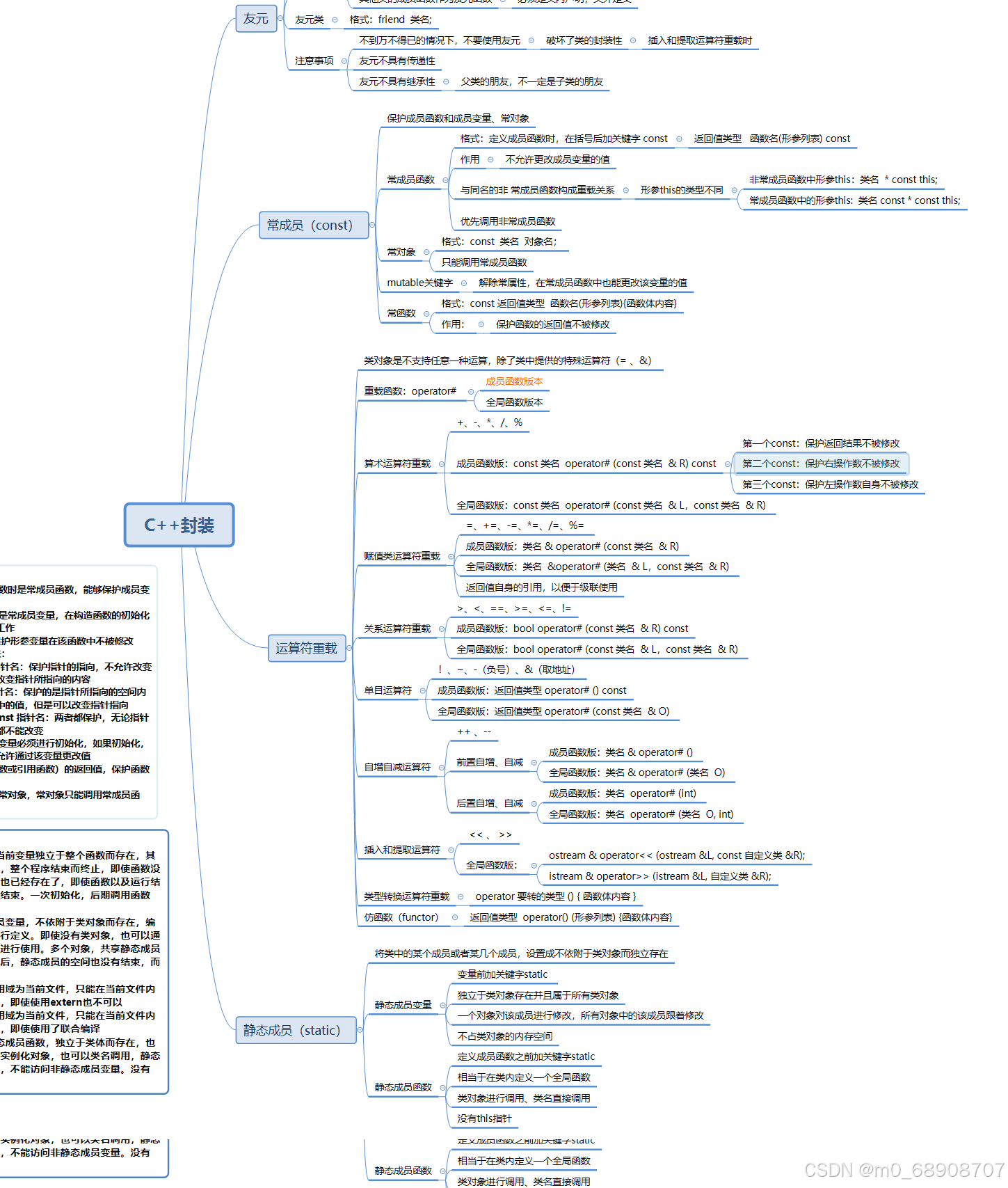
什么是统计量
我们首先给出统计量的定义:设
X
1
,
X
2
,
⋯
,
X
n
X_1,X_2,\cdots,X_n
X1,X2,⋯,Xn 为来自于总体X的一个样本,
g
(
X
1
,
X
2
,
⋯
,
X
n
)
g(X_1,X_2,\cdots,X_n)
g(X1,X2,⋯,Xn) 为关于
X
1
,
X
2
,
⋯
,
X
n
X_1,X_2,\cdots,X_n
X1,X2,⋯,Xn的函数,如果g中不含未知参数,则其被称为是一个统计量。
用大白话来说就是用都是已知的数据做计算就是一个统计量,把数据相加,相减,求平均,求次方等等结果全部都是一个统计量。
而有些统计量在生活中更具有实际意义和使用价值,大家使用的也比较多,所以有如下常用的统计量:
样本均值:
X
ˉ
=
1
n
∑
i
=
1
n
X
i
\bar X = \frac1n \sum\limits_{i=1}^{n} X_i
Xˉ=n1i=1∑nXi
样本方差:
S
2
=
1
n
−
1
∑
i
=
1
n
(
X
i
−
X
ˉ
)
2
=
1
n
−
1
(
∑
i
=
1
n
X
i
2
−
n
X
ˉ
2
)
S^2 = \frac1{n-1}\sum\limits^{n}_{i=1}(X_i-\bar X)^2=\frac1{n-1}(\sum\limits_{i=1}^{n} X_i^2 - n \bar X^2)
S2=n−11i=1∑n(Xi−Xˉ)2=n−11(i=1∑nXi2−nXˉ2)
样本标准差:
S
=
1
n
−
1
(
∑
i
=
1
n
X
i
2
−
n
X
ˉ
2
)
S=\sqrt{\frac1{n-1}(\sum\limits_{i=1}^{n} X_i^2 - n \bar X^2)}
S=n−11(i=1∑nXi2−nXˉ2)
k阶原点矩
A
k
=
1
n
∑
i
=
1
n
X
i
k
,
k
=
1
,
2
,
⋯
;
A_k=\frac1n \sum\limits_{i=1}^{n}X_i^{k},k=1,2,\cdots;
Ak=n1i=1∑nXik,k=1,2,⋯;
k阶中心矩
B
k
=
1
n
∑
i
=
1
n
(
X
i
−
X
ˉ
)
k
,
k
=
2
,
3
,
⋯
;
B_k=\frac1n\sum\limits_{i=1}^{n}(X_i - \bar X)^k,k=2,3,\cdots;
Bk=n1i=1∑n(Xi−Xˉ)k,k=2,3,⋯;
需要注意的就是样本方差的分母是n-1,主要是考虑到无偏性,具体的推导可以参考:https://blog.csdn.net/qq_42692386/article/details/137955127
抽样分布
什么是抽样分布
首先来辨别一下统计中常说的几个词:总体分布,样本分布,抽样分布。
总体分布是总体中各元素的观察值所形成的相对频数分布,例如之前说过的二项分布,整个总体中的元素都是只有0和1两个取值,根据总体分布可以得到总体均值
