ModelScan是由AI初创公司ProtectAI提供的一个开源项目,旨在扫描机器学习模型以确定它们是否包含不安全的代码。它是首个支持多种模型格式的扫描工具,目前支持H5、Pickle和SavedModel格式。这个工具用于保护使用PyTorch、TensorFlow、Keras、Sklearn、XGBoost等框架的用户,目前有140+star。
为什么要扫描模型
模型通常由自动化管道创建,其他模型可能来自数据科学家的电脑中。无论哪种情况,模型都需要在使用之前从一台机器移动到另一台机器。将模型保存到磁盘的过程称为序列化。
模型序列化攻击是指在分发之前,在序列化(保存)期间将恶意代码添加到模型的内容中,这是特洛伊木马的现代版本。
该攻击通过利用模型的保存和加载过程来发挥作用。在使用加载模型时,PyTorch 会打开文件的内容并开始运行其中的代码。加载漏洞利用已执行的模型的第二秒。
model = torch.load(PATH)模型序列化攻击可用于执行:
-
凭据盗窃(用于将数据写入和读取到环境中其他系统的云凭据)
-
数据盗窃(发送到模型的请求)
-
数据中毒(模型执行任务后发送的数据)
-
模型中毒(改变模型本身的结果)
工具使用方式
安装
pip install modelscan安装完成后,扫描模型
modelscan -p /path/to/model_file.h5支持参数
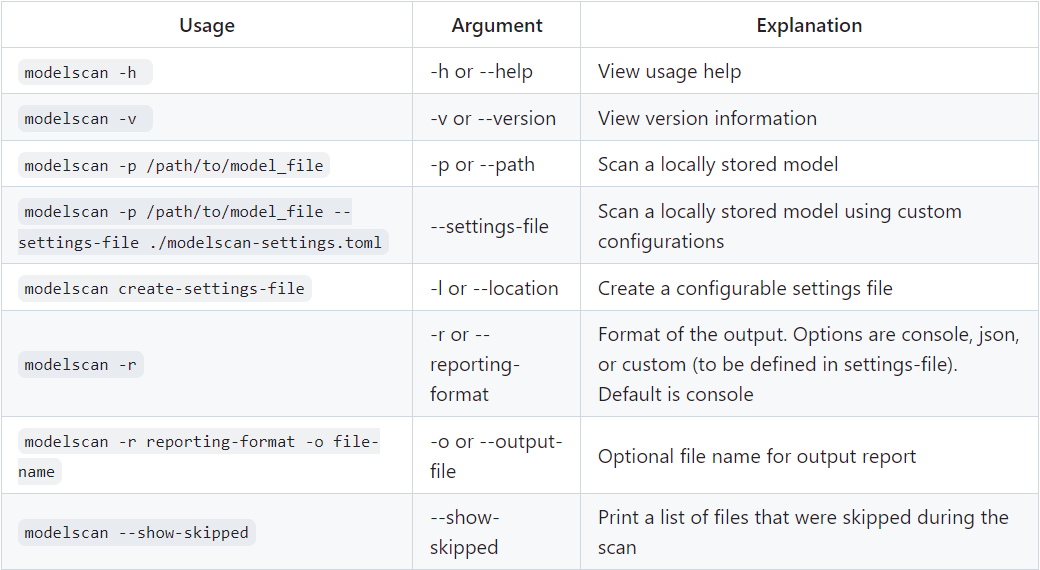
扫描结果
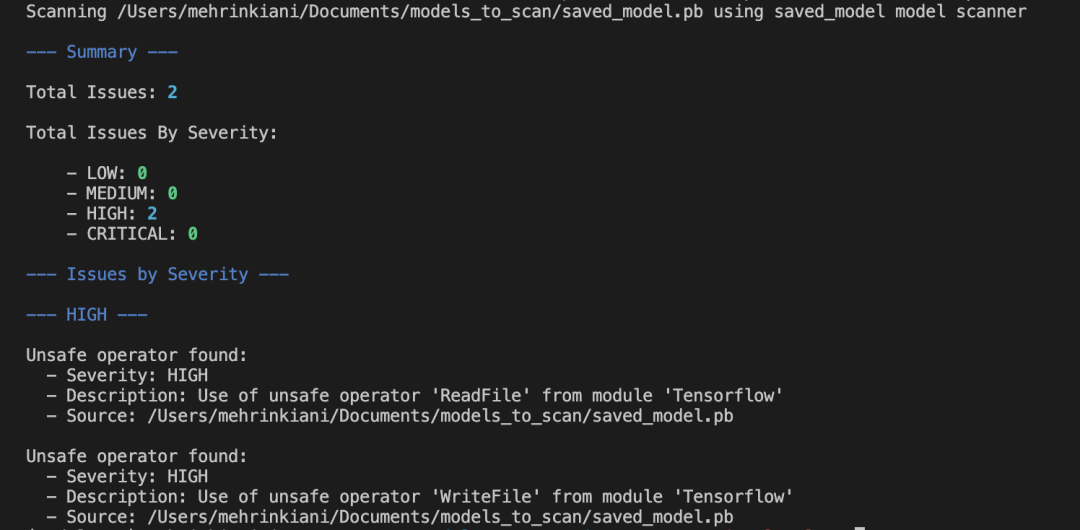
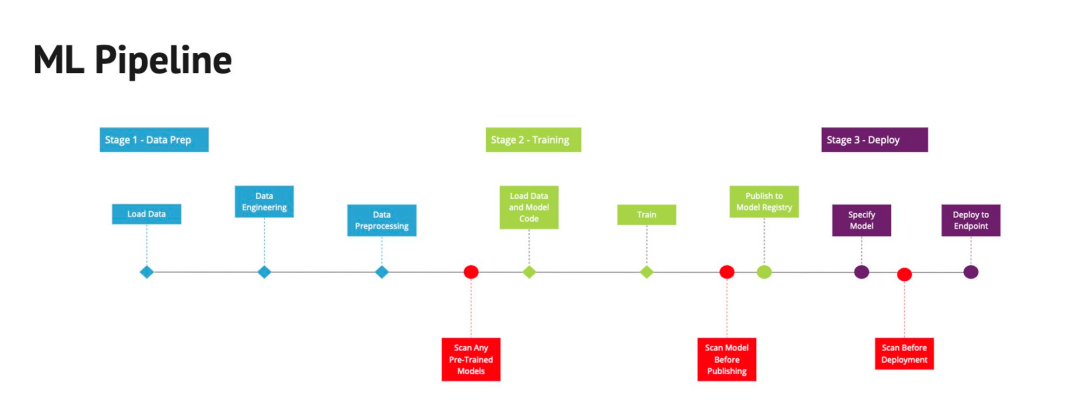
将ModelScan集成到ML Pipeline或CI/CD Pipeline
-
在加载模型之前扫描所有预训练模型以进行进一步工作,以防止模型不会影响您的模型构建或数据科学环境。
-
训练后扫描所有模型,以检测危及新模型的供应链攻击。
-
在部署到端点之前扫描所有模型,以确保模型在存储后未受到损害。
下面的红色块在传统的 ML 管道中突出显示了这一点。
项目地址:https://github.com/protectai/modelscan