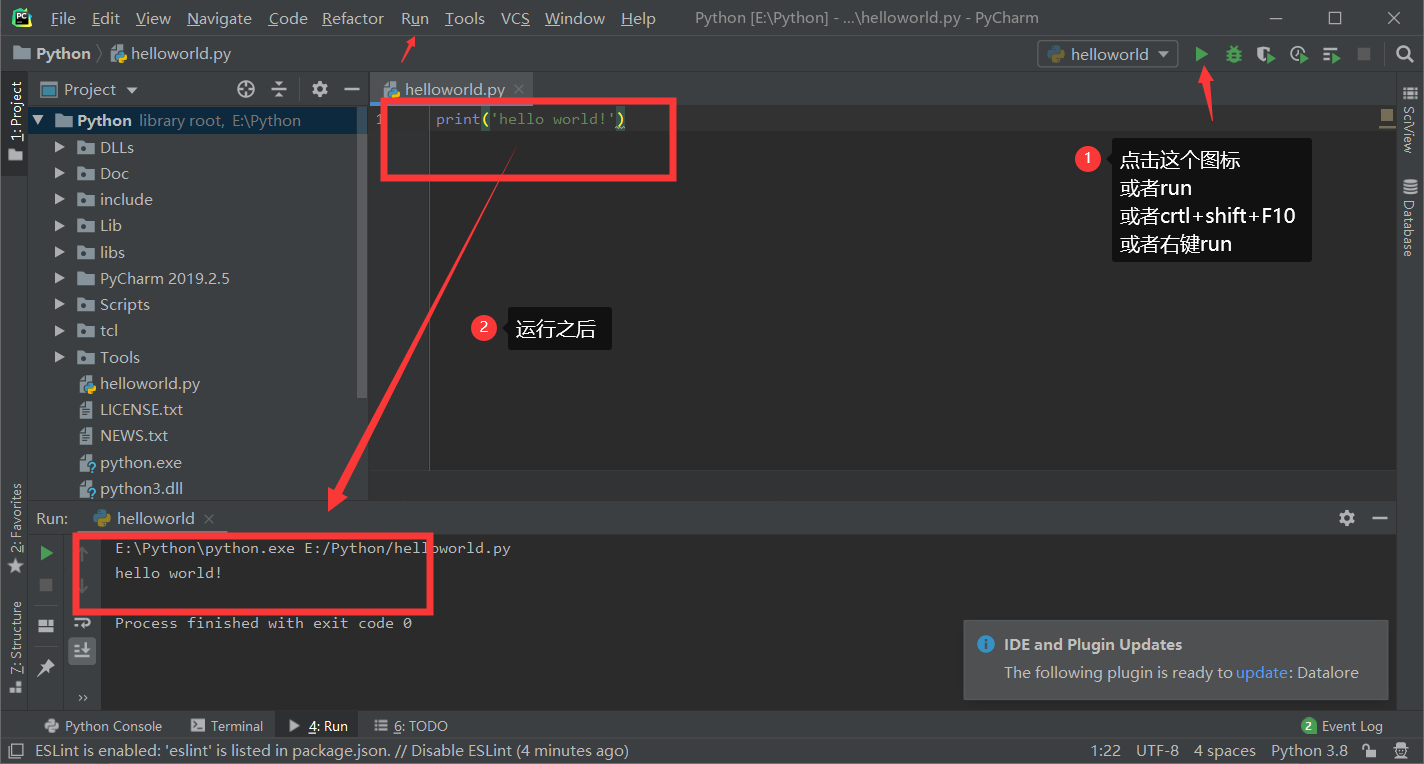
Hadoop介绍
Hadoop是一个开源的分布式系统框架,专为处理和分析大规模数据而设计。它由Apache基金会开发,并通过其高可靠性、高扩展性、高效性和高容错性等特性,在大数据领域发挥着重要作用。以下是对Hadoop的详细解释及其用途的概述:
Hadoop是什么
- 定义:Hadoop是一个开源的分布式计算平台,它通过将数据分布式存储在多台服务器上,并使用MapReduce等算法进行数据处理,从而实现高效的数据存储和处理。
- 核心组件:Hadoop主要由HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)和MapReduce组成。HDFS提供高容错性的分布式存储解决方案,而MapReduce则是一个用于大规模数据处理的并行计算框架。
- 生态系统:Hadoop的生态系统还包括YARN(Yet Another Resource Negotiator,另一种资源协调者)、Zookeeper等组件,以及Hive、HBase、Spark等多个工具,这些工具和组件共同构成了Hadoop强大的数据处理和分析能力。
Hadoop的用途
- 大数据存储:Hadoop通过其分布式文件系统HDFS,能够支持PB级的数据存储,并且提供高吞吐量的数据访问能力,非常适合存储大规模数据集。
- 数据处理与分析:Hadoop的MapReduce框架使得大规模数据处理变得简单高效。用户可以通过编写MapReduce程序来处理和分析存储在HDFS上的数据,从而挖掘出有价值的信息。
日志处理:Hadoop擅长处理和分析日志数据。企业可以利用Hadoop来收集、存储和分析大量的日志文件,以监控系统的运行状态、识别潜在的问题并进行优化。 - ETL(Extract, Transform, Load):Hadoop可以用于数据抽取、转换和加载的过程。企业可以将不同来源的数据抽取到Hadoop中,然后进行清洗、转换和加载到目标数据库或数据仓库中。
- 机器学习:Hadoop的生态系统中的Mahout等工具支持机器学习算法,使得企业可以在Hadoop平台上进行机器学习模型的训练和预测。
- 搜索引擎:Hadoop可以与Lucene等搜索引擎技术结合使用,构建高性能的搜索引擎系统,用于处理大规模的搜索请求和数据。
操作Hadoop
·Hadoop的服务是以集群的方式存在的。整个平台在项目中是由多个服务器共同组网构成,
Hadoop的安装有三种模式
- 单机版(Standalone Mode)
- 特点:
- Hadoop默认的安装模式。
- 所有的服务和数据处理都在同一台机器上进行,不与其他节点交互。
- 不使用Hadoop文件系统(HDFS),直接在本地操作系统的文件系统上读写数据。
- 不加载任何Hadoop的守护进程。
- 主要用于开发和调试MapReduce应用程序。
- 配置:
- 通常不需要修改配置文件,安装后即可使用。
- 主要配置可能涉及设置JAVA_HOME环境变量,以确保Hadoop能够找到Java运行环境。
- 特点:
- 伪分布式(Pseudo-Distributed Mode)
- 特点:
- 在一台机器上模拟分布式环境,所有Hadoop的守护进程(NameNode、DataNode、ResourceManager、NodeManager等)都运行在同一台机器上。
- 具备Hadoop的所有功能,如HDFS、YARN等。适用于学习、开发和小规模实验。
- 配置:
- 需要修改Hadoop的配置文件,如core-site.xml、hdfs-site.xml、mapred-site.xml(或mapred-default.xml的副本)、yarn-site.xml等。
- 配置文件中需要设置HDFS的NameNode和DataNode的地址、端口,以及YARN的ResourceManager和NodeManager的配置。
- 可能还需要配置SSH免密登录,以便Hadoop守护进程之间可以相互通信。
- 特点:
- 完全分布式模式(Fully-Distributed Mode)
- 特点:
- Hadoop集群由多台机器(节点)组成,各节点通过网络互联。
- 每个节点上运行不同的Hadoop守护进程,共同协作完成数据处理任务。
- 适用于生产环境,可以处理大规模数据。
- 配置:
