文章链接:https://arxiv.org/pdf/2409.12576
Github链接:https://github.com/RedAIGC/StoryMaker
模型链接:https://huggingface.co/RED-AIGC/StoryMaker
亮点直击
解决了生成具有一致面部、服装、发型和身体的图像的任务,同时允许背景、姿势和风格的变化,通过文本提示实现叙事创作。
提出了StoryMaker,首先从参考图像中提取信息,并使用Positional-aware Perceiver Resampler进行细化。为了防止不同角色与背景互相交织,使用带有分割mask的均方误差损失(MSE loss)对交叉注意力影响区域进行规范化,并通过ControlNet在姿势条件下训练主干网络,以促进解耦。
训练了一个LoRA以增强保真度和质量。
StoryMaker实现了出色的性能,并在现实场景中具有多样化的应用。
总结速览
解决的问题
现有的无调优个性化图像生成方法在处理多个角色时,尽管能保持面部一致性,但在场景的整体一致性方面存在缺陷,这影响了叙事的连贯性。
提出的方案
提出了StoryMaker,一个个性化解决方案,不仅保持面部一致性,还保留了服装、发型和身体的一致性,从而支持通过一系列图像创建故事。
应用的技术
-
Positional-aware Perceiver Resampler :将面部身份信息与裁剪的角色图像相结合,以获取独特的角色特征。
-
均方误差损失(MSE Loss):通过分割mask分别约束不同角色和背景的交叉注意力影响区域,防止角色与背景的混合。
-
姿势条件生成网络:促进与姿势的解耦。
-
LoRA:增强生成图像的保真度和质量。
达到的效果
实验结果证明了StoryMaker的有效性,支持多种应用,并兼容其他插件。
方法
概述
给定包含一或两个角色的参考图像,StoryMaker旨在生成一系列新图像,展示相同的角色,保持面部、服装、发型和身体的一致性。通过改变背景、角色的姿势和风格,根据文本提示可以创建叙事。
首先使用面部编码器提取角色的面部信息(即身份),并通过角色图像编码器获取他们的服装、发型和身体的细节。然后,使用Positional-aware Perceiver Resampler对这些信息进行细化。为了控制主干生成网络,将细化的信息注入IP-Adapter提出的解耦交叉注意力模块。
