开发工具
Python版本:3.6.4
相关模块:
DecryptLogin模块;
pyecharts模块;
以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
数据爬取
既然说了是模拟登录相关的爬虫小案例,首先自然是要实现一下淘宝的模拟登录啦。这里还是利用我们开源的DecryptLogin库来实现,只需三行代码即可:
'''模拟登录淘宝'''@staticmethoddef login():lg = login.Login()infos_return, session = lg.taobao()return session
另外,顺便提一句,经常有人想让我在DecryptLogin库里加入cookies持久化功能。其实你自己多写两行代码就能实现了:
if os.path.isfile('session.pkl'):self.session = pickle.load(open('session.pkl', 'rb'))else:self.session = TBGoodsCrawler.login()f = open('session.pkl', 'wb')pickle.dump(self.session, f)f.close()
我真不想在这个库里添加这个功能,后面我倒是想添加一些其他爬虫相关的功能,这个之后再说吧。好的,偏题了,言归正传吧。接着,我们去网页版的淘宝抓一波包吧。比如F12打开开发者工具后,在淘宝的商品搜索栏里随便输入点东西,就像这样:
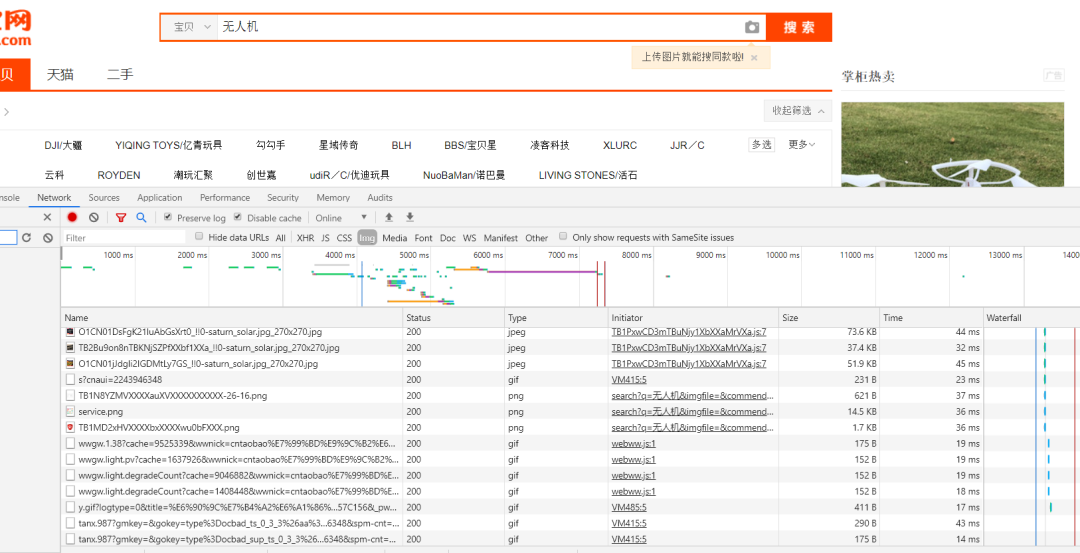