- 配置过程相对复杂,需要设置每个节点的角色(如NameNode、DataNode、ResourceManager、NodeManager等)。
- 需要配置Hadoop的配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml等。
- 配置文件中需要设置HDFS的NameNode和DataNode的地址、端口,以及YARN的ResourceManager和NodeManager的配置。
- 还需要配置slaves文件(或类似的文件),列出所有DataNode和NodeManager节点的地址。
- 配置SSH免密登录,以便各节点之间可以相互通信。
- 在主节点上启动Hadoop集群,然后验证各节点的服务状态。
- 特点:
Hadoop的文件夹结构和文件功能
- sbin:存放所有的Hadoop管理相关脚本文件的文件夹
- start -all.sh:开启所有服务
- start-dfs,sh:开启文件管理服务
- start-yarn.sh:开启资源管理服务
- etc/hadoop:存放所有配置文件的文件夹
- core-site.xml:核心站点的配置
- hdfs-site.xml:文件系统的配置
- yarn-site.xml:资源管理系统的配置
- mapred-site.xml:计算引擎的配置
伪分布式安装Hadoop的示例:
- 修改文件系统,让系统不仅可以本地访问,也可以用于局域网的访问:
- 修改core-site.xml文件的地址配置信息
将localhost本地的地址先改成局域网的ip地址:vim /home/hadoop-3.2.1/etc/hadoop/core-site.xml

- 重新格式化文件系统的内容
hdfs namenode -format- 现在我们需要去同步hdfs文件系统中数据的版本
可以通过 /home/hadoop-3.2.1/etc/hadoop/hdfs-site.xml 文件,查看namenode和datanode两个服务的地址:

- 先查看 namenode 服务中的版本号:
cat /home/root/tmp/data/hadoop/dfs/name/current/VERSION```

- 修改 datanode 服务中的版本号:
vim /home/root/tmp/data/hadoop/dfs/data/current/VERSION
发现这里的clusterID和上面的不一样,修改成和上面的id相同的值即可。

- 启动完整的hadoop的服务,查看启动是否正常
/home/hadoop-3.2.1/sbin/start-all.sh
使用 jps 命令来查看启动的信息:显示的是hadoop服务的进程编号和名字

hadoop的基础服务
在hadoop的平台中,有三大基础服务:
– HDFS:hadoop里面的分布式文件管理系统
– YARN:资源管理系统
– MAPREDUCE:计算引擎
HDFS
–通过浏览器来查看hdfs的界面和内容:192.168.222.132:50070。
–在hdfs中创建的内容,在Linux中是看不见的,他们是两套不同的系统。
HDFS命令
| 命令 | 说明 |
|---|---|
| 创建文件夹 | hadoop fs -mkdir -p 文件夹位置和名字 |
| 给文件夹赋予权限 | hadoop fs -chmod -R 要给的权限 文件或者文件夹的名字和位置 |
| 创建文件 | hadoop fs -touch(z) 文件位置和名字 |
| 删除文件或文件夹 | hadoop fs -rm -r 文件路径(不需要f,hdfs默认强制删除) |
| 将Linux系统中的文件上传到hdfs系统中 | hadoop fs -put linux的文件路径 hdfs的目标路径 |
| 将hdfs的文件下载到Linux中 | hadoop fs -get hdfs中文件路径 Linux目标路径 |
| 将Linux本地文件的内容,上传合并到hdfs已存在文件 | hadoop fs -appendToFile linux的文件位置 hdfs文件位置 |
| 查看hdfs文件的内容 | hadoop fs -cate hdfs文件路径 |
| 查看文件大小 | hadoop fs -du -s -h hdfs文件或文件夹路径 |
HDFS的三个服务
