【Kubernetes知识点】解读HPA的 thrashing(抖动)问题
目录
- 1 概念
- 1.1 什么是 Thrashing 现象?
- 1.2 HPA 中 Thrashing 产生的原因
- 1.3 解决 Thrashing 的优化措施
- 1.3.1 设置合适的阈值
- 1.3.2 使用自定义指标和基于负载的自动扩缩
- 1.3.3 增加扩缩容的稳定性窗口
- 2 实验:模拟 HPA 的 Thrashing 现象与优化效果
- 2.1 实验环境准备
- 2.2 创建 php-apache Deployment
- 2.2.1 Deployment YAML 文件:
- 2.2.2 通过autoscaling/v2配置 HPA
- 2.3 生成负载波动
- 2.3.1 模拟负载生成
- 2.3.2 交替运行高负载和低负载:
- 2.4 观察 HPA 行为
- 2.4.1 监控 HPA 状态
- 2.4.2 观察扩容过程
- 2.5 第一次停止负载测试
- 2.6 观察缩容行为
- 3 总结
- 4 参考资料
❤️ 摘要:在 Kubernetes 集群中,Horizontal Pod Autoscaler (HPA) 是通过自动调整 Pod 的副本数量,来根据应用负载动态地进行弹性扩展。然而,由于监控的指标(如 CPU 或内存使用率)可能频繁波动,这会导致 HPA 的扩缩容操作变得频繁不稳定,产生所谓的 thrashing(抖动) 或 flapping(摆动) 现象。本文带读者了解这种现象,并实践在Kubernetes的优化措施。
1 概念

❓ 思考:在深入了解了HPA弹性扩展的机制后, 首先会被其灵活性和自动化程度惊喜到,但是转念想,在真实的业务场景中,性能的不稳定波动是时常的事情,这是否会导致HPA频繁的扩缩容,反而会损坏大量的计算资源和降低业务质量, 对此应该如何解决呢?
1.1 什么是 Thrashing 现象?
在弹性扩展过程中,由于监控的指标(如 CPU 或内存使用率)不断波动,副本数量可能频繁变化,这种现象称为 thrashing(抖动) 或 flapping(摆动)。HPA 如果没有足够的时间窗口来稳定系统,会因瞬时波动而多次执行扩容和缩容。就像一个控制系统在面对持续变化的输入时,频繁地切换输出状态一样,类似于控制系统中的滞后现象(hysteresis)。
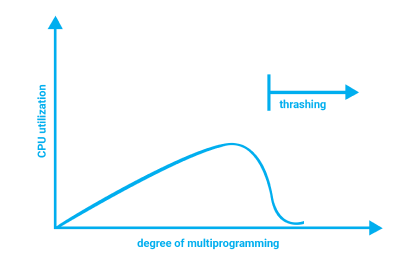
如上图所属,这种现象不仅会消耗更多的计算资源,还会影响服务的稳定性。例如 Pod 在频繁的扩缩容中可能无法及时响应请求,导致请求失败或服务性能下降。
1.2 HPA 中 Thrashing 产生的原因
Thrashing 现象有以下几个原因所引发:
- 指标波动剧烈:当应用的负载短时间内大幅度变化时,HPA 会紧跟指标频繁调整 Pod 数量。
- 没有足够的稳定性窗口:如果没有配置适当的稳定性窗口,短期内的资源波动会触发HPA不必要的扩缩容操作。
- 资源请求和限制设置不当:Pod 的资源请求和限制设置不合理,可能会导致指标过于敏感,产生误判。
1.3 解决 Thrashing 的优化措施
为了解决 HPA 中的 Thrashing 问题,我们可以通过几种方法来提高系统的稳定性。
1.3.1 设置合适的阈值
观察业务正常情况负载情况,调整 HPA 的目标指标阈值和扩缩容的上下限范围到合理指标,使系统对短期波动不敏感。例如:
- CPU 或内存的目标使用率:将目标 CPU 或内存利用率设置为合适的范围,例如将目标 CPU 使用率设置为 70%,而不是 50%,以避免在轻微波动时触发扩缩容。
- 最小和最大副本数:为应用设置合适的最小和最大 Pod 副本数量,防止 HPA 在负载波动时触发过大幅度的扩缩容。
1.3.2 使用自定义指标和基于负载的自动扩缩
对于复杂场景下的应用,CPU 或内存指标可能无法完全反映实际的负载情况。你可以通过 自定义指标(Custom Metrics) 和 外部指标(External Metrics) 结合业务需求进行扩缩容决策。例如根据请求的延迟时间、请求量或其他关键业务指标来决定是否需要扩缩容。
自定义指标可以通过 Prometheus 等监控系统集成到 Kubernetes 中,并由 HPA 进行决策。
1.3.3 增加扩缩容的稳定性窗口
通过调整组件参数或者行为策略可以有效减少短时间内由于负载波动导致的扩缩容。可以通过修改这些参数来延长等待时间,从而避免因瞬时负载变化引发的频繁扩缩。
❔ 说明:Kubernetes v1.23之前, 通过kube-controller-manager的参数控制
Kubernetes 中,HPA 的缩容和扩容操作分别有两个参数控制:
--horizontal-pod-autoscaler-downscale-delay:控制缩容时的最小等待时间,默认为 5 分钟。这意味着即使 HPA 监测到需要缩容,也至少会等待 5 分钟再执行实际操作。--horizontal-pod-autoscaler-upscale-delay:控制扩容时的最小等待时间,默认值为 3 分钟。
❔ 说明:Kubernetes v1.23之后,
autoscaling/v2API版本支持自定义HPA行为。
默认行为策略与 HPA 算法中的现有行为相匹配。
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 4
periodSeconds: 15
selectPolicy: Max
❔参数说明:
1. 缩容策略 (scaleDown)
