在 LeNet 提出后,卷积神经网络在计算机视觉和机器学习领域中很有名气,但并未起到主导作用。
这是因为 LeNet 在更大、更真实的数据集上训练的性能和可行性还有待研究。
事实上,在 20 世纪 90 年代到 2012 年之间的大部分时间里,神经网络往往被其他机器学习方法超越,如支持向量机。
在计算机视觉中,直接将神经网络与其他机器学习方法比较也许不太公平,因为卷积神经网络的输入是由原始像素值或是经过简单预处理的像素值组成。
而在使用传统机器学习方法时,从业者永远不会将原始像素作为输入。
在传统机器学习方法中,计算机视觉流水线是由经过人的精心设计的特征流水线组成的。
与训练端到端(从像素到分类结果)系统相比,经典机器学习的流水线看起来更像下面这样:
- 获取一个有趣的数据集(早期收集数据需要昂贵的传感器)。
- 根据光学、几何学及其他偶然发现,手工对特征数据集进行预处理。
- 通过标准的特征提取算法,如 SIFT(尺度不变特征变换)和 SURF(加速鲁棒特征)。
- 将提取的特征送入分类器中,以训练分类器。
对于机器学习研究人员来说,用优雅的理论去证明各种模型的性质是重要且美丽的;而对计算机视觉研究人员来说,推动领域进步的是数据特征,而不是学习算法。
计算机视觉研究人员相信,从对最终模型精度的影响来说,更大或更干净的数据集、或是稍微改进的特征提取,比任何学习算法带来的进步大得多。
一、学习表征
在 2012 年以前,图像特征都是机械地计算出来的。在当时,设计一套新的特征函数、改进结果,并撰写论文是主流。
另有一些研究人员有不同的想法,他们认为特征本身就应该被学习。
此外,他们还认为,在合理的复杂性前提下,特征应该由多个共同学习的神经网络层组成,每个层都有可学习的参数。
在机器视觉中,最底层可能检测边缘、颜色和纹理。由 Alex 等人(2012)提出的新的卷积神经网络变体 AlexNet 的最底层就学习到了一些类似于传统滤波器的特征抽取器。
AlexNet 的更高层建立在这些底层表示的基础上,表示出更大的特征,如眼睛、鼻子等等。
而更高的层可以检测整个物体,如人、飞机等等。最终的隐藏神经元可以学习图像的综合表示,从而使得属于不同类别的数据易于区分。
尽管一直有一群执着的研究者不断钻研,试图学习视觉数据的逐级表征,但很长一段时间都未能有所突破。
深度卷积神经网络的突破出现在 2012 年,可归因于两个因素:数据和硬件。
数据
包含许多特征的深度模型需要大量的有标签数据,才能显著优于基于凸优化的传统方法。
然而,限于早期计算机有限的存储和 90 年代有限的研究预算,大部分研究只基于小的公开数据集。
这一状况在 2010 年前后兴起的大数据浪潮中得到改善。2009 年,ImageNet 数据集发布,并发起 ImageNet 挑战赛,其推动了计算机视觉和机器学习研究的发展。
硬件
深度学习对计算资源的要求很高,训练可能需要数百个迭代轮数,每次迭代都需要通过代价高昂的许多线性代数层传递数据。
然而,用 GPU 训练神经网络改变了这一格局。图形处理器(Graphics Processing Unit, GPU)早年用来加速图形处理,使电脑游戏玩家受益。
GPU 可优化高吞吐量的 4$\times$4 矩阵和向量乘法,从而服务于基本的图形任务。幸运的是,这些数学运算与卷积层的计算惊人地相似。
相比于 CPU,GPU 的综合性能更强,内核也要简单得多,因此 GPU 更加节能。此外,深度学习的许多操作需要较高的内存带宽,而 GPU 拥有 10 倍于 CPU 的带宽。
回到 2012 年的重大突破,Alex 等人意识到卷积神经网络中的计算瓶颈:卷积和矩阵乘法,都是可以在硬件上并行化的操作。于是,他们使用 GPU 加快了卷积运算,推动了深度学习热潮。
二、AlexNet
2012 年,AlexNet 横空出世。它首次证明了学习到的特征可以超越手工设计的特征,一举打破了计算机视觉研究的现状。
AlexNet 使用了 8 层卷积神经网络,其架构和 LeNet 非常相似,如下图所示。