NameNode
名称节点,直接和客户端进行数据交互,验证数据交互的过程;保存所有数据的元数据信息。
什么是元数据:
对于数据内容的解释以及结构的定义。如果数据是一个表格,那么元数据就是表格的名字、位置、字段名、字段的数据类型等信息。
DataNode
数据节点,进行数据的保存和写入
SecondaryNameNode
辅助名称节点,扫描整个服务器节点的信息,将数据的信息内容复制到NameNode保存起来。
面试常问
hdfs写入数据的流程

rack:架子
- 客户端向NameNode发送写入数据的申请
- NameNode校验数据是否符合规则(是否重名,路径是否存在)
- NameNode同意申请
- 客户端向NameNode发送获得能够写入数据的DataNode节点的列表信息的请求
- NameNode发送DataNode节点列表
- 客户端根据Linux的管道技术,找到离自己最近的rack上的DataNode然后发送写入数据的申请
- DataNode发送同意的回应
- 客户端发送数据(DataNode收到数据同时复制两份分别发送到同一rack和不同rack的DataNode中进行备份)
- DataNode回复写入完成
HDFS读取数据的流程

- 客户端发送带有文件路径path的访问请求
- NameNode返回有这个文件的DataNode节点信息列表
- 客户端申请读取数据
- 返回同意读取
- 客户端申请要读取的数据的数据块信息
- DataNode返回相应数据
注:
HDFS的写入过程中,数据是默认保存3份的,这个存储的备份数量是可以自己定义的:
/home/hadoop-3.2.1/etc/hadoop/hdfs-site.xml

BLOCK SIZE:hdfs的数据块的大小,128M。定义的我们数据文件每次传输的最大值。
如果有一个文件是300M,这个文件会拆分成3个block,分别是128 128 44 M三个块,每次传输只写入其中一个block。
MAPREDUCE
MapReduce是hadoop平台的默认的计算引擎,除了mr还有spark、tez、flink … 等不同的计算引擎。
计算引擎在我们的工作过程中,是通过sql语句等完成自动的调用的。
| 步骤 | 说明 |
|---|---|
| input | 读取器数据 |
| split | 拆分数据 |
| map | 映射数据 |
| shuffle | 计算数据 |
| reduce | 汇总数据 |
| finalized | 展示数据 |

YARN
yarn是Hadoop平台的资源管理系统,由两个基础服务组成:
- ResourceManager:
资源管理器,负责资源的申请和管理 - NodeManager:
节点管理器,负责资源的下放和回收

HIVE数据库的操作
hive只是一个写sql的窗口而已,元数据的存储是通过 derby 或者 mysql 进行存储的,表格的数据存储在hdfs中,数据的计算是用mapreduce来实现的。
hive的操作有三个基本的窗口:
- webUI:通过浏览器的组件去操作hive数据库,例如hue
- jdbc:通过各种客户端的软件来操作的,例如dbeaver
- CLI:命令行的操作方法,例如直接通过xshell的命令窗口来操作数据库
库的操作
在Hive中,有一个默认的数据库,叫做default。我们也可以自己去创建和删除数据库。
default库的位置是 /user/hive/warehouse 整个文件夹。
创建一个数据库
语法:create database dbName;
**注:**数据库在hdfs中以文件夹的方式存在。位置在 /user/hive/warehouse
查看有哪些数据库
show databases;
删除数据库
drop database dbName;
drop database abName cascade;
如果你的数据库已经创建了表格,不是空库了,就只能通过cascade选项强制删除
使用和切换数据库
use dbName;
显示数据库名字(可选)
set hive.cli.print.current.db=true;
这个参数的默认值是false,我们给它修改成true即可。
如果想要参数永久的有效,需要去修改hive数据库的配置文件:
vim /home/apache-hive-3.1.2-bin/conf/hive-site.xml