μ
\mu
μ和总体方差
σ
2
{\sigma }^{2}
σ2等。
样本分布是从总体中抽出一个容量为n的样本,由这n个观察值形成的相对频数分布,称为样本分布。用来描述样本分布的样本统计量有样本均值
X
ˉ
\bar X
Xˉ和样本方差
S
2
S^2
S2等
抽样分布:抽样分布是指样本统计量的概率分布。对于抽样分布的理解最核心的点是:样本统计量是被当成了一个随机变量来看待的,它是统计量的概率分布。
以样本均值为例,在之前说到的样本分布中是一个具体的值,是在总体中抽到的个数为n的一个样本加总平均计算得到的一个固定的值,但是这个值是只抽取一组样本计算的一个样本均值结果,在整个总体中还可以抽出其他更多的个数为n的样本,每抽取一组样本都可以计算出一个样本均数,而且这些样本均数或多或少都会有些差异。
我们不妨用身高的这个例子还原一下这个过程。假设我们现在想了解中国成年男子的身高情况,通过简单随机抽样获取了一个1000人的样本,计算出样本均值为1.76(米),样本标准差为0.1(米)。现在,我们按照同样的方法重复抽100次,每次都抽取1000人。在这个过程中我们实际一共调查了10万人,不过这10万人以1000人为一组被分成了100个样本,而每一组都可以计算一个样本均值,假设分别为:1.76,1.72,1.69,1.77,……,1.75,这就是一个关于身高的样本均值的抽样分布。由此,我们一共获得了100个样本均值,从而可以对这100个数求平均数和标准差。
在统计后面的学习中,我们经常会看到样本均值有 E ( X ˉ ) = μ , D ( X ˉ ) = σ 2 n E(\bar X)=\mu,D(\bar X)=\frac{\sigma^2}{n} E(Xˉ)=μ,D(Xˉ)=nσ2这样的公式,也就是样本均值的期望等于总体期望,样本均值的方差是总体方差的 1 n \frac{1}{n} n1,这里的式子中的 X ˉ \bar X Xˉ就是一个随机变量,如果理解为一个样本下的均值理解为一个常数值的话,那么你就会疑惑为什么一个常数值得方差不是0而是 σ 2 n \frac{\sigma^2}{n} nσ2了
三大抽样分布
在正态总体的条件下有如下三个常用统计量的分布
卡方分布( χ 2 \chi^2 χ2 )
设
X
1
,
X
2
,
⋯
,
X
n
X_1,X_2,\cdots,X_n
X1,X2,⋯,Xn为来自总体
N
(
0
,
1
)
N(0,1)
N(0,1)的样本,则称统计量
χ
2
=
X
1
2
+
X
2
2
+
⋯
+
X
n
2
\chi^2=X_1^2+X_2^2+\cdots+X_n^2
χ2=X12+X22+⋯+Xn2服从自由度为n的卡方分布,记为
χ
2
∼
χ
2
(
n
)
\chi ^2 \sim \chi^2(n)
χ2∼χ2(n)
卡方分布的概率密度函数和图像如下:
f
(
y
)
=
1
2
n
/
2
Γ
(
n
/
2
)
y
n
/
2
−
1
e
−
y
/
2
,
y
>
0
