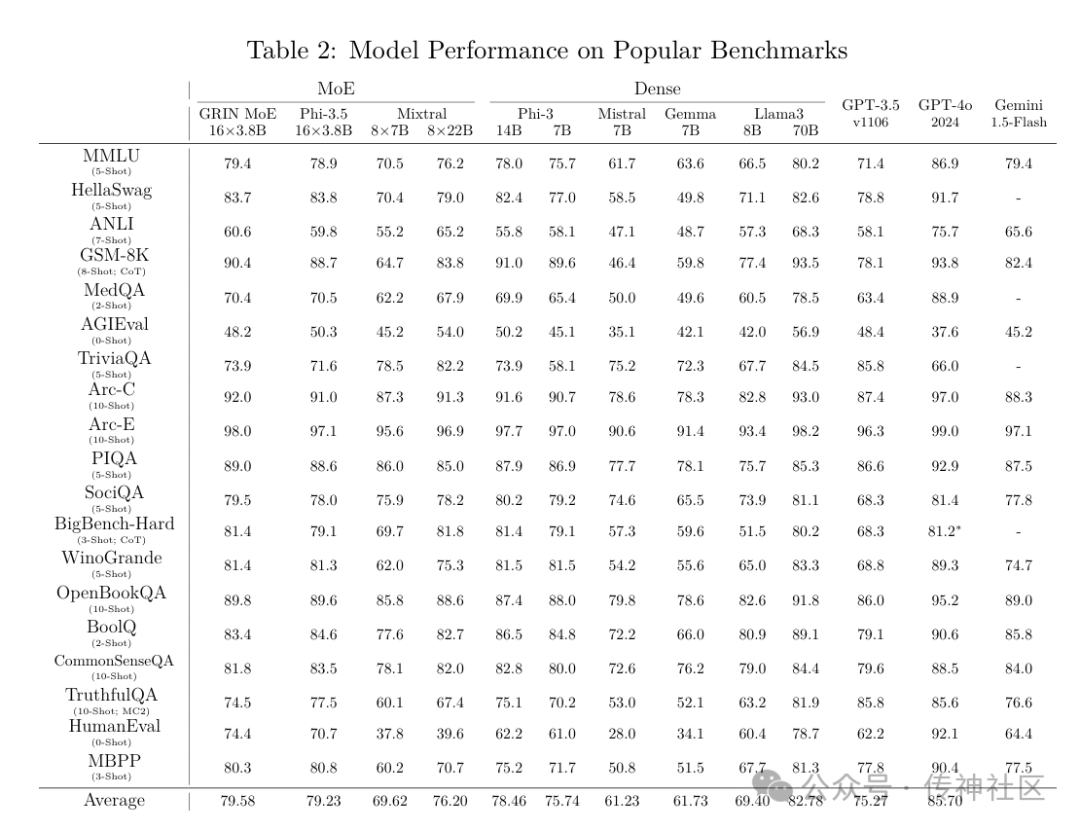
GRIN-MoE在多个基准测试中表现优异,展现出其强大的处理能力。在MMLU(大规模多任务语言理解)基准测试中,该模型得分79.4,显著超越了其他同类模型。在GSM-8K数学问题解决能力测试中,GRIN-MoE得分90.4,证明其在数学推理方面的突出表现。
在编码任务的HumanEval基准测试中,GRIN-MoE获得74.4的高分,超越了GPT-3.5-turbo等多个流行模型。这些成绩表明,GRIN-MoE在处理复杂任务时不仅高效而且可靠,为企业的智能化转型提供了强有力的支持。
04 模型下载
传神社区:
https://opencsg.com/models/microsoft/GRIN-MoE
huggingface:
https://huggingface.co/microsoft/GRIN-MoE
欢迎加入传神社区
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎🌟:https://github.com/OpenCSGs
•Huggingface主页
欢迎下载:https://huggingface.co/opencsg
•加入我们的用户交流群,分享经验

扫描上方二维码添加传神小助手
“ 关于OpenCSG
开放传神(OpenCSG)成立于2023年,是一家致力于大模型生态社区建设,汇集人工智能行业上下游企业链共同为大模型在垂直行业的应用提供解决方案和工具平台的公司。
关注OpenCSG

加入传神社区