人工智能咨询培训老师叶梓 转载标明出处
图神经网络(GNNs)在处理图结构数据方面取得了显著的进展,但现有模型在深层结构中存在性能问题,如“悬挂动画问题”和“过平滑问题”。而且图数据内在的相互连接特性限制了大规模图输入的并行化处理,这在内存限制下尤为突出。
针对这些问题,美国佛罗里达州立大学IFM实验室和伊利诺伊大学芝加哥分校以及北京邮电大学的研究者共同提出了一种新的图神经网络模型——GRAPH-BERT(基于图的BERT),该模型完全基于注意力机制,不依赖于任何图卷积或聚合操作。
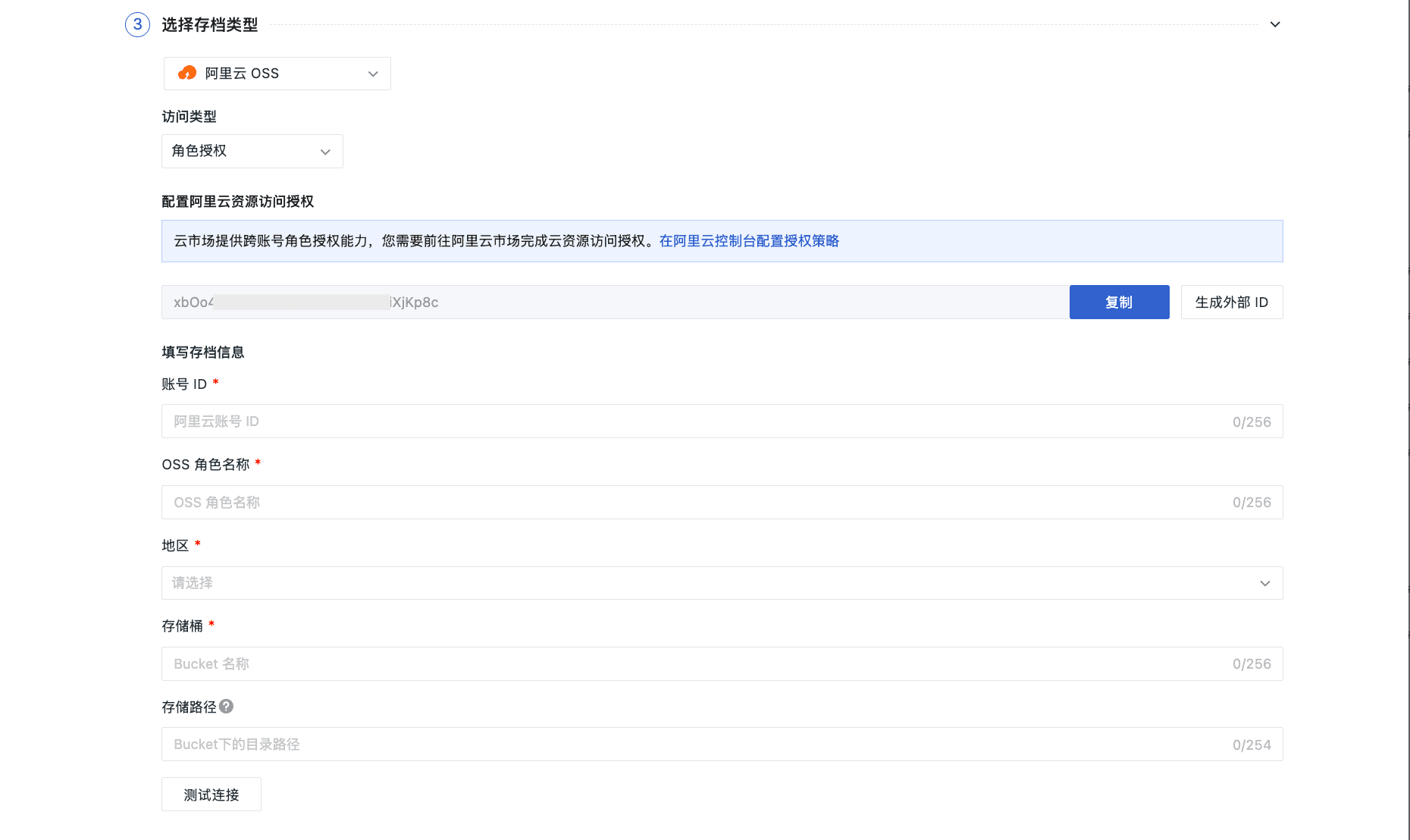
GRAPH-BERT的创新之处在于,它不是通过图的链接来学习节点表示,而是通过在输入大型图数据中采样无链接的子图(称为linkless subgraphs)来进行训练。这种基于局部上下文的采样方法,使得GRAPH-BERT能够有效地解决现有GNNs模型中的性能问题,并提高了学习效率。
方法
GRAPH-BERT模型由几个关键部分组成(Figure 1)包括无链接子图批处理、节点输入向量嵌入、基于图的 Transformer 编码器、表示融合和功能组件这五个部分。

