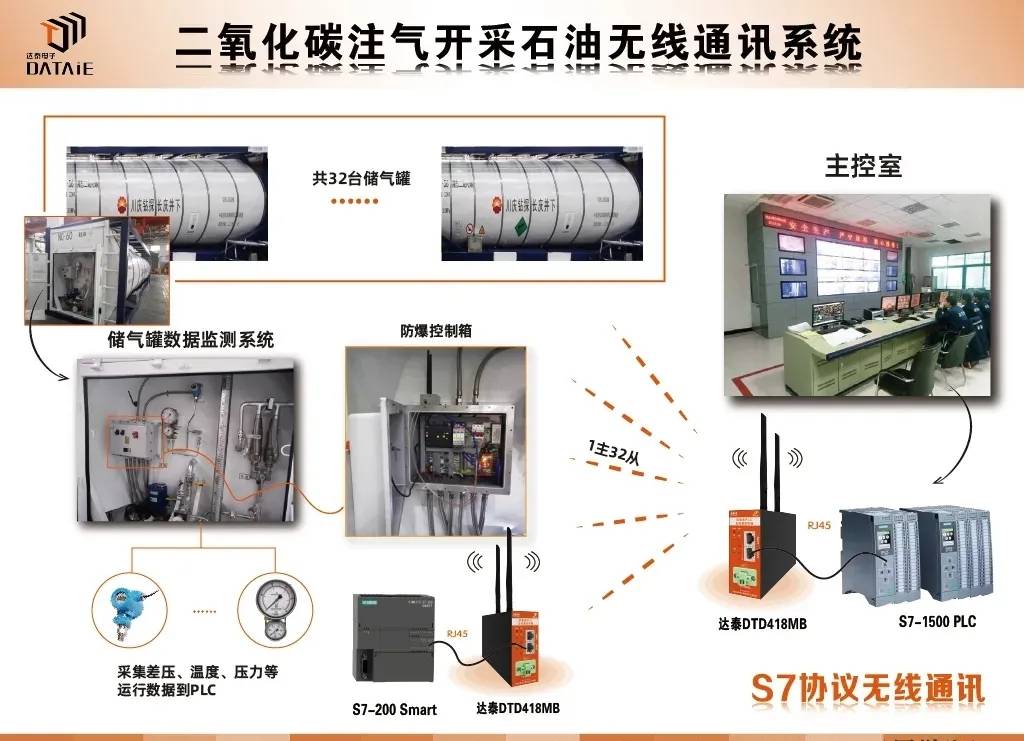
Calcite 是什么?
2024 年 9 月,最新版本
1.37.0。前面三节我们先不看任何的源码,只从背景、介绍、概念、原理层面入手,作为深入学习和源码分析的预备。
如果用一句话形容 Calcite,Calcite 是一个用于优化异构数据源的查询处理的基础框架。
最近十几年来,出现了很多专门的数据处理引擎。例如列式存储 (HBase)、流处理引擎 (Flink)、文档搜索引擎 (Elasticsearch) 等等。这些引擎在各自针对的领域都有独特的优势,在现有复杂的业务场景下,我们很难只采用当中的某一个而舍弃其他的数据引擎。当引擎发展到一定成熟阶段,为了减少用户的学习成本,大多引擎都会考虑引入 SQL 支持,但如何避免重复造轮子又成了一个大问题。
基于这个背景,Calcite 横空出世,它提供了标准的 SQL 语言、多种查询优化和连接各种数据源的能力,将数据存储以及数据管理的能力留给引擎自身实现。同时 Calcite 有着良好的可插拔的架构设计,我们可以只使用其中一部分功能构建自己的 SQL 引擎,而无需将整个引擎依托在 Calcite 上。因此 Calcite 成为了现在许多大数据框架 SQL 引擎的最佳方案。
八面玲珑的方解石
Calcite(中文意为方解石) 一开始设计的目标就是 one size fits all,它希望能为不同计算存储引擎提供统一的 SQL 查询引擎,当然 Calcite 并不仅仅是一个简单的 SQL 查询引擎,Calcite 的架构有三个特点:flexible, embeddable, and extensible,就是灵活性、组件可插拔、可扩展,它的 SQL Parser 层、Optimizer 层等都可以单独使用,这也是 Calcite 受总多开源框架欢迎的原因之一。
背景介绍(官网)
文档地址: Background - apache.org
Apache Calcite 是一个动态数据管理框架。
它包含构成典型数据库管理系统的许多部分,但省略了一些关键功能:数据存储、数据处理算法和元数据存储库。
Calcite 设计为不参与数据的存储和处理。正如我们将要看到的,这使它成为应用程序与一个或多个数据存储位置和数据处理引擎之间的绝佳中介。它还是构建数据库的完美基础:只需添加数据即可。
关系代数的基本知识
关系代数是关系型数据库操作的理论基础,关系代数支持并、差、笛卡尔积、投影和选择等基本运算。关系代数也是 Calcite 的核心,任何一个查询都可以表示成由关系运算符组成的树。
在 Calcite 中,它会先将 SQL 转换成关系表达式(relational expression),然后通过规则匹配(rules match)进行相应的优化,优化时会有一个成本(cost)模型为参考。
先看下关系代数相关内容,这对于理解 Calcite 很有帮助,特别是 Calcite Optimizer 这块的内容:
| 名称 | 英文 | 符号 | 说明 |
|---|---|---|---|
| 选择 | select | σ | 类似于 SQL 中的 where |
| 投影 | project | Π | 类似于 SQL 中的 select |
| 并 | union | ∪ | 类似于 SQL 中的 union |
| 集合差 | set-difference | - | SQL中没有对应的操作符 |
| 笛卡儿积 | Cartesian-product | × | 类似于 SQL 中不带 on 条件的 inner join |
| 重命名 | rename | ρ | 类似于 SQL 中的 as |
| 集合交 | intersection | ∩ | SQL中没有对应的操作符 |
| 自然连接 | natural join | ⋈ | 类似于 SQL 中的 inner join |
| 赋值 | assignment | ← |
核心架构

