文章目录
- 前言
- 1、概述
- 1.1、整体架构
- 1.2、syz-manager进程
- 1.3、syz-fuzzer进程
- 1.4、syz-executor进程
- 1.5、Generate进程
- 1.6、Mutate进程
- 2、安装与使用
- 2.1、源码安装
- 2.1.1、部署系统依赖组件
- 2.1.2、使用源码安装系统
- 2.2、使用方法
- 2.2.1、下载编译测试内核
- 2.2.2、配置测试虚拟机
- 2.2.3、对Linux内核进行Fuzz
- 3、测试用例
- 3.1、对Linux 5.14内核进行Fuzz测试
- 3.1.1、下载编译测试内核
- 3.1.2、配置测试虚拟机
- 3.1.3、对Linux内核进行Fuzz
- 3.2、对Linux 4.14内核进行Fuzz测试
- 3.2.1、下载编译测试内核
- 3.2.2、配置测试虚拟机
- 4、总结
- 4.1、部署架构
- 4.2、漏洞检测对象
- 4.3、漏洞检测方法
- 4.4、种子生成/变异技术
- 5、参考文献
- 总结
前言
本博客的主要内容为Syzkaller的部署、使用与原理分析。本博文内容较长,因为涵盖了Syzkaller的几乎全部内容,从部署的详细过程到如何使用Syzkaller对目标Linux内核进行Fuzz测试,以及对Syzkaller进行漏洞检测的原理分析,相信认真读完本博文,各位读者一定会对Syzkaller有更深的了解。以下就是本篇博客的全部内容了。
1、概述
Syzkaller是一个用于系统内核的Fuzz测试工具,主要用于发现操作系统内核中的漏洞和错误。它是一个开源项目,由谷歌公司开发和维护。Syzkaller的工作原理是通过生成大量随机的系统调用序列,以及输入数据,来Fuzz测试操作系统内核。通过在不同的场景下模拟系统调用和输入数据,Syzkaller可以发现一些潜在的漏洞,例如内存泄漏、空指针引用、死锁等。Syzkaller支持多种操作系统内核,包括Linux、FreeBSD、NetBSD等,并且可以方便地扩展支持新的系统调用和数据类型。通过Syzkaller的使用,开发人员可以提高操作系统内核的安全性和稳定性。Syzkaller具有以下主要特点:
- 自动化测试:Syzkaller是一个自动化的Fuzz测试工具,可以自动生成大量的测试用例,并在目标系统上运行这些测试用例,无需人工干预。
- 系统覆盖广泛:Syzkaller支持多种操作系统内核,包括Linux、FreeBSD、NetBSD等,可以用于不同的操作系统环境中进行测试。
- 高效发现漏洞:通过Fuzz测试的方式,Syzkaller可以在较短的时间内发现系统内核中的各种漏洞和错误,如内存泄漏、空指针引用、死锁等。
- 容易扩展性:Syzkaller的设计考虑了易于扩展性,可以方便地添加新的系统调用和数据类型,以适应不断变化的内核代码结构。
- 持续集成:Syzkaller可以与持续集成系统集成,实现自动化的测试流程,及时发现和修复新的漏洞。
- 开源社区支持:作为一个开源项目,Syzkaller得到了广泛的开源社区支持和贡献,有着活跃的开发者和用户社区,持续改进和更新。
总的来说,Syzkaller是一个强大的工具,对于提高操作系统内核的安全性和稳定性起着至关重要的作用。此外Syzkaller工具基于Go语言、C/C++语言、Roff语言和Python语言开发。
1.1、整体架构
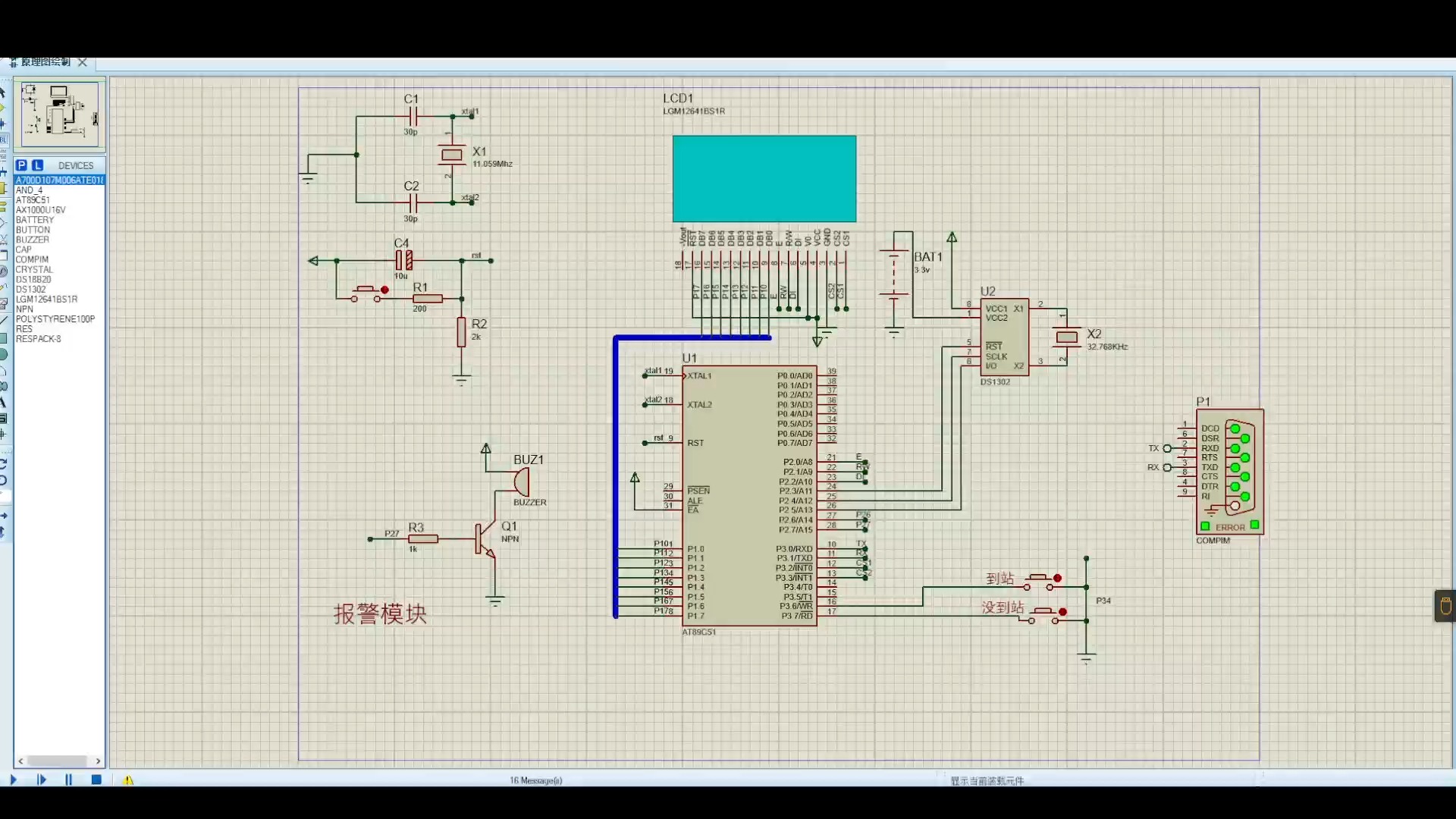
关于Syzkaller的整体架构如下图所示,此图出自How syzkaller works。

其中,红色标签表示对应的配置选项。此外,对于Syzkaller整体架构图中的各个模块的作用解释如下所示:
- syz-manager进程负责启动、监控和重新启动多个虚拟机实例,并在虚拟机内部启动一个syz-fuzzer进程(syz-manager进程通过ssh调用syz-fuzzer进程)。syz-manager还负责持久性语料库和崩溃存储。它在具有稳定内核的主机上运行,该内核不会受到白噪声Fuzz测试负载的影响。
- syz-fuzzer进程运行在可能不稳定的虚拟机中。syz-fuzzer引导Fuzz测试过程(输入生成、变异、最小化等),并通过RPC将触发新覆盖范围的输入发送回syz-manager进程(syz-fuzzer进程和syz-manager进程通过RPC进行通信)。它还启动瞬态的syz-executor进程。
- 每个syz-executor进程执行单个输入(一系列系统调用)。它从syz-fuzzer进程接受要执行的程序以及其对应的测试输入参数,并将测试结果发送回来。它被设计得尽可能简单(以不干扰Fuzz测试过程),用C++编写,编译为静态二进制,并使用共享内存进行通信。
通过以上三个组件的配合,就可以对内核进行Fuzz,最终可以将对内核Fuzz的覆盖率信息以及Fuzz结果反馈给syz-fuzzer。这就是Syzkaller对内核进行Fuzz的全部流程,当然,Syzkaller的实现不仅仅是这三个组件,还有其它复杂,重要的组件/内容,下面我们就将对这三个关键组件以及其它重点组件/内容进行学习。
1.2、syz-manager进程
syz-manager进程是Syzkaller的启动进程,即入口进程。此进程是通过sudo ./bin/syz-manager -config=setting.cfg命令启动,其中-config=setting.cfg作为此命令的参数使用。我们需要关注的是syz-manager这个二进制文件,在Syzkaller中也有对应源码,位于“/syzkaller/syz-manager/manager.go”中。我们从此开始分析。
在源代码的main函数(“/syzkaller/syz-manager/manager.go”源代码文件的第151行)中,进行了一些初始化的操作,不过其中最重要的是RunManager函数,此函数以传入的Fuzz配置作为参数,使Syzkaller工具真正的启动。

RunManager函数实现在“/syzkaller/syz-manager/manager.go”源代码文件的第168行,这段代码使整个管理器程序的入口点,负责初始化管理器并启动主循环来管理VM的创建和运行。
func RunManager(cfg *mgrconfig.Config) {
var vmPool *vm.Pool
// Type "none" is a special case for debugging/development when manager
// does not start any VMs, but instead you start them manually
// and start syz-fuzzer there.
if cfg.Type != "none" {
var err error
vmPool, err = vm.Create(cfg, *flagDebug)
if err != nil {
log.Fatalf("%v", err)
}
}
crashdir := filepath.Join(cfg.Workdir, "crashes")
osutil.MkdirAll(crashdir)
reporter, err := report.NewReporter(cfg)
if err != nil {
log.Fatalf("%v", err)
}
mgr := &Manager{
cfg: cfg,
vmPool: vmPool,
target: cfg.Target,
sysTarget: cfg.SysTarget,
reporter: reporter,
crashdir: crashdir,
startTime: time.Now(),
stats: &Stats{haveHub: cfg.HubClient != ""},
crashTypes: make(map[string]bool),
corpus: make(map[string]CorpusItem),
disabledHashes: make(map[string]struct{}),
memoryLeakFrames: make(map[string]bool),
dataRaceFrames: make(map[string]bool),
fresh: true,
vmStop: make(chan bool),
externalReproQueue: make(chan *Crash, 10),
needMoreRepros: make(chan chan bool),
reproRequest: make(chan chan map[string]bool),
usedFiles: make(map[string]time.Time),
saturatedCalls: make(map[string]bool),
}
mgr.preloadCorpus()
mgr.initStats() // Initializes prometheus variables.
mgr.initHTTP() // Creates HTTP server.
mgr.collectUsedFiles()
// Create RPC server for fuzzers.
mgr.serv, err = startRPCServer(mgr)
if err != nil {
log.Fatalf("failed to create rpc server: %v", err)
}
if cfg.DashboardAddr != "" {
mgr.dash, err = dashapi.New(cfg.DashboardClient, cfg.DashboardAddr, cfg.DashboardKey)
if err != nil {
log.Fatalf("failed to create dashapi connection: %v", err)
}
}
if !cfg.AssetStorage.IsEmpty() {
mgr.assetStorage, err = asset.StorageFromConfig(cfg.AssetStorage, mgr.dash)
if err != nil {
log.Fatalf("failed to init asset storage: %v", err)
}
}
go func() {
for lastTime := time.Now(); ; {
time.Sleep(10 * time.Second)
now := time.Now()
diff := now.Sub(lastTime)
lastTime = now
mgr.mu.Lock()
if mgr.firstConnect.IsZero() {
mgr.mu.Unlock()
continue
}
mgr.fuzzingTime += diff * time.Duration(atomic.LoadUint32(&mgr.numFuzzing))
executed := mgr.stats.execTotal.get()
crashes := mgr.stats.crashes.get()
corpusCover := mgr.stats.corpusCover.get()
corpusSignal := mgr.stats.corpusSignal.get()
maxSignal := mgr.stats.maxSignal.get()
triageQLen := len(mgr.candidates)
mgr.mu.Unlock()
numReproducing := atomic.LoadUint32(&mgr.numReproducing)
numFuzzing := atomic.LoadUint32(&mgr.numFuzzing)
log.Logf(0, "VMs %v, executed %v, cover %v, signal %v/%v, crashes %v, repro %v, triageQLen %v",
numFuzzing, executed, corpusCover, corpusSignal, maxSignal, crashes, numReproducing, triageQLen)
}
}()
if *flagBench != "" {
mgr.initBench()
}
if mgr.dash != nil {
go mgr.dashboardReporter()
go mgr.dashboardReproTasks()
}
osutil.HandleInterrupts(vm.Shutdown)
if mgr.vmPool == nil {
log.Logf(0, "no VMs started (type=none)")
log.Logf(0, "you are supposed to start syz-fuzzer manually as:")
log.Logf(0, "syz-fuzzer -manager=manager.ip:%v [other flags as necessary]", mgr.serv.port)
<-vm.Shutdown
return
}
mgr.vmLoop()
}
这段代码的主要逻辑或者主要功能如下:
- 首先,它创建一个VM池,如果配置不是
none,则通过调用vm.Create函数来创建VM池。 - 然后,它创建一个用于存储崩溃报告的目录,并初始化崩溃报告的报告器。
- 接着,它初始化了一个Manager结构体,其中包含了管理器的各种配置和状态信息。
- 它预加载了语料库(corpus)、初始化了统计信息、创建了HTTP服务器,并收集了已使用的文件。
- 接下来,它创建了用于与Fuzzer之间进行RPC通信的服务器。
- 如果配置中提供了仪表板地址,则创建了一个与仪表板通信的客户端。
- 如果配置中定义了资产存储,则初始化资产存储。
- 启动了一个Goroutine来定期打印虚拟机的状态信息。
- 如果配置中指定了基准测试文件,则初始化基准测试。
- 如果存在仪表板客户端,则启动了两个Goroutine来定期报告状态和处理重现任务。
- 程序捕获了中断信号,以便在接收到中断信号时进行清理工作。
- 最后,如果VM池为空,则打印一条消息提示用户手动启动Fuzzer,否则启动主循环,该循环将不断创建和管理VM。
在这段函数中,我们只需要关注上面标红的两部分,即:
-
预加载语料库(Corpus),即
mgr.preloadCorpus():
此功能是由实现在“/syzkaller/syz-manager/manager.go”中第606行的preloadCorpus函数完成的。

这个函数主要完成了两个操作:-
加载工作目录中的语料库,即“corpus.db”。如果此语料库不存在则创建一个新的空语料库文件。在我们的测试中,工作目录设置为“/syzkaller/workdir/”,其中的语料库如下所示:

-
加载种子文件,这些种子文件都是由作者事先设计好的,存储在“/syzkaller/sys/target/test/”中,其中“target”就是我们进行Fuzz测试的目标,在我们的例子中,由于测试的是Linux系统,所以“target”的值为“linux”。我们可以使用这些定义好的种子文件中的内容,对目标进行Fuzz和变异以获得更高的覆盖率:

我们可以随便打开一个种子文件查看其中的内容,比如打开名为“ping”的这个种子文件。

这段代码是使用socket系统调用创建了一个基于ICMP协议的套接字,并将其文件描述符赋值给变量r0。接着,调用close系统调用关闭了这个套接字,释放了相关的资源。具体来说:socket$inet_icmp(AUTO, AUTO, AUTO)是创建一个基于ICMP协议的套接字。在这里,AUTO表示自动选择适当的参数。该系统调用创建了一个用于发送和接收ICMP协议数据包的套接字,并返回一个文件描述符,即r0。close(r0)是关闭之前创建的套接字。这是一种良好的做法,可以释放已经打开的资源,避免资源泄漏和占用。
-
-
启动主循环,即
mgr.vmLoop():
此功能是由实现在“/syzkaller/syz-manager/manager.go”中第335行的vmLoop函数完成的。
// Manager needs to be refactored (#605).
// nolint: gocyclo, gocognit, funlen
func (mgr *Manager) vmLoop() {
log.Logf(0, "booting test machines...")
log.Logf(0, "wait for the connection from test machine...")
instancesPerRepro := 3
vmCount := mgr.vmPool.Count()
maxReproVMs := vmCount - mgr.cfg.FuzzingVMs
if instancesPerRepro > maxReproVMs && maxReproVMs > 0 {
instancesPerRepro = maxReproVMs
}
instances := SequentialResourcePool(vmCount, 10*time.Second*mgr.cfg.Timeouts.Scale)
runDone := make(chan *RunResult, 1)
pendingRepro := make(map[*Crash]bool)
reproducing := make(map[string]bool)
var reproQueue []*Crash
reproDone := make(chan *ReproResult, 1)
stopPending := false
shutdown := vm.Shutdown
for shutdown != nil || instances.Len() != vmCount {
mgr.mu.Lock()
phase := mgr.phase
mgr.mu.Unlock()
for crash := range pendingRepro {
if reproducing[crash.Title] {
continue
}
delete(pendingRepro, crash)
if !mgr.needRepro(crash) {
continue
}
log.Logf(1, "loop: add to repro queue '%v'", crash.Title)
reproducing[crash.Title] = true
reproQueue = append(reproQueue, crash)
}
log.Logf(1, "loop: phase=%v shutdown=%v instances=%v/%v %+v repro: pending=%v reproducing=%v queued=%v",
phase, shutdown == nil, instances.Len(), vmCount, instances.Snapshot(),
len(pendingRepro), len(reproducing), len(reproQueue))
canRepro := func() bool {
return phase >= phaseTriagedHub && len(reproQueue) != 0 &&
(int(atomic.LoadUint32(&mgr.numReproducing))+1)*instancesPerRepro <= maxReproVMs
}
if shutdown != nil {
for canRepro() {
vmIndexes := instances.Take(instancesPerRepro)
if vmIndexes == nil {
break
}
last := len(reproQueue) - 1
crash := reproQueue[last]
reproQueue[last] = nil
reproQueue = reproQueue[:last]
atomic.AddUint32(&mgr.numReproducing, 1)
log.Logf(0, "loop: starting repro of '%v' on instances %+v", crash.Title, vmIndexes)
go func() {
reproDone <- mgr.runRepro(crash, vmIndexes, instances.Put)
}()
}
for !canRepro() {
idx := instances.TakeOne()
if idx == nil {
break
}
log.Logf(1, "loop: starting instance %v", *idx)
go func() {
crash, err := mgr.runInstance(*idx)
runDone <- &RunResult{*idx, crash, err}
}()
}
}
var stopRequest chan bool
if !stopPending && canRepro() {
stopRequest = mgr.vmStop
}
wait:
select {
case <-instances.Freed:
// An instance has been released.
case stopRequest <- true:
log.Logf(1, "loop: issued stop request")
stopPending = true
case res := <-runDone:
log.Logf(1, "loop: instance %v finished, crash=%v", res.idx, res.crash != nil)
if res.err != nil && shutdown != nil {
log.Logf(0, "%v", res.err)
}
stopPending = false
instances.Put(res.idx)
// On shutdown qemu crashes with "qemu: terminating on signal 2",
// which we detect as "lost connection". Don't save that as crash.
if shutdown != nil && res.crash != nil {
needRepro := mgr.saveCrash(res.crash)
if needRepro {
log.Logf(1, "loop: add pending repro for '%v'", res.crash.Title)
pendingRepro[res.crash] = true
}
}
case res := <-reproDone:
atomic.AddUint32(&mgr.numReproducing, ^uint32(0))
crepro := false
title := ""
if res.repro != nil {
crepro = res.repro.CRepro
title = res.repro.Report.Title
}
log.Logf(0, "loop: repro on %+v finished '%v', repro=%v crepro=%v desc='%v'"+
" hub=%v from_dashboard=%v",
res.instances, res.report0.Title, res.repro != nil, crepro, title,
res.fromHub, res.fromDashboard,
)
if res.err != nil {
reportReproError(res.err)
}
delete(reproducing, res.report0.Title)
if res.repro == nil {
if res.fromHub {
log.Logf(1, "repro '%v' came from syz-hub, not reporting the failure",
res.report0.Title)
} else {
log.Logf(1, "report repro failure of '%v'", res.report0.Title)
mgr.saveFailedRepro(res.report0, res.stats)
}
} else {
mgr.saveRepro(res)
}
case <-shutdown:
log.Logf(1, "loop: shutting down...")
shutdown = nil
case crash := <-mgr.externalReproQueue:
log.Logf(1, "loop: got repro request")
pendingRepro[crash] = true
case reply := <-mgr.needMoreRepros:
reply <- phase >= phaseTriagedHub &&
len(reproQueue)+len(pendingRepro)+len(reproducing) == 0
goto wait
case reply := <-mgr.reproRequest:
repros := make(map[string]bool)
for title := range reproducing {
repros[title] = true
}
reply <- repros
goto wait
}
}
}
这段代码主要负责管理虚拟机实例的生命周期,包括启动、运行和停止,并根据不同的事件和状态变化进行相应的处理,以确保整个系统能够正常运行并达到预期的效果,其主要逻辑或者主要功能如下:
- 初始化准备:
- 在方法开始处,首先输出一些日志,指示管理器正在启动测试机器,并等待测试机器的连接。
- 初始化一些变量,包括实例的最大数量、等待运行结果的通道等。
- 循环处理实例:
- 这部分是整个方法的核心,它通过一个无限循环来不断处理虚拟机实例的状态变化和事件。
- 循环中会不断检查虚拟机实例的状态,以确定是否需要启动新的实例、停止实例或者处理其他事件。
- 处理事件:
- 在循环中,通过不同的
case分支处理不同的事件和状态变化: - 当虚拟机实例完成运行时,会将实例放回实例池中,并根据是否发生漏洞来保存相关信息。
- 当有新的漏洞需要重现时,会启动一定数量的虚拟机实例,并将漏洞信息添加到重现队列中。
- 当收到停止请求时,会发送停止信号给正在运行的虚拟机实例,并将
shutdown标记设为nil,以退出循环。 - 当收到其他来自外部的请求时,会相应地处理并进行相应的操作,如添加重现请求到队列中或回复重现请求等。
- 在循环中,通过不同的
- 最终结束:
- 当所有实例都停止运行时,循环结束,方法执行完成。
在这段代码中,我们只需要关注循环处理实例(注意,这是一个无限循环执行的代码)中运行具体实例的代码,即:

这行代码调用了mgr.runInstance(*idx)函数,该函数的作用是在虚拟机上运行一个实例,并返回实例的崩溃信息(如果有)以及可能出现的错误。因此,这行代码负责启动一个测试实例,并接收其返回的崩溃信息和错误信息。
所以说这一行代码才是我们下面要分析的核心,因为此函数才是Syzkaller真正开始进行Fuzz的函数,关于Syzkaller如何进行Fuzz的过程,请参阅下一章节。
1.3、syz-fuzzer进程
上一章节我们分析了,Syzkaller最终是通过调用runInstance函数来进行Fuzz的。所以我们从该函数开始进行下面的分析。runInstance函数实现在“/syzkaller/syz-manager/manager.go”文件的第763行。

这段代码的作用是在虚拟机上运行一个实例并处理可能的崩溃情况。具体来说,它的主要步骤包括:
- 文件检查:首先,它会调用
mgr.checkUsedFiles()方法,确保正在使用的文件没有被更改。 - 实例名称构建:然后,它会根据传入的索引参数构建实例的名称,这个名称以 vm- 开头,后面跟着虚拟机的索引号。
- 运行实例:接着,它调用
mgr.runInstanceInner()方法,在虚拟机上运行实例。这个方法返回了运行结果、虚拟机的信息以及可能的错误。 - 获取虚拟机信息:在运行实例后,它会获取虚拟机的信息,并将其添加到机器信息中。
- 错误处理:如果在运行实例的过程中出现了错误,那么函数会直接返回该错误,不再进行下一步操作。
- 崩溃处理:如果运行实例后发生了崩溃,函数会创建一个
Crash结构体,其中包含了崩溃的相关信息,比如虚拟机索引、崩溃报告等。 - 返回结果:最后,根据实际情况,函数会返回
nil或者包含了崩溃信息的Crash结构体,以及可能的错误。
在这段代码中,我们主要关注运行实例部分的函数调用,即调用的runInstanceInner函数。此函数实现在“/syzkaller/syz-manager/manager.go”文件的第790行。
func (mgr *Manager) runInstanceInner(index int, instanceName string) (*report.Report, []byte, error) {
inst, err := mgr.vmPool.Create(index)
if err != nil {
return nil, nil, fmt.Errorf("failed to create instance: %w", err)
}
defer inst.Close()
fwdAddr, err := inst.Forward(mgr.serv.port)
if err != nil {
return nil, nil, fmt.Errorf("failed to setup port forwarding: %w", err)
}
fuzzerBin, err := inst.Copy(mgr.cfg.FuzzerBin)
if err != nil {
return nil, nil, fmt.Errorf("failed to copy binary: %w", err)
}
// If ExecutorBin is provided, it means that syz-executor is already in the image,
// so no need to copy it.
executorBin := mgr.sysTarget.ExecutorBin
if executorBin == "" {
executorBin, err = inst.Copy(mgr.cfg.ExecutorBin)
if err != nil {
return nil, nil, fmt.Errorf("failed to copy binary: %w", err)
}
}
fuzzerV := 0
procs := mgr.cfg.Procs
if *flagDebug {
fuzzerV = 100
procs = 1
}
// Run the fuzzer binary.
start := time.Now()
atomic.AddUint32(&mgr.numFuzzing, 1)
defer atomic.AddUint32(&mgr.numFuzzing, ^uint32(0))
args := &instance.FuzzerCmdArgs{
Fuzzer: fuzzerBin,
Executor: executorBin,
Name: instanceName,
OS: mgr.cfg.TargetOS,
Arch: mgr.cfg.TargetArch,
FwdAddr: fwdAddr,
Sandbox: mgr.cfg.Sandbox,
Procs: procs,
Verbosity: fuzzerV,
Cover: mgr.cfg.Cover,
Debug: *flagDebug,
Test: false,
Runtest: false,
Optional: &instance.OptionalFuzzerArgs{
Slowdown: mgr.cfg.Timeouts.Slowdown,
RawCover: mgr.cfg.RawCover,
SandboxArg: mgr.cfg.SandboxArg,
PprofPort: inst.PprofPort(),
ResetAccState: mgr.cfg.Experimental.ResetAccState,
},
}
cmd := instance.FuzzerCmd(args)
outc, errc, err := inst.Run(mgr.cfg.Timeouts.VMRunningTime, mgr.vmStop, cmd)
if err != nil {
return nil, nil, fmt.Errorf("failed to run fuzzer: %w", err)
}
var vmInfo []byte
rep := inst.MonitorExecution(outc, errc, mgr.reporter, vm.ExitTimeout)
if rep == nil {
// This is the only "OK" outcome.
log.Logf(0, "%s: running for %v, restarting", instanceName, time.Since(start))
} else {
vmInfo, err = inst.Info()
if err != nil {
vmInfo = []byte(fmt.Sprintf("error getting VM info: %v\n", err))
}
}
return rep, vmInfo, nil
}
这段函数的主要功能是在虚拟机中运行Fuzz测试程序,并监视其执行情况。它执行了以下关键步骤:
- 创建虚拟机实例:
- 通过
mgr.vmPool.Create(index)创建虚拟机实例inst,其中index是虚拟机的索引。 - 使用
defer inst.Close()来确保在函数结束时关闭虚拟机实例,以释放资源。
- 通过
- 设置端口转发:
- 调用
inst.Forward(mgr.serv.port)来设置端口转发,将管理器服务的端口转发到虚拟机中,返回转发后的地址fwdAddr。
- 调用
- 复制二进制文件:
- 使用
inst.Copy()方法复制Fuzz测试程序的二进制文件和执行器的二进制文件到虚拟机实例中,分别保存在fuzzerBin和executorBin中。
- 使用
- 配置Fuzz测试执行参数:
- 根据调试模式设置
fuzzerV和procs,调试模式下fuzzerV为100,procs为1;否则根据配置文件中的设置来确定。 - 构建
args结构体,其中包含Fuzz测试执行所需的各种参数,如二进制文件路径、虚拟机信息、沙箱设置、并发度、覆盖率等。
- 根据调试模式设置
- 启动Fuzz测试程序:
- 使用
instance.FuzzerCmd(args)返回一个用于执行Fuzz测试程序的命令对象,该对象包含了Fuzzer的相关参数信息,如执行路径、执行器(Executor)路径、实例名称等。 - 调用
inst.Run()方法启动Fuzz测试程序,传入执行时间限制、停止信号和执行命令,获取输出管道outc、错误管道errc和可能的错误。
- 使用
- 监视Fuzz测试执行:
- 通过
inst.MonitorExecution()方法监视Fuzz测试程序的执行情况,传入输出管道、错误管道、报告器和虚拟机超时退出时间,获取执行报告rep。 - 如果没有执行报告,则重新启动虚拟机实例,并记录虚拟机信息到
vmInfo中。
- 通过
- 返回执行结果:
- 返回执行报告
rep、虚拟机信息vmInfo和可能的错误。
- 返回执行报告
这段代码看起来很长,不过我们并不需要关心其它内容,我们只需要关注上面我们标红的位置的代码,即:
-
复制二进制文件,即
inst.Copy(mgr.cfg.FuzzerBin)和inst.Copy(mgr.cfg.ExecutorBin):
在这里我们主要关注在“/syzkaller/vm/isolated/isolated.go”文件中的第285行实现的Copy函数。

可以发现,此函数的目的是将在Syzkaller安装阶段编译好的“syz-fuzzer”和“syz-executor”二进制文件复制到虚拟机中的目标目录中。这个目标目录由Syzkaller启动时加载的名为“setting.cfg”的配置文件中定义的“vm.target_dir”的值确定的,即“/fuzzdir”。所以最终会将“syz-fuzzer”和“syz-executor”复制到虚拟机中的“/fuzzdir”目录中。 -
启动Fuzz测试程序:
启动Fuzz测试程序的过程包含两个操作,即instance.FuzzerCmd(args)和inst.Run(mgr.cfg.Timeouts.VMRunningTime, mgr.vmStop, cmd),我们逐一分析:-
instance.FuzzerCmd(args):
该函数具体实现在“syzkaller/pkg/instance/instance.go”中的第483行:

这个函数根据传入的参数生成对应的命令行参数字符串,其中包括了Fuzzer的路径、执行器的路径、实例的名称、架构、操作系统、远程管理器地址、沙盒模式、并发进程数、覆盖率选项、调试模式、是否执行测试以及其它可选参数。具体来说,做了如下操作:osArg := "":初始化一个空字符串,用于存储操作系统参数。if targets.Get(args.OS, args.Arch).HostFuzzer {...}:检查目标操作系统是否需要指定操作系统参数。如果需要,会设置osArg为-os=操作系统。runtestArg := "":初始化一个空字符串,用于存储是否执行测试参数。if args.Runtest {...}:检查是否需要执行测试。如果需要,会设置runtestArg为-runtest。verbosityArg := "":初始化一个空字符串,用于存储调试详细级别参数。if args.Verbosity != 0 {...}:检查调试详细级别是否为零。如果不为零,会设置verbosityArg为-vv=详细级别。optionalArg := "":初始化一个空字符串,用于存储可选参数。if args.Optional != nil {...}:检查是否有可选参数。如果有,会构建一个包含慢速度、原始覆盖率、沙盒参数、性能分析端口和重置访问状态的参数列表,并将其设置为optionalArg。return fmt.Sprintf(...):使用格式化字符串构建命令行参数字符串,其中包括Fuzzer路径、执行器路径、实例名称、架构、操作系统参数、远程管理器地址、沙盒模式、并发进程数、覆盖率选项、调试模式、是否执行测试、以及可选参数。
总之,该函数最后一步是核心(上面标红的部分),即此函数会返回类似
/syz-fuzzer -executor=/syz-executor -name=vm-0 -arch=amd64 -manager=10.0.2.10:33185 -procs=1 -leak=false -cover=true -sandbox=none -debug=true -v=100的命令。 -
inst.Run(mgr.cfg.Timeouts.VMRunningTime, mgr.vmStop, cmd):
该函数具体实现在“syzkaller/vm/isolated/isolated.go”中的第316行
-
func (inst *instance) Run(timeout time.Duration, stop <-chan bool, command string) (
<-chan []byte, <-chan error, error) {
args := append(vmimpl.SSHArgs(inst.debug, inst.sshKey, inst.targetPort), inst.sshUser+"@"+inst.targetAddr)
dmesg, err := vmimpl.OpenRemoteConsole("ssh", args...)
if err != nil {
return nil, nil, err
}
rpipe, wpipe, err := osutil.LongPipe()
if err != nil {
dmesg.Close()
return nil, nil, err
}
args = vmimpl.SSHArgsForward(inst.debug, inst.sshKey, inst.targetPort, inst.forwardPort)
if inst.cfg.Pstore {
args = append(args, "-o", "ServerAliveInterval=6")
args = append(args, "-o", "ServerAliveCountMax=5")
}
args = append(args, inst.sshUser+"@"+inst.targetAddr, "cd "+inst.cfg.TargetDir+" && exec "+command)
if inst.debug {
log.Logf(0, "running command: ssh %#v", args)
}
cmd := osutil.Command("ssh", args...)
cmd.Stdout = wpipe
cmd.Stderr = wpipe
if err := cmd.Start(); err != nil {
dmesg.Close()
rpipe.Close()
wpipe.Close()
return nil, nil, err
}
wpipe.Close()
var tee io.Writer
if inst.debug {
tee = os.Stdout
}
merger := vmimpl.NewOutputMerger(tee)
merger.Add("dmesg", dmesg)
merger.Add("ssh", rpipe)
return vmimpl.Multiplex(cmd, merger, dmesg, timeout, stop, inst.closed, inst.debug)
}
该函数主要是在虚拟机中执行上面我们构造好的命令,即用于在虚拟机实例中执行命令。其具体函数逻辑如下:
args := append(vmimpl.SSHArgs(inst.debug, inst.sshKey, inst.targetPort), inst.sshUser+"@"+inst.targetAddr):构建SSH连接参数,包括调试模式、SSH密钥、目标端口和目标地址。dmesg, err := vmimpl.OpenRemoteConsole("ssh", args...):通过SSH连接打开远程控制台,用于获取虚拟机的消息记录。rpipe, wpipe, err := osutil.LongPipe():创建一个长管道,用于读取命令的标准输出和标准错误。args = vmimpl.SSHArgsForward(inst.debug, inst.sshKey, inst.targetPort, inst.forwardPort):构建SSH端口转发参数,包括调试模式、SSH密钥、目标端口和转发端口。args = append(args, inst.sshUser+"@"+inst.targetAddr, "cd "+inst.cfg.TargetDir+" && exec "+command):向SSH参数列表中添加连接地址和要执行的命令。cmd := osutil.Command("ssh", args...):创建一个执行SSH命令的命令对象。cmd.Stdout = wpipe和cmd.Stderr = wpipe:将命令的标准输出和标准错误重定向到写入端口。cmd.Start():启动SSH命令。wpipe.Close():关闭写入端口,以便SSH命令能够正常执行。merger := vmimpl.NewOutputMerger(tee):创建一个输出合并器,用于将来自不同源的输出合并到一起。merger.Add("dmesg", dmesg)和merger.Add("ssh", rpipe):向输出合并器添加虚拟机的消息记录和SSH命令的输出管道。return vmimpl.Multiplex(cmd, merger, dmesg, timeout, stop, inst.closed, inst.debug):返回一个多路复用的结果,其中包括命令执行的标准输出和标准错误,以及一个用于控制执行的通道和错误通道。
该段代码的核心是第8步(上面标红的部分),这行代码表示终于要在虚拟机中进行Fuzz了,即真正的执行我们刚刚构造好的命令。所以说,此时才开始要真正的分析syz-fuzzer进程的相关代码。
根据以上分析,我们要在虚拟机中执行我们刚刚构造好的命令,该命令调用了syz-fuzzer,并传入了相关参数(要记得,有一个参数为syz-executor,不过这是我们下一章节要讲的内容),所以我们首先从“/syzkaller/syz-fuzzer/fuzzer.go”中第161行实现的main函数开始分析。
// nolint: funlen
func main() {
debug.SetGCPercent(50)
var (
flagName = flag.String("name", "test", "unique name for manager")
flagOS = flag.String("os", runtime.GOOS, "target OS")
flagArch = flag.String("arch", runtime.GOARCH, "target arch")
flagManager = flag.String("manager", "", "manager rpc address")
flagProcs = flag.Int("procs", 1, "number of parallel test processes")
flagOutput = flag.String("output", "stdout", "write programs to none/stdout/dmesg/file")
flagTest = flag.Bool("test", false, "enable image testing mode") // used by syz-ci
flagRunTest = flag.Bool("runtest", false, "enable program testing mode") // used by pkg/runtest
flagRawCover = flag.Bool("raw_cover", false, "fetch raw coverage")
flagPprofPort = flag.Int("pprof_port", 0, "HTTP port for the pprof endpoint (disabled if 0)")
// Experimental flags.
flagResetAccState = flag.Bool("reset_acc_state", false, "restarts executor before most executions")
)
defer tool.Init()()
outputType := parseOutputType(*flagOutput)
log.Logf(0, "fuzzer started")
target, err := prog.GetTarget(*flagOS, *flagArch)
if err != nil {
log.SyzFatalf("%v", err)
}
config, execOpts, err := ipcconfig.Default(target)
if err != nil {
log.SyzFatalf("failed to create default ipc config: %v", err)
}
if *flagRawCover {
execOpts.Flags &^= ipc.FlagDedupCover
}
timeouts := config.Timeouts
sandbox := ipc.FlagsToSandbox(config.Flags)
shutdown := make(chan struct{})
osutil.HandleInterrupts(shutdown)
go func() {
// Handles graceful preemption on GCE.
<-shutdown
log.Logf(0, "SYZ-FUZZER: PREEMPTED")
os.Exit(1)
}()
if *flagPprofPort != 0 {
setupPprofHandler(*flagPprofPort)
}
checkArgs := &checkArgs{
target: target,
sandbox: sandbox,
ipcConfig: config,
ipcExecOpts: execOpts,
gitRevision: prog.GitRevision,
targetRevision: target.Revision,
}
if *flagTest {
testImage(*flagManager, checkArgs)
return
}
machineInfo, modules := collectMachineInfos(target)
log.Logf(0, "dialing manager at %v", *flagManager)
manager, err := rpctype.NewRPCClient(*flagManager, timeouts.Scale)
if err != nil {
log.SyzFatalf("failed to create an RPC client: %v ", err)
}
log.Logf(1, "connecting to manager...")
a := &rpctype.ConnectArgs{
Name: *flagName,
MachineInfo: machineInfo,
Modules: modules,
}
r := &rpctype.ConnectRes{}
if err := manager.Call("Manager.Connect", a, r); err != nil {
log.SyzFatalf("failed to call Manager.Connect(): %v ", err)
}
featureFlags, err := csource.ParseFeaturesFlags("none", "none", true)
if err != nil {
log.SyzFatalf("%v", err)
}
if r.CoverFilterBitmap != nil {
if err := osutil.WriteFile("syz-cover-bitmap", r.CoverFilterBitmap); err != nil {
log.SyzFatalf("failed to write syz-cover-bitmap: %v", err)
}
}
if r.CheckResult == nil {
checkArgs.gitRevision = r.GitRevision
checkArgs.targetRevision = r.TargetRevision
checkArgs.enabledCalls = r.EnabledCalls
checkArgs.allSandboxes = r.AllSandboxes
checkArgs.featureFlags = featureFlags
r.CheckResult, err = checkMachine(checkArgs)
if err != nil {
if r.CheckResult == nil {
r.CheckResult = new(rpctype.CheckArgs)
}
r.CheckResult.Error = err.Error()
}
r.CheckResult.Name = *flagName
if err := manager.Call("Manager.Check", r.CheckResult, nil); err != nil {
log.SyzFatalf("Manager.Check call failed: %v", err)
}
if r.CheckResult.Error != "" {
log.SyzFatalf("%v", r.CheckResult.Error)
}
} else {
target.UpdateGlobs(r.CheckResult.GlobFiles)
if err = host.Setup(target, r.CheckResult.Features, featureFlags, config.Executor); err != nil {
log.SyzFatalf("%v", err)
}
}
log.Logf(0, "syscalls: %v", len(r.CheckResult.EnabledCalls[sandbox]))
for _, feat := range r.CheckResult.Features.Supported() {
log.Logf(0, "%v: %v", feat.Name, feat.Reason)
}
createIPCConfig(r.CheckResult.Features, config)
if *flagRunTest {
runTest(target, manager, *flagName, config.Executor)
return
}
needPoll := make(chan struct{}, 1)
needPoll <- struct{}{}
fuzzer := &Fuzzer{
name: *flagName,
outputType: outputType,
config: config,
execOpts: execOpts,
workQueue: newWorkQueue(*flagProcs, needPoll),
needPoll: needPoll,
manager: manager,
target: target,
timeouts: timeouts,
faultInjectionEnabled: r.CheckResult.Features[host.FeatureFault].Enabled,
comparisonTracingEnabled: r.CheckResult.Features[host.FeatureComparisons].Enabled,
corpusHashes: make(map[hash.Sig]struct{}),
checkResult: r.CheckResult,
fetchRawCover: *flagRawCover,
noMutate: r.NoMutateCalls,
stats: make([]uint64, StatCount),
// Queue no more than ~3 new inputs / proc.
parallelNewInputs: make(chan struct{}, int64(3**flagProcs)),
resetAccState: *flagResetAccState,
}
gateCallback := fuzzer.useBugFrames(r, *flagProcs)
fuzzer.gate = ipc.NewGate(gateSize, gateCallback)
for needCandidates, more := true, true; more; needCandidates = false {
more = fuzzer.poll(needCandidates, nil)
// This loop lead to "no output" in qemu emulation, tell manager we are not dead.
log.Logf(0, "fetching corpus: %v, signal %v/%v (executing program)",
len(fuzzer.corpus), len(fuzzer.corpusSignal), len(fuzzer.maxSignal))
}
calls := make(map[*prog.Syscall]bool)
for _, id := range r.CheckResult.EnabledCalls[sandbox] {
calls[target.Syscalls[id]] = true
}
fuzzer.choiceTable = target.BuildChoiceTable(fuzzer.corpus, calls)
if r.CoverFilterBitmap != nil {
fuzzer.execOpts.Flags |= ipc.FlagEnableCoverageFilter
}
log.Logf(0, "starting %v fuzzer processes", *flagProcs)
for pid := 0; pid < *flagProcs; pid++ {
proc, err := newProc(fuzzer, pid)
if err != nil {
log.SyzFatalf("failed to create proc: %v", err)
}
fuzzer.procs = append(fuzzer.procs, proc)
go proc.loop()
}
fuzzer.pollLoop()
}
该函数主要负责程序的初始化、连接管理器、执行测试和处理测试结果等任务,是整个程序的入口和控制中心。其主要逻辑如下:
- 设置垃圾回收参数,这里将GC的百分比设置为50%。
- 解析命令行参数,包括程序名称、目标操作系统、目标架构、管理器的地址、并行测试进程数量等。
- 确定输出方式,如将程序写入
stdout、写入文件等。 - 创建目标环境的配置信息和执行选项,这包括目标操作系统的IPC配置、沙箱设置等。
- 处理程序中断信号,以便在收到中断信号时做出相应处理,这里使用了Goroutine监听中断信号。
- 如果指定了pprof端口,则设置pprof处理函数。
- 检查测试目标的特性,并根据需要更新全局环境配置,主要是进行环境的初始化和配置。
- 与管理器建立连接,这里通过RPC调用
Manager.Connect函数实现。 - 根据管理器返回的结果进行进一步处理,主要是检查测试环境和特性,若有错误则输出错误信息并退出。
- 通过RPC客户端调用RPC服务器上名为“Manager”的服务的
Check方法来对客户端的请求进行检查,并加载语料库和种子到服务器/虚拟机中。 - 根据程序运行模式(Fuzz测试模式或测试镜像模式),并执行相应的测试操作。
- 为给定的Fuzzer对象构建选择表(Choice Table)。
- 在需要时启动并发测试进程,根据并行测试进程数量创建相应数量的测试进程。
- 进行Fuzzer的轮询循环,定期检查和处理一些事务,包括生成新的候选输入、记录统计信息以及向管理器报告状态。
在上面的代码中,核心功能为10.、12.、13.和14(即上面标红的部分),这些功能才是Fuzz启动的准备工作和入口程序。下面我们将对这四部分功能进行详细分析:
- 通过RPC客户端调用RPC服务器上名为“Manager”的服务的
Check方法来对客户端的请求进行检查,并加载语料库和种子到服务器/虚拟机中(即manager.Call("Manager.Check", r.CheckResult, nil)函数调用):
此功能是由“/syzkaller/syz-manager/rpc.go”中的第213行实现的Check函数完成的。在此函数中,我们只需要关注machineChecked函数。

该函数实现在“/syzkaller/syz-manager/manager.go”中的第1401行。其主要功能是更新Manager结构体中的一些状态,包括保存最新的检查结果、更新目标的启用系统调用列表、更新全局环境的文件列表(Globs),以及加载语料库和种子(Corpus)。
在这里我们着重关注loadCorpus这个函数,因为该函数最终实现了向虚拟机中加载语料库和种子的功能。该函数实现在“/syzkaller/syz-manager/manager.go”中的第632行。
func (mgr *Manager) loadCorpus() {
// By default we don't re-minimize/re-smash programs from corpus,
// it takes lots of time on start and is unnecessary.
// However, on version bumps we can selectively re-minimize/re-smash.
minimized, smashed := true, true
switch mgr.corpusDB.Version {
case 0:
// Version 0 had broken minimization, so we need to re-minimize.
minimized = false
fallthrough
case 1:
// Version 1->2: memory is preallocated so lots of mmaps become unnecessary.
minimized = false
fallthrough
case 2:
// Version 2->3: big-endian hints.
smashed = false
fallthrough
case 3:
// Version 3->4: to shake things up.
minimized = false
fallthrough
case currentDBVersion:
}
broken := 0
for key, rec := range mgr.corpusDB.Records {
if !mgr.loadProg(rec.Val, minimized, smashed) {
mgr.corpusDB.Delete(key)
broken++
}
}
mgr.fresh = len(mgr.corpusDB.Records) == 0
corpusSize := len(mgr.candidates)
log.Logf(0, "%-24v: %v (deleted %v broken)", "corpus", corpusSize, broken)
for _, seed := range mgr.seeds {
mgr.loadProg(seed, true, false)
}
log.Logf(0, "%-24v: %v/%v", "seeds", len(mgr.candidates)-corpusSize, len(mgr.seeds))
mgr.seeds = nil
// We duplicate all inputs in the corpus and shuffle the second part.
// This solves the following problem. A fuzzer can crash while triaging candidates,
// in such case it will also lost all cached candidates. Or, the input can be somewhat flaky
// and doesn't give the coverage on first try. So we give each input the second chance.
// Shuffling should alleviate deterministically losing the same inputs on fuzzer crashing.
mgr.candidates = append(mgr.candidates, mgr.candidates...)
shuffle := mgr.candidates[len(mgr.candidates)/2:]
rand.Shuffle(len(shuffle), func(i, j int) {
shuffle[i], shuffle[j] = shuffle[j], shuffle[i]
})
if mgr.phase != phaseInit {
panic(fmt.Sprintf("loadCorpus: bad phase %v", mgr.phase))
}
mgr.phase = phaseLoadedCorpus
}
这个方法是用于加载语料库和种子并进行一系列的预处理,以便后续的Fuzz测试可以基于这些数据进行。具体来说,这个方法做了以下几件事情:
- 根据语料库的版本号进行一些预处理。根据不同版本的语料库可能需要重新进行最小化(minimization)和粉碎(smashing)等操作。
- 遍历语料库/种子文件中的每个记录,并将其加载到管理器中。
- 更新
Manager结构体中的相关状态信息,包括语料库的新鲜度(fresh)、候选程序的数量以及种子程序的数量。 - 对加载后的语料库进行处理,将其中的输入进行重复并进行乱序处理,以防止在Fuzz测试过程中丢失重要输入。
- 最后,检查语料库加载的阶段是否正确,并更新
Manager结构体的加载阶段状态。
在以上操作中,我们着眼于标红的部分,即“遍历语料库/种子文件中的每个记录,并将其加载到管理器中”,这部分的代码实现为mgr.loadProg(rec.Val, minimized, smashed)。该函数实现在“/syzkaller/syz-manager/manager.go”中的第689行。

该函数的主要目的是加载程序到管理器中。它接收一个字节切片data,以及两个布尔值minimized和smashed。在加载程序之前,它会调用checkProgram函数来检查程序是否有效,并且会检查程序中是否包含禁用的系统调用。如果程序中包含了禁用的系统调用,根据配置选项的不同,会有两种处理方式:
- 如果配置选项
PreserveCorpus被设置为true,则该程序不会被执行,但是其哈希值会被记录下来,以防止在最小化过程中被删除。 - 如果配置选项
PreserveCorpus没有被设置为true,则会从程序中删除禁用的系统调用,并将剩余部分作为候选程序加入到管理器的候选程序列表中。
最后,无论是否包含禁用的系统调用,程序都会被添加到管理器的候选程序列表(即mgr.candidates)中,并返回true表示加载成功。
- 为给定的Fuzzer对象构建选择表(Choice Table)(即
target.BuildChoiceTable(fuzzer.corpus, calls)函数调用):
该功能是由实现在“/syzkaller/prog/prio.go”的第191行的BuildChoiceTable函数来完成的。
func (target *Target) BuildChoiceTable(corpus []*Prog, enabled map[*Syscall]bool) *ChoiceTable {
if enabled == nil {
enabled = make(map[*Syscall]bool)
for _, c := range target.Syscalls {
enabled[c] = true
}
}
noGenerateCalls := make(map[int]bool)
enabledCalls := make(map[*Syscall]bool)
for call := range enabled {
if call.Attrs.NoGenerate {
noGenerateCalls[call.ID] = true
} else if !call.Attrs.Disabled {
enabledCalls[call] = true
}
}
var generatableCalls []*Syscall
for c := range enabledCalls {
generatableCalls = append(generatableCalls, c)
}
if len(generatableCalls) == 0 {
panic("no syscalls enabled and generatable")
}
sort.Slice(generatableCalls, func(i, j int) bool {
return generatableCalls[i].ID < generatableCalls[j].ID
})
for _, p := range corpus {
for _, call := range p.Calls {
if !enabledCalls[call.Meta] && !noGenerateCalls[call.Meta.ID] {
fmt.Printf("corpus contains disabled syscall %v\n", call.Meta.Name)
for call := range enabled {
fmt.Printf("%s: enabled\n", call.Name)
}
panic("disabled syscall")
}
}
}
prios := target.CalculatePriorities(corpus)
run := make([][]int32, len(target.Syscalls))
// ChoiceTable.runs[][] contains cumulated sum of weighted priority numbers.
// This helps in quick binary search with biases when generating programs.
// This only applies for system calls that are enabled for the target.
for i := range run {
if !enabledCalls[target.Syscalls[i]] {
continue
}
run[i] = make([]int32, len(target.Syscalls))
var sum int32
for j := range run[i] {
if enabledCalls[target.Syscalls[j]] {
sum += prios[i][j]
}
run[i][j] = sum
}
}
return &ChoiceTable{target, run, generatableCalls, noGenerateCalls}
}
该函数用于构建目标系统的选择表(Choice Table),通过分析语料库中的系统调用序列,确定每个系统调用的优先级,并生成一个可用于快速生成测试程序的数据结构。具体步骤如下:
- 如果
enabled映射为空,则初始化为一个将目标系统所有系统调用都设置为已启用的映射。 - 创建两个映射,
noGenerateCalls用于存储不生成的系统调用,enabledCalls用于存储启用的系统调用。 - 遍历
enabled映射中的每个系统调用,将不生成的系统调用添加到noGenerateCalls中,将未禁用的系统调用添加到enabledCalls中。 - 构建一个包含所有启用的系统调用的切片
generatableCalls。 - 如果没有启用的系统调用,则触发panic。
- 根据系统调用的ID对
generatableCalls进行排序,以便后续的选择表构建过程中保持一致性。 - 遍历语料库中的每个程序,检查其中的系统调用是否属于已启用或不生成的系统调用,如果不是,则触发panic。
- 使用目标系统的
CalculatePriorities方法计算每个系统调用之间的优先级。 - 创建一个二维切片
run,其中每个元素代表一个系统调用,并存储了累积加权优先级之和(即sum += prios[i][j])。这有助于在生成测试程序时进行快速的二分查找。 - 返回一个新的选择表对象,其中包含了目标系统的各项信息,如运行时数据、可生成的系统调用列表等。
在这里我们需要关注上面标红的两部分代码,这两部分代码是该函数的核心,下面我们将对其进行分析:
-
使用目标系统的
CalculatePriorities方法计算每个系统调用之间的优先级(即target.CalculatePriorities(corpus)函数调用):
该功能是由实现在“/syzkaller/prog/prio.go”的第27行的CalculatePriorities来完成的。