表格的操作
创建表格的基础语法:
create table 表名(
列名 数据类型
);
数据类型
- 简单类型
- 数字类型:整数 int bigint;小数 float,double(默认形式),decimal(总长度,精度)
- 字符串类型:定长字符串 char;不定长字符串 varcahr;无限制字符串 string
- 日历类型:年月日时分秒毫秒 date。注:在hive中一般不用date定义时间,通常用string保存,方便不同数据库交换数据
- 复杂类型
- 数组array
一个数组里只能存放相同类型的数据。array<数据类型> - 映射类型:map
存放键值对类型的数据,所有的key和所有的value类型必须是同种类型。map<key类型,value类型>
- 数组array
向表格中插入数据
- 只有简单数据
insert into tabname(cloumnname) values(value);
- 有复杂类型的插入
insert into 表名(列名) select 查询语句
insert into users select 1002,'bb','18898765432',
array('吃饭','睡觉','玩游戏'),
map('语文',88,'数学',72);
如果操作的数据整体的数据量是小于128M,那么可以使用Hive的本地模式去运行:(速度会快点)
set hive.exec.mode.local.auto=true;
表格的分隔符信息
默认的分隔符有三种,分别是:
字段的分隔符:^A,在数据库里面的编码内容是 \001,使用ctrl+v+a才能打印这个符号
元素之间的分隔符:^B,在数据库里面的编码内容是 \002,使用ctrl+v+b才能打印这个符号
键值对之间的分隔符:^C,在数据库里面的编码内容是 \003,使用ctrl+v+c才能打印这个符号
自己在创建表格的时候定义分隔符的信息:
create table 表名(
列名 数据类型
) row format delimited fields terminated by '字段分隔符'
collection items terminated by '元素分隔符'
map keys terminated by '键值对分隔符';
通过sql语句导入linux的文件内容到Hive数据库表格中:
load data local inpath 'linux文件的位置和名字' into table 表名;
通过load data去添加数据才是hive数仓的常见的方式,用 insert into 操作比较少用到。
外部表
通过create table创建的表格都叫做内部表,通过create external
table 创建的表格叫做外部表。
create external table 表名(
列名 数据类型
);
特点:
- 外部表是不能通过 truncate table 进行表格数据清空的
- 外部表如果使用 drop table 进行删除,只会删除在元数据库中的表格结构定义,不会删除在 hdfs 中的表格文件夹以及表格的数据
- 在数据的分层结构中,ODS层的表格,在hive数仓中,都会用外部表进行创建
保留的文件夹,可以通过建表来恢复表格:
create table test1(
userid int,
name string,
age int
)
location '/user/hive/warehouse/bigdata.db/ext_users';
create external table test2(
userid int,
name string,
age int
)
location '/user/hive/warehouse/bigdata.db/ext_users';
通过 location 指向文件夹的表格,是不会在hdfs中创建自己的表格文件夹的。
内部表和外部表是可以相互转换的:
内 --> 外:
alter table 内部表名字 set tblproperties ('EXTERNAL'='TRUE');
外 --> 内:
alter table 外部表名字 set tblproperties ('EXTERNAL'='FALSE');
分区表
创建一个分区表
create table 表名(
column_1 type,
column_2 type,
...