stabilizationWindowSeconds: 300:缩容的稳定窗口期为 300 秒,当 HPA 检测到负载下降时,它会等待 300 秒(5 分钟)后再开始缩容。policies:配置了缩容的策略。type: Percent:根据百分比进行缩容。value: 100:每次缩容可以减少当前 Pod 副本数的 100%,也就是说在 300 秒的窗口期之后,缩容可以将所有副本直接减少到 0。periodSeconds: 15:缩容策略每 15 秒检查一次 Pod 的缩容需求。
2. 扩容策略 (scaleUp)
stabilizationWindowSeconds: 0:扩容没有稳定窗口期。也就是说,HPA 监测到负载增加后,会立即触发扩容操作。policies:配置了扩容的策略。- 第一条策略:
type: Percent,value: 100,periodSeconds: 15。扩容时,最多每 15 秒将 Pod 副本数增加当前 Pod 数量的 100%,即翻倍。 - 第二条策略:
type: Pods,value: 4,periodSeconds: 15。扩容时,最多每 15 秒可以增加 4 个 Pod。
- 第一条策略:
selectPolicy: Max:当有多条扩容策略时,选择扩容幅度最大的策略。在此配置下,HPA 会选择每 15 秒增加 4 个 Pod,或将 Pod 数量翻倍,取其中增长最多的策略。
2 实验:模拟 HPA 的 Thrashing 现象与优化效果
本次实验旨在通过模拟负载波动场景,使用 autoscaling/v2 的 Behavior 配置,来观察 Horizontal Pod Autoscaler (HPA) 的扩缩容行为,并解决由于负载波动导致的 Thrashing(频繁扩缩容)现象。
2.1 实验环境准备
- 部署 Kubernetes 集群
- 安装 Metrics Server 或 Prometheus 作为指标采集工具
2.2 创建 php-apache Deployment
首先,我们用回《一文读懂HPA弹性扩展以及实践攻略》的案例,创建一个Deployment,用于模拟波动负载下的扩缩容。
2.2.1 Deployment YAML 文件:
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
replicas: 1
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: harbor.zx/hcie/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 200m
requests:
cpu: 100m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
创建Deployment
kubectl apply -f php-apache.yaml
该 Deployment 创建了一个 Web 服务器,并设置了 CPU 请求(100m)和 CPU 限制(200m),确保在负载上升时有足够的资源消耗来触发 HPA。
2.2.2 通过autoscaling/v2配置 HPA
使用 autoscaling/v2 API 版本创建 HPA,并通过 Behavior 配置控制扩缩容行为。
配置HPA YAML 文件(带有 Behavior 配置):
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50 # 目标 CPU 利用率为 50%
behavior:
scaleUp:
stabilizationWindowSeconds: 60 # 稳定时间窗口为 60 秒
policies:
- type: Percent
value: 100 # 每次扩容最多增加 100% 的副本数量
periodSeconds: 30 # 每 30 秒检查一次扩容需求
scaleDown:
stabilizationWindowSeconds: 300 # 缩容的稳定时间窗口为 300 秒
policies:
- type: Percent
value: 50 # 每次缩容最多减少 50% 的副本数量
periodSeconds: 60 # 每 60 秒检查一次缩容需求
❔ 配置说明:
| 策略 | 参数 | 说明 |
|---|---|---|
scaleUp | stabilizationWindowSeconds: 60 | 扩容时,会等待至少 60 秒,以确保负载的上升是持续性的,而不是瞬时波动。 |
value: 100 | 每次扩容时,Pod 数量最多增加 100%(即翻倍)。 | |
periodSeconds: 30 | 每 30 秒检查一次扩容的需求。 | |
scaleDown | stabilizationWindowSeconds: 300 | 缩容的稳定窗口期为 5 分钟,确保负载下降是稳定的,防止因短暂的负载降低而过早缩容。 |
value: 50 | 每次缩容最多减少 50% 的 Pod 数量。 | |
periodSeconds: 60 | 每 60 秒检查一次缩容的需求。 |
创建hpa
kubectl apply -f hpa-behavior.yaml
成功输入如下:
horizontalpodautoscaler.autoscaling/php-apache-hpa created
查看hpa详细信息:
kubectl describe hpa php-apache-hpa
输出如下:
Name: php-apache-hpa
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Sat, 21 Sep 2024 23:20:13 +0800
Reference: Deployment/php-apache