f(y) = \frac{1}{2^{n/2}\Gamma(n/2)} y^{n/2 - 1} e^{-y/2},y>0
f(y)=2n/2Γ(n/2)1yn/2−1e−y/2,y>0
其中
Γ
(
n
/
2
)
\Gamma(n/2)
Γ(n/2)是伽马函数。(一般教材中会有这些内容,但好像有的专业不做要求,只要知道相关性质就可以了,关于伽马函数可自行百度)

卡方分布有如下性质:
1.可加性:设
χ
1
2
∼
χ
2
(
n
1
)
,
χ
2
2
∼
χ
2
(
n
2
)
\chi _1^2 \sim \chi ^2(n_1),\chi_2^2 \sim \chi^2(n_2)
χ12∼χ2(n1),χ22∼χ2(n2)且
χ
1
2
,
χ
2
2
\chi_1^2,\chi_2^2
χ12,χ22相互独立,那么有
χ
1
2
+
χ
2
2
∼
χ
2
(
n
1
+
n
2
)
\chi_1^2+\chi_2^2 \sim \chi^2(n_1+n_2)
χ12+χ22∼χ2(n1+n2)
2.期望和方差:假设
χ
2
∼
χ
2
(
n
)
\chi ^2 \sim \chi^2(n)
χ2∼χ2(n),则有
E
(
χ
2
)
=
n
,
D
(
χ
2
)
=
2
n
E(\chi^2)=n,D(\chi^2)=2n
E(χ2)=n,D(χ2)=2n
3.上
α
\alpha
α分位点:对于给定的正数
α
,
0
<
α
<
1
\alpha,0<\alpha<1
α,0<α<1,称满足条件
P
{
χ
2
>
χ
α
2
(
n
)
}
=
∫
χ
α
2
(
n
)
∞
f
(
y
)
d
y
=
α
P\{\chi^2 > \chi^2_\alpha(n)\}=\int_{ \chi^2_\alpha(n)}^{\infty}f(y)\mathrm{d}y=\alpha
P{χ2>χα2(n)}=∫χα2(n)∞f(y)dy=α的点
χ
α
2
(
n
)
\chi^2_\alpha(n)
χα2(n)为分布的上
α
\alpha
α分位点

t分布
设
X
∼
N
(
0
,
1
)
,
Y
∼
χ
2
(
n
)
X \sim N(0,1),Y \sim \chi^2(n)
X∼N(0,1),Y∼χ2(n),且
X
,
Y
X,Y
X,Y相互独立,那么我们称随机变量
t
=
X
Y
/
n
t=\frac{X}{\sqrt{Y/n}}
t=Y/nX服从自由度为
n
n
n的
t
t
t分布,也称为学生分布。
t分布的概率密度函数和图像如下:

卡方分布有如下性质:
对称性:
t
1
−
α
(
n
)
=
−
t
α
(
n
)
t_{1-\alpha}(n)=-t_{\alpha}(n)
t1−α(n)=−tα(n),类似于正态分布
期望与方差:
E
(
t
α
(
n
)
)
=
0
,
D
(
t
α
(
n
)
)
=
n
n
−
2
E(t_\alpha(n))=0,D(t_\alpha(n))=\frac{n}{n-2}