) partitioned by (column _3 type)
row format delimited fields terminated by ',';--用逗号作为字段之间的分隔符
添加数据
- load data
loda data local inpath '数据文件的路径' into table 表名 partition(column=value)
-
insert overwrite table / insert into table;overwrite:覆盖写入
-
查看表格有哪些分区:
show partitions 表名;
- 删除某个分区:
alter table 分区表名字 drop partition (column=value)
- 练习:使用insert语句进行分区表格的数据导入操作
有一个表格是一个普通的表格,这个表格的数据量现在已经非常大了,操作不方便,需要将这个表格创建成一个分区表进行数据的存储。
模拟创建一个普通的表格,然后再创建一个相同结构的分区表格,最后进行数据的导入。
create table emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal float,
comm float,
deptno int
)row format delimited fields terminated by ',';
--从Linux系统导入文件
load data inpath '/usr/my_docu/emp.txt' into table emp;
--创建一个分区表
create table emp_par(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal float,
comm float
)partitioned by (deptno int)
row format delimited fields terminated by ',';
从普通表emp中导入数据到分区表emp_par:
insert overwrite|into table 表名字 partition (分区字段=分区值) select 查询语句;
动态导入分区的方法
上文手动去指定分区的方式,叫做静态分区,也可以通过动态分区导入数据:
- 打开hive中和动态分区相关的参数
- 动态分区的支持参数:set hive.exec.dynamic.partition=true;
- 动态分区中有一个非严格模式需要设置:set hive.exec.dynamic.partition.mode=nonstrict;
- 编写sql语句,进行数据的导入和添加,在sql中,分区的值是不需要自己去指定的,他是根据sql语句来自动判断的。
insert overwrite |into table 表名 partition (分区字段) select 查询语句;
静态分区和动态分区的区别
- 静态分区有load data和insert两种导数据的方法,动态分区只能insert导数据。
- 动态分区需要打开动态参数以及非严格模式的参数
- 静态分区在导入数据时,分区字段的值由用户手动设置,动态分区在导入时自动识别分区字段。
- 在使用insert导入数据的时候,静态分去不需要将分区字段写在select中,动态分区需要将分区值写在select后面
外部的分区表:
创建一个外表,读取某个hdfs文件夹已经存在的分区信息:

在hdfs中上传了这个logs的文件夹目录结构:
hadoop fs -put /root/logs /tmp
创建一个外部表,通过location关键字读取这个Logs文件夹里面的数据:
-- 创建一个外部的分区表
create external table ext_test(
id int,
name string,
price int
) partitioned by (dt string)
row format delimited fields terminated by ','
location '/tmp/logs';
-- 现在这个表里面通过 show partitions 语句是看不到分区结构的,分区需要我们自己去添加,这个时候我们需要将分区的值和对应的分区所在的文件夹通过alter语句进行一个绑定
alter table ext_test add partition (dt=20240901) location '/tmp/logs/20240901';
alter table ext_test add partition (dt=20240902) location '/tmp/logs/20240902';
alter table ext_test add partition (dt=20240903) location '/tmp/logs/20240903';
分桶表
分区表
- 是为了加快表格筛选的速度,在针对分区字段进行数据读取的时候,速度会更快,效率更高,只需要读取分区文件夹的内容即可。优化的是where阶段的内容;
- 分区表是以文件夹的操作去进行表格数据拆分的;
- 分区表是用新的字段进行数据分区;
- 分区表是自己指定分区的规则。
分桶表
- 为了加快表格在group by和join操作的时候,select语句操作的效率;
- 分桶表是直接拆分成多个文件;
- 分桶表是用表格中的已有字段进行分桶的;
- 分桶表是根据哈希算法来自动分配的(将任何的内容转换成数字,用数字除以划分的数字,根据除以之后的余数进行数据的存储)。
创建一个分桶表
语法:
create table 表名(
列名 字段类型,
...
