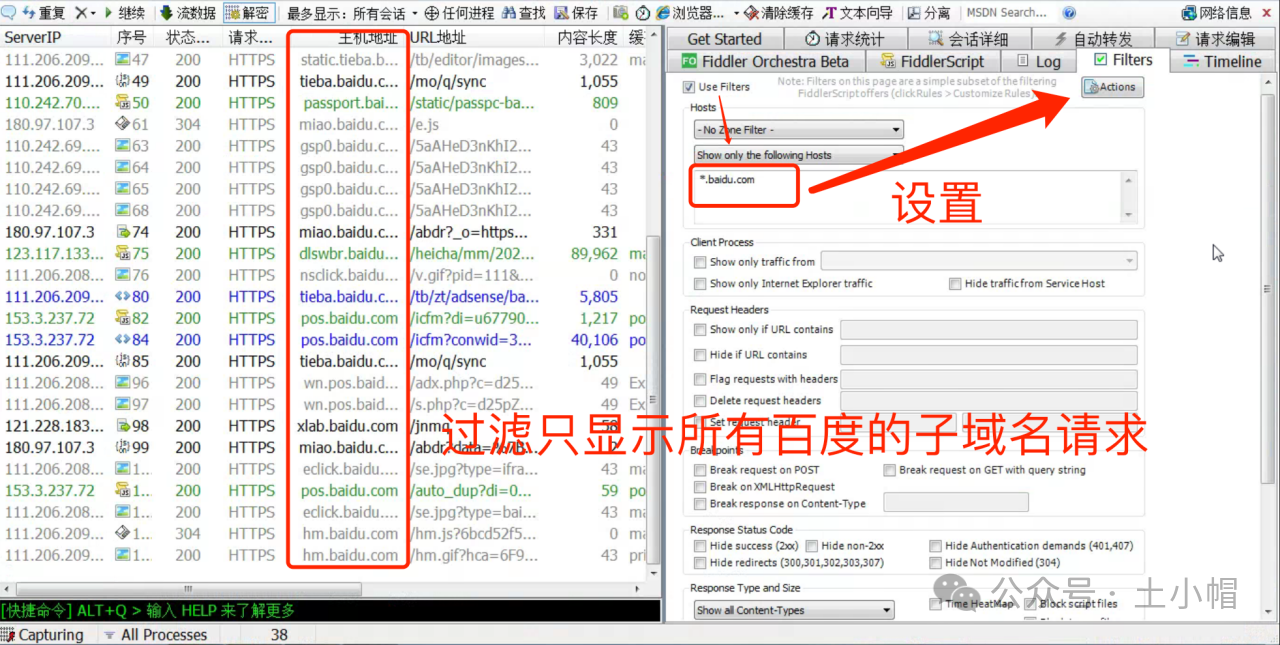
学习链接:https://www.bilibili.com/video/BV1gm411S7EX/?spm_id_from=333.337.search-card.all.click&vd_source=efbaa07876b231ae3225ba8999116807
- 创建线程的几种方式?
- 继承Thread类
- 实现Runnable接口
- 实现Callable接口
- 通过线程池来创建线程
- 为什么不建议使用Executors创建线程池?
以创建FixedThreadPool为例,其构造方法为:
public static ExecutorService newFixedThreadPool (int nThread) {
return new ThreadPoolExecutor (nThread, nThread, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
发现创建的队列为LinkedBlockingQueue,是一个无界阻塞队列(最大是21亿个任务),如果使用该线程池执行任务,如果任务过多就会不断的添加到队列中,任务越多占用的内存就越多,最终可能耗尽内存,导致OOM。
// 短信关于创建线程池的实践,线程池的大小要结合具体的场景来确定。
private static final ExecutorService executor;
static {
Integer corePoolSize = DeviceConfig.getInstance().getInteger("route.exec.corePoolSize", 16);
Integer maximumPoolSize = DeviceConfig.getInstance().getInteger("route.exec.maximumPoolSize", 16);
Integer queueCapacity = DeviceConfig.getInstance().getInteger("route.exec.queueCapacity", 1000);
executor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, 0L,
TimeUnit.SECONDS, new LinkedBlockingQueue<>(queueCapacity),
Executors.defaultThreadFactory(), new CallerRunsPolicyWithCounter());
}
// 拒绝策略,计数
public class CallerRunsPolicyWithCounter implements RejectedExecutionHandler {
private AtomicLong count = new AtomicLong(0L);
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
if (!executor.isShutdown()) {
count.incrementAndGet();
r.run();
}
}
public long report() {
return count.getAndSet(0L);
}
}
- 线程池有几种状态,分别表示什么?
- Running(运行状态):线程池新建或者调用execute()方法后,处于运行状态,能够接收新的任务
- ShutDown(关闭状态):调用shutdown()方法后,此时线程池不再接收新的任务,但会执行已提交的等待队列中的任务.
- Stop(停止状态):调用shutdownNow()方法时,线程的状态会变为Stop。此时线程池不再接收新的任务,并且会中断正在处理中的任务
- Tidying(整理状态):中间状态不做任何处理
- Terminated(终止状态):线程池内部的所有线程都已经终止时,线程池进入Terminated状态

- Synchronized和ReentrantLock有哪些不同点?
- Sync的底层锁升级策略?
- Lock的中断方式?