E(tα(n))=0,D(tα(n))=n−2n
大样本情况下近似于正态分布:
n
>
45
,
t
α
(
n
)
≈
z
α
n>45,t_\alpha(n)\approx z_\alpha
n>45,tα(n)≈zα
F分布
设
U
∼
χ
2
(
n
1
)
,
V
∼
χ
2
(
n
2
)
U \sim \chi^2(n_1),V \sim \chi^2(n_2)
U∼χ2(n1),V∼χ2(n2),且
U
,
V
U,V
U,V相互独立,则称随机变量
F
=
U
/
n
1
V
/
n
2
F=\frac{U/n_1}{V/n_2}
F=V/n2U/n1服从自由度为
(
n
1
,
n
2
)
(n_1,n_2)
(n1,n2)的
F
F
F分布,记为
F
∼
F
(
n
1
,
n
2
)
F \sim F(n_1,n_2)
F∼F(n1,n2)
F分布的概率密度函数图像如下:

F分布的性质如下:
如有
F
∼
F
(
n
1
,
n
2
)
,
则
1
F
∼
F
(
n
2
,
n
1
)
如有F \sim F(n_1,n_2), 则\frac1{F} \sim F(n_2,n_1)
如有F∼F(n1,n2),则F1∼F(n2,n1)
F
1
−
α
(
n
1
,
n
2
)
=
1
F
α
(
n
2
,
n
1
)
F_{1-\alpha}(n_1,n_2)=\frac{1}{F_{\alpha}(n_2,n_1)}
F1−α(n1,n2)=Fα(n2,n1)1
正态总体的样本均值与样本方差的分布
之前我们说过抽样分布就是对统计量的概率分布的描述,我们知道日常生活中的大样本基本服从正态分布,而我们一般无法统计总体只能进行抽样并只能得到样本均值和样本方差,所以研究正态总体的样本均值与样本方差的分布就有相当重要的意义。在之后我们会说到区间估计与假设检验就是这方面的实际应用和扩展。
设总体
X
X
X(不管服从什么分布,只要方差和均值存在)的均值为
μ
\mu
μ,方差为
σ
2
\sigma^2
σ2,
X
1
,
X
2
,
⋯
,
X
n
X_1,X_2,\cdots,X_n
X1,X2,⋯,Xn为来自总体
X
X
X的一个样本,样本均值为
X
ˉ
\bar X
Xˉ,样本方差为
S
2
S^2
S2,则有:
E
(
X
ˉ
)
=
μ
,
D
(
X
ˉ
)
=
σ
2
n
,
E
(
S
2
)
=
σ
2
E(\bar X)=\mu,D(\bar X)=\frac{\sigma^2}{n},E(S^2)=\sigma^2
E(Xˉ)=μ,D(Xˉ)=nσ2,E(S2)=σ2
进而设
X
∼
N
(
μ
,
σ
2
)
X \sim N(\mu,\sigma^2)
X∼N(μ,σ2),即在正态总体下,设
X
1
,
X
2
,
⋯
,
X
n
X_1,X_2,\cdots,X_n
X1,X2,⋯,Xn为来自正态总体总体
X
∼
N
(
μ
,
σ
2
)
X \sim N(\mu,\sigma^2)
X∼N(μ,σ2)的一个样本,样本均值为
X
ˉ
\bar X