) clustered by (表格中已有字段) into 分桶数 buckets;
--示例
create table emp_c(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal float,
comm float,
deptno int
) clustered by (deptno) into 3 buckets;
row format delimited fields terminated by ',';
根据什么来决定最终表格划分多少桶是最合适的?
被导入的数据量的大小/(blocksize*2) = 分桶的数量
假如文件是1G的大小,那么就是1024/256=4。(让数据均匀分散在各个桶中)
- 使用Load data来导入数据文件到分桶表格。
分桶表格的数据导入,不能运行在本地模式上,开了不影响它运行。
load data local inpath '/root/emp.txt' into table emp_c;
- 通过insert 语句插入数据到分桶表格
insert overwrite table emp_c
select * from emp;
hive中的四个不同的by操作
- order by:对整个表格进行排序。不管你的表格有多大,最终都是用一个reduce的进程来完成整个表格的排序操作的。多用于当表格的数据量不大的时候,或者是表格的排序字段相对来说比较有规律的时候。
- sort by:当使用的reduce进程是一个的时候,和 order by 是没有任何区别的,如果我们设置了reduce的数量,那么表格就会在多个reduce进程中分别的并行的进行排序。
set mapred.reduce.tasks; #检查reduce数量,默认是-1表示没有去设置reduce
我们可以修改这个reduce的数量。
例如
set mapred.reduce.tasks=2;
select * from emp sort by sal desc;
如果只想在不同的分桶中进行数据的排序的,不针对整个表格,直接按照上面的sort by的操作,是看不出来按照什么规则和字段进行分桶排序的,所以sort by语句,一般会和 distribute by 结合使用。
- distribute by:按照什么字段对表格进行分桶的数据的拆分。这个关键字是不能单独使用的,必须和 sort by 结合使用。
select * from emp distribute by empno sort by sal desc;
- cluster by:相当于 distribute by A字段 sort by A字段 asc
select * from emp distribute by sal sort by sal asc;
等效于
select * from emp cluster by sal;
表格的存储类型和数据的压缩格式
- textfile文本格式:hive创建表格的默认格式
create table test1(
id int,
name string
);
#或者
create table test1(
id int,
name string
) stored as textfile;
emp默认的textfile表格,大小是8.5M
创建一个表格,里面存储emp表格的数据,表格结构和emp表是一样的,只是数据是压缩的数据:
create table emp_ys(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal float,
comm float,
deptno int
) row format delimited fields terminated by ',';
打开数据在写入的时候,同时压缩数据的开关和参数:
set hive.exec.compress.output=true;
set mapred.output.compress=true;
将emp表格的数据,insert overwrite 到emp_ys的表格中:
insert overwrite table emp_ys
select * from emp;
同样数据的表格,压缩之后是 45.3 K,默认的压缩格式是 .deflate,除了这个默认的格式,通用的还有一种格式叫做 .gzip
gzip emp_more2.txt 就会得到一个 emp_more2.txt.gz 的压缩文件
导入这个文件到emp_ys表格中。
load data local inpath '/root/emp_more2.txt.gz' into table emp_ys;
用gzip压缩之后是 42.8 K
- parquet拼接文件
创建一个parquet类型的表格
create table emp_parquet(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal float,
comm float,
deptno int
) row format delimited fields terminated by ','
stored as parquet;
insert overwrite table emp_parquet
select * from emp;
这个表格默认大小是 546.7 K
1 aa 18
2 bb 17
3 cc 19
1 aa 18
1 aa 18
在拼接文件里面会用两个文件来存储表格的数据:
1 aa 18
2 bb 17
3.cc 19
1 1,4,5
2 2
3 3
它会把所有重复记录的行号放在一起。
创建一个有压缩格式的parquet的表格:
==parquet表格的压缩格式叫做 SNAPPY ==
create table emp_parquet_ys(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal float,
comm float,
deptno int
) row format delimited fields terminated by ','
stored as parquet
tblproperties('parquet.compression'='SNAPPY');
insert into emp_parquet_ys
select * from emp;
压缩之后数据是 28.3 K