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 1% (1m) / 50%
Min replicas: 1
Max replicas: 10
Behavior:
Scale Up:
Stabilization Window: 60 seconds
Select Policy: Max
Policies:
- Type: Percent Value: 100 Period: 30 seconds
Scale Down:
Stabilization Window: 300 seconds
Select Policy: Max
Policies:
- Type: Percent Value: 50 Period: 60 seconds
Deployment pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale recommended size matches current size
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited False DesiredWithinRange the desired count is within the acceptable range
Events: <none>
2.3 生成负载波动
为了模拟负载波动,我们可以使用 kubectl run 生成高负载和低负载交替的请求,观察 HPA 的行为。
2.3.1 模拟负载生成
kubectl run -it --restart=Never load-generator --image=harbor.zx/hcie/busybox:1.29-2 -- /bin/sh
在 busybox 容器中,运行以下命令向web发送请求模拟负载:
while sleep 0.1; do wget -q -O- http://php-apache; done
在负载生成器运行一段时间后,停止负载生成,模拟负载下降。
2.3.2 交替运行高负载和低负载:
- 高负载:运行上面的
wget命令 持续5 分钟。 - 低负载:停止
wget命令 3 分钟,模拟负载下降。 - 第二次高负载:运行上面的
wget命令 持续3 分钟。 - 停止负载:运行上面的
wget命令 持续5 分钟。
反复交替执行这两个操作,以观察 HPA 如何应对负载的波动。
2.4 观察 HPA 行为
2.4.1 监控 HPA 状态
使用以下命令监控 HPA 的状态变化,特别是观察 Pod 副本数在负载波动下的变化:
- 查看hpa状态
kubectl get hpa php-apache-hpa --watch
- 查看pod状态
kubectl get pods --watch
- 查看deployment状态
kubectl get deployment php-apache --watch
2.4.2 观察扩容过程
第一次压测中,观察hpa状态,输出如下:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache-hpa Deployment/php-apache 105%/50% 1 10 1 34m
php-apache-hpa Deployment/php-apache 197%/50% 1 10 1 35m
php-apache-hpa Deployment/php-apache 198%/50% 1 10 1 35m
php-apache-hpa Deployment/php-apache 198%/50% 1 10 2 35m
php-apache-hpa Deployment/php-apache 21%/50% 1 10 2 36m
php-apache-hpa Deployment/php-apache 91%/50% 1 10 2 36m
php-apache-hpa Deployment/php-apache 106%/50% 1 10 2 36m
php-apache-hpa Deployment/php-apache 107%/50% 1 10 2 36m
php-apache-hpa Deployment/php-apache 106%/50% 1 10 2 37m
php-apache-hpa Deployment/php-apache 99%/50% 1 10 4 37m
php-apache-hpa Deployment/php-apache 61%/50% 1 10 4 37m
php-apache-hpa Deployment/php-apache 58%/50% 1 10 4 37m
php-apache-hpa Deployment/php-apache 73%/50% 1 10 4 38m
php-apache-hpa Deployment/php-apache 94%/50% 1 10 4 38m
php-apache-hpa Deployment/php-apache 84%/50% 1 10 4 38m
php-apache-hpa Deployment/php-apache 107%/50% 1 10 5 38m
php-apache-hpa Deployment/php-apache 100%/50% 1 10 6 39m
php-apache-hpa Deployment/php-apache 59%/50% 1 10 7 39m
php-apache-hpa Deployment/php-apache 53%/50% 1 10 7 39m
php-apache-hpa Deployment/php-apache 52%/50% 1 10 7 39m