为了防止多个角色和背景互相交织,分别约束不同角色和背景的交叉注意力影响区域。此外,使用ID损失以保持角色的身份。为了将姿势信息与参考图像解耦,通过ControlNet训练网络,以检测到的姿势进行条件化。为了增强保真度和质量,还训练了带有LoRA的U-Net。一旦训练完成,可以选择丢弃整个ControlNet,通过文本提示控制角色的姿势,或在推理过程中用新姿势引导图像生成。完整流程如下图2所示。
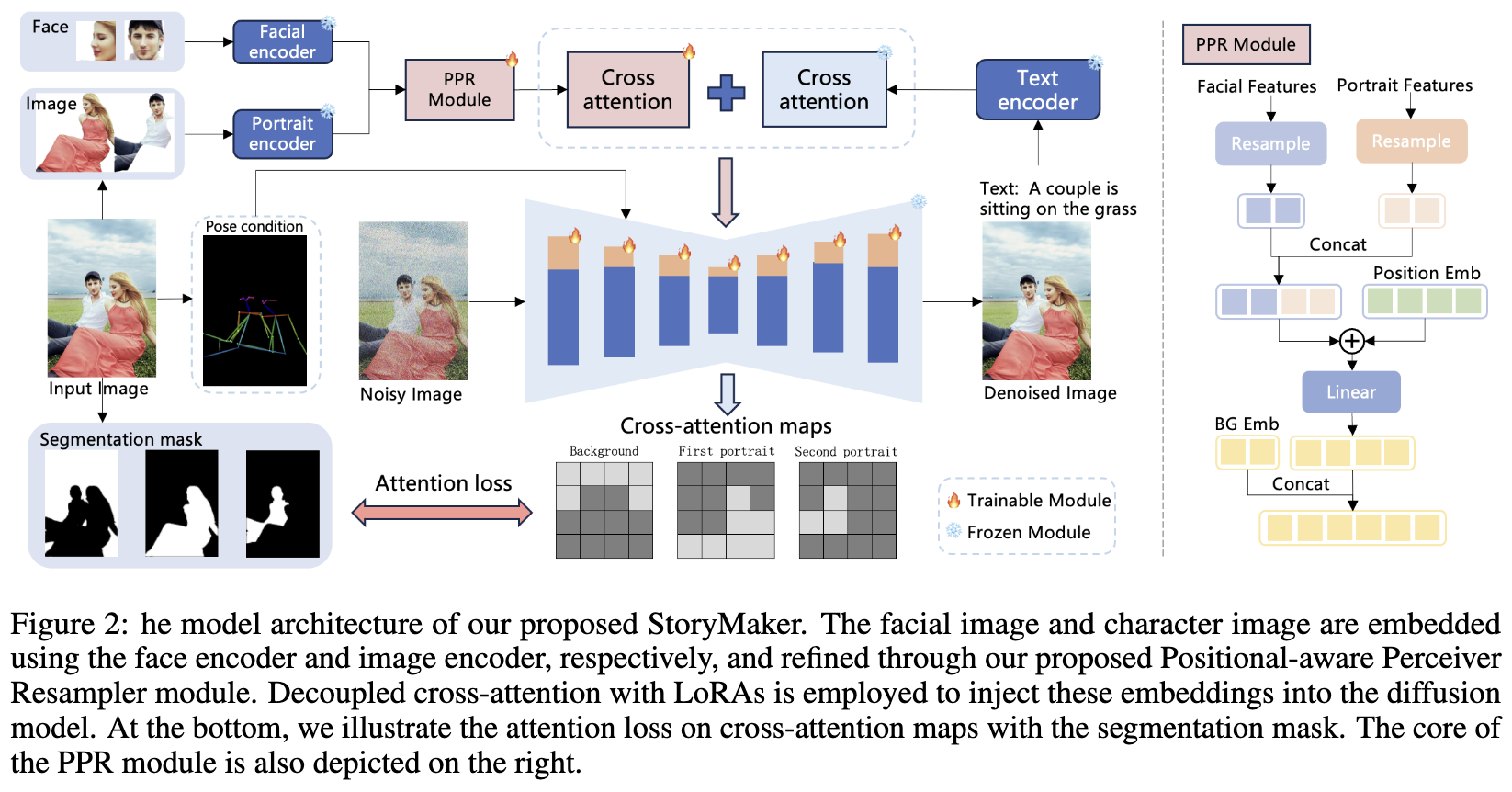
参考信息提取
由于面部识别模型提取的面部特征有效捕捉语义细节并增强保真度,类似于InstantID和IP-Adapter-FaceID,利用Arcface检测面部并从参考图像中获得对齐的面部embeddings。为了保持发型、服装和身体的一致性,首先对参考图像进行分割以裁剪角色。遵循IP-Adapter和MM-Diff等最新工作,使用预训练的CLIP视觉编码器,以提取角色的发型、服装和身体特征。在训练过程中,面部编码器(即Arcface模型)和图像编码器(即CLIP视觉编码器)保持冻结状态。
使用Positional-aware Perceiver Resampler进行参考信息细化
遵循InstantID和IP-adapter,利用两个独立的重采样模块将面部特征()和角色特征()分别转换为面部embeddings和角色embeddings。这些embeddings被串联并与位置embeddings()增强,以区分不同的角色。为了区分前景和背景,引入一个可学习的背景嵌入(即),并将其串联到最终embedding中。将两个独立的重采样模块记为 和 ,Positional-aware Perceiver Resampler的公式如下:
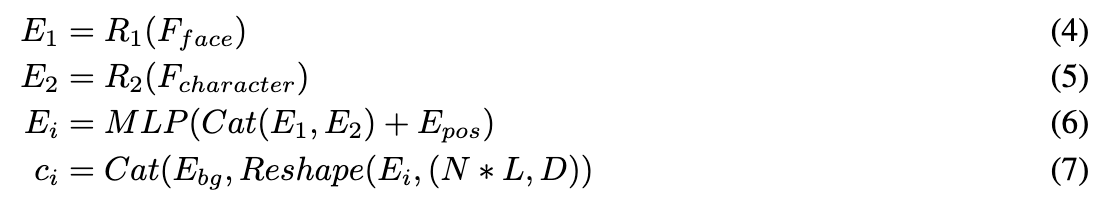
其中,分别表示令牌的数量和角色embeddings的维度,表示参考图像中的角色数量。图像提示embed为。将背景embedding的个tokens表示为,因此的维度为。
解耦交叉注意力
在提取参考信息后,利用解耦交叉注意力将其嵌入到文本到图像模型中,遵循IP-Adapter。
从角色图像解耦姿势
姿势多样性对叙事至关重要。仅基于角色图像进行训练可能导致网络对参考图像的姿势过拟合,从而生成具有相同姿势的角色。为了促进角色图像与姿势的解耦,使用Pose-ControlNet对训练进行姿势条件化。在推理过程中,可以选择丢弃ControlNet,通过文本提示控制生成角色的姿势,或使用新提供的姿势引导生成。
使用LoRA进行训练
此外,为了增强ID一致性、保真度和质量,类似于IP-Adapter-FaceID,将LoRA层集成到扩散模型的每个注意力层中。具体而言,在每个交叉注意力层中,, , , 和 的修改如下:

冻结U-Net模型,仅使可训练。
带masks的交叉注意力图的损失约束
为了防止多个角色与背景互相交织,研究者们使用不同角色和背景的embeddings对交叉注意力的影响区域进行规范化。与MM-Diff不考虑背景不同,引入一个可学习的背景embeddings来解决此问题。
通过计算交叉注意力的softmax值与预训练网络预测的分割mask之间的均方误差损失(MSE loss)来约束影响区域。该设计,即引入可学习的背景embeddings,促进了前景角色之间以及前景与背景之间的更好分离。如公式7所示,图像提示的前个tokens表示背景,而每组后续的个tokens表示每个角色。在每个图像交叉注意力层中,通过将所有的个tokens相加来获得每个角色的大小为的交叉注意力图:

提出的注意力损失可以公式化为以下形式:

其中,是参考图像中的角色数量,"+1"表示背景。
总体损失
在训练中,将在所有层上取平均,并与扩散损失结合,如下所示:

其中,是最终训练目标,是加权标量。
实验
设置
数据集
研究者们收集了一个内部角色数据集,总共有50万张图像,包括30万张单角色图像和20万张双角色图像。图像标题使用CogVLM自动生成。
使用buffalo_l模型检测并获取每个面部的ID-embedding 。角色分割mask是通过内部实例分割模型获取的。
训练细节
基于Stable Diffusion XL训练模型。类似于IP-Adapter-FaceID,使用buffalo_l 作为面部识别模型,使用OpenCLIP ViT-H/14作为图像编码器。可训练的LoRA权重的秩设置为128。
在训练期间,冻结基础模型的原始权重,仅训练PPR模块和LoRA权重。此外,分别从IP-Adapter-FaceID和IP-Adapter初始化面部和角色的重采样模块权重。本文的模型在8个NVIDIA A100 GPU上训练8000步,每个GPU的批量大小为8。使用AdamW,前4000步的学习率为1e-4,后4000步为5e-5。将设置为0.1。训练图像的分辨率调整为1024×1024。在训练过程中,文本标题随机丢弃10%,裁剪的角色图像随机丢弃5%。在推理期间,使用UniPC采样器,设定25步,分类器无指导的引导值设置为7.5。
评估指标
为了与其他方法进行比较,在单角色设置中评估本文的方案。共收集了40个角色的数据集,并从FastComposer采用20个独特的文本提示,为每个提示生成4张图像。遵循FastComposer 和MM-Diff,使用CLIP图像相似度(CLIP-I)将生成的图像与参考图像进行比较。为了评估身份保留,采用buffalo_l模型检测并计算两个面部图像之间的余弦相似度(Face Sim.)。此外,使用CLIP分数(CLIP-T)评估图像与文本的相似度。
结果
定量评估
如下表1所示,将StoryMaker与四个无调优角色生成模型进行比较,包括MM-Diff、PhotoMaker-V2、InstantID和IP-Adapter-FaceID。