该函数计算系统调用的优先级,结合静态和动态的优先级信息。静态优先级(即target.calcStaticPriorities()函数调用)是预定义的,而动态优先级(即target.calcDynamicPrio(corpus)函数调用)则是从给定的测试用例集中计算得出的。最终返回一个二维数组,其中每个元素代表对应系统调用的优先级值。下面我们来对计算系统调用的优先级的方法进行详细分析:-
静态优先级(即
target.calcStaticPriorities()函数调用):
该函数实现在“/syzkaller/prog/prio.go”的第41行。

这个函数主要用于计算系统调用之间的静态优先级。它通过分析系统调用之间的资源使用情况来确定优先级。具体步骤如下:- 首先,使用
calcResourceUsage函数计算系统调用之间的资源使用情况,得到一个表示资源使用情况的数据结构。 - 然后,根据资源使用情况,创建一个二维数组
prios用于存储系统调用之间的优先级。数组的大小为系统调用的数量,每个元素表示一个系统调用与其它系统调用之间的优先级。 - 遍历资源使用情况数据结构,对于每对资源使用情况,根据输入输出的关系来确定静态优先级。具体计算方式为将每对调用的输入输出情况相乘,并根据结果调整优先级。如果一个调用产生资源,另一个调用使用该资源,则提高优先级。
- 对计算得到的优先级进行归一化,确保优先级在合适的范围内。
- 最后,将每个系统调用与自身的优先级设置为一个较高的值,以确保自身调用的优先级较高。
函数最终会返回一个二维数组,表示系统调用之间的静态优先级关系。
- 首先,使用
-
动态优先级(即
target.calcDynamicPrio(corpus)函数调用):
该函数实现在“/syzkaller/prog/prio.go”的第146行。

这个函数用于计算系统调用之间的动态优先级,主要基于给定的测试用例集合(corpus)。具体步骤如下:- 创建一个二维数组
prios用于存储系统调用之间的动态优先级。数组的大小为系统调用的数量,每个元素表示一个系统调用与其他系统调用之间的动态优先级。 - 遍历测试用例集合中的每个测试用例。
- 对于每个测试用例,遍历其中的系统调用对
(c0, c1),其中c0是系统调用序列中的第一个调用,c1是后续的系统调用。 - 对于每一对系统调用
(c0, c1),将c0对c1的优先级加一。即如果在某个测试用例中出现了系统调用c0后紧跟着系统调用c1,那么c0对c1的优先级会增加。 - 完成测试用例集合的遍历后,对计算得到的优先级进行归一化,确保优先级在合适的范围内。
- 返回计算得到的动态优先级数组。
这个函数最终会返回一个二维数组,表示系统调用之间的动态优先级关系。
- 创建一个二维数组
-
-
创建一个二维切片
run,其中每个元素代表一个系统调用,并存储了累积加权优先级之和(即sum += prios[i][j])。这有助于在生成测试程序时进行快速的二分查找(该代码片段如下所示):

这段代码的作用是计算系统调用的动态优先级,具体步骤如下:- 对于每个系统调用
target.Syscalls[i],检查是否在enabledCalls中启用。如果未启用,则跳过该系统调用,继续处理下一个系统调用。 - 对于已启用的系统调用,创建一个大小为
len(target.Syscalls)的整数切片run[i],用于存储该系统调用与其他系统调用之间的累积优先级和。 - 遍历
run[i]中的每个元素,表示与该系统调用相关联的其他系统调用。对于每个与当前系统调用相关的系统调用target.Syscalls[j],检查是否启用。如果已启用,则将其静态优先级prios[i][j]累加到sum中,并将sum的值赋给run[i][j],表示当前系统调用到目前为止的累积优先级和。 - 通过以上步骤,完成了系统调用之间的动态优先级计算,得到了一个二维的累积优先级矩阵
run,其中run[i][j]表示从系统调用target.Syscalls[i]到系统调用target.Syscalls[j]的累积优先级和。
这个累积优先级矩阵可以在生成测试用例时使用,帮助选择具有更高优先级的系统调用,以增加测试用例的多样性和代表性。
此外,对于给定的一对系统调用
i和j,用prios[i][j]表示对包含在系统调用i的程序中添加系统调用j是否可能得到新的覆盖的猜测。 - 对于每个系统调用
-
在需要时启动并发测试进程,根据并行测试进程数量创建相应数量的测试进程(即
proc.loop()函数调用):
该功能是由实现在“/syzkaller/syz-fuzzer/proc.go”的第62行的loop()函数来完成的。

这段代码负责控制Fuzz测试的整个流程,不断地生成测试程序并执行Fuzz测试。具体分析如下:- 生成周期(Generate Period):根据是否有真实覆盖信号(real coverage signal),决定了生成程序的频率。如果没有真实的覆盖信号,则生成程序的频率较高,因为回退信号较弱。
- 循环执行:在无限循环中,不断地进行以下操作:
- 从工作队列中取出任务(
item):
工作队列即在下面的对fuzzer.pollLoop()中的workQueue,此工作队列中就保存了由pollLoop()函数加载的测试程序(即语料库/种子文件) - 根据任务的类型执行相应的操作:
- 如果是三种不同的任务类型之一(
WorkTriage、WorkCandidate、WorkSmash),则分别执行对应的处理函数(triageInput、execute、smashInput)。 - 如果是其他未知的任务类型,则记录日志并终止程序。
- 如果是三种不同的任务类型之一(
- 如果没有任务需要处理,则根据当前的Fuzzer快照(fuzzerSnapshot)进行以下操作:
- 如果语料库为空或者达到了生成周期,就生成一个新的程序。
- 否则,从当前的快照中选择一个程序进行变异(
Mutate)操作,生成新的测试程序。
- 对生成的程序执行Fuzz测试(executeAndCollide)。
- 从工作队列中取出任务(
- 日志记录:在关键操作处记录日志,包括生成的程序编号和操作类型(生成还是变异)。
以上代码就是Syzkaller进行Fuzz的核心逻辑,其中上面标黄的部分更是核心。这些核心可以分为执行(对生成的程序执行Fuzz测试就是调用了
execute函数)、生成(生成语料库/种子调用了Generate函数)和变异(对语料库/种子进行变异调用了Mutate函数,同时smashInput也调用了Mutate函数)三个过程(或者可以认为是三个核心函数)。而这些核心代码我们要放到后面的章节进行分析,故关于Syzkaller的Fuzz的过程就到此为止,因为Syzkaller后续执行需要其它组件进行相应的配合。 -
进行Fuzzer的轮询循环,定期检查和处理一些事务,包括生成新的候选输入、记录统计信息以及向管理器报告状态(即
fuzzer.pollLoop()函数调用):
该函数实现在“/syzkaller/syz-fuzzer/fuzzer.go”的第404行。其目的是定期检查和处理一些事务,包括生成新的候选输入、记录统计信息以及向管理器报告状态。

对于此函数我们要关注fuzzer.poll函数调用,因为此函数用于向管理器发起轮询请求,以获取新的输入、候选输入和相关统计信息,并将其添加到Fuzzer中。此函数实现在“/syzkaller/syz-fuzzer/fuzzer.go”的第443行。

对于此函数我们主要关注fuzzer.manager.Call("Manager.Poll", a, r);,其目的是通过RPC调用向管理器发出轮询请求,请求管理器返回新的输入、候选输入和相关统计信息。而此处调用了在“/syzkaller/syz-manager/rpc.go”的第328行实现的Poll函数,该函数用于处理来自Fuzzer实例的轮询请求,主要功能包括合并统计信息、处理最大覆盖信号、准备并发送候选输入和新输入,并记录处理过的请求信息。该函数看起来虽然很长,不过我们只需要关注该函数的serv.mgr.candidateBatch(serv.batchSize)部分代码,因为正是该函数调用完成了对初始语料/种子的加载(或者说初始测试用例的加载)。

我们关注的candidateBatch函数实现在“/syzkaller/syz-manager/manager.go”的第1453行。

这个函数用于从Manager的候选输入队列中提取一批候选输入,并在提取后更新队列状态。具体步骤如下:- 首先获取
Manager的互斥锁,以确保在操作候选输入队列时不会发生竞争条件。 - 初始化一个空的结果数组
res []rpctype.Candidate,用于存储提取的候选输入。 - 使用
for循环,从候选输入队列中提取指定数量(size)的候选输入。- 循环终止条件为提取数量达到指定大小或候选输入队列为空。
- 在每次迭代中,从队列末尾提取一个候选输入,并将其添加到结果数组中。
- 如果候选输入队列已经为空,则将其置为
nil,并根据Manager的当前阶段更新状态:- 如果
Manager当前处于加载完毕的语料库阶段(phaseLoadedCorpus),并且配置中指定了HubClient,则将阶段切换为已分类的语料库阶段(phaseTriagedCorpus),并启动一个异步循环来同步Hub的数据。 - 如果
Manager当前处于从Hub查询语料库的阶段(phaseQueriedHub),则将阶段切换为已分类的Hub阶段(phaseTriagedHub)。
- 如果
- 最后,释放
Manager的互斥锁,并返回提取的候选输入数组。
可以发现,这才是
fuzzer.pollLoop()函数调用最终核心的目的,即将之前加载到虚拟机中的测试程序(即语料库/种子文件)再次加载到workQueue(即工作队列中),等待后续Fuzz使用。故这部分代码可以说是为了上面我们分析过的proc.loop()函数调用中“循环执行”部分的代码服务的。 - 首先获取
1.4、syz-executor进程
syz-executor进程负责执行Syzkaller生成的测试程序。具体来说,它接收来自Syzkaller Manager的请求,执行这些请求中指定的系统调用序列,并监视程序的执行情况。当程序发生崩溃或超时时,syz-executor会收集程序执行的输出、错误信息以及相关的调试信息,并将这些信息发送回Syzkaller Manager进行进一步分析和处理。总的来说,syz-executor进程的主要职责包括执行测试程序、收集执行结果以及与Syzkaller Manager进行通信,以协助进行系统调用Fuzz测试。
经过之前章节的分析,我们清楚syz-executor进程由proc.execute(proc.execOpts, item.p, item.flags, StatCandidate, false)函数调用启动。而execute函数实现在“/syzkaller/syz-fuzzer/proc.go”的第256行。

该函数的主要作用是执行给定的程序(prog.Prog),并根据执行结果进行处理。不过我们要关注proc.executeRaw(execOpts, p, stat)这个函数调用,因为该函数最终真正的执行了给定的程序。该函数实现在“/syzkaller/syz-fuzzer/proc.go”的第324行。

该函数的作用是执行给定的程序(prog.Prog),并返回执行结果信息。让我们逐步解释这段代码的功能:
- 首先,通过
proc.fuzzer.checkDisabledCalls(p)函数检查程序p中是否包含已禁用的系统调用,以确保只执行已启用的系统调用。 - 接下来是一个无限循环,通过
for try := 0; ; try++开始。这个循环的目的是在执行失败时进行重试。 - 在每次循环中,首先尝试重启执行器(executor),以确保它处于可用状态。如果执行器无法重启,则会导致错误,并在下一次循环中进行重试。
- 如果执行器成功启动,就会记录程序的执行日志(通过
proc.logProgram(opts, p)函数),并增加与此次执行相关的统计信息(通过atomic.AddUint64(&proc.fuzzer.stats[stat], 1))。 - 然后,通过
proc.env.Exec(opts, p)方法执行程序,该方法返回执行结果的输出、信息以及是否出现挂起(hang)的情况。 - 如果执行失败,会根据不同的错误类型采取不同的处理方式。例如,如果出现了
prog.ErrExecBufferTooSmall错误,说明序列化程序时出现了问题,会计数并返回nil。如果出现其他类型的错误,则会记录错误信息并在一定重试次数后进行重试。 - 最后,如果执行成功,则会记录执行结果的日志,并返回执行信息。
总的来说,这个方法负责执行给定程序,并在执行失败时进行重试,直到执行成功或达到重试次数上限为止。不过在这段代码中,我们只关注上面标红的部分。下面对其进行详细分析:
-
在每次循环中,首先尝试重启执行器(executor),以确保它处于可用状态。如果执行器无法重启,则会导致错误,并在下一次循环中进行重试(即
proc.env.RestartIfNeeded(p.Target)函数调用):
该功能是由实现在“/syzkaller/pkg/ipc/ipc.go”的第304行的RestartIfNeeded函数实现的。

这个方法用于确保执行器进程处于可用状态,如果需要重新启动,则重新启动它。不过我们关注makeCommand(env.pid, env.bin, env.config, env.inFile, env.outFile, env.out, tmpDirPath)这个函数调用,因为该函数创建执行器进程的命令对象。该函数实现在“/syzkaller/pkg/ipc/ipc.go”的第571行。这个函数看起来很长,不过我们只需要关注下图中红框和红箭头部分的代码。

因为在这里首先创建syz-executor进程的命令对象cmd(即第一个红框处的代码),然后通过创建好的命令对象cmd来启动syz-executor进程(即第二个红框处的代码)故通过以上代码就完成了syz-executor进程的初始化(即启动了之前传入虚拟机中的名为“syz-executor”二进制文件),这些环节都是一环套一环的,此时我们就可以进行后面的操作了。
-
然后,通过
proc.env.Exec(opts, p)方法执行程序,该方法返回执行结果的输出、信息以及是否出现挂起(hang)的情况(即proc.env.Exec(opts, p)函数调用):
该功能是由实现在“/syzkaller/pkg/ipc/ipc.go”的第255行的Exec函数实现的。

该方法主要用于执行给定的程序。不过我们只需要关心env.cmd.exec(opts, progData)这个函数调用,因为该函数最最终执行了给定的程序。该函数实现在“/syzkaller/pkg/ipc/ipc.go”的第761行。

该函数的目的是将待执行/测试的程序(语料库/种子文件)传输给syz-executor执行,其核心功能由c.outwp.Write(progData);完成,故此时syz-executor已经接收到了待执行/测试的程序(语料库/种子文件),下面就要开始对syz-executor中的核心代码进行分析了。
根据以上分析我们知道,最终Syzkaller将待执行/测试的程序(语料库/种子文件)传输给syz-executor去执行,所以我们就要来到“/syzkaller/executor/executor.cc”的第422行的main函数(注:syz-executor由C++语言编写)中来看syz-executor究竟进行了什么操作。
int main(int argc, char** argv)
{
if (argc == 2 && strcmp(argv[1], "version") == 0) {
puts(GOOS " " GOARCH " " SYZ_REVISION " " GIT_REVISION);
return 0;
}
if (argc >= 2 && strcmp(argv[1], "setup") == 0) {
setup_features(argv + 2, argc - 2);
return 0;
}
if (argc >= 2 && strcmp(argv[1], "leak") == 0) {
#if SYZ_HAVE_LEAK_CHECK
check_leaks(argv + 2, argc - 2);
#else
fail("leak checking is not implemented");
#endif
return 0;
}
if (argc >= 2 && strcmp(argv[1], "setup_kcsan_filterlist") == 0) {
#if SYZ_HAVE_KCSAN
setup_kcsan_filterlist(argv + 2, argc - 2, true);
#else
fail("KCSAN is not implemented");
#endif
return 0;
}
if (argc == 2 && strcmp(argv[1], "test") == 0)
return run_tests();
if (argc < 2 || strcmp(argv[1], "exec") != 0) {
fprintf(stderr, "unknown command");
return 1;
}
start_time_ms = current_time_ms();
os_init(argc, argv, (char*)SYZ_DATA_OFFSET, SYZ_NUM_PAGES * SYZ_PAGE_SIZE);
current_thread = &threads[0];
#if SYZ_EXECUTOR_USES_SHMEM
void* mmap_out = mmap(NULL, kMaxInput, PROT_READ, MAP_PRIVATE, kInFd, 0);
#else
void* mmap_out = mmap(NULL, kMaxInput, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANON, -1, 0);
#endif
if (mmap_out == MAP_FAILED)
fail("mmap of input file failed");
input_data = static_cast<char*>(mmap_out);
#if SYZ_EXECUTOR_USES_SHMEM
mmap_output(kInitialOutput);
// Prevent test programs to mess with these fds.
// Due to races in collider mode, a program can e.g. ftruncate one of these fds,
// which will cause fuzzer to crash.
close(kInFd);
#if !SYZ_EXECUTOR_USES_FORK_SERVER
close(kOutFd);
#endif
// For SYZ_EXECUTOR_USES_FORK_SERVER, close(kOutFd) is invoked in the forked child,
// after the program has been received.
#endif // if SYZ_EXECUTOR_USES_SHMEM
use_temporary_dir();
install_segv_handler();
setup_control_pipes();
#if SYZ_EXECUTOR_USES_FORK_SERVER
receive_handshake();
#else
receive_execute();
#endif
if (flag_coverage) {
int create_count = kCoverDefaultCount, mmap_count = create_count;
if (flag_delay_kcov_mmap) {
create_count = kCoverOptimizedCount;
mmap_count = kCoverOptimizedPreMmap;
}
if (create_count > kMaxThreads)
create_count = kMaxThreads;
for (int i = 0; i < create_count; i++) {
threads[i].cov.fd = kCoverFd + i;
cover_open(&threads[i].cov, false);
if (i < mmap_count) {
// Pre-mmap coverage collection for some threads. This should be enough for almost
// all programs, for the remaning few ones coverage will be set up when it's needed.
thread_mmap_cover(&threads[i]);
}
}
extra_cov.fd = kExtraCoverFd;
cover_open(&extra_cov, true);
cover_mmap(&extra_cov);
cover_protect(&extra_cov);
if (flag_extra_coverage) {
// Don't enable comps because we don't use them in the fuzzer yet.
cover_enable(&extra_cov, false, true);
}
char sep = '/';
#if GOOS_windows
sep = '\\';
#endif
char filename[1024] = {0};
char* end = strrchr(argv[0], sep);
size_t len = end - argv[0];
strncpy(filename, argv[0], len + 1);
strncat(filename, "syz-cover-bitmap", 17);
filename[sizeof(filename) - 1] = '\0';
init_coverage_filter(filename);
}
int status = 0;
if (flag_sandbox_none)
status = do_sandbox_none();
#if SYZ_HAVE_SANDBOX_SETUID
else if (flag_sandbox_setuid)
status = do_sandbox_setuid();
#endif
#if SYZ_HAVE_SANDBOX_NAMESPACE
else if (flag_sandbox_namespace)
status = do_sandbox_namespace();
#endif
#if SYZ_HAVE_SANDBOX_ANDROID
else if (flag_sandbox_android)
status = do_sandbox_android(sandbox_arg);
#endif
else
fail("unknown sandbox type");
#if SYZ_EXECUTOR_USES_FORK_SERVER
fprintf(stderr, "loop exited with status %d\n", status);
// Other statuses happen when fuzzer processes manages to kill loop, e.g. with:
// ptrace(PTRACE_SEIZE, 1, 0, 0x100040)
if (status != kFailStatus)
status = 0;
// If an external sandbox process wraps executor, the out pipe will be closed
// before the sandbox process exits this will make ipc package kill the sandbox.
// As the result sandbox process will exit with exit status 9 instead of the executor
// exit status (notably kFailStatus). So we duplicate the exit status on the pipe.
reply_execute(status);
doexit(status);
// Unreachable.
return 1;
#else
reply_execute(status);
return status;
#endif
}
该函数作为syz-executor的主函数,做了很多操作,不过我们只关心我们分析的主线,其主要逻辑为:
- 首先,通过命令行参数
argc和argv来判断用户输入的命令是什么,然后执行相应的操作。 - 如果用户输入的命令是
version,则输出当前操作系统、体系结构、SYZ_REVISION和GIT_REVISION,并返回0。 - 如果用户输入的命令是
setup,则调用setup_features函数来设置特定的功能,并返回0。 - 如果用户输入的命令是
leak,且宏SYZ_HAVE_LEAK_CHECK定义了,就调用check_leaks函数进行内存泄漏检查,否则输出错误信息leak checking is not implemented并返回 0。 - 如果用户输入的命令是
setup_kcsan_filterlist",且宏SYZ_HAVE_KCSAN定义了,就调用setup_kcsan_filterlist函数设置KCSAN的过滤列表,否则输出错误信息KCSAN is not implemented并返回0。 - 如果用户输入的命令是
test,则调用run_tests函数执行测试,并返回其返回值。 - 如果用户输入的命令是
exec,则继续执行后续操作。 - 执行到这里说明用户输入的命令不是上述任何一个,输出错误信息
unknown command并返回1。
在这部分代码中,很明显其核心逻辑为上面标红的部分,因为调用syz-executor时传入的参数就是exec,用来执行给定的语料/种子。所以接下来解析exec命令的处理逻辑:
- 获取当前时间的毫秒表示,并初始化系统。
- 根据宏
SYZ_EXECUTOR_USES_SHMEM的定义,使用不同的方式进行内存映射。 - 进行临时目录的设置、SEGV信号处理器的安装以及控制管道的设置。
- 如果使用Fork Server模式,则接收握手消息;否则接收执行消息。
- 如果开启了覆盖率检测 (flag_coverage),则设置覆盖率收集器,并根据情况进行额外的覆盖率设置。
- 根据不同的沙盒类型,执行相应的沙盒操作。
- 如果使用Fork Server模式,输出循环的结束状态,并根据状态来决定执行相应的操作,然后退出程序。
- 如果不使用Fork Server模式,输出执行状态,并根据状态来决定执行相应的操作。
整体来说,这段代码主要实现了命令行解析、命令处理以及相应操作的执行,其中涉及了内存映射、SEGV信号处理、控制管道的设置、覆盖率检测、沙盒操作等功能。其中最重要的功能就是上面标红的部分,具体来说是下面的代码:

这部分代码会根据不同的沙盒类型,来选择对应的操作。因为我们使用Linux系统作为虚拟机进行Fuzz,所以最终执行的就是对Linux系统沙盒的具体操作,即调用了do_sandbox_none()函数,而该函数实现在“/syzkaller/executor/common_linux.h”的第4054行。
static int do_sandbox_none(void)
{
// CLONE_NEWPID takes effect for the first child of the current process,
// so we do it before fork to make the loop "init" process of the namespace.
// We ought to do fail here, but sandbox=none is used in pkg/ipc tests
// and they are usually run under non-root.
// Also since debug is stripped by pkg/csource, we need to do {}
// even though we generally don't do {} around single statements.
if (unshare(CLONE_NEWPID)) {
debug("unshare(CLONE_NEWPID): %d\n", errno);
}
int pid = fork();
if (pid != 0)
return wait_for_loop(pid);
setup_common();
#if SYZ_EXECUTOR || SYZ_VHCI_INJECTION
initialize_vhci();
#endif
sandbox_common();
drop_caps();
#if SYZ_EXECUTOR || SYZ_NET_DEVICES
initialize_netdevices_init();
#endif
if (unshare(CLONE_NEWNET)) {
debug("unshare(CLONE_NEWNET): %d\n", errno);
}
// Enable access to IPPROTO_ICMP sockets, must be done after CLONE_NEWNET.
write_file("/proc/sys/net/ipv4/ping_group_range", "0 65535");
#if SYZ_EXECUTOR || SYZ_DEVLINK_PCI
initialize_devlink_pci();
#endif
#if SYZ_EXECUTOR || SYZ_NET_INJECTION
initialize_tun();
#endif
#if SYZ_EXECUTOR || SYZ_NET_DEVICES
initialize_netdevices();
#endif
#if SYZ_EXECUTOR || SYZ_WIFI
initialize_wifi_devices();
#endif
setup_binderfs();
loop();
doexit(1);
}
该函数的目的是在不进行任何沙箱化的情况下执行主程序逻辑,包括初始化进程环境、设备初始化、权限管理以及执行主循环,以实现程序的正常运行。其主要逻辑如下:
- 使用
unshare(CLONE_NEWPID)创建新的PID命名空间。这会使得当前进程的第一个子进程成为新命名空间中的init进程。如果unshare失败,会输出错误信息。 - 调用
fork创建子进程,并检查返回值。如果不是子进程,则调用wait_for_loop函数等待子进程的结束,并返回其状态。 - 调用
setup_common函数进行一些初始化操作,然后根据宏定义SYZ_EXECUTOR或SYZ_VHCI_INJECTION是否定义,来决定是否进行虚拟HCI初始化。 - 调用
sandbox_common函数进行沙箱化操作。 - 调用
drop_caps函数放弃进程的权限。 - 使用
unshare(CLONE_NEWNET)创建新的网络命名空间,并在其中使能对IPPROTO_ICMP套接字的访问。如果unshare失败,会输出错误信息。 - 使用
write_file函数将“/proc/sys/net/ipv4/ping_group_range”文件中的内容设置为0 65535,以便允许对IPPROTO_ICMP套接字的访问。 - 根据宏定义
SYZ_EXECUTOR或SYZ_DEVLINK_PCI是否定义,来决定是否进行设备链接PCI初始化。 - 根据宏定义
SYZ_EXECUTOR或`SYZ_NET_INJECTION是否定义,来决定是否初始化TUN设备。 - 根据宏定义
SYZ_EXECUTOR或SYZ_NET_DEVICES是否定义,来决定是否初始化网络设备。 - 根据宏定义
SYZ_EXECUTOR或SYZ_WIFI是否定义,来决定是否初始化Wi-Fi设备。 - 调用
setup_binderfs函数设置Binder文件系统。 - 调用
loop函数执行主循环。 - 调用
doexit函数退出进程。
这部分代码很多,不过我们只需要关心上面标红的部分(即“调用loop函数执行主循环”,这才是syz-executor执行的核心函数),这部分功能通过调用loop()函数来完成,而loop()函数又实现在“/syzkaller/executor/common.h”的第629行和第774行。这里虽然有两处loop()函数的具体实现,不过我们并不关心其函数内部究竟做了什么事情,而是关心这两个loop()函数都调用了execute_one()函数。而execute_one()函数实现在“syzkaller/executor/executor.cc”的第753行,这个函数代码很多,不过我们并不关注,我们只需要知道该函数负责执行输入的程序,并确保系统调用能够顺利完成即可。对于此函数值得注意的一点是,其调用了schedule_call()函数。

schedule_call()函数实现在“syzkaller/executor/executor.cc”的第970行,该函数用于安排系统调用的执行,并确保选定的线程可以执行该系统调用。这个函数的核心是调用了thread_create()函数。

thread_create()函数实现在“syzkaller/executor/executor.cc”的第1217行,该函数用于创建线程对象,并根据需要进行相关的初始化工作,包括覆盖率收集和线程的事件初始化。这个函数的核心是调用了thread_start函数。

thread_start函数(实现在“/syzkaller/executor/common.h”的第354行)用于启动线程并执行指定的函数,具有一定的重试机制以应对可能的资源不足情况。我们并不向下继续分析thread_start函数具体都做了什么,而是注意thread_start函数中传入的worker_thread参数,而worker_thread实际是一个函数,该函数实现在“syzkaller/executor/executor.cc”的第1244行。在thread_start函数内部调用了worker_thread()函数。而对于worker_thread()函数,我们也不关心它都做了什么,我们只需要注意到其调用了execute_call()函数。

execute_call()函数实现在“syzkaller/executor/executor.cc”的第1259行,该函数负责执行系统调用,并记录执行结果,以便后续的分析和处理。我们主要关注在该函数中对execute_syscall()函数的调用。

execute_syscall()函数实现在“/syzkaller/executor/executor_linux.h”的第72行。

这段代码定义了execute_syscall()函数,它用于执行系统调用。下面就让我们逐步分析该函数:
- 函数接受两个参数:一个指向
call_t结构体的指针c,以及一个包含系统调用参数的数组a。 - 首先检查
c->call是否为非空指针,如果是,则说明该系统调用有一个自定义的调用函数,直接调用该函数,并将参数传递给它。 - 如果
c->call为空,则使用标准的syscall函数来执行系统调用,将系统调用号和参数传递给它。 - 函数返回系统调用的执行结果,如果系统调用执行失败,则返回相应的错误码。
这个函数负责实际执行系统调用,根据系统调用的类型,可能调用自定义的调用函数,也可能直接调用系统提供的syscall函数来执行系统调用。所以最终syz-executor通过此函数对语料库/种子文件中的系统调用序列进行执行,通过系统调用进入Linux内核继续执行测试语句序列,从而对Linux内核进行Fuzz。故以上就是syz-executor执行的全部流程。
1.5、Generate进程
Generate进程用于自动生成系统调用接口的定义和相关的代码。具体来说,它根据操作系统的特性和给定的配置参数,生成用于Fuzz的测试程序的相关代码和结构定义。该进程会分析操作系统的系统调用接口,包括系统调用的参数、返回值、错误码等信息,并根据这些信息生成对应的数据结构、函数声明以及其他必要的代码。生成的代码能够被Syzkaller工具使用,用于自动生成测试用例并进行Fuzz测试。因此,Generate进程的主要作用是自动化地生成用于Fuzz测试的代码,从而帮助提高测试的覆盖率和效率。
经过之前章节的分析,我们清楚Generate进程由proc.fuzzer.target.Generate(proc.rnd, prog.RecommendedCalls, ct)函数调用启动。而Generate函数实现在“/syzkaller/prog/generation.go”的第12行。

该函数用于生成具有指定数量系统调用的随机程序,并确保这些程序的结构和内容符合预期,其实现的主要步骤如下:
- 创建一个新的
Prog结构体,表示生成的程序。 - 使用给定的随机数源和选择表,创建一个新的随机数生成器和状态。
- 在程序中循环生成系统调用,直到达到指定的系统调用数量。
- 在每次迭代中,通过随机数生成器生成一组系统调用,并将每个系统调用添加到程序中。
- 分析每个生成的系统调用,更新状态信息。
- 在生成的系统调用数量超过指定数量时,删除多余的系统调用。
- 对程序进行清理和修正,确保程序的结构和内容符合要求。
- 最后,对生成的程序进行调试验证,确保其有效性。
其中核心步骤为上面标红的部分,其功能由r.generateCall(s, p, len(p.Calls))函数调用实现,而generateCall()函数实现在“/syzkaller/prog/rand.go”的第578行。

该方法的作用是根据当前的程序状态和一些随机性,以及可能的偏向,选择并生成一个特定的系统调用序列。下面我们将逐步分析该方法的功能:
biasCall的计算:biasCall用于记录基础调用的索引,该索引将影响新调用序列的插入点。- 如果插入点大于0,则将基础调用设置为当前程序调用列表中的一个随机元素。
- 如果选定的基础调用是不可生成的(即具有
NoGenerate标志),则不会偏向此调用。
- 从选择表中选择系统调用:
- 调用
s.ct.choose方法从状态s中的选择表中选择一个系统调用的索引。如果有偏向的调用(即biasCall不为负数),则会考虑此偏向,并在选择时优先考虑基础调用。 - 获取特定索引
idx处的系统调用信息。
- 调用
- 生成特定的系统调用:
- 使用选定的系统调用的元信息,调用
generateParticularCall方法来生成一个特定的系统调用。 - 这个方法返回一个
Call类型的指针数组,代表生成的系统调用序列。
- 使用选定的系统调用的元信息,调用
在这里我们主要关注上面标红的两部分,因为这两部分代码才是该函数的核心代码,下面我们对其进行分析:
-
获取特定索引
idx处的系统调用信息(即meta := r.target.Syscalls[idx]操作):
其实这里并不涉及函数调用,不过有一个很重要的结构,即Syscalls结构体,该结构体定义在“/syzkaller/prog/types.go”的第12行。

该结构体描述了一个系统调用的属性,包括名称、内核系统调用号、参数列表、返回类型以及与之相关的资源描述。可以认为这是一个模板,Generate进程就是根据这个模板生成的对系统调用的描述来生成具体的系统调用及其对应参数。
其实这个模板属于中间层,它将“syzkaller/sys/linux/”目录(这里我们因为测试使用的Linux系统,所以打开Linux目录,如果测试的其它内容,只需要打开对应目录即可)中的文件的内容以Syscalls结构体为模板生成对应系统调用的相关信息。“syzkaller/sys/linux/”目录中的文件如下图所示:

我们可以随便打开一个文件看看,比如打开名为“aio.txt.const”的文件,其中的内容如下所示。

这段代码是由syz-sysgen生成的,用于描述不同架构下的异步IO系统调用和相关常量。以下是代码中的一些关键内容:arches:定义了支持的架构列表,包括386、amd64、arm等。IOCB_CMD_XXXX:定义了不同类型的IO控制命令,如PREAD、PWRITE等。IOCB_FLAG_XXXX:定义了IO控制块的不同标志位,如IOPRIO、RESFD等。__NR_XXXX:定义了不同架构下的异步IO系统调用号,如io_setup、io_submit等。
该文件提供了跨不同架构的异步IO系统调用和相关常量的映射关系,是Syzkaller用于在不同架构下生成系统调用代码的重要参考数据。其它文件也是类似内容,我们不再展开。此外,这些文件及其中内容,都是作者提供的,我们并不需要进行修改。
最终这些文件会通过syz-extract和syz-sysgen的配合,生成以
Syscalls结构体为模板的系统调用信息结构。最终生成的内容保存在“syzkaller/sys/linux/gen/amd64.go”文件(因为我们测试的系统是amd64架构,所以这里打开的是amd64.go,如果是其它架构,只需要打开对应文件即可)中,具体内容如下所示:

其实这里生成了很多很多系统调用的信息,不过由于篇幅原因,肯定不能展开了,不过这些系统调用信息就用到了本章节Generate进程生成系统调用和对应的参数的功能上面了。最终Generate进程就会根据此模板内容,对目标系统调用生成测试用例以及参数。
各位读者应该注意到了,这里涉及到syz-extract和syz-sysgen这两个二进制文件,不过由于这两个二进制文件的执行过程并不是我们分析的主线,所以就不进行过多赘述,我们只需要知道它们是用于将给定的系统调用信息转换为指定的系统调用模板结构,以及Syzkaller在执行的过程中,调用了这两个二进制文件即可。所以这部分内容算是支线分析,只需要简单介绍。
-
使用选定的系统调用的元信息,调用
generateParticularCall方法来生成一个特定的系统调用(即r.generateParticularCall(s, meta)函数调用):
该函数实现在“/syzkaller/prog/rand.go”文件的第593行,其具体代码内容如下图所示。

该函数负责生成特定系统调用的调用序列,并处理条件字段和参数大小分配等细节。它的实现逻辑如下:- 首先,检查该系统调用的属性。如果该系统调用被禁用(Disabled),则会通过
panic函数抛出异常,指示禁用的系统调用无法生成调用序列。同样地,如果系统调用被标记为不生成(NoGenerate),则会抛出异常,指示不生成调用序列的系统调用。 - 如果系统调用没有被禁用或标记为不生成,那么就创建一个新的调用对象(Call)。调用对象的元数据(
meta)来自传入的参数,即待生成系统调用的元数据。 - 接下来,调用
generateArgs方法生成系统调用的参数列表。generateArgs方法的返回值包括参数列表和可能产生的额外调用。这些额外调用可能是由于条件字段的存在而生成的。 - 调用
patchConditionalFields方法对生成的参数列表进行修补,以处理条件字段。这个方法可能会生成额外的调用序列(moreCalls)。 - 最后,调用
assignSizesCall方法为系统调用分配大小,并将生成的调用对象添加到调用序列中。如果有额外的调用序列,则也会将它们添加到结果中。
我们主要关注上面标红部分的具体代码执行逻辑,即
r.generateArgs(s, meta.Args, DirIn)函数调用,此generateArgs()函数实现在“/syzkaller/prog/rand.go”中的第670行。

该函数用于生成调用的参数列表,并收集在生成参数过程中产生的额外调用列表。我们只需要关注该函数中的r.generateArg(s, field.Type, field.Dir(dir))函数调用,该generateArg()函数实现在“/syzkaller/prog/rand.go”中的第687行。

这里只涉及到generateArgImpl()函数,故继续向下分析。generateArgImpl()函数实现在“/syzkaller/prog/rand.go”中的第691行。 - 首先,检查该系统调用的属性。如果该系统调用被禁用(Disabled),则会通过
func (r *randGen) generateArgImpl(s *state, typ Type, dir Dir, ignoreSpecial bool) (arg Arg, calls []*Call) {
if dir == DirOut {
// No need to generate something interesting for output scalar arguments.
// But we still need to generate the argument itself so that it can be referenced
// in subsequent calls. For the same reason we do generate pointer/array/struct
// output arguments (their elements can be referenced in subsequent calls).
switch typ.(type) {
case *IntType, *FlagsType, *ConstType, *ProcType, *VmaType, *ResourceType:
return typ.DefaultArg(dir), nil
}
}
if typ.Optional() && r.oneOf(5) {
if res, ok := typ.(*ResourceType); ok {
v := res.Desc.Values[r.Intn(len(res.Desc.Values))]
return MakeResultArg(typ, dir, nil, v), nil
}
return typ.DefaultArg(dir), nil
}
// Allow infinite recursion for optional pointers.
if pt, ok := typ.(*PtrType); ok && typ.Optional() {
switch pt.Elem.(type) {
case *StructType, *ArrayType, *UnionType:
name := pt.Elem.Name()
r.recDepth[name]++
defer func() {
r.recDepth[name]--
if r.recDepth[name] == 0 {
delete(r.recDepth, name)
}
}()
if r.recDepth[name] >= 3 {
return MakeSpecialPointerArg(typ, dir, 0), nil
}
}
}
if !ignoreSpecial && dir != DirOut {
switch typ.(type) {
case *StructType, *UnionType:
if gen := r.target.SpecialTypes[typ.Name()]; gen != nil {
return gen(&Gen{r, s}, typ, dir, nil)
}
}
}
return typ.generate(r, s, dir)
}
这个函数的主要作用是根据输入的类型、方向和特殊标记,生成对应的参数对象。具体分析如下:
- 函数首先检查参数方向,如果是输出方向(
DirOut),则对于一些简单的类型(如整数、标志、常量等),直接返回其默认参数值,无需生成更复杂的内容。 - 对于可选参数(
Optional),有一定的几率返回默认参数值,或者从资源描述中随机选择一个值作为参数。 - 对于指针类型参数,如果是可选的,函数允许递归生成,但限制了递归深度,以避免无限递归。
- 对于非输出方向的参数,在生成之前会检查是否有特殊类型的生成器,如果有的话会使用特殊的生成方式来生成参数。
- 最后,如果以上情况都不符合,函数将调用类型对象的生成方法来生成参数。
该函数的核心是上面标红的部分,即typ.generate(r, s, dir)函数调用,generate()函数实际是一个接口,定义在/syzkaller/prog/types.go的第178行。

该接口共实现了14种方法,每种方法对应一种类型的参数值的具体生成,如下图所示。

我们可以点击查看ArrayType类型关于generate()函数的具体实现。可以发现ArrayType类型关于generate()函数的具体实现在“/syzkaller/prog/rand.go”的第858行。

该方法负责生成数组类型的参数,并返回生成的参数对象列表以及生成的额外调用列表。该方法的具体逻辑如下:
- 首先,根据数组的长度类型(随机长度或者指定范围的长度),确定数组的长度。如果数组长度是随机的,则调用
r.randArrayLen()生成随机长度;如果数组长度是范围内的,则调用r.randRange()生成范围内的随机长度。 - 如果正在生成资源,并且数组的长度为0,则确保至少创建一个数组元素,以防资源在数组元素中。
- 然后,通过循环生成数组的每个元素。在每次循环中,调用
r.generateArg()生成数组元素,并将生成的参数对象添加到内部的参数列表中。 - 最后,使用
MakeGroupArg创建一个包含数组参数对象的组参数,并将生成的额外调用列表返回。
可以发现,最终数组类型的参数无非就是通过随机生成的,并没有什么特殊的地方,可能就是对于参数的调整以及处理比其它工具更为完善。下面我们再来按照同样的方法查看IntType类型关于generate()函数的具体实现。可以发现IntType类型关于generate()函数的具体实现在“/syzkaller/prog/rand.go”的第844行。

用于生成整数类型参数的函数。它根据整数类型的定义,生成一个具体的整数值,并将其封装为一个参数返回。具体来说:
- 首先,通过调用
a.TypeBitSize()获取整数类型的位数。 - 然后,根据整数类型的定义,决定生成的整数值
v。如果整数类型的范围是固定的(比如指定了一个具体的值或者范围),则调用r.randInt(bits)方法随机生成一个整数值。 - 如果整数类型的范围是一个区间,则调用
r.randRangeInt(a.RangeBegin, a.RangeEnd, bits, a.Align)方法根据该区间的上下界随机生成一个整数值。 - 最后,将生成的整数值
v封装为一个ConstArg参数对象,并将其作为生成的结果返回。同时,返回的调用列表为空,因为生成整数值时不需要进行其它函数调用。
可以发现关于整数类型的参数,也是通过随机生成的。那么对于其它类型的参数关于generate()函数的具体实现我们就不一一讲解了,因为所有类型的参数也都是随机生成的,只是实现的细节有些许区别,故不再赘述。
以上就是Generate进程的全部流程,当我们通过Generate进程生成新的系统调用序列以及参数后,就可以通过Mutate进程对这些新生成的系统调用序列以及参数进行变异,以获取更高的代码覆盖率,不过这是我们要在下一章节需要分析的内容。
1.6、Mutate进程
Mutate进程用于对现有的测试用例进行变异(Mutation)。具体来说,它会对现有的测试程序进行修改,生成新的测试用例,以便对系统进行更全面和深入的测试。变异是一种常用的Fuzz技术,通过对现有的测试用例进行变异,可以生成具有不同特征和行为的新测试用例,从而扩展测试覆盖范围,发现更多的潜在漏洞和问题。Mutate进程会对现有的测试用例进行随机修改,例如改变系统调用的参数、删除或添加系统调用,或者调整系统调用的顺序等,从而生成新的测试用例。这些新生成的测试用例会被用于Fuzz测试,以验证系统的稳定性和安全性。因此,Mutate进程的主要作用是通过对现有测试用例进行变异,生成新的测试用例,以扩展测试覆盖范围,发现系统中的潜在问题和漏洞。
经过之前章节的分析,我们清楚Mutate进程由p.Mutate(proc.rnd, prog.RecommendedCalls, ct, proc.fuzzer.noMutate, fuzzerSnapshot.corpus)函数调用启动。而Mutate函数实现在“/syzkaller/prog/mutation.go”的第27行。

该函数用于对给定的程序进行变异操作,以生成新的程序版本,其中包括压缩、拼接、插入、修改和移除调用等操作。其具体逻辑如下。
- 首先,创建一个新的随机数生成器
r,用于产生随机数。 - 如果指定的调用数量
ncalls小于当前程序的调用数量len(p.Calls),则将ncalls设置为当前程序的调用数量。 - 创建一个名为
ctx的变异器对象,其中包含了当前程序的信息、随机数生成器、调用数量限制等信息。 - 循环进行变异操作,直到满足停止条件:
- 以一定概率进行以下操作:
- 调用
squashAny()方法(20%的概率),尝试将一个调用压缩成一个更简单的形式。 - 调用
splice()方法(1%的概率),尝试将两个调用片段拼接在一起。 - 调用
insertCall()方法(20/31的概率),尝试插入一个新的调用。 - 调用
mutateArg()方法(10/11的概率),尝试对一个调用的参数进行变异。 - 调用
removeCall()方法(除以上情况的默认情况),尝试移除一个调用。
- 调用
- 如果某次变异操作成功(
ok为true),则将stop设置为true,否则继续进行下一次变异操作。
- 以一定概率进行以下操作:
- 完成变异操作后,对程序进行修正,确保程序的结构符合预期。
- 最后,检查程序的调用数量是否在指定范围内,如果不在范围内则引发异常。
在上面的代码执行流程中,标红的部分是核心,也就是Syzkaller对生成的预料/种子进行Mutate的核心逻辑,下面我们将对其进行详细分析。
-
squashAny()
该函数实现在“/syzkaller/prog/mutation.go”的第94行。该函数的作用是从程序中随机选取一个复杂指针,将其指向的参数压缩为ANY类型。如果压缩后的ANY类型包含数据块(blobs),则对其中的一个数据块进行变异。

该段代码的核心部分是mutateData(r, arg.Data(), 0, maxBlobLen)函数调用,mutateData()函数实现在“/syzkaller/prog/mutation.go”的第710行。

这个函数用于对数据进行突变,即在一定范围内修改数据内容以模拟程序中的数据变化。主要逻辑如下:- 通过
mutateDataFuncs切片随机选择一个数据变异函数f。 - 使用选定的函数
f对数据进行变异,并返回变异后的数据和一个布尔值stop。 - 如果
stop为true,则停止变异过程,否则继续进行下一轮变异。 - 最终返回变异后的数据。
该函数的核心逻辑为上面标红的部分,这里主要涉及到
mutateDataFuncs这个函数列表,通过从mutateDataFuncs函数列表中随机选取一个变异函数来对函数参数进行变异。故我们应该主要分析mutateDataFuncs这个函数列表,看看不同的变异函数究竟都是如何对函数参数进行变异操作的。mutateDataFuncs函数列表实现在“/syzkaller/prog/mutation.go”的第721行。 - 通过
var mutateDataFuncs = [...]func(r *randGen, data []byte, minLen, maxLen uint64) ([]byte, bool){
// TODO(dvyukov): duplicate part of data.
// Flip bit in byte.
func(r *randGen, data []byte, minLen, maxLen uint64) ([]byte, bool) {
if len(data) == 0 {
return data, false
}
byt := r.Intn(len(data))
bit := r.Intn(8)
data[byt] ^= 1 << uint(bit)
return data, true
},
// Insert random bytes.
func(r *randGen, data []byte, minLen, maxLen uint64) ([]byte, bool) {
if len(data) == 0 || uint64(len(data)) >= maxLen {
return data, false
}
n := r.Intn(16) + 1
if r := int(maxLen) - len(data); n > r {
n = r
}
pos := r.Intn(len(data))
for i := 0; i < n; i++ {
data = append(data, 0)
}
copy(data[pos+n:], data[pos:])
for i := 0; i < n; i++ {
data[pos+i] = byte(r.Int31())
}
if uint64(len(data)) > maxLen || r.bin() {
data = data[:len(data)-n] // preserve original length
}
return data, true
},
// Remove bytes.
func(r *randGen, data []byte, minLen, maxLen uint64) ([]byte, bool) {
if len(data) == 0 {
return data, false
}
n := r.Intn(16) + 1
if n > len(data) {
n = len(data)
}
pos := 0
if n < len(data) {
pos = r.Intn(len(data) - n)
}
copy(data[pos:], data[pos+n:])
data = data[:len(data)-n]
if uint64(len(data)) < minLen || r.bin() {
for i := 0; i < n; i++ {
data = append(data, 0) // preserve original length
}
}
return data, true
},
// Append a bunch of bytes.
func(r *randGen, data []byte, minLen, maxLen uint64) ([]byte, bool) {
if uint64(len(data)) >= maxLen {
return data, false
}
const max = 256
n := max - r.biasedRand(max, 10)
if r := int(maxLen) - len(data); n > r {
n = r
}
for i := 0; i < n; i++ {
data = append(data, byte(r.rand(256)))
}
return data, true
},
// Replace int8/int16/int32/int64 with a random value.
func(r *randGen, data []byte, minLen, maxLen uint64) ([]byte, bool) {
width := 1 << uint(r.Intn(4))
if len(data) < width {
return data, false
}
i := r.Intn(len(data) - width + 1)
storeInt(data[i:], r.Uint64(), width)
return data, true
},
// Add/subtract from an int8/int16/int32/int64.
func(r *randGen, data []byte, minLen, maxLen uint64) ([]byte, bool) {
width := 1 << uint(r.Intn(4))
if len(data) < width {
return data, false
}
i := r.Intn(len(data) - width + 1)
v := loadInt(data[i:], width)
delta := r.rand(2*maxDelta+1) - maxDelta
if delta == 0 {
delta = 1
}
if r.oneOf(10) {
v = swapInt(v, width)
v += delta
v = swapInt(v, width)
} else {
v += delta
}
storeInt(data[i:], v, width)
return data, true
},
// Set int8/int16/int32/int64 to an interesting value.
func(r *randGen, data []byte, minLen, maxLen uint64) ([]byte, bool) {
width := 1 << uint(r.Intn(4))
if len(data) < width {
return data, false
}
i := r.Intn(len(data) - width + 1)
value := r.randInt64()
if r.oneOf(10) {
value = swap64(value)
}
storeInt(data[i:], value, width)
return data, true
},
}
这是一组用于对数据进行变异的函数列表。每个函数接受一个随机数生成器r、一个字节切片data、最小长度minLen和最大长度maxLen作为输入,并返回一个修改后的字节切片以及一个布尔值,表示是否应该停止变异。具体来说,这些变异函数包括:
- 翻转字节中的一个比特。
- 插入随机字节。
- 移除字节。
- 添加一些字节。
- 用随机值替换int8类型、int16类型、int32类型或int64类型的值。
- 对int8类型、int16类型、int32类型或int64类型的值进行增减操作。
- 将int8类型、int16类型、int32类型或int64类型的值设置为一个有趣的值。
每次调用mutateData函数时,都会从这些变异函数中随机选择一个,并将其应用于数据。然后根据返回的布尔值决定是否继续进行下一轮变异。
-
splice()
该函数实现在“/syzkaller/prog/mutation.go”的第77行。