php-apache-hpa Deployment/php-apache 61%/50% 1 10 7 40m
观察Deployment状态,输入如下:
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 1/1 1 1 17s
php-apache 1/2 1 1 20m
php-apache 1/2 1 1 20m
php-apache 1/2 1 1 20m
php-apache 1/2 2 1 20m
php-apache 2/2 2 2 20m
php-apache 2/4 2 2 22m
php-apache 2/4 2 2 22m
php-apache 2/4 2 2 22m
php-apache 2/4 4 2 22m
php-apache 3/4 4 3 22m
php-apache 4/4 4 4 22m
php-apache 4/5 4 4 23m
php-apache 4/5 4 4 23m
php-apache 4/5 4 4 23m
php-apache 4/5 5 4 23m
php-apache 4/6 5 4 23m
php-apache 4/6 5 4 23m
php-apache 4/6 5 4 23m
php-apache 4/6 6 4 23m
php-apache 5/6 6 5 23m
php-apache 5/7 6 5 24m
php-apache 5/7 6 5 24m
php-apache 5/7 6 5 24m
php-apache 5/7 7 5 24m
php-apache 6/7 7 6 24m
❔ 说明:扩容行为是遵循每次扩容都有 60 秒的延迟,以及每次最多扩容 100% 的限制。
2.5 第一次停止负载测试
第一次压测后,观察hpa状态,输出如下:
php-apache-hpa Deployment/php-apache 15%/50% 1 10 7 41m
php-apache-hpa Deployment/php-apache 4%/50% 1 10 7 41m
php-apache-hpa Deployment/php-apache 1%/50% 1 10 7 41m
php-apache-hpa Deployment/php-apache 34%/50% 1 10 7 44m
php-apache-hpa Deployment/php-apache 55%/50% 1 10 7 44m
php-apache-hpa Deployment/php-apache 59%/50% 1 10 7 44m
php-apache-hpa Deployment/php-apache 57%/50% 1 10 7 45m
php-apache-hpa Deployment/php-apache 62%/50% 1 10 7 45m
❔ 说明:缩容行为未发生,遵循缩容有 5 分钟的延迟。
2.6 观察缩容行为
完成第二次压测后,观察hpa状态,输出如下:
php-apache-hpa Deployment/php-apache 27%/50% 1 10 8 53m
php-apache-hpa Deployment/php-apache 1%/50% 1 10 8 53m
php-apache-hpa Deployment/php-apache 1%/50% 1 10 8 58m
php-apache-hpa Deployment/php-apache 1%/50% 1 10 5 58m
php-apache-hpa Deployment/php-apache 1%/50% 1 10 4 58m
php-apache-hpa Deployment/php-apache 1%/50% 1 10 4 59m
php-apache-hpa Deployment/php-apache 1%/50% 1 10 2 59m
php-apache-hpa Deployment/php-apache 1%/50% 1 10 2 60m
php-apache-hpa Deployment/php-apache 1%/50% 1 10 1 60m
观察Deployment状态,输入如下:
php-apache 8/5 8 8 43m
php-apache 5/5 5 5 43m
php-apache 5/4 5 5 43m
php-apache 5/4 5 5 43m
php-apache 4/4 4 4 43m
php-apache 4/2 4 4 44m
php-apache 4/2 4 4 44m
php-apache 2/2 2 2 44m
php-apache 2/1 2 2 45m
php-apache 2/1 2 2 45m
php-apache 1/1 1 1 45m
❔ 说明: 缩容行为有 5 分钟的延迟,并遵循每60秒检测一次和每次最多缩容 50% 的限制。
3 总结
thrashing 或 flapping 现象虽然会由于负载指标的动态波动引起的频繁扩容和缩容。但是如果对Kubernetes资源设定合适的阈值和对HPA设置Behavior 配置,可以使得扩缩容行为更加平滑和稳定,这不仅有助于改善系统的弹性扩展能力,还能更好地平衡资源的使用和成本,帮助应用平稳应对不同的负载压力。
4 参考资料
[1] HorizontalPodAutoscalerSpec
[2]Horizontal Pod Autoscaling


![[Python学习日记-29] 开发基础练习2——三级菜单与用户登录](https://i-blog.csdnimg.cn/direct/ca69ae135d174c47bb3c9284b5c40c9f.png)