- ThreadLocal 有哪些应用场景?它底层是如何实现的?
线程隔离
结构如下,每个线程都会关联一个ThreadLocalMap



- ReentrantLock分为公平锁和非公平锁,那底层分别是如何实现的?
首先不管是公平锁和非公平锁,他们的底层实现都是使用AQS来进行排队,他们的区别在于线程在使用lock()方法加锁时:
- 如果是公平锁,会先检查AQS队列中是否存在线程在排队,如果有线程在排队,则当前线程也进行排队;
- 如果是非公平锁,则不会去检查是否有线程在排队,而是直接去竞争锁。
另外,不管是公平锁还是非公平锁,一旦没竞争到锁,都会进行排队,当锁释放时,都是唤醒排在最前面的线程,所以非公平锁只是体现在了线程加锁阶段,而没有体现在线程被唤醒的阶段。
ReentrantLock是可重入锁,不管是公平锁,还是非公平锁都是可重入。
- Synchronized 的锁升级过程是什么样的?

- tomcat 为什么要自定义类加载器?
避免因为类名一样而产生冲突。

- 微服务有什么好处?
单体项目的缺点:
- 可扩展性受限
- 难以维护和更新
- 高风险
- 技术栈限制
- 团队协助复杂
微服务项目的缺点:
- 成本挑战
i. 基础设施成本增加
ii. 开发和维护成本- 复杂性挑战
i. 分布式系统复杂性
ii. 服务发现与治理- 部署挑战
i. 自动化部署需求
ii. 版本控制和回滚- 一致性挑战
i. 数据一致性
ii. 事务管理- 监控与故障排查挑战
i. 性能挑战
ii. 故障排查
- 现在有哪些微服务解决方案?
- Dubbo + ZK
- SpringCloud


- Eureka 实现原理了解吗?
Eureka的实现原理,可以分为以下几个方面:
- 服务注册与发现:当一个服务实例启动时,会向Eureka Server发送注册请求,将自己注册到注册中心。Eureka Server会将这些信息保存在内存中,并提供REST接口供其他服务查询。服务消费者可以通过查询服务实例列表来获取可用的服务提供实例,从而实现服务的发现。
- 服务健康检查:Eureka通过心跳机制来检测服务实例的健康状态。服务实例会定期向Eureka Server发送心跳,也就是续约,以表明自己的存活状态.如果Eureka Server在一定时间内没有收到某个服务实例的心跳,则会将其标记为不可用,并从服务列表中移除,下线实例。
- 服务负载均衡:Eureka客户端在调用其他服务时,会从本地缓存中获取服务的注册信息.如果缓存中没有对应的信息,则会向Eureka Server发送查询请求.Eureka Server会返回一个可用的服务实例列表给客户端,客户端可以使用负载均衡算法选择其中一个去调用。
- Eureka Server是怎么保证高可用的?
- 多实例部署:通过将多个Eureka Server实例部署在不同的节点上,可以实现高可用性。当其中一个实例发生故障时,其他实例仍然可以提供服务,并保持注册信息的一致性。
- 服务注册信息的复制:当一个服务实例向Eureka Server注册时,每个Eureka Server实例都会复制其他实例的注册信息,以保持数据的一致性。当某个Eureka Server实例发生故障时,其他实例可以接管其工作,保证整个系统的正常运行.
- 自我保护机制:Eureka具有自我保护机制.当Eureka Server节点在一定时间内没有收到心跳时,会进入自我保护模式。在自我保护模式下,Eureka Server 不再剔除注册表中的服务实例,以保护现有的注册信息。这样可以防止由于网络抖动活其他原因导致的误剔除,进一步提高系统的稳定性。

- 什么是CAP?为什么三者不能同时拥有?
分布式项目的3个特性:一致性(Consistency),可用性(Availability)、分区容错(Partition-tolerance)
- 分区容错性:分布式系统在遇到某节点或者网络分区故障时,仍然能够对外提供服务。
- 一致性:所有节点在同一时间的数据完全一致。
- 可用性:服务一直可用,而且是正常响应时间。允许读到的是旧的数据。

- Base理论了解吗?
- Basically Available : 基本可用:
- Soft state:软状态,即允许多个节点存在数据延迟
- Eventually consistent:最终一致性

- 什么是分布式事务?
ACID
- Atomicity: 原子性 一个事务的所有操作,必须全部完成,或者全部不完成。
- Consistency: 一致性 在事务开始或结束时,数据库应该在一致状态。
- Isolation:隔离性 事务与事务之间不会互相影响
- Durability: 持久性 事务一旦完成,就不能返回,变更完全保存到数据库中

- 分布式事务有哪些常见的实现方案?
- 2PC:2阶段 准备-完成 准备-回滚
- 3PC:canCommit + 2阶段
- TCC:Try-Confirm-Cancel 类似2PC,阻塞粒度小 偏重于代码上解决
- SAGA: 流水线事务 == 长事务
- 消息队列实现数据最终一致性
-
有哪些分布式锁的实现方案?
-
xxxx