目录
Linux进程状态与进程优先级
前置知识
并行与并发
时间片
进程状态
基本介绍
等待状态的本质
swap分区
Linux进程状态
Linux进程状态分类
运行状态(Running)与等待状态(Sleeping)
硬盘等待状态(Disk Sleeping)
停止状态(Stopped)
追踪停止状态(tracing stopped)
僵尸状态(Zombie)和终止状态(Dead)
进程退出
僵尸进程
孤儿进程
进程优先级
Linux进程状态与进程优先级
前置知识
并行与并发
并发:表示CPU在同一个时间内执行多个任务
并行:表示多个CPU在同一个时间内执行各自的任务
示意图如下:

时间片
时间片(timeslice),又称为“量子(quantum)”或“处理器片(processor slice)”,是分时操作系统分配给每个正在运行的进程微观上的一段CPU时间(在抢占内核中是:从进程开始运行直到被抢占的时间)
现代操作系统(如:Windows、Linux、Mac OS X等)允许同时运行多个进程。例如,在打开音乐播放器的同时用浏览器浏览网页并下载文件。由于一台计算机通常只有一个CPU,所以不可能真正地同时运行多个任务。这些进程「看起来像」同时运行,实则是轮番运行,由于时间片通常很短(在Linux上为5ms-800ms),用户基本不会感觉到。
时间片由操作系统内核的调度程序分配给每个进程。首先,内核会给每个进程分配相等的初始时间片,然后每个进程轮番地执行相应的时间,当所有进程都处于时间片耗尽的状态时,内核会重新为每个进程计算并分配时间片,如此往复。
在现代操作系统中,大部分的民用级操作系统均是分时操作系统,这类操作系统的最大特点就是可以通过多道程序和多任务处理的方式让用户感觉到「尽管只有一个CPU,但是应用可以同时执行」
- 多道程序:表示操作系统能够同时管理多个运行中的程序。在早期的计算机系统中,一次只能运行一个程序。当这个程序结束或者因为某种原因暂停时,需要手工干预来加载下一个程序。而多道程序技术允许系统同时保持多个程序在内存中,并且这些程序可以交替执行,这样就提高了系统的利用率和效率
- 多任务处理:表示操作系统能够在同一时刻处理多个任务的能力。在多任务环境下,操作系统通过快速地切换上下文(即保存当前任务的状态并加载新任务的状态),此处切换的时间依据就是时间片,使得多个任务看起来像是同时进行的一样
多道程序强调的是在一个系统中同时存在多个程序的能力,而多任务处理则进一步强调了这些程序能够以一种看似同时的方式执行
与分时操作系统类似的,就是实时操作系统,该类操作系统最大的特点就是如果有一个任务需要执行,实时操作系统会马上(在较短时间内)执行该任务,不会有较长的延时。
进程状态
基本介绍
在操作系统中,一般会存在一个进程状态转换图,例如下图:
整个过程中涉及到五个基本进程状态:
- 创建(new):表示进程创建
- 运行(running):表示进程正在被执行
- 等待(waiting):表示进程正在等待具体事件发生,也被称为阻塞状态
- 就绪(ready):等待被调度器调度执行
- 终止(terminated):进程完成执行
执行过程如下:
- 当进程创建成功后(new),其状态转化为就绪(ready),等待调度器调度(scheduler dispatch),调度到当前进程后开始运行(running),程序正常结束退出(exit)向操作系统返回数据,最后终止(terminated)
- 整个过程中涉及到等待和中断,例如:当程序需要进行类似于IO或者其他事件(I/O or event wait)时就会进入等待状态,等待IO结束或者其他事件结束(I/O or event completion)再从等待转换为就绪状态(ready)等待调度器调度重新进入运行状态(running)
等待状态的本质
下面重点考虑等待(waiting)状态
进程在被创建之后,此时根据操作系统「先描述,再组织」的管理方式,在创建进程时,会形成对应进程的PCB(例如Linux下的task_struct),此时「描述」已经完成
接着程序进入就绪状态,此时操作系统会将进程对应的PCB加载到就绪队列中,在Linux下是一般是使用双向链表结构对每一个PCB进行连接,示意图如下,其中current指针表示当前正在被执行的进程:
每一个CPU需要执行进程,就需要一个与就绪队列有关的结构,该结构中存在当前进程的相关信息,例如进程状态等,一般结构中还会存在一个指针,该指针指向正在运行的进程,此时head指针指向的就是当前进程
如果此时程序需要进行I/O操作,因为I/O操作速度远小于CPU的执行速度,在分时操作系统中,会尽可能提高CPU的利用率,所以此时当前进程就会被操作系统切换到指定设备的等待队列(例如键盘),而CPU继续执行其他存在于就绪队列中的进程。等待队列与就绪队列结构基本一致,也是一个双向链表结构。进程进入等待队列中链接后,对应进程状态更改为等待状态,等待I/O操作完成。
等待队列和运行队列示意图如下:
当I/O操作完成,继续进入就绪队列等待被调度执行进入运行状态
综上所述:等待的本质就是进入对应设备的等待队列进行执行,只是不会执行对应的代码,而等待和运行的切换就是进程PCB在不同的双向链表结构中连接
swap分区
swap分区从字面意思上来看就是交换分区,该分区一般存在于硬盘中,主要用于内存和硬盘之间的资源交换,但是这种交换并不是常规性的,一般出现于内存空间严重不足的情况
当内存空间严重不足时,操作系统为了保证自身的运行正常,会将当前正在等待队列的进程对应的代码和数据放到硬盘的swap分区,尽可能减少内存空间的占用,这个过程也被称为「换出」,此时进程的状态也被称为阻塞挂起状态
而当执行到指定进程时,操作系统会重新将对应进程的代码和数据从swap分区加载到内存,从而达到正常运行的目的,这个过程也被称为「换入」
整个过程中的「换入」和「换出」实际上就是利用「时间换空间」的思想,因为swap分区在硬盘上,所以避免不了交换速度慢,如果出现大量的交换,整机的效率就被大大拉低
部分操作系统也会存在一个属于就绪队列的
swap分区,同样内存空间严重不足时,会将处于就绪队列中的部分进程的代码和数据进行换入和换出
Linux进程状态
前面操作系统的进程状态只是一个广泛的状态,每一种操作系统的进程状态可能不尽相同,下面主要谈Linux下的进程状态
Linux进程状态分类
在Linux下,进程状态被分为下面的7种:
R(Running):运行状态S(Sleeping):可被中断的等待状态D(Disk Sleeping):不可被中断的等待状态T(Stopped):停止状态t(Tracing Stop):追踪停止状态X(Dead):终止状态Z(Zombie):僵尸状态,终止状态前的一种状态
在Linux下,就绪状态和运行状态一般不作区分,所以就绪队列也可以认为就是运行队列
运行状态(Running)与等待状态(Sleeping)
运行状态:表示程序正在就绪队列或者正在被CPU执行,包括前台运行和后台运行
在Linux下,通过ps ajx查看到的状态代号后的+代表正在前台运行,可以使用Ctrl+C终止,没有+则表示后台运行,不可以使用Ctrl+C终止,只能使用kill命令
例如,下面的C语言程序:
#include <stdio.h>
int main()
{
while(1) {
}
return 0;
}对应的Makefile如下:
TARGET=status
SRC=status.c
$(TARGET):$(SRC)
gcc $^ -o $@
.PHONY:clean
clean:
rm -f $(TARGET)查看进程效果如下:
![]()
但是,需要注意,如果上面程序写为:
#include <stdio.h>
#include <unistd.h>
int main()
{
while(1) {
printf("hello\n");
sleep(1);
}
return 0;
}此时尽管程序在前台执行,查看进程时会显示S+,表示在前台等待:

之所以会出现这种情况,是因为printf函数本质是在做I/O,而因为I/O的速度远小于CPU的执行速度,所以为了保证CPU利用率,在做I/O的过程中,当前进程会被操作系统列入到等待队列,而CPU继续执行其他处于就绪队列的进程
硬盘等待状态(Disk Sleeping)
硬盘等待状态是Linux系统特有的进程状态,前面提到当内存空间严重不足时,操作系统为了保证自身在内存中的空间安全,会将部分处于等待队列的进程对应的代码和数据换入swap分区
假设在「内存空间严重不足」的背景下,内存中的某一个进程需要向硬盘写入非常多的数据,此时就会进行I/O操作,而正在做I/O的进程就处于等待队列中,而操作系统此时因为要保证自身安全,就会换出一部分进程的代码和数据到swap分区。
假设这个行为刚好将正在等待完成大量数据I/O的进程对应的代码和数据换入到了swap分区,当I/O设备向内存中指定的进程反馈相关信息(例如存储空间不足)时,由于该进程的相关代码和数据被换入到了swap分区,也就没有办法接受I/O的反馈信息,同时I/O设备也收不到后续的操作指令,这种情况下,就会出现因存储空间不足的问题导致数据丢失。
上面的过程中,如果数据是非常重要的数据,就会导致严重的损失
Linux系统为了防止这个问题的出现,提出了Disk Sleeping,该状态可以保证当内存空间严重不足时,该进程不会被操作系统换出
停止状态(Stopped)
依旧以上面C语言的代码为例:
#include <stdio.h>
#include <unistd.h>
int main()
{
while(1) {
printf("hello\n");
sleep(1);
}
return 0;
}在kill指令中,存在两个选项:
![]()
代号为18的选项代表进程继续,代号为19的选项表示进程停止
在终端中输入:
// 停止进程
kill -19 进程PID
// 继续进程
kill -18 进程PID需要注意,使用kill -18 进程PID继续指定进程时,对应的进程状态代号后面不会带+
就可以停止进程,即将指定进程的状态更改为Stopped
例如上面的程序,运行后执行kill -19 21827:
![]()
想要程序继续运行,可以使用kill -18 21827:
![]()
此时想终止程序,就必须使用kill -9 21827而不能使用Ctrl+C,停止进程后再按下Ctrl+C即可
追踪停止状态(tracing stopped)
对于追踪停止状态,可以在gdb调试指定代码时程序在断点位置暂停看到,例如调试前面的C语言代码,查看对应程序进程可以看到:

所以,调试代码之所以可以让程序停止运行,下一次还可以继续运行,本质就是通过追踪停止状态(tracing stopped)控制
僵尸状态(Zombie)和终止状态(Dead)
每一个进程需要执行都需要管理者的调度,但是进程是否结束管理者也需要知道,这里管理者有操作系统和其父进程,而进程告诉操作系统或其父进程自己正常结束的方式就是通过进程的退出信息,一般退出信息存在进程退出码,0表示进程正常退出,而这一过程发生时刻所处的状态就是僵尸状态
当操作系统或父进程通过某种方式获取了对应的进程的退出信息(例如进程退出时的退出码),进程状态就会变为终止状态,但是如果一直不查看进程退出信息,进程会一直处于僵尸状态
可以使用echo $?显示最近一次进程退出的信息,使用其查看ls命令在无法找到文件时的返回值以及找到文件时的返回值:
- 未找到文件时

- 找到文件时:

这里使用echo $?查看进程退出码本质就是因为bash是ls命令进程的父进程
这也就可以解释为什么之前在写C语言程序时,需要在主函数退出前写上return 0,这里的0就是告诉操作系统或其父进程当前进程正常退出
进程正常退出不一定程序完成了指定的任务,后面会细讲如何通过返回值判断进程是否完成任务
进程退出
进程退出:表示当前进程已经进入了僵尸状态,但不一定进入了终止状态
在Linux中,进程退出的特点是:保留对应进程的PCB,但是会销毁对应进程的代码和数据,而之所以要保留PCB就是因为进程的退出信息依旧存在于对应进程的PCB中,而保留的PCB就会被操作系统管理,方便未来查看
在Linux 1.0的源码中,可以看到部分退出信息,例如退出码和退出信号:
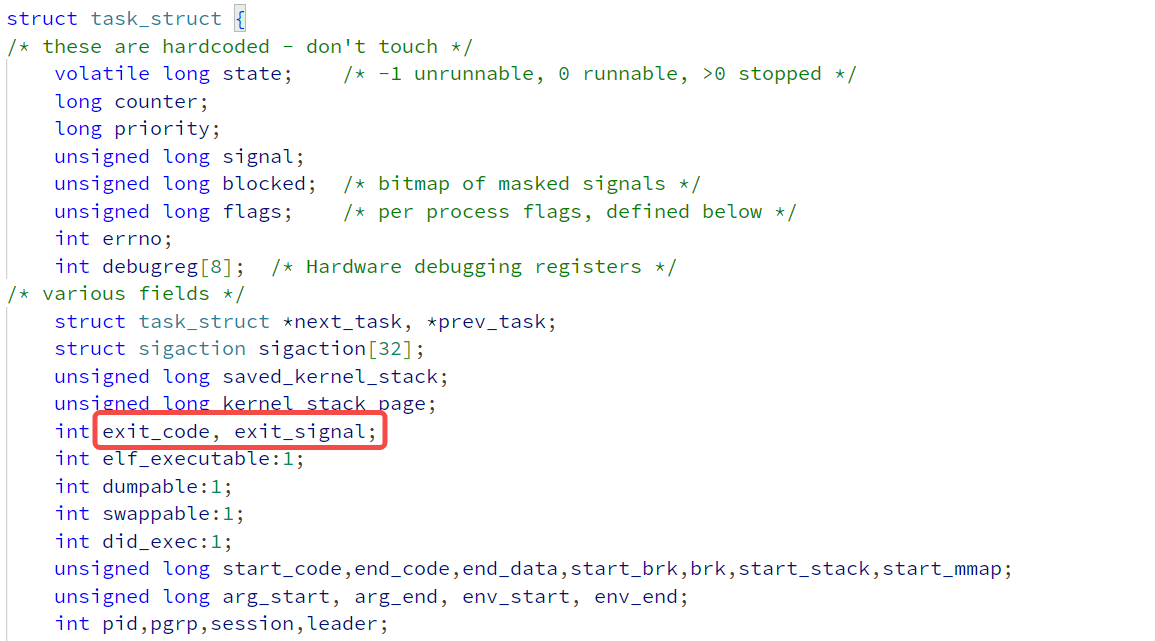
僵尸进程
僵尸进程就是处于僵尸状态的进程,前面提到如果操作系统或者父进程没有获取对应(子)进程的退出信息,该进程就会一直处于僵尸状态
例如下面的代码:
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("I am parent process, mypid: %d, myppid: %d\n", getpid(), getppid());
// 创建子进程
pid_t id = fork();
if (id == 0) {
while(1) {
printf("I am a child process, my pid = %d, my ppid = %d\n", getpid(), getppid());
sleep(2);
}
}
// 父进程不接收子进程的退出信息
while (1) {
}
return 0;
}编译运行上面的代码,再结束掉对应的子进程可以看到下面的信息:

其中,PID为26544的为父进程,PID为26545的为子进程,在上面的代码中,结束子进程后,父进程并没有对子进程的退出信息进行接收,所以此时子进程就会持续保持僵尸状态,并且对应的进程会被修饰为<defunct>,表示「失效的」,此时的task_struct就会被操作系统保存,但是对应进程的代码和数据就会被操作系统移除
因为处于僵尸状态时,进程已经退出,所以不可以再使用kill指令结束该僵尸进程:

进入僵尸状态的进程,默认情况下是不会被任何进程托管,所以一旦出现了僵尸进程,就表示该进程退出信息没有任何进程接收,这种情况下就会出现内存泄漏问题
在前面C/C++语言层面提到的内存泄漏表示开辟的空间在没有使用的情况下,程序运行时没有释放导致持续占用空间,但是这种内存泄漏最大的特点就是程序一旦结束,该空间就会被释放。所以语言层面的内存泄漏在常驻内存的进程上影响最大,但是不论如何,还是要处理这种内存泄漏问题
此处进程的内存泄漏表示处于僵尸状态的进程,因为进程退出信息没有被接受,导致其task_struct一直存在于内存中,但是这种内存泄漏是无法在程序结束后被操作系统自动释放。所以为了避免出现这种内存泄漏问题,需要对每一个进程的退出信息进行接收
孤儿进程
前面提到的是子进程先结束,父进程没有结束并且不接受子进程的退出信息,子进程就处于僵尸状态,如果反过来先结束父进程,再结束子进程就会出现子进程变为孤儿进程,编译运行前面的代码,结束对应父进程结果如下:
![]()
孤儿进程最大的特点就是其PPID变为1,并且为后台运行,所以不可以使用Ctrl+C终止,可以使用top指令查看PID为1对应的进程:

根据上面的结果,可以看到孤儿进程会被系统托管
进程优先级
进程优先级,表示优先被CPU执行的进程的等级,在Linux下,进程优先级等级越小,优先级越高,被优先执行的概率越大
之所以需要进程优先级,是因为大部分的民用电脑都只有一个CPU,但是进程的个数可以有很多,这种情况下就需要进程对CPU资源的抢夺,为了保证部分进程能以更大优势抢到CPU资源,就需要进程优先级
在Linux下,可以使用下面的指令查看到当前用户执行的进程对应的优先级:
ps -la在Linux下,进程优先级由两个值进行控制,一个是PRI(priority),另一个是NI(nice),PRI代表进程启动时系统自动分配的优先级,而NI代表优先级修正值,这个值的范围是[-20, 19]
在计算Linux进程的优先级时,使用公式:PRI = 初始PRI + NI值
例如,启动下面的C语言程序:
#include <stdio.h>
int main()
{
while(1) {
}
return 0;
}使用ps -la查看效果:

因为初始的PRI为80,NI为0,所以最终的PRI = 80 + 0 = 80
在Linux下,不可以修改PRI,但是可以通过修改NI从而改变进程优先级。使用top指令,再输入r,再输入对应的NI值即可修改
如果将NI修正为-6,则会出现下面的结果:

因为默认的PRI值为80,而此时NI值为-6,所以最终的PRI = 80 - 6 = 74
如果此时将NI修正为15,则会出现下面的结果:
![]()
默认的PRI值为80,而此时的NI值为15,所以最终的PRI = 80 + 15 = 95
可以看到,尽管开始修改了PRI为74,下一次再更改NI值时,计算PRI使用的还是初始的PRI+NI
进程优先级并不支持频繁修改,在Linux下,可能修改1次或者2次左右后再修改NI就需要使用root权限
在实际中,进程优先级一般很少去修改,尽管可以在程序中使用函数更改进程优先级或者使用命令修改进程优先级















![[论文速读] Multimodal Fusion on Low-quality Data:A Comprehensive Survey 低质多模态数据融合综述](https://i-blog.csdnimg.cn/direct/718e273222ab4ccba586ea3dba421d4e.png)