中间的方框总结了 Calcite 的核心结构:
- 首先 Calcite 通过 SQL Parser 和 Validator 将一个 SQL 查询解析得到一个抽象语法树 (AST, Abstract Syntax Tree)-
- 由于 Calcite 不包含存储层,因此它提供了另一种定义 table schema 和 view 的机制—— Catalog 作为元数据的存储空间(另外 Calcite 提供了 Adaptor 机制连接外部的存储引擎获取元数据,这部分内容不在本文范围内)。
- 之后,Calcite 通过优化器生成对应的关系表达式树,根据特定的规则进行优化。
- 优化器是 Calcite 最为重要的一部分逻辑,它包含了三个组件:Rule、MetadataProvider(Catalog)、Planner engine。
通过架构图我们可以看出,Calcite 最大的特点(优势)是它将 SQL 的处理、校验和优化等逻辑单独剥离出来,省略了一些关键组件,例如,数据存储,处理数据的算法以及用于存储元数据的存储库。
其次 Calcite 做得最出色的地方则是它的可插拔机制,每个大数据框架都可以选择 Calcite 的整体或部分模块建立自己的 SQL 处理引擎,如 Hive 自己实现了 SQL 解析,只使用了 Calcite 的优化功能,Storm 以及 Flink 则是完全基于 Calcite 建立了 SQL 引擎。
四个阶段

Calcite 框架的运行主要分四个阶段:
- Parse:使用 JavaCC 生成的解析器进行词法、语法分析,得到 AST;
- Validate:结合元数据进行校验;
- Optimize:将 AST 转化为逻辑执行计划(tree of relational expression),并根据特定的规则(heuristic 或 cost-baesd)进行优化;
- Execute:将逻辑执行计划转化成引擎特有的执行逻辑,比如 Flink 的 DataStream。第 4 步是一个和引擎耦合的流程。

启发式算法(heuristic algorithm)就是例如遗传算法,模拟退火,各种群算法,蚁群,鱼群,粒子群,人工神经网络等模仿自然界或生命体行为模式的算法,一般又称人工智能算法或全局优化算法。
启发式算法是指具有自学习功能,可利用部分信息对计算产生推理的算法。
四大组件
围绕着这个运行流程,Apache Calcite 最核心的框架可以拆分为四个组件
-
SQL Parser:将符合语法规则的 SQL 转化成 AST(Sql text → SqlNode),Calcite 提供了默认的 parser,但也可以基于
JavaCC生成自定义的 parser;通过 Parser, 可以将 Sql 转化成 SqlNode, 什么是 SqlNode? SqlNode 是 Calcite 中用于表达关系运算的中间数据结构,也就是标识符、字符串常量、函数调用、动态参数等等,这样 SQL 就从普通文本变成了有类型的结构。在Calcite中,所有的操作都是一个SqlCall, 如查询是一个SqlSelect, 删除是一个SqlDelete等,对应的查询条件等为SqlCall中的参数。
-
Catalog:定义记录了 SQL 的 metadata 和 namespace,方便后续的访问和校验;
-
SQL Validator:结合 Catalog 提供的元数据校验 AST,具体的实现都在 SqlValidatorImpl 中;此过程主要是根据定义的scheam, table, columns 来验证SqlNode是否合法。
-
Query Optimizer:这块概念较多,首先需要将 AST 转化成逻辑执行计划(即 SqlNode → RelNode),其次使用 Rules 优化逻辑执行计划。查询优化主要是围绕着 等价交换 的原则做相应的转换。
参考文档
Calcite:Apache Calcite 框架初探及概念详解
Apache Calcite 处理流程详解-Matt’s Blog
Apache Calcite:Hadoop中新型大数据查询引擎_开源



![[NewStarCTF 2023 公开赛道]Begin of PHP1](https://i-blog.csdnimg.cn/direct/68a3e9514c964e968c63c0180722c568.png)









![【PWN · HOO | HOF | Tcache pthread struct】[2024 · ByteCTF] ezheap](https://i-blog.csdnimg.cn/direct/0fbe255c8dc443b5a2065fead740a1a0.png)