全局搜索一下诸如search这样的关键词,可以发现如下链接:
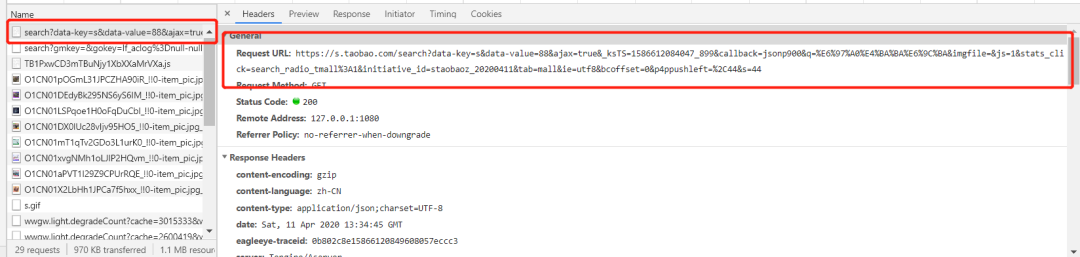
看看它返回的数据是啥:
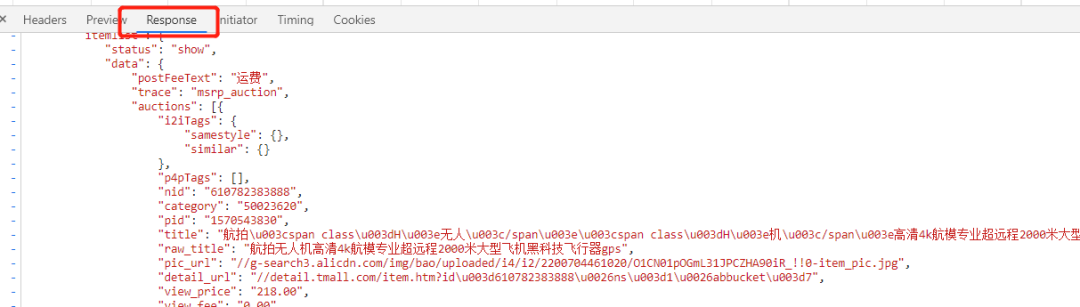
看来应该没错了。另外,如果小伙伴们自己实战的时候没有找到这个接口api,可以尝试再点击一下右上角的下一页商品按钮:
这样就肯定能抓到这个请求接口啦。简单测试一下,可以发现尽管请求这个接口所需携带的参数看上去很多,但实际上必须要提交的参数只有两个,即:
q: 商品名称s: 当前页码的偏移量
好啦,根据这个接口,以及我们的测试结果,现在就可以愉快地开始实现淘宝商品数据的抓取啦。具体而言,主代码实现如下:
'''外部调用'''def run(self):search_url = 'https://s.taobao.com/search?'while True:goods_name = input('请输入想要抓取的商品信息名称: ')offset = 0page_size = 44goods_infos_dict = {}page_interval = random.randint(1, 5)page_pointer = 0while True:params = {'q': goods_name,'ajax': 'true','ie': 'utf8','s': str(offset)}response = self.session.get(search_url, params=params)if (response.status_code != 200):breakresponse_json = response.json()all_items = response_json.get('mods', {}).get('itemlist', {}).get('data', {}).get('auctions', [])if len(all_items) == 0:breakfor item in all_items:if not item['category']:continuegoods_infos_dict.update({len(goods_infos_dict)+1:{'shope_name': item.get('nick', ''),'title': item.get('raw_title', ''),'pic_url': item.get('pic_url', ''),'detail_url': item.get('detail_url', ''),'price': item.get('view_price', ''),'location': item.get('item_loc', ''),'fee': item.get('view_fee', ''),'num_comments': item.get('comment_count', ''),'num_sells': item.get('view_sales', '')}})print(goods_infos_dict)self.__save(goods_infos_dict, goods_name+'.pkl')offset += page_sizeif offset // page_size > 100:breakpage_pointer += 1if page_pointer == page_interval:time.sleep(random.randint(30, 60)+random.random()*10)page_interval = random.randint(1, 5)page_pointer = 0else:time.sleep(random.random()+2)print('[INFO]: 关于%s的商品数据抓取完毕, 共抓取到%s条数据...' % (goods_name, len(goods_infos_dict)))
就是这么简单,我们已经大功告成啦。
数
据
可
视
化
这里我们来可视化一波我们抓到的奶茶数据呗。先来看看在淘宝上卖奶茶的商家在全国范围内的数量分布情况呗:
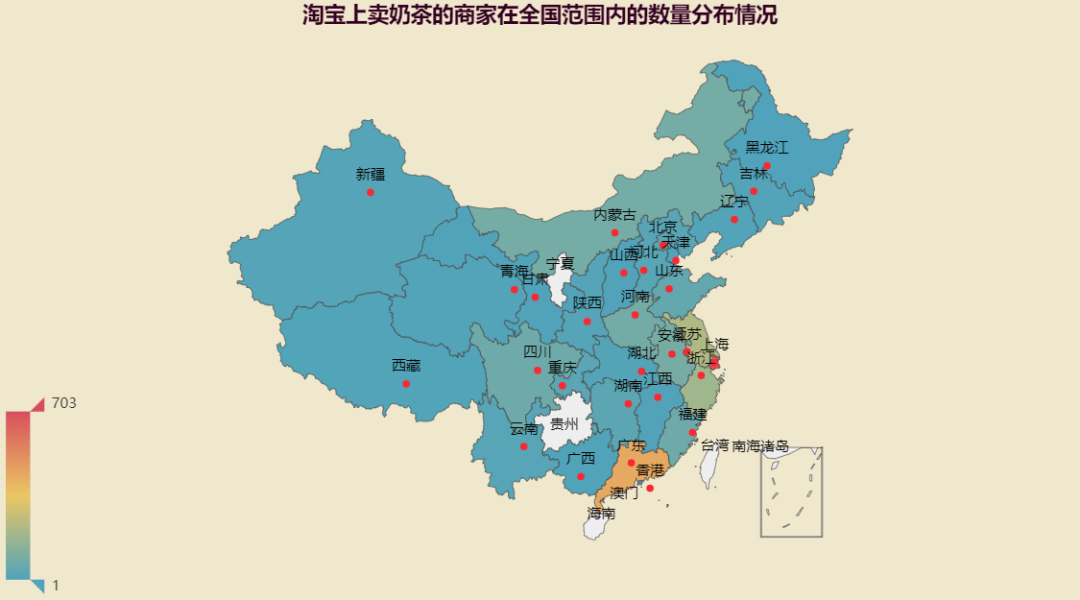
没想到啊,奶茶店铺最多的地方竟然是广东。T_T
再来看看淘宝上卖奶茶的店铺的销量排名前10名呗:
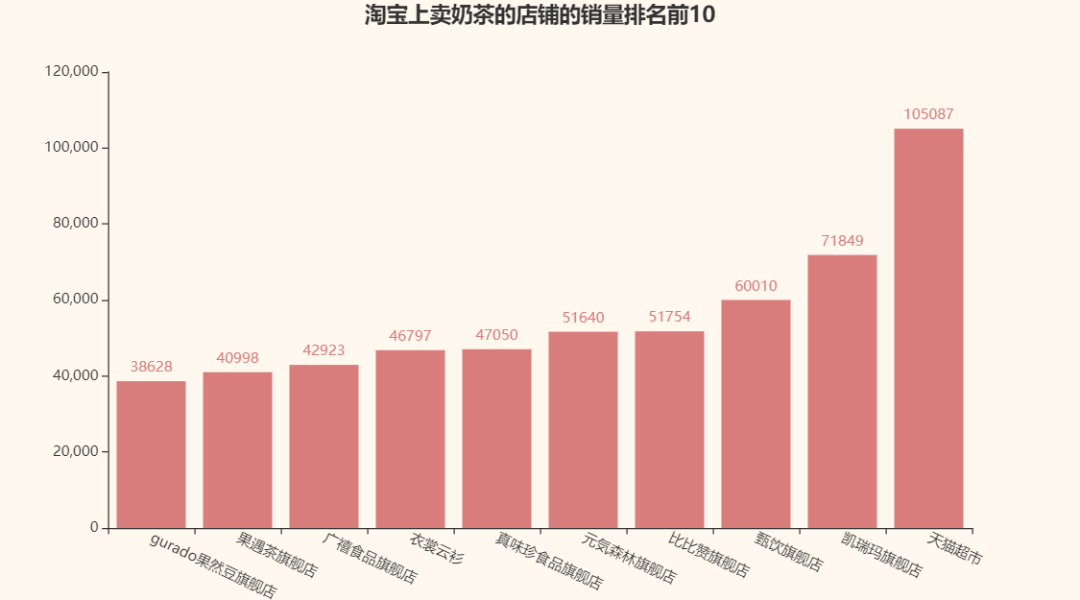
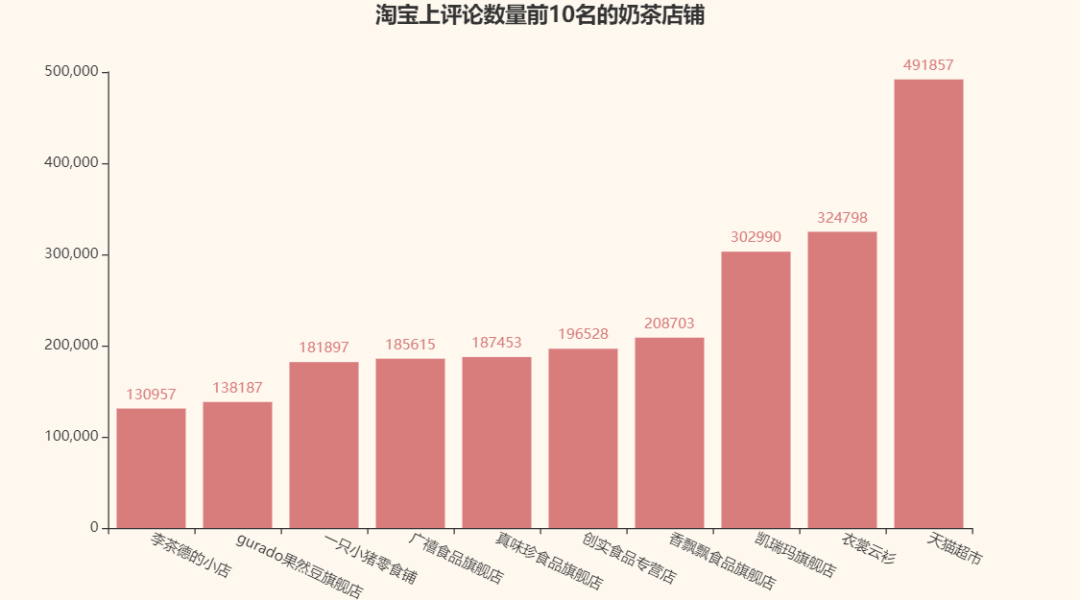
以及淘宝上评论数量前10名的奶茶店铺:
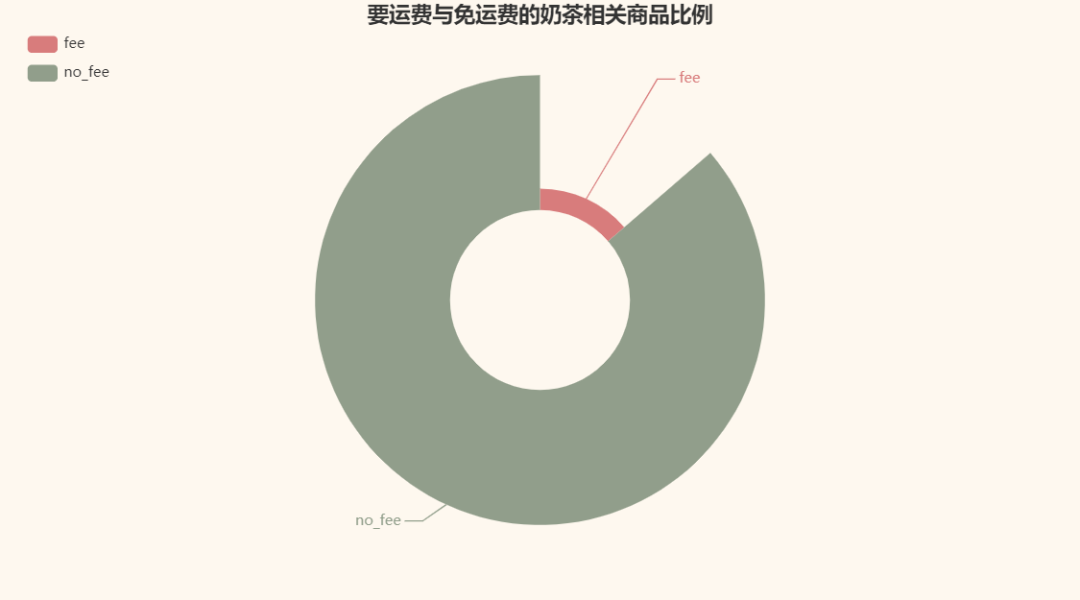
再看看在这些店铺要运费和不要运费的商品比例呗:
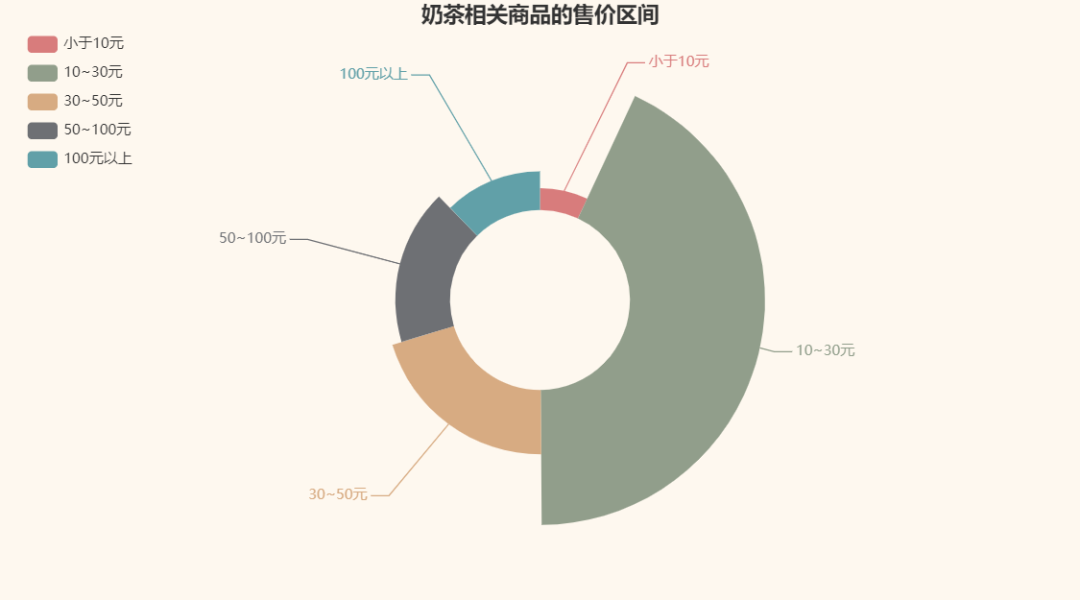
最后,再看看奶茶相关商品的售价区间呗:
差不多今天就这样呗,相关文件里提供了本文中所涉及到的所有源代码以及爬取到的数据,需要的可以在公众号里回复"淘宝商品数据"自取。