该函数用于生成新的测试用例(系统调用),通过将两个现有的程序片段进行组合,以创建一个新的测试用例(系统调用)。具体来说:- 从语料库中随机选择一个程序
p0。 - 随机选择一个索引
i,将目标程序ctx.p的调用保留到索引i(不包括索引i),然后将程序p0从索引i(包括索引i)开始的调用连接到ctx.p的调用列表中。 - 如果连接后的调用数量超过了规定的最大调用数量
ctx.ncalls,则删除超出部分的调用。
- 从语料库中随机选择一个程序
-
insertCall()
该函数实现在“/syzkaller/prog/mutation.go”的第141行。

该函数的作用是在现有系统调用序列的随机位置插入一个新的调用,有一定的偏向性,更倾向于在系统调用序列的末尾进行插入。如果系统调用序列已经包含了指定数量的系统调用,则不会插入新的调用。具体步骤如下:- 检查系统调用序列的系统调用数量是否已经达到指定的
ncalls。 - 如果系统调用序列的系统调用数量已经达到了指定的上限,则函数返回
false,表示无法插入新的系统调用。 - 否则,随机选择一个位置进行插入,有一定的偏向性,更倾向于选择现有系统调用序列的末尾。
- 对于选择的插入点,生成新的系统调用序列。
- 将生成的系统调用序列插入到程序中选定的位置。
- 如果插入新的系统调用后程序的系统调用数量超过了指定的上限,则删除多余的系统调用,确保系统调用序列的系统调用数量不超过
ncalls。 - 函数返回
true,表示成功插入新的系统调用。
- 检查系统调用序列的系统调用数量是否已经达到指定的
-
mutateArg()
该函数实现在“/syzkaller/prog/mutation.go”的第172行。

这个函数的目的是通过变异参数来增加测试用例的多样性和复杂性,以便更好地进行Fuzz测试。它的操作步骤如下:- 如果系统调用序列中没有系统调用,则返回
false,表示没有进行变异。 - 选择一个随机的系统调用,通过调用
chooseCall函数来完成。 - 如果选择的系统调用被标记为不可变异(noMutate),则返回
false,表示不进行变异。 - 遍历选定系统调用的所有参数,并收集它们。
- 如果没有找到参数,则返回
false,表示不进行变异。 - 分析系统调用以确定参数的大小和其他信息。
- 选择要变异的参数,调用
mutateArg函数进行变异。变异可能会生成一系列新的调用序列。 - 如果成功生成了新的系统调用序列,则将它们插入到原始系统调用的位置之前。
- 如果需要,更新系统调用的大小信息。
- 如果变异成功,则返回
true,表示已经进行了变异。
该函数的核心为上面标红的部分,即
p.Target.mutateArg(r, s, arg, argCtx, &updateSizes)函数调用,mutateArg函数实现在“/syzkaller/prog/mutation.go”的第240行。

这个函数的目的是对目标系统调用的参数进行变异。其具体逻辑如下:mutateArg函数接收一个随机数生成器r、一个状态s、一个参数arg以及一个参数上下文ctx,还有一个布尔值指针updateSizes,用来表示是否需要更新参数的大小。- 在函数中,首先获取参数的基础大小(如果有的话),这通常是指参数引用的内存块的大小。
- 然后调用参数的类型的
mutate方法,该方法会尝试对参数进行变异。这个方法返回三个值:calls、retry和preserve。calls是一个系统调用列表,表示在变异过程中生成的新系统调用。retry是一个布尔值,表示是否应该重试变异操作。preserve也是一个布尔值,表示是否应该保留参数不变。如果参数不应该变异,则设置*updateSizes为false。
- 如果变异操作需要更新参数的大小且基础指针不为空,且在变异后参数的大小增加了,则更新基础指针的大小为新的大小,并为其分配新的地址。
- 最后,返回生成的系统调用列表和一个布尔值表示是否成功进行了参数变异。
该函数的核心是上面标红的部分,即
arg.Type().mutate(r, s, arg, ctx)函数调用,mutate()其实是一个函数接口,其声明在“/syzkaller/prog/types.go”的第179行。

该函数接口共为14种不同的参数类型,实现了14种对应的参数变异的具体函数。我们可以按照如下图所示的顺序进行查看。

比如我们在这里可以查看IntType类型中关于mutate接口的具体实现,其具体实现在“/syzkaller/prog/mutation.go”的第299行。

这段代码是IntType类型的mutate方法,用于对整数类型的参数进行变异。以下是它的逻辑:- 首先,检查是否应该进行二进制变异。如果是,调用
regenerate函数重新生成参数。 - 如果不是二进制变异,那么参数被认为是ConstArg类型。根据参数的对齐方式,选择不同的变异方法。
- 如果整数类型的对齐值为
0,则调用mutateInt函数对参数进行变异。否则,调用mutateAlignedInt函数。 - 在变异完成后,将参数值截断为类型位数大小,以确保结果值在合适的范围内。
- 最后,返回生成的调用列表、重试标志(retry)和保留标志(preserve)。
该函数其实又对底层的具体参数变异逻辑进行了封装,如果我们想看具体是如何变异的,还需要继续向下分析。不过我们就不一一分析了,我们在这里以
mutateInt()函数为了,来看看其具体是如何进行参数变异的,mutateInt()函数实现在“/syzkaller/prog/mutation.go”的第267行。

这个mutateInt()函数用于对整数类型的参数进行变异。它采用随机策略,根据一定的概率选择以下操作之一:- 以
1/3的概率将参数值增加一个随机的值(范围为1到4)。 - 以
1/2的概率将参数值减少一个随机的值(范围为1到4)。 - 剩余的情况下,对参数值进行按位异或运算,其中异或的位是参数类型的位数范围内的随机位。
这个函数通过
r.nOutOf方法来实现不同概率的选择,其中nOutOf(n, m)的意思是从m个选项中随机选择n个。可以发现,参数变异的底层逻辑无非还是随机,即随机对参数进行变异(比如,增加参数值、减少参数值和对参数值进行按位与或运算)。对于其它变异函数以及其它类型的变异函数也都遵循这个逻辑,即随机的逻辑,只是实现的具体细节上可能有差异。我们就不一一分析了,感兴趣的读者可以自行查看。
- 如果系统调用序列中没有系统调用,则返回
-
removeCall()
该函数实现在“/syzkaller/prog/mutation.go”的第161行。

这个函数的作用是从程序中随机删除一个调用。它的实现逻辑如下:- 首先,检查程序中是否存在调用,如果不存在,则函数返回
false,表示没有进行删除操作。 - 然后,通过生成一个
0到len(p.Calls)-1之间的随机整数来选择要删除的调用的索引。 - 最后,调用程序的
RemoveCall方法来从调用列表中删除选定的调用,并返回true,表示删除成功。
该函数的核心是上面标黄的部分,即
p.RemoveCall(idx)函数调用。其中RemoveCall()函数实现在“/syzkaller/prog/prog.go”的第427行。

这段代码实现了从系统调用的系统调用列表中删除指定索引的系统调用。其步骤如下:- 首先,获取要删除的系统调用
c,它是系统调用列表p.Calls中索引为idx的元素。 - 然后,遍历系统调用
c的所有参数和返回值,并调用removeArg函数来删除它们。 - 接着,将系统调用列表中索引大于
idx的所有系统调用向前移动一个位置,覆盖掉要删除的系统调用。 - 最后,通过将系统调用列表的长度减一来移除最后一个元素,即删除系统调用
c。
- 首先,检查程序中是否存在调用,如果不存在,则函数返回
2、安装与使用
| 软件环境 | 硬件环境 | 约束条件 |
|---|---|---|
| Ubuntu-22.04.2-desktop-amd64(内核版本5.19.0-45-generic) | 使用4个处理器,每个处理器4个内核,共分配16个内核 | VMware Pro 17需对此虚拟机开启Intel VT-x/EPT或AMD-V/RVI(V)选项 |
| 具体的软件环境可见“2.1、源码安装”章节所示的软件环境 | 内存16GB | 本文所讲解的Syzkaller源代码于2024.02.28下载 |
| 硬盘30GB | 本文所安装的Syzkaller源代码于2023.06.26下载 | |
| Syzkaller部署在VMware Pro 17上的Ubuntu22.04.2系统上(主机系统为Windows 11),硬件环境和软件环境也是对应的VMware Pro 17的硬件环境和软件环境 | 具体的约束条件可见“2.1、源码安装”章节所示的软件版本约束 |
2.1、源码安装
2.1.1、部署系统依赖组件
- 首先使用如下命令更新软件源:
$ sudo apt-get update
- Syzkaller的安装部署需要很多软件的支持,除了系统自带的软件环境外,还需要使用如下命令对额外使用的软件进行安装:
$ sudo apt-get install debootstrap
$ sudo apt install qemu-kvm
$ sudo apt-get install subversion
$ sudo apt-get install git
$ sudo apt-get install make
$ sudo apt-get install qemu
$ sudo apt install libssl-dev libelf-dev
$ sudo apt-get install flex bison libc6-dev libc6-dev-i386 linux-libc-dev linux-libc-dev:i386 libgmp3-dev libmpfr-dev libmpc-dev
$ sudo apt-get install g++
$ sudo apt-get install build-essential
$ sudo apt install gcc
$ sudo apt-get install vim
$ sudo apt install tree
- 除了以上可以直接安装的软件外,我们还需要安装go 1.20.1,因为Syzkaller主要就是由go语言编写的,但是go 1.20.1不能直接使用一句命令安装,需要下载源码进行安装。首先执行如下命令进入root用户权限,因为后面需要使用root用户权限,为了避免不必要的麻烦,我们直接使用root用户权限进行安装:
$ su
-
输入密码后即可进入root用户权限:

-
然后进入系统的根目录后使用如下这些命令进行下载并解压,并且添加环境变量:
# cd /
# wget https://dl.google.com/go/go1.20.1.linux-amd64.tar.gz
# tar -xf go1.20.1.linux-amd64.tar.gz
# export GOROOT=`pwd`/go
# export PATH=$GOROOT/bin:$PATH
- 最后就可以输入
go version命令查看go 1.20.1是否安装成功,如果出现如下内容,即代表go 1.20.1安装成功:

2.1.2、使用源码安装系统
- 因为很多操作需要root用户权限,所以首先执行如下命令进入root用户权限:
$ su
-
输入密码后即可进入root用户权限:

-
然后在系统的根目录中下载源码,并进入Syzkaller源代码目录进行编译:
# cd /
# git clone https://github.com/google/syzkaller.git
# cd syzkaller/
# make
- 编译完成后,输入如下命令查看编译后的结果:
# tree ./bin/
- 编译完成后,在Syzkaller目录下会出现一个bin目录,此目录中的内容如下图所示,这些就是我们后面需要用到的二进制文件,此时我们就部署好了Syzkaller:

注:实际执行中遇到的问题及解决方法
A 问题1:
-
在步骤3对Syzkaller进行编译的时候,出现如下问题:

-
这是因为文件夹的所有者和现在的用户不一致,我们只需要执行如下命令即可:
$ git config --global --add safe.directory "*"
2.2、使用方法
2.2.1、下载编译测试内核
- 首先我们需要准备我们待Fuzz的内核。我们首先进入系统的根目录,然后进入root用户权限,并使用如下命令下载Linux 5.14版本的内核(以5.14版本的Linux内核为例介绍Syzkaller的具体使用方法,关于具体测试细节请参考3、测试用例章节),并对其解压,这就是我们准备Fuzz的内核:
$ su
# cd /
# wget https://mirrors.tuna.tsinghua.edu.cn/kernel/v5.x/linux-5.14.tar.gz
# tar -zxvf linux-5.14.tar.gz
- 然后进入解压后的Linux 5.14内核目录,并生成配置文件:
# cd linux-5.14
# make defconfig
# make kvm_guest.config
- 然后使用如下命令打开配置文件:
# vim .config
- 为了提高Fuzz效率,在打开的配置文件中加入如下内容(注意要将原有已经存在对应配置项即对应注释删除,可以使用记事本打开后搜索然后删除,否则后续的操作可能会报错):
CONFIG_KCOV=y
CONFIG_DEBUG_INFO_DWARF4=y
CONFIG_KASAN=y
CONFIG_KASAN_INLINE=y
CONFIG_CONFIGFS_FS=y
CONFIG_SECURITYFS=y
- 修改配置文件后,保存修改并退出,然后重新生成配置文件并编译:
# make olddefconfig
# make -j4
- 编译成功后,使用如下两条命令查看对应目录的内容,会出现如下箭头所指的红框所示的内容:

2.2.2、配置测试虚拟机
- 完成上一小节的操作后,继续向下操作,因为此时我们已经准备好了待Fuzz的内核,所以需要将此内核部署在一个虚拟机中,这样我们才能使用Syzkaller对此内核进行Fuzz。我们首先来到根目录创建一个新目录,进入这个新目录后使用debootstrap构建Linux内核启动镜像:
# cd /
# mkdir image-test
# cd image-test/
# wget https://raw.githubusercontent.com/google/syzkaller/master/tools/create-image.sh -O create-image.sh
# chmod +x create-image.sh
# ./create-image.sh
-
以上命令执行时间较长,等待执行完成后,可以使用
ll命令查看执行结果,如果执行成功,会在此目录生成如下内容:

-
然后切换到系统的根目录,然后使用如下命令启动QEMU虚拟机:
# cd /
# qemu-system-x86_64 -m 2G -smp 2 -kernel /linux-5.14/arch/x86/boot/bzImage -append "console=ttyS0 root=/dev/sda earlyprintk=serial net.ifnames=0" -drive file=/image-test/bullseye.img,format=raw -net user,hostfwd=tcp:127.0.0.1:10021-:22 -net nic,model=e1000 -enable-kvm -nographic -pidfile vm.pid 2>&1 | tee vm.log
-m 2G:分配2G内存给虚拟系统-smp 2:分配2个CPU给虚拟系统-kernel /linux-5.14/arch/x86/boot/bzImage:使用/linux-5.14/arch/x86/boot/bzImage作为内核镜像文件,QEMU可以使用这个功能用来测试不同的内核-append "console=ttyS0 root=/dev/sda earlyprintk=serial net.ifnames=0":添加内核启动参数,包括控制台设置、根文件系统设备、早期打印和网络接口名称(禁用)-drive file=/image-test/bullseye.img,format=raw:指定/image-test/bullseye.img作为磁盘映像文件,并指定其格式为raw-net user,hostfwd=tcp:127.0.0.1:10021-:22 -net nic,model=e1000:添加网络配置,将虚拟机的网卡连接到一个用户网络,可以使宿主机与客户机进行通信,同时使用e1000模型-enable-kvm:开启kVM虚拟化,启用KVM硬件加速-nographic:禁用图形显示,所有输出都将通过控制台输出-pidfile vm.pid 2>&1 | tee vm.log:将QEMU进程pid储存在vm.pid这个文件中,并将执行过程中的标准错误和标准输出同时定向输出到控制台和vm.log文件中
-
出现以下内容,即代表成功,只需要输入
root后按Enter即可,此时就进入QEMU虚拟机中了。另外需要注意的是,一直到Fuzz结束之前,此虚拟机都不要关闭,如果Fuzz结束或者有其它原因需要关闭这个虚拟机,只需要在此虚拟机内执行init 0命令即可:

-
进入虚拟机后我们暂时先不要做其它操作,我们首先在主机新开一个终端,顺序执行如下命令使用ssh来查看主机和这个虚拟机之间是否可以进行通信:
$ cd /
$ sudo ssh -i image-test/bullseye.id_rsa -p 10021 -o "StrictHostKeyChecking no" root@localhost
-
若出现如下内容,即代表主机和刚刚安装的虚拟机之间的通信没有问题:

-
既然主机和客户机之间的通信没有问题,那么我们在这个新打开的终端中执行如下命令,断开ssh连接:
# exit
- 然后我们就可以进行最后的配置,准备Fuzz了。我们只需在刚刚创建的虚拟机中顺序执行如下命令,就可以创建一个新的目录,此目录作为Fuzz过程中的中间文件的存储目录:
# cd /
# mkdir fuzzdir
- 如果成功进行到此步,就说明Syzkaller进行测试之前的准备工作已经完成了,下面就可以进行测试了
注:实际执行中遇到的问题及解决方法
A 问题1:
-
在步骤3第一次启动QEMU虚拟机的时候,出现如下问题:

-
这是因为我们在“2.2.1、下载编译测试内核”章节的步骤4中填入内容后,忘记删除各自对应的注释,导致编译内核时新的配置被重写了。为了解决这个问题,我们首先执行如下命令进入Linux内核源代码目录:
# cd /linux-5.14/
- 然后使用如下命令打开配置文件:
# gedit .config
-
然后按“Ctrl+F”搜索“CONFIG_KCOV”,将搜索到的箭头所指红框一行内容删除:

-
继续按“Ctrl+F”搜索“CONFIG_KASAN”,将搜索到的箭头所指红框一行内容删除:

-
继续按“Ctrl+F”搜索“CONFIG_CONFIGFS_FS”,将搜索到的箭头所指红框一行内容删除:

-
继续按“Ctrl+F”搜索“CONFIG_SECURITYFS”,将搜索到的箭头所指红框一行内容删除:

-
做完以上工作后,保存修改后关闭配置文件,然后重复执行步骤3,并继续向下操作即可
2.2.3、对Linux内核进行Fuzz
- 如果已经成功部署了Syzkaller,那么对其进行测试就比较简单了,首先打开一个新的终端,在其中顺序执行如下命令,目的是进入到Syzkaller源代码目录中,并新建一个工作目录和一个配置文件:
$ cd /syzkaller/
$ sudo mkdir workdir
$ sudo vim setting.cfg
- 然后在新建的配置文件中输入如下内容,然后保存退出:
{
"target": "linux/amd64",
"http": "127.0.0.1:56741",
"rpc": "127.0.0.1:0",
"workdir": "/syzkaller/workdir",
"kernel_obj": "/linux-5.14",
"sshkey": "/image-test/bullseye.id_rsa",
"syzkaller": "/syzkaller",
"sandbox": "setuid",
"type": "isolated",
"vm": {
"targets" : [ "127.0.0.1:10021" ],
"pstore": false,
"target_dir" : "/fuzzdir",
"target_reboot" : false
}
}
以上参数也可以进行自定义,为了方便后续的测试与使用,现将上面配置文件中的各个参数进行详细解释:
target:目标操作系统/架构http:显示有关正在运行的syz-manager进程的信息的urlrpc:为Fuzz进程的RPC提供服务的TCP地址(可选)workdir:syz-manager进程的工作目录的路径kernel_obj:内核构建目录的路径sshkey:用于与虚拟机通信的根SSH标识的位置(在主机上)(对于某些虚拟机类型可能为空)syzkaller:Syzkaller源码的位置sandbox:Fuzz处理期间要使用的沙盒类型none:root下试验namespace:使用CLONE_NEWUSER创建一个新的用户命名空间进行测试(仅在Linux上支持)setuid:模拟成用户nobody(65534)(在Linux、FreeBSD、NetBSD、OpenBSD上受支持)android:模拟不受信任的Android应用程序的权限(仅在Linux上支持)
type:要使用的虚拟机类型,例如“qemu”、“gce”、“android”、“isolated”等。vm.targets:用于Fuzz测试的主机列表vm.pstore:如果被测设备(DUT)支持Pstore,则可以配置Syzkaller从sys/fs/pstore获取崩溃日志vm.target_dir:目标主机上的工作目录vm.target_reboot:如果远程进程挂起,请重新启动机器(对广泛的Fuzz测试很有用,默认为false)
- 然后顺序执行如下命令启动Syzkaller进行Fuzz。此命令中的syz-manager是一个进程,将会启动虚拟机并在其中开始Fuzz测试,并利用-config命令行选项确定的配置文件的位置,根据配置文件中的具体配置内容进行Fuzz:
$ cd /syzkaller/
$ sudo ./bin/syz-manager -config=setting.cfg
-
成功启动后,终端中会出现如下图所示的内容,我们需要保存下图红框处的Http地址,因为发现的崩溃、统计数据和其他信息都会在管理器配置的这个指定的Http地址上公开:

-
将上一步获取到的地址用浏览器打开,会得到如下图所示的内容,这就代表Syzkaller已经成功开始Fuzz了,并且实时的运行结果会输出到“setting.cfg”文件中指定的“fuzzdir”目录(虚拟机中)中:

3、测试用例
3.1、对Linux 5.14内核进行Fuzz测试
3.1.1、下载编译测试内核
- 首先进入系统的根目录,然后进入root用户权限,并使用如下命令下载Linux 5.14版本的内核,并对其解压:
$ su
# cd /
# wget https://mirrors.tuna.tsinghua.edu.cn/kernel/v5.x/linux-5.14.tar.gz
# tar -zxvf linux-5.14.tar.gz
- 然后进入解压后的Linux 5.14内核目录,并生成配置文件:
# cd linux-5.14/
# make defconfig
# make kvm_guest.config
- 然后使用如下打开配置文件:
# vim .config
- 然后在打开的配置文件中加入如下内容(注意要将原有已经存在对应配置项即对应注释删除):
CONFIG_KCOV=y
CONFIG_DEBUG_INFO_DWARF4=y
CONFIG_KASAN=y
CONFIG_KASAN_INLINE=y
CONFIG_CONFIGFS_FS=y
CONFIG_SECURITYFS=y
- 修改配置文件后,保存修改并退出,然后重新生成配置文件并编译:
# make olddefconfig
# make -j4
- 编译成功后,使用如下两条命令查看对应目录的内容,会出现如下箭头所指的红框所示的内容:

3.1.2、配置测试虚拟机
- 首先来到根目录创建一个新目录,进入这个新目录后使用debootstrap构建Linux内核启动镜像:
# cd /
# mkdir images-test-linux5.14
# cd images-test-linux5.14/
# wget https://raw.githubusercontent.com/google/syzkaller/master/tools/create-image.sh -O create-image.sh
# chmod +x create-image.sh
# ./create-image.sh
-
若此目录生成如下内容,则代表执行成功:

-
然后切换到系统的根目录,然后使用如下命令启动QEMU虚拟机:
# cd /
# qemu-system-x86_64 -m 2G -smp 2 -kernel /linux-5.14/arch/x86/boot/bzImage -append "console=ttyS0 root=/dev/sda earlyprintk=serial net.ifnames=0" -drive file=/images-test-linux5.14/bullseye.img,format=raw -net user,hostfwd=tcp:127.0.0.1:10021-:22 -net nic,model=e1000 -enable-kvm -nographic -pidfile vm.pid 2>&1 | tee vm.log
-
出现以下内容,即代表成功,只需要输入
root后按Enter即可,此时就进入QEMU虚拟机中了。另外需要注意的是,一直到Fuzz结束之前,此虚拟机都不要关闭,如果Fuzz结束或者有其它原因需要关闭这个虚拟机,只需要在此虚拟机内执行init 0命令即可:

-
进入虚拟机后我们暂时先不要做其它操作,我们首先在主机新开一个终端,顺序执行如下命令使用ssh来查看主机和这个虚拟机之间是否可以进行通信:
$ cd /
$ sudo ssh -i images-test-linux5.14/bullseye.id_rsa -p 10021 -o "StrictHostKeyChecking no" root@localhost
-
若出现如下内容,即代表主机和刚刚安装的虚拟机之间的通信没有问题:

-
既然主机和客户机之间的通信没有问题,那么我们在这个新打开的终端中执行如下命令,断开ssh连接:
# exit
- 然后我们就可以进行最后的配置,准备Fuzz了。我们只需在刚刚创建的虚拟机中顺序执行如下命令,就可以创建一个新的目录,此目录作为Fuzz过程中的中间文件的存储目录:
# cd /
# mkdir fuzzdir
- 如果成功进行到此步,就说明Syzkaller进行测试之前的准备工作已经完成了
3.1.3、对Linux内核进行Fuzz
- 首先打开一个新的终端,在其中顺序执行如下命令,目的是进入到Syzkaller源代码目录中,并新建一个工作目录和一个配置文件:
$ cd /syzkaller/
$ sudo mkdir workdir
$ sudo vim setting.cfg
- 然后在新建的配置文件中输入如下内容,然后保存退出:
{
"target": "linux/amd64",
"http": "127.0.0.1:56741",
"rpc": "127.0.0.1:0",
"workdir": "/syzkaller/workdir",
"kernel_obj": "/linux-5.14",
"sshkey": "/images-test-linux5.14/bullseye.id_rsa",
"syzkaller": "/syzkaller",
"sandbox": "setuid",
"type": "isolated",
"vm": {
"targets" : [ "127.0.0.1:10021" ],
"pstore": false,
"target_dir" : "/fuzzdir",
"target_reboot" : false
}
}
- 然后顺序执行如下命令启动Syzkaller进行Fuzz:
$ cd /syzkaller/
$ sudo ./bin/syz-manager -config=setting.cfg
-
成功启动后,终端中会出现如下图所示的内容,我们需要保存下图红框处的Http地址,因为发现的崩溃、统计数据和其他信息都会在管理器配置的这个指定的Http地址上公开:

-
将上一步获取到的地址用浏览器打开,会得到如下图所示的内容,这就代表Syzkaller已经成功开始Fuzz了,并且实时的运行结果会输出到“setting.cfg”文件中指定的“fuzzdir”目录(虚拟机中)中:

3.2、对Linux 4.14内核进行Fuzz测试
3.2.1、下载编译测试内核
- 首先进入系统的根目录,然后进入root用户权限,并使用如下命令下载Linux 4.14版本的内核,并对其解压:
$ su
# cd /
# wget https://mirrors.tuna.tsinghua.edu.cn/kernel/v4.x/linux-4.14.tar.gz
# tar -zxvf linux-4.14.tar.gz
- 然后进入解压后的Linux 4.14内核目录,并生成配置文件:
# cd linux-4.14
# make defconfig
# make kvm_guest.config
- 然后使用如下打开配置文件:
# vim .config
- 然后在打开的配置文件中加入如下内容(注意要将原有已经存在对应配置项即对应注释删除):
CONFIG_KCOV=y
CONFIG_DEBUG_INFO_DWARF4=y
CONFIG_KASAN=y
CONFIG_KASAN_INLINE=y
CONFIG_CONFIGFS_FS=y
CONFIG_SECURITYFS=y
- 修改配置文件后,保存修改并退出,然后重新生成配置文件并编译:
# make olddefconfig
# make -j4
- 编译成功后,使用如下两条命令查看对应目录的内容,会出现如下箭头所指的红框所示的内容:

注:实际执行中遇到的问题及解决方法
A 问题1:
-
在步骤5编译Linux 4.14内核时,出现如下问题:

-
首先打开如下文件:
# gedit scripts/selinux/genheaders/genheaders.c
-
在打开的文件中,删除红框和红箭头处所示的内容,保存修改后退出:

-
然后再打开如下文件:
# gedit scripts/selinux/mdp/mdp.c
-
在打开的文件中,删除红框和红箭头处所示的内容,保存修改后退出:

-
然后再打开如下文件:
# gedit security/selinux/include/classmap.h
-
在打开的文件中,添加红框和红箭头处所示的内容,保存修改后退出:

-
然后执行如下命令,清除之前的编译记录:
# make clean
- 此时我们就解决了这个问题,我们只需要回到步骤5重新继续向下操作即可
B 问题2:
-
在步骤5编译Linux 4.14内核时,出现如下问题:

-
为了解决这个问题,我们首先创建并打开如下文件:
# gedit patch-machine_kexec_64.patch
- 在打开的文件中输入如下内容,然后保存修改后退出:
diff --git a/arch/x86/kernel/machine_kexec_64.c b/arch/x86/kernel/machine_kexec_64.c
index 1f790cf9d38fe0..3b7427aa7d8506 100644
--- a/arch/x86/kernel/machine_kexec_64.c
+++ b/arch/x86/kernel/machine_kexec_64.c
@@ -542,6 +542,7 @@ int arch_kexec_apply_relocations_add(const Elf64_Ehdr *ehdr,
goto overflow;
break;
case R_X86_64_PC32:
+ case R_X86_64_PLT32:
value -= (u64)address;
*(u32 *)location = value;
break;
- 然后执行如下命令对当前版本的Linux内核打补丁:
# patch -p1 < patch-machine_kexec_64.patch
- 然后创建并打开如下文件:
# gedit patch-module.patch
- 在打开的文件中输入如下内容,然后保存修改后退出:
diff --git a/arch/x86/kernel/module.c b/arch/x86/kernel/module.c
index da0c160e558905..f58336af095c9d 100644
--- a/arch/x86/kernel/module.c
+++ b/arch/x86/kernel/module.c
@@ -191,6 +191,7 @@ int apply_relocate_add(Elf64_Shdr *sechdrs,
goto overflow;
break;
case R_X86_64_PC32:
+ case R_X86_64_PLT32:
if (*(u32 *)loc != 0)
goto invalid_relocation;
val -= (u64)loc;
- 然后执行如下命令对当前版本的Linux内核打补丁:
# patch -p1 < patch-module.patch
- 然后创建并打开如下文件:
# gedit patch-relocs.patch
- 在打开的文件中输入如下内容,然后保存修改后退出:
diff --git a/arch/x86/tools/relocs.c b/arch/x86/tools/relocs.c
index 5d73c443e778b3..220e97841e494c 100644
--- a/arch/x86/tools/relocs.c
+++ b/arch/x86/tools/relocs.c
@@ -770,9 +770,12 @@ static int do_reloc64(struct section *sec, Elf_Rel *rel, ElfW(Sym) *sym,
break;
case R_X86_64_PC32:
+ case R_X86_64_PLT32:
/*
* PC relative relocations don't need to be adjusted unless
* referencing a percpu symbol.
+ *
+ * NB: R_X86_64_PLT32 can be treated as R_X86_64_PC32.
*/
if (is_percpu_sym(sym, symname))
add_reloc(&relocs32neg, offset);
- 然后执行如下命令对当前版本的Linux内核打补丁:
# patch -p1 < patch-relocs.patch
- 然后执行如下命令,清除之前的编译记录:
# make clean
- 此时我们就解决了这个问题,我们只需要回到步骤5重新继续向下操作即可
3.2.2、配置测试虚拟机
- 首先来到根目录创建一个新目录,进入这个新目录后使用debootstrap构建Linux内核启动镜像:
# cd /
# mkdir images-test-linux4.14
# cd images-test-linux4.14/
# wget https://raw.githubusercontent.com/google/syzkaller/master/tools/create-image.sh -O create-image.sh
# chmod +x create-image.sh
# ./create-image.sh
-
若此目录生成如下内容,则代表执行成功:

-
然后切换到系统的根目录,然后使用如下命令启动QEMU虚拟机:
# cd /
# qemu-system-x86_64 -m 2G -smp 2 -kernel /linux-4.14/arch/x86/boot/bzImage -append "console=ttyS0 root=/dev/sda earlyprintk=serial net.ifnames=0" -drive file=/images-test-linux4.14/bullseye.img,format=raw -net user,hostfwd=tcp:127.0.0.1:10021-:22 -net nic,model=e1000 -enable-kvm -nographic -pidfile vm.pid 2>&1 | tee vm.log
- 启动QEMU虚拟机后,终端中不停刷新如下信息,就是无法启动QEMU虚拟机,目前仍没有排查出具体原因,故截至目前无法使用Syzkaller对Linux 4.14版本的内核进行Fuzz测试,后续如果解决此问题,将会更新此文档的这部分内容:

4、总结
4.1、部署架构
关于Syzkaller部署的架构图,如下所示。

对于以上架构图,我们具体来看Syzkaller是否对其中的组件进行了修改。详情可参见下方的表格。
| 是否有修改 | 具体修改内容 | 备注 | |
|---|---|---|---|
| 主机内核 | 无 | 无 | 无 |
| 主机操作系统 | 有 | 开启Intel VT-X/EPT或AMD-V/RVI(V)功能 | 开启程序追踪功能 |
| Guest内核 | 有 | CONFIG_KCOV=y | 启用Linux内核的代码覆盖功能 |
| CONFIG_DEBUG_INFO_DWARF4=y | 启用Linux内核的DWARF4格式调试信息 | ||
| CONFIG_KASAN=y | 启用Linux内核的KASAN功能,用于检测和防止内存错误 | ||
| CONFIG_KASAN_INLINE=y | 启用KASAN内联功能 | ||
| CONFIG_CONFIGFS_FS=y | 启用ConfigFS文件系统支持 | ||
| CONFIG_SECURITYFS=y | 启用SecurityFS支持 | ||
| Guest操作系统 | 有 | 由官方提供,故目前并不清楚其修改细节 | 无 |
| 虚拟机监视器QEMU | 无 | 无 |
4.2、漏洞检测对象
- 检测的对象为Guest内核
- 针对的内核版本为Linux 5.14和Linux 4.14
- 针对的漏洞类型为崩溃性错误
4.3、漏洞检测方法
- 根据Syzkaller的系统调用结构体生成系统调用测试用例
- 使用
syscall()函数(其函数原型为long syscall(long number, ...);)执行系统调用,从而对内核进行Fuzz测试 - 将测试结果保存到主机中
- 目前可以进行测试的系统调用共298个
4.4、种子生成/变异技术
- 初始种子由Syzkaller生成
- 基于种子是否被使用完毕,对种子进行变异
- 变异的策略基于随机,即随机变异特定类型的参数的具体值(比如bool类型、int类型和char类型等)
5、参考文献
- fuzz测试之syzkaller(linux kernel fuzz)
- syzkaller fuzz工具的使用方法及实践实例
- Setup: Ubuntu host, QEMU vm, x86-64 kernel
- syzkaller/docs/internals.md at master · google/syzkaller
- 内核漏洞挖掘技术系列(4)——syzkaller(1)
- 内核漏洞挖掘技术系列(4)——syzkaller(2)
- 内核漏洞挖掘技术系列(4)——syzkaller(3)
- 内核漏洞挖掘技术系列(4)——syzkaller(4)
- 内核漏洞挖掘技术系列(4)——syzkaller(5)
- google/syzkaller: syzkaller is an unsupervised coverage-guided kernel fuzzer
- 内核编译问题#error New address family defined, please update secclass_map#multiple definition of yylloc
- Go下载 - Go语言中文网
- 感谢您下载GoLand!
总结
以上就是本篇博文的全部内容,可以发现,Syzkaller的部署与使用比较复杂,踩了很多坑,不过我都在博客中一一列出来了,避免各位读者再次遇到同样的问题。
对于各类漏洞检测工具的深入研究,我都已经整理成博客供大家学习了,因为知识是共享的。若对该方向感兴趣的读者一定可以从我的博客中收获满满。
总而言之,Syzkaller是一个不错的Fuzz测试的工具,值得大家学习。相信读完本篇博客,各位读者一定对Syzkaller有了更深的了解。