parquet格式适用于有大量重复数据的表格
- sequencefile 序列文件
内部数据以键值对的方式存储:{“id”:1,“name”:lilei,“age”:18}
对字段进行筛选和读取的时候,效率要比textfile文本格式高一些,但是会占用更多的存储空间。
create table emp_seq(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal float,
comm float,
deptno int
) row format delimited fields terminated by ','
stored as sequencefile;
insert overwrite table emp_seq select * from emp;
--存储空间占用是 12.1 M
序列文件的压缩格式 叫做 BLOCK,默认使用的是RECODE格式,是不压缩的。
想要使用压缩格式,先要打开hive的压缩开关
set hive.exec.compress.output=true;
再设置sequencefile表格的格式
set mapred.output.compression.type=BLOCK;
使用压缩格式后,文件大小为:51.8K
- orc列存格式
orc是项目中用的最多的一种数据存储的格式。orc是列存数据的格式,上面三种都是行存数据。orc是唯一一个默认压缩的数据表格,orc是以行单位进行压缩和解压的。适合中大型表格的存储。
create table emp_orc(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal float,
comm float,
deptno int
) stored as orc;
insert overwrite table emp_orc
select * from emp;
默认的压缩格式叫做 zlib
-- 16.7 K
textfile:deflate gzip
parquet:SNAPPY
sequencefile:BLOCK
orc:zlib
表格数据的更新于删除
在默认的textfile表格中,行数据是不支持update语句和delete语句的。只能通过其他方式实现update和delete类似的效果:
不好使,别这样用
示例:
1.更新SMITH的工资为900
insert overwrite table emp
select empno,ename,job,mgr,hiredate,900,comm,deptno from emp where ename='SMITH'
union all
select * from emp where ename !='SMITH';
2.假入要删除SMITH的数据
insert overwrite table emp
select * from emp where ename!='SMITH';
当表格的数据量很大的时候,上面的方法消耗的系统资源是很多的,操作的效率也很慢,所以很大的表格使用Orc进行存储,并且在orc里面会开启一个事务的属性,orc就可以支持update和delete的语句。
在hive中默认是不支持事务属性创建的,需要先提前打开hive的参数
set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
set hive.support.concurrency=true;
create table emp_orc02(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal float,
comm float,
deptno int
) stored as orc
tblproperties('transactional'='true');开启事务属性
insert overwrite table emp_orc02 select * from emp;
-- 在开启了事务的表格中,orc表可以支持update和delete语句
update emp_orc02 set sal=888 where ename='SMITH';
delete from emp_orc02 where ename='ALLEN';
临时表
create temporary table 临时表名字(
列名 数据类型
);
create temporary table tmp_user(
id int,
name string,
age int
);
临时表是用来保存数据计算过程中的中间数据的,可以将某个比较复杂的sql拆分,将中间的计算过程保存在临时表中,可以用来简化某个sql的逻辑。
临时表数据是保存在内存中的,重新打开窗口,表格数据就会被清空了。
视图
视图是一个虚拟的表格,不占用磁盘空间的,视图是一个select语句查询的结果集,每次查询视图,都是对这个select语句进行查询。视图只是将一个select语句当成一个别名来进行查询和使用。(有点像Oracle中的with as 子句)
create view 视图名字
as
select 语句;
create view dept_sal
as
select deptno,avg(sal) s from emp group by deptno;
表格的复制
-
完整的复制一个一模一样的表格:create table 新的表名 like 已有的表名;这种复制的方式,只会复制表格的结构,不会复制表格的数据。
-
复制一个select查询结果集的内容:create table 新的表名 as select 查询;
完整的建表语句
create [external] [temporary] table 表名(
列名 数据类型
) [partitioned by (分区字段 分区类型)]
[clustered by (分桶字段) into xx buckets]
[row format delimited fields terminated by ''--字段间分隔符
collection items terminated by '' --复杂数据间分隔符
map keys terminated by ''] --键值对间分隔符
[tblproperties (属性名=属性值)]
[stored as 存储类型]
[location 'hdfs文件夹存储位置'];