无链接子图批处理
首先提出了问题的设置。输入图数据可以表示为 G = (V, E, w, x, y),其中 V 和 E 分别表示图中的节点和链接集合。映射 w 将链接投影到其权重,而映射 x 和 y 可以将节点投影到其原始特征和标签。模型在预训练阶段不需要任何标签监督信息,但部分标签将用于后续的节点分类微调任务。
GRAPH-BERT不是在完整图 G 上工作,而是在从输入图中采样的无链接子图批次上进行训练。这样可以有效地并行化学习,即使是现有的图神经网络无法处理的极大规模图也适用。
节点输入向量嵌入
与图像和文本数据不同,图中的像素和单词/字符具有固有的顺序,而图中的节点是无序的。GRAPH-BERT模型实际上并不需要输入采样子图中的任何节点顺序。为了简化表示,建议将输入子图中的节点序列化为有序列表。
节点的输入向量嵌入包括四个部分:
- 原始特征向量嵌入(Raw Feature Vector Embedding):每个节点的原始特征向量被嵌入到共享特征空间中。
- Weisfeiler-Lehman 绝对角色嵌入(Weisfeiler-Lehman Absolute Role Embedding):Weisfeiler-Lehman算法可以根据图中的结构角色对节点进行标记。
- 基于亲密度的相对位置嵌入(Intimacy based Relative Positional Embedding):基于节点列表的顺序,可以提取子图中的局部信息。
- 基于跳数的相对距离嵌入(Hop based Relative Distance Embedding):可以视为绝对角色嵌入(全局信息)和基于亲密度的相对位置嵌入(局部信息)之间的平衡。
基于图变换器的编码器
基于上述计算的嵌入向量,可以将它们聚合在一起,定义子图中节点的初始输入向量。然后,基于图变换器的编码器将通过多个层(D层)迭代更新节点的表示。
GRAPH-BERT 学习
预训练包括两个任务:节点原始属性重建和图结构恢复。
- 节点原始属性重建:目标是捕获学习表示中的节点属性信息。
- 图结构恢复:重点更多地放在图连接信息上。
预训练后的GRAPH-BERT可以用于新任务,或者进行必要的调整,即微调。
- 节点分类:基于节点学习到的表示,可以推断出节点的标签。
- 图聚类:主要目标是对图中的节点进行分组。

Figure 2展示了GRAPH-BERT在节点重建和图恢复任务上的预训练过程。图中的x轴表示迭代次数,y轴表示训练损失。
想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具。实战专家1小时讲解让您轻松上手,学习如何使用 Llama Factory 微调模型。
评论留言“参加”或扫描微信备注“参加”,即可参加线上直播分享,叶老师亲自指导,互动沟通,全面掌握Llama Factory。关注享粉丝福利,限时免费录播讲解。
实验
实验在三个真实世界的基准图数据集上进行,分别是Cora、Citeseer和Pubmed。这些数据集在最新的图神经网络研究中被广泛使用。
实验使用了Cora、Citeseer和Pubmed数据集,这些数据集在图神经网络的研究中非常常见。实验中首先预计算节点亲密度得分,基于这些得分对子图批次进行采样,子图大小k 的范围是 {1, 2, ..., 10, 15, 20, ..., 50}。此外,还预计算了节点之间的跳数距离和Weisfeiler-Lehman (WL) 节点代码。通过最小化节点原始特征重构损失和图结构恢复损失,可以有效地预训练GRAPH-BERT。

Figure 3展示了GRAPH-BERT在Cora数据集上节点分类任务的学习性能。图中展示了不同层数的GRAPH-BERT模型的训练和测试准确率,可以看出模型在训练集上的收敛速度非常快,并且随着模型深度的增加,GRAPH-BERT并没有出现悬挂动画问题。

Table 1 展示了GRAPH-BERT在节点分类任务上与现有基线方法相比的学习性能。结果表明,GRAPH-BERT在大多数情况下都能取得更好的性能。
在没有预训练的情况下,GRAPH-BERT能够独立应用于各种图学习任务。在Cora数据集上,展示了不同深度的GRAPH-BERT模型的学习收敛情况。实验结果表明,即使是非常深的GRAPH-BERT(50层)也能有效地响应训练数据并取得良好的学习性能。

Table 2 分析了在Cora数据集上不同子图大小 k 对模型性能(测试准确率和测试损失)和总时间成本的影响。结果表明,参数 k 对GRAPH-BERT的学习性能有很大影响。

Table 3展示了使用不同图残差项的GRAPH-BERT的学习性能。结果表明,使用graph-raw残差项的GRAPH-BERT表现更好。

Table 4展示了GRAPH-BERT在三个数据集上不同初始嵌入输入的学习性能。结果表明,原始特征嵌入对模型性能的贡献最大。Table 5展示了GRAPH-BERT在没有预训练的情况下,仅基于节点原始特征进行图聚类的学习结果。结果通过多种不同的指标进行评估。
在没有预训练的情况下,GRAPH-BERT在三个数据集上的图聚类学习结果被展示出来。聚类组件使用的是KMeans算法,它将节点的原始特征向量作为输入。
对于有预训练和没有预训练的GRAPH-BERT在微调任务上的实验结果。为了突出差异,这里只使用了正常训练周期的1/5来微调GRAPH-BERT。结果表明,对于大多数数据集,预训练为GRAPH-BERT提供了良好的初始状态,这有助于模型在只有很少的微调周期的情况下取得更好的性能。Figure 2 展示了GRAPH-BERT在节点属性重建和图结构恢复任务上的预训练学习性能,反映了模型在预训练任务上的快速收敛情况。
GRAPH-BERT的源代码和相关数据集可以通过以下链接访问:
https://github.com/jwzhanggy/Graph-Bert
论文链接:https://arxiv.org/pdf/2001.05140v2