在数据分析的过程中,快速掌握数据集的基本特征是必不可少的一步。虽然 Pandas 提供了方便的 df.describe() 方法来生成数据摘要,但随着数据类型和分析需求的多样化,这一方法的局限性逐渐显现。Skimpy 作为一个新兴的 Python 包,旨在填补这一空白,提供更全面、更智能的数据摘要功能。
什么是 Skimpy?
Skimpy 是一个轻量级的数据探索工具,旨在为 Pandas 和 Polars 数据框提供详尽的统计摘要。
主要功能特点
-
多数据类型支持:不仅支持数值型数据,还涵盖类别型、布尔型、日期时间型等多种数据类型。
-
详尽的统计信息:除了均值、标准差等基本统计量外,还提供缺失值分析、类别分布、布尔值比例、时间序列信息等。
-
直观的输出展示:利用 Rich 库,Skimpy 能够以美观的表格和直方图形式展示统计结果,增强可读性。
-
兼容性强:适用于 Pandas 和 Polars 数据框,且易于集成到现有的数据分析流程中。
-
可定制性:用户可以根据需求自定义统计项,灵活调整摘要内容。
Skimpy 与 Pandas df.describe() 的对比
虽然 Pandas 的 df.describe() 方法在快速生成数据摘要方面表现出色,但它主要针对数值型数据,且提供的信息较为有限。以下是 Skimpy 在多个方面对 df.describe() 的提升:
-
数据类型覆盖更全面:
-
df.describe()主要针对数值型数据提供统计信息,而 Skimpy 支持更多数据类型,如类别型(categorical)、布尔型(bool)、日期时间型(datetime)等,能够对不同类型的数据进行相应的统计分析。
-
-
缺失值分析:
-
Skimpy 自动识别并报告每一列的缺失值数量及其比例,帮助用户快速定位数据中的潜在问题。这一点在
df.describe()中是缺失的。
-
-
类别型数据详细信息:
-
对于类别型数据,Skimpy 不仅统计唯一值的数量,还分析每个类别的频次分布,甚至可以识别有序类别。这些信息对于理解分类变量的分布和结构非常有价值。
-
-
布尔值分布:
-
Skimpy 对布尔型数据提供详细的真值和假值的比例分析,并通过直方图直观展示分布情况,这在
df.describe()中并未涉及。
-
-
时间序列数据分析:
-
对于日期时间型数据,Skimpy 提供最早和最晚的时间点,以及数据的时间频率分布,帮助用户理解时间维度上的数据特征。
-
-
字符串数据分析:
-
Skimpy 能够分析字符串列中的词数和总词数,为文本数据的初步探索提供支持,而
df.describe()对此类数据的处理较为有限。
-
-
增强的可视化:
-
借助 Rich 库,Skimpy 在控制台中生成的摘要不仅包含表格信息,还可以显示直观的文本式直方图,提升数据理解的效率。
-
如何使用 Skimpy
安装 Skimpy
Skimpy 可以通过 pip 轻松安装:
pip install skimpy
或从 GitHub 仓库安装最新的开发版本:
pip install git+https://github.com/aeturrell/skimpy.git
快速上手
以下是一个使用 Skimpy 的简单示例:
import pandas as pd
from skimpy import skim
df = pd.read_csv('yc_data.csv')
# 生成数据摘要
skim(df)
示例输出
运行上述代码后,Skimpy 会生成如下统计摘要:
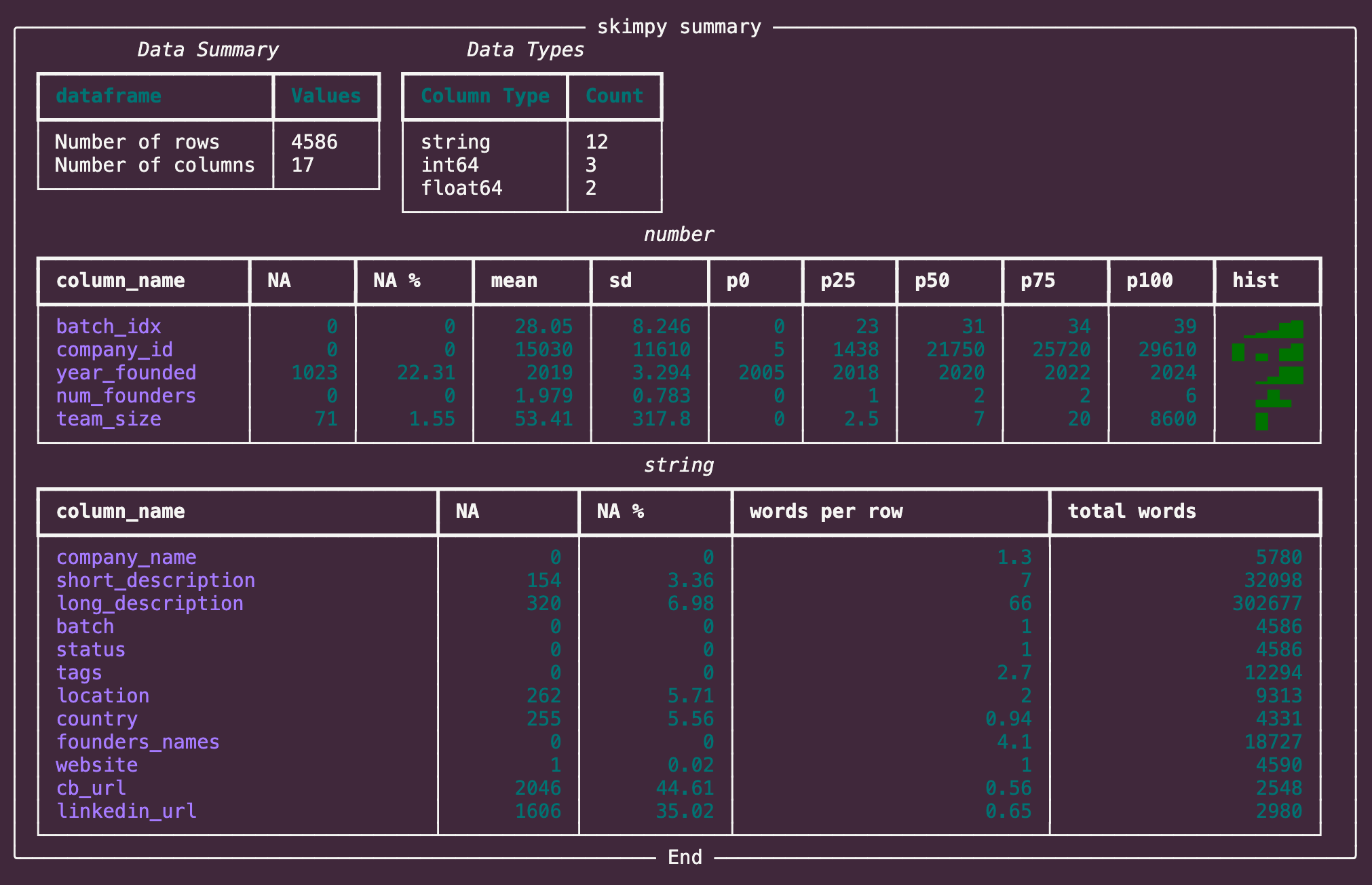
注:具体输出格式可能因 Skimpy 版本和数据内容有所不同。
可以看出与传统的 df.describe() 方法相比,Skimpy 不仅涵盖了数值型数据的基本统计信息,还扩展到了类别型、布尔型、日期时间型等多种数据类型的分析,使得数据探索更加全面和高效。



