StoryMaker在先前方法中获得了最高的CLIP-I分数,这归功于整个肖像的一致性,包括面部、发型和服装,尽管其CLIP-T相对较低,稍微妥协了文本提示的遵循性。对于面部相似度,本文的方法优于其他方法,除了InstantID。将InstantID的优越表现归因于广泛的训练数据和IdentityNet控制模块。需要注意的是,在所有评估的方法中,只有MM-Diff和本文的方法能够保留多个人的ID。此外,StoryMaker是唯一一个在面部、服装、发型和身体上都保持一致性的方案。
可视化
单角色图像生成。如下图3所示,与为身份保留设计的IP-Adapter-FaceID、InstantID、MM-Diff和PhotoMaker-V2相比,所提的StoryMaker不仅保持了面部的保真度,还保持了服装的一致性。虽然IP-Adapter-Plus在服装一致性方面表现良好,但在文本提示遵循和面部保真度方面存在不足。

多角色图像生成。进一步展示多角色图像生成的性能。如下图4所示,借助文本提示,StoryMaker可以生成两个角色的不同姿势,同时保持面部、服装和发型的一致性。此外,由于使用了两个独立的重采样模块,可以将角色embedding(公式7中的)设置为全0,同时在图4的最后四列中仅保持ID保留并生成风格化合成。

个性化故事扩散。给定参考角色图像,StoryMaker可以根据任意提示生成一致的角色图像,从而利用一系列提示创建故事。如图1的前三行所示,本文的方法根据五个文本提示描述的“一个办公室工作的人的一天”生成了一系列单人图像。生成的角色姿势各异,而不受给定姿势图的控制。在下图1的最后两张图像中,展示了以电影《日出之前》为主题的故事,生成了两个角色。为了实现最佳效果,使用指定姿势控制生成。

应用
本文的方法在对齐ID、服装、一致性保持提示及提升生成图像的多样性和质量方面表现出色,为多样的下游应用奠定了坚实基础。如下图5(a)所示,男性或女性角色可以在保持服装一致性的情况下变为男孩或女孩。
此外,StoryMaker展示了惊人的服装交换能力(图5(b)),通过将角色图像替换为服装图像,实现了这一点,这表明角色嵌入包含服装信息。此外,类似于IP-Adapter和InstantID,StoryMaker作为即插即用模块,能够与LoRA或ControlNet集成,以生成多样化图像,同时保持角色一致性,如下图5(c,e)所示。由于其角色保留能力,人像变体得以实现,如图5(d)所示。此外,研究者们探索了两个角色之间的角色插值,展示了StoryMaker混合多个角色特征的能力,如图5(f)所示。

结论
本文介绍了StoryMaker,这是一种新颖的个性化图像生成方法,能够在多角色场景中不仅保持面部身份的一致性,还能保持服装、发型和身体的一致性。
本文的方法通过允许背景、姿势和风格的变化来增强叙事创作,从而实现多样和连贯的故事讲述。StoryMaker利用Positional-aware Perceiver Resampler融合从面部图像和裁剪角色图像中提取的特征,获得独特的角色embedding。为了防止多个角色与背景的交错,使用MSE损失和分割mask分别约束不同角色和背景的交叉注意力影响区域。通过引入ControlNet进行姿势解耦和使用LoRA增强保真度,StoryMaker始终生成高质量且匹配身份和视觉一致性的图像。
广泛实验表明,StoryMaker在保持角色身份和一致性方面表现优越,尤其在多角色场景中超越现有的无调优模型。该模型的多样性在服装交换、角色和与其他生成插件的集成等各种应用中得到了进一步体现。相信StoryMaker对个性化图像生成作出了重要贡献,并为数字故事讲述、漫画等领域的广泛应用开辟了可能性,在这些领域中,个性与叙事连贯性至关重要。
参考文献
[1] StoryMaker: Towards Holistic Consistent Characters in Text-to-image Generation
更多精彩内容,请关注公众号:AI生成未来