Xˉ,样本方差为
S
2
S^2
S2,则
X
ˉ
\bar X
Xˉ与
S
2
S^2
S2相互独立,且有如下结论:
结论1:
X
ˉ
∼
N
(
μ
,
σ
2
n
)
\bar{X} \sim N(\mu, \dfrac{\sigma^2}{n})
Xˉ∼N(μ,nσ2)
证明:根据正态分布的可加性,设
X
1
,
X
2
,
⋯
,
X
n
∼
N
(
μ
,
σ
2
)
X_1,X_2,\cdots,X_n\sim N(\mu,\sigma^2)
X1,X2,⋯,Xn∼N(μ,σ2),可得
X
1
+
X
2
+
⋯
+
X
n
∼
N
(
n
μ
,
n
σ
2
)
X_1+X_2+\cdots+X_n\sim N(n\mu,n\sigma^2)
X1+X2+⋯+Xn∼N(nμ,nσ2)
X
ˉ
=
X
1
+
X
2
+
⋯
+
X
n
n
∼
N
(
μ
,
σ
2
n
)
\bar{X}=\dfrac{X_1+X_2+\cdots+X_n}{n}\sim N\left(\mu,\dfrac{\sigma^2}{n}\right)
Xˉ=nX1+X2+⋯+Xn∼N(μ,nσ2)
转化为标准型有:
X
ˉ
−
μ
σ
/
n
∼
N
(
0
,
1
)
\begin{align} \frac{\bar{X}-\mu}{\sigma / \sqrt{n}} \sim N(0,1) \end{align}
σ/nXˉ−μ∼N(0,1)
结论2:
1
σ
2
∑
i
=
1
n
(
X
i
−
μ
)
2
=
∑
i
=
1
n
(
X
i
−
μ
σ
)
2
∼
χ
2
(
n
)
\dfrac{1}{\sigma^2} \sum\limits^{n}_{i=1}\left(X_i-\mu \right)^2= \sum\limits^{n}_{i=1}\left(\frac{X_i-\mu}{\sigma}\right)^2 \sim \chi^2(n)
σ21i=1∑n(Xi−μ)2=i=1∑n(σXi−μ)2∼χ2(n)
结论3:
(
n
−
1
)
S
2
σ
2
=
∑
i
=
1
n
(
X
i
−
X
ˉ
σ
)
2
∼
χ
2
(
n
−
1
)
\dfrac{(n-1)S^2}{\sigma^2}= \sum\limits^{n}_{i=1}\left(\frac{X_i-\bar X}{\sigma}\right)^2 \sim \chi^2(n-1)
σ2(n−1)S2=i=1∑n(σXi−Xˉ)2∼χ2(n−1)
结论4:
n
⋅
(
X
ˉ
−
μ
)
S
∼
t
(
n
−
1
)
\dfrac{\sqrt{n}\cdot(\bar{X}-\mu)}{S}\sim t(n-1)
Sn⋅(Xˉ−μ)∼t(n−1)
结论5:
n
⋅
(
X
ˉ
−
μ
)
2
S
2
∼
F
(
1
,
n
−
1
)
\dfrac{n\cdot(\bar{X}-\mu)^2}{S^2}\sim F(1,n-1)
S2n⋅(Xˉ−μ)2∼F(1,n−1)