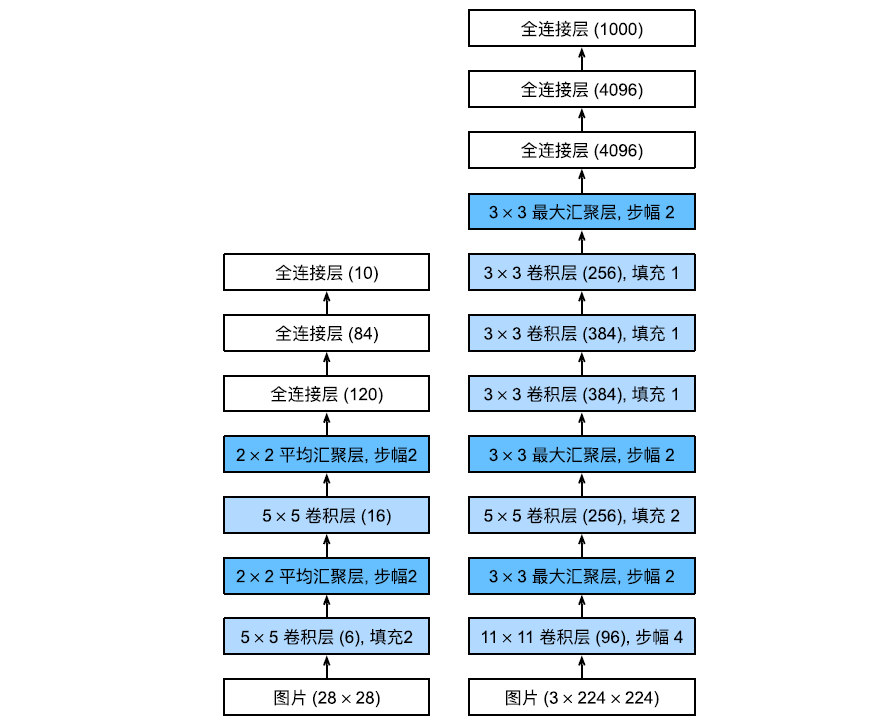
尽管它们的设计理念非常相似,但也存在显著差异:
- AlexNet 相较于 LeNet-5 要深得多,其由 8 层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。
- AlexNet 使用 ReLU 而不是 sigmoid 作为激活函数。
模型设计
在 AlexNet 的第一层,卷积窗口的形状是 11$\times$11,比 LeNet 中大得多。
这是因为 ImageNet 中使用的图像要比 MNIST 大得多,因此需要一个更大的卷积窗口来捕获目标。
第二层中的卷积窗口缩减为 5$\times 5 ,然后是 3 5,然后是 3 5,然后是3\times 3 ,在第一层、第二层和第五层卷积层后,加入窗口形状为 3 3,在第一层、第二层和第五层卷积层后,加入窗口形状为 3 3,在第一层、第二层和第五层卷积层后,加入窗口形状为3\times$3、步幅为 2 的最大汇聚层。而且,AlexNet 的通道数是 LeNet 的 10 倍。
AlexNet 将 sigmoid 激活函数改为更简单的 ReLU 激活函数。一方面,ReLU 激活函数的计算更为简单;另一方面,当使用不同的参数初始化方法时,ReLU 激活函数使训练模型更加容易。
容量控制和预处理
AlexNet 通过暂退法(Dropout)控制全连接层的模型复杂度,而 LeNet 只使用了权重衰减。
为了进一步扩充数据,AlexNet 在训练时增加了大量的图像增强数据,如翻转、裁切和变色。这使得模型更加健壮,更大的样本量有效地减少了过拟合。
net = nn.Sequential( # 定义模型
# 这里使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使用三个连续的卷积层和较小的卷积窗口。
# 除了最后的卷积层,输出通道的数量进一步增加。
# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合,暂退概率0.5
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10))
数据集准备
即使在现代 GPU 上,使用 ImageNet 数据集训练也需要数小时或数天的时间,因此我们继续使用 Fashion-MNIST 数据集来实现 AlexNet 模型。
但由于 Fashion-MNIST 数据集中的图像(28$\times 28 )远低于 I m a g e N e t 图像,为了有效使用 A l e x N e t 架构,我们把图像 r e s i z e 变换为 224 28)远低于 ImageNet 图像,为了有效使用 AlexNet 架构,我们把图像 resize 变换为 224 28)远低于ImageNet图像,为了有效使用AlexNet架构,我们把图像resize变换为224\times$224。
模型训练
定义好模型以及变换数据集后,训练的代码和前面 LeNet 几乎一样,不过这里采用的是小学习率(0.01)和小batch_size(128)。
LeNet 模型训练的代码上次忘了放了,放到这篇文章附件里。
这次输入的图像增大很多,导致训练时间久了不少,我的拯救者风扇响个不停。第 10 轮训练后的相关结果为:
第10轮的训练损失为0.328
第10轮的训练精度为0.879
第10轮的测试集精度为0.885
可以看到精度已经很接近 90%,相比 LeNet 有一定提高,这得益于 Dropout、ReLU 的使用和预处理。
尽管 AlexNet 的代码仅比 LeNet 多几行,但这中间跨越的时间却有 20 来年。目前 AlexNet 已经被很多更有效的架构超越,但它是从浅层网络到深层网络的关键一步。
LeNet 与 AlexNet 模型训练的代码见附件: