文章目录
- 【JUC并发编程系列】深入理解Java并发机制:Volatile从底层原理解析到高级应用技巧(六、Volatile关键字、JMM、重排序、双重检验锁)
- 1. Volatile的特性
- 2. Volatile的用法
- 3. CPU多核硬件架构剖析
- 4. JMM内存模型
- 4.1 主要特性
- 4.2 JMM 的工作原理
- 4.3 实现机制
- 5. JMM八大同步规范
- 6. Volatile的底层实现原理
- 6.1 Java汇编指令查看
- 6.2 MESI协议实现的原理
- 6.3 为什么Volatile不能保证原子性
- 6.4 为什么System.out.println() 可以保证线程的可见性
- 7. 重排序
- 7.1 什么是重排序
- 7.2 为什么需要重排序
- 7.3 重排序的案例分析
- 7.4 编译重排序
- 7.5 内存屏障
- 7.6 演示重排序效果
- 8. 双重检验锁
- 8.1 单例模式
- 8.2 单例的(7种)写法
- 8.2.1 懒汉式线程不安全
- 8.2.2 懒汉式线程安全
- 8.2.3 懒汉式双重检验锁(DCL,即 double-checked locking)
- 8.2.4 饿汉式
- 8.2.5 静态代码块
- 8.2.6 静态内部类
- 8.2.7 枚举实现单例
- 8.3 双重检验锁单例为什么需要加上 volatile
- 8.4 如何破解单例模式
- 8.4.1 创建对象的方式有哪些
- 8.4.2 反射破解单例
- 8.4.3 序列化破解单例
- 8.4.4 为什么枚举是最安全的单例
- 8.5 缓存行
- 8.5.1 什么是缓存行
- 8.5.2 缓存行案例演示
- 8.5.3 解决缓存行解为共享问题
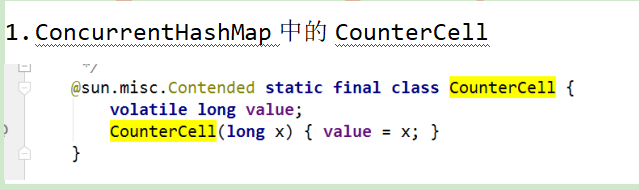
- 8.5.4 @sun.misc.Contended
【JUC并发编程系列】深入理解Java并发机制:Volatile从底层原理解析到高级应用技巧(六、Volatile关键字、JMM、重排序、双重检验锁)
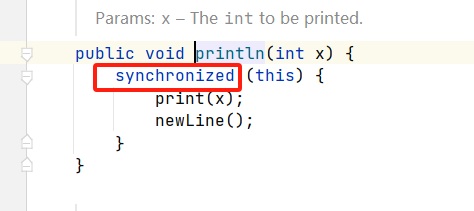
volatile是Java提供的轻量级的同步机制,保证了可见性,不保证原子性,禁止重排序。
Java 语言包含两种内在的同步机制:同步块(或方法)和 volatile 变量,相比于synchronized(synchronized通常称为重量级锁),volatile更轻量级,因为它不会引起线程上下文的切换和调度。但是volatile 变量的同步性较差(有时它更简单并且开销更低),而且其使用也更容易出错。
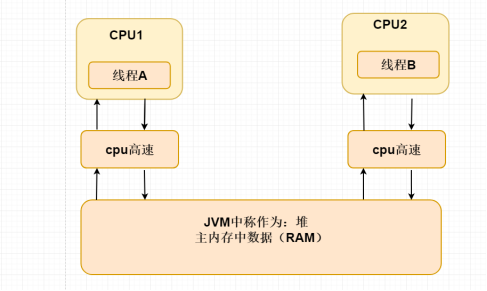
volatile 保证了多个cpu中高速缓存(工作内存)数据的一致性问题。
Java内存模型: java内存结构(jvm中知识点)还是jmm内存模型(并发编程中)
1. Volatile的特性
可见性
可见性,是指线程之间的可见性,一个线程修改的状态对另一个线程是可见的
顺序性
程序执行程序按照代码的先后顺序执行。
原子性
原子是世界上的最小单位,具有不可分割性。
Volatile关键字不保证原子性
2. Volatile的用法
在计算机编程中,volatile 是一个关键字,用于指示编译器某个变量可能会被外部(比如硬件或者其他线程)修改。这个关键字最常出现在多线程编程和低级硬件访问代码中。
在 Java 中,volatile 关键字可以确保当一个线程改变了共享变量的值时,其他线程能够看到这个改变。它通过禁止指令重排序和确保内存可见性来实现这一点。
-
禁止指令重排序:
- 编译器和处理器为了提高性能,可能会重新排序指令。
volatile变量读写操作不会被重排序。
-
确保内存可见性:
- 当一个线程修改了
volatile变量后,其他线程能立即看到这个变化。 - 这是通过强制将对
volatile变量的写入刷新到主内存,并从主内存加载volatile变量的读取来实现的。
- 当一个线程修改了
-
示例:
public class Test01 {
private volatile boolean running = true;
public void runSomeLoop() {
while (running) {
// 执行一些操作
}
}
public void stopLoop() {
running = false;
}
}
在这个例子中,running 被声明为 volatile,这样当一个线程调用 stopLoop() 方法时,其他正在执行 runSomeLoop() 的线程会立即看到 running 变量的变化,从而停止循环。
需要注意的是,虽然 volatile 可以保证内存可见性和禁止指令重排序,但它并不提供原子性。
例如,下面的操作不是原子性的:
volatile int count = 0;
public void increment() {
count++;
}
因为 count++ 包括读取 count 的值、增加 1 并写回结果三个步骤,这在多线程环境下可能不是一个完整的原子操作。
如果你需要更复杂的同步操作,通常会使用 synchronized 块或者 Java 并发库中的高级工具如 AtomicInteger 或者 Lock 类等。
总结来说,volatile 主要用于确保线程之间的可见性,防止编译器和处理器进行不安全的优化,并且通常与单个变量一起使用。
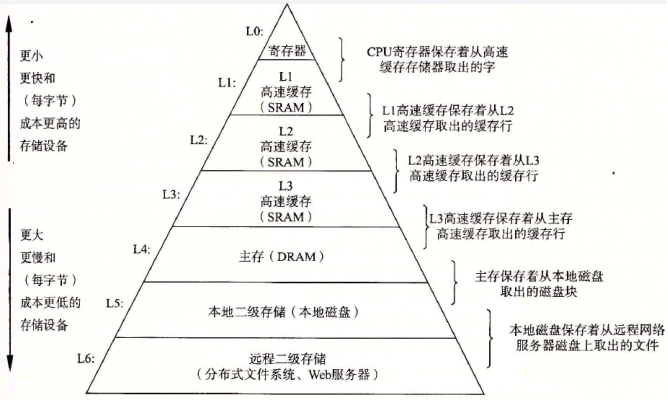
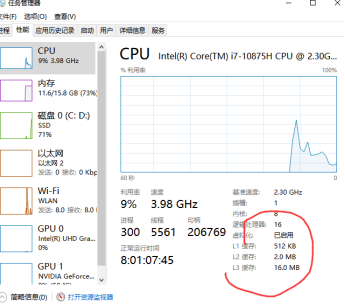
3. CPU多核硬件架构剖析
CPU每次从主内存读取数据比较慢,而现代的CPU通常涉及多级缓存,CPU读主内存按照空间局部性原则加载。
4. JMM内存模型
Java Memory Model (JMM) 是 Java 虚拟机 (JVM) 中的一个概念,它定义了 Java 程序中各种变量(线程共享变量)的访问规则,以及在并发环境下如何保证内存的可见性、有序性和原子性。理解 JMM 对于开发高性能且线程安全的 Java 应用程序至关重要。
4.1 主要特性
-
原子性:基本数据类型的读取和写入是原子性的,即不会被线程调度器打断。但需要注意的是,对于 64 位的 long 和 double 类型,在没有
volatile或synchronized修饰的情况下,读写操作可能不是原子性的。 -
有序性:JMM 保证程序执行的顺序按照代码的先后顺序进行,但在实际运行时,由于编译器优化和处理器乱序执行的原因,可能会出现指令重排序。为了保证有序性,可以通过
volatile关键字和happens-before原则来实现。 -
可见性:当一个线程修改了共享变量的值,其他线程能够立即看到这个修改。通过
volatile关键字、synchronized关键字和final关键字可以确保可见性。
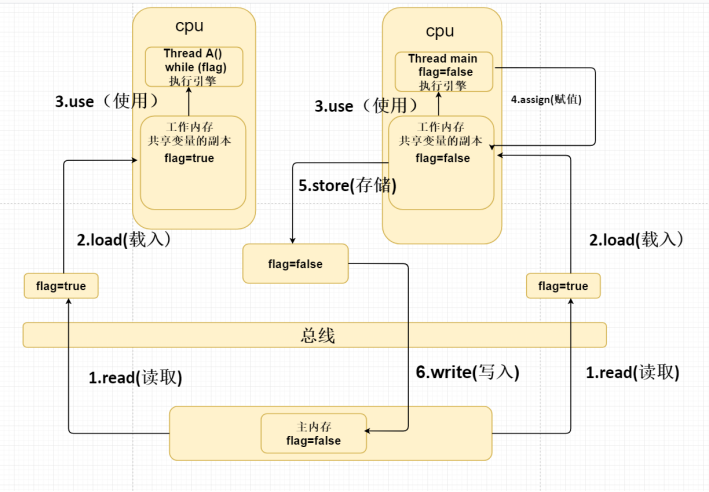
4.2 JMM 的工作原理
-
主内存与工作内存:
- 主内存:JMM 规定所有变量都存储在主内存中。
- 工作内存:每个线程都有自己的工作内存,线程对变量的操作(读取、赋值等)都在其工作内存中进行,而不是直接对主内存中的变量进行操作。
-
操作类型:
- 读取(read):将变量从主内存传输到线程的工作内存中。
- 加载(load):将主内存中的值放入工作内存的变量副本中。
- 使用(use):将工作内存中的值传递给执行引擎。
- 分配(assign):将从执行引擎接收到的值赋值给工作内存中的变量。
- 存储(store):将工作内存中的值传送到主内存中。
- 写入(write):将工作内存中的值写入主内存的变量中。
4.3 实现机制
- volatile 关键字:除了具备原子性之外,还提供可见性和禁止指令重排序的功能。
- synchronized 关键字:保证了原子性、可见性和有序性。
- final 关键字:用于不可变对象,可以保证对象创建完成后引用的可见性。
了解 JMM 的这些方面可以帮助开发者编写出更高效、更安全的多线程 Java 程序。
5. JMM八大同步规范
-
read(读取):作用于主内存的变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load(载入)动作使用;
- 从主内存读取数据
-
load(载入):作用于工作内存的变量,它把read(读取)操作从主内存中得到的变量值放入工作内存的变量副本中;
- 将主内存读取到的数据写入工作内存中
-
use(使用):作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎;
- 从工作内存读取数据来计算
-
assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋给工作内存的变量;
- 将计算好的值重新赋值到工作内存中
-
store(存储):作用于 工作内存的变量,把工作内存中的一个变量的值传送到 主内存中,以便随后的write的操作;
- 将工作内存数据写入主内存
-
write(写入):作用于工作内存的变量,它把store(存储)操作从工作内存中的一个变量的值传送到主内存的变量中;
- 将store(存储)过去的变量值赋值给主内存中的变量
-
lock(锁定):作用于主内存的变量,把一个变量标记为一条线程独占状态;
- 将主内存变量加锁,标识位线程独占状态
-
unlock(解锁):作用于主内存的变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定;
- 将主内存变量解锁,解锁后其他线程可以锁定该变量
6. Volatile的底层实现原理
Volatile的底层实现原理:通过汇编lock前缀指令触发底层锁的机制
锁的机制两种:(主要帮助我们解决多个不同cpu之间缓存之间数据同步)
- 总线锁
- MESI缓存一致性协议
什么是总线:cpu和内存进行交互就得通过总线
总线锁(现在的CPU基本上都不会使用了)
-
最初实现就是通过总线加锁的方式也就是上面的lock与unlock操作,但是这种方式存在很大的弊端。会将我们的并行转换为串行,从而失去了多线程的意义。
-
当一个cpu(线程)访问到我们主内存中的数据时候,往总线总发出一个Lock锁的信号,其他的线程不能够对该主内存做任何操作,变为阻塞状态。该模式,存在非常大的缺陷,就是将并行的程序,变为串行,没有真正发挥出cpu多核的好处。
Intel- 64 与 IA-32架构软件开发者手册对汇编lock前缀指令的解释:
- 底层实现主要通过汇编lock前缀指令,它会锁定这块内存区域的缓存(缓存行锁定)并回写到主内存。
- 会将当前处理器缓存行的数据立即写回系统主内存;
- 这个写回主内存的操作会引起在其他CPU里缓存了该内存地址的数据无效(MESI协议)
6.1 Java汇编指令查看
首先需要将该工具 hsdis-amd64.dll放入D:\java\jdk1.8\jre\bin\server\hsdis-amd64.dll中
-server -Xcomp -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -XX:CompileCommand=compileonly,*要查看的类名称.*
就会发现我们Test类中的第24行的main方法中使用到用volatile 修饰的变量在底层里前面加上了lock
0x0000000002ae6277: lock addl $0x0,(%rsp) ;*putstatic FLAG
; - com.zhaoli.Test::main@17 (line 24)
6.2 MESI协议实现的原理
-
M 修改 (Modified) :这行数据有效,数据被修改了和主内存中的数据不一致,数据只存在于本Cache中。
-
E 独享、互斥 (Exclusive): 这行数据有效,数据和主内存中的数据一致,数据只存在于本Cache中。
-
S 共享 (Shared): 这行数据有效,数据和主内存中的数据一致,数据存在于很多Cache中。
-
I 无效 (Invalid) :这行数据无效。
总线:维护解决cpu高速缓存副本数据之间一致性问题。
-
E 独享状态:在单核的情况下 ,只有一个线程,当前线程工作内存(主内存中副本数据)与主内存数据保持一致
- 则当前cpu的状态:E 独享状态
-
S 共享状态: 在多个cpu的情况下,每个线程中工作内存中(主内存中副本数据)与主内存数据保持一致性
- 当前cpu的状态是为:S 共享状态
-
M 修改状态 :当前线程线程修改了工作内存中的数据,当前cpu的副本数据与主内存数据不一致性
- 当前cpu的状态为:M修改状态
-
I 无效状态 : 总线嗅探机制如果发现cpu中副本数据与主内存数据不一致的情况下,则会认为无效需要从新刷新主内存中的数据到工作内存中
- 当前cpu的状态为:I 无效状态
6.3 为什么Volatile不能保证原子性
Volatile 可以保证可见性(保证每个cpu中的高速缓存数据一致性问题)和禁止重排序,但是不能够保证数据原子性
public class VolatileAtomThread extends Thread {
private static volatile int count;
public static void create() {
count++;
}
public static void main(String[] args) {
ArrayList<Thread> threads = new ArrayList<>();
for (int i = 0; i < 10; i++) {
Thread tempThread = new Thread(() -> {
for (int j = 0; j < 1000; j++) {
create();
}
});
threads.add(tempThread);
tempThread.start();
}
threads.forEach(thread -> {
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println(count);
}
}
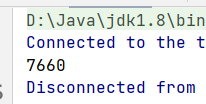
Volatile为了能够保证数据的可见性,但是不能够保证原子性,及时的将工作内存的数据刷新主内存中,导致其他的工作内存的数据变为无效状态,其他工作内存做的count++操作等于就是无效丢失了,这是为什么我们加上Volatile count结果在小于10000以内。
6.4 为什么System.out.println() 可以保证线程的可见性
因为Synchronized可以保证线程可见性和线程安全性
- 线程解锁前,必须把共享变量的最新值刷新到主内存中;
- 线程加锁时,将清空工作内存中共享变量的值,从而使用共享变量是需要从主内存中重新读取最新的值(加锁与解锁需要统一把锁)
而System.out.println()加上了 Synchronized所以可以保证线程的可见性
7. 重排序
7.1 什么是重排序
重排序并没有严格的定义。整体上可以分为两种:
-
真·重排序:编译器、底层硬件(CPU等)出于“优化”的目的,按照某种规则将指令重新排序(尽管有时候看起来像乱序);
-
伪·重排序:由于缓存同步顺序等问题,看起来指令被重排序了;
重排序也是单核时代非常优秀的优化手段,有足够多的措施保证其在单核下的正确性。在多核时代,如果工作线程之间不共享数据或仅共享不可变数据,重排序也是性能优化的利器。然而,如果工作线程之间共享了可变数据,由于两种重排序的结果都不是固定的,会导致工作线程似乎表现出了随机行为。
注意:指令重排序的前提是,重排序指令不能够影响结果
指令重排序在单线程的情况下,不会影响结果,但是在多线程的情况可能会影响结果
// 可以重排序
int a = 10;// 指令1
int b = 20;// 指令2
System.out.println(a + b);
// 不可重排序
int c = 10;
int d = c - 7;
System.out.println(d);
7.2 为什么需要重排序
优点:
执行任务的时候,为了提高编译器和处理器的执行性能,编译器和处理器(包括内存系统,内存在行为没有重排但是存储的时候是有变化的)会对指令重排序。编译器优化的重排序是在编译时期完成的,指令重排序和内存重排序是处理器重排序
-
编译器优化的重排序,在不改变单线程语义的情况下重新安排语句的执行顺序
-
指令级并行重排序,处理器的指令级并行技术将多条指令重叠执行,如果不存在数据的依赖性将会改变语句对应机器指令的执行顺序
-
内存系统的重排序,因为使用了读写缓存区,使得看起来并不是顺序执行的

缺点:
-
重排序可能会导致多线程程序出现内存可见性问题。(工作内存和主内存,编译器处理器重排序导致的可见性)
-
重排序会导致有序性问题,程序的读写顺序于内存的读写顺序不一样(编译器处理器重排序,内存缓冲区(是处理器重排序的内容))
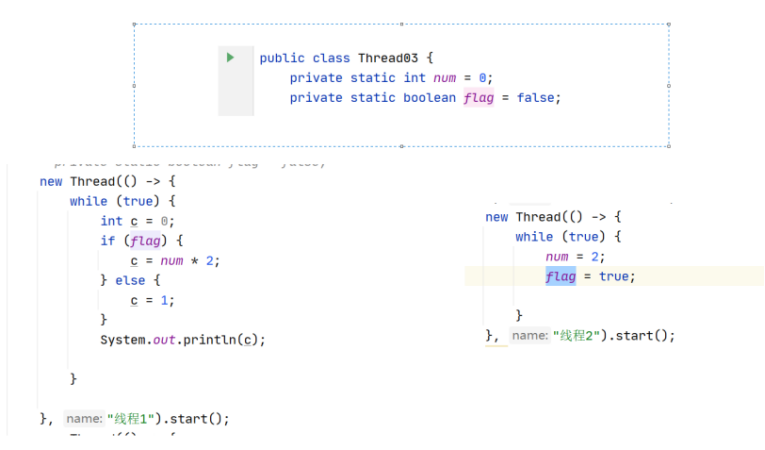
7.3 重排序的案例分析
new Thread(() -> {
while (flag) {
int c = 0;
if (flag) {
c = num * 2;
} else {
c = 1;
}
if (c == 0) {
System.out.println(c);
}
}
}, "线程1").start();
new Thread(() -> {
while (true) {
num = 2;
flag = true;
}
}, "线程2").start();
c的结果可能分析:
-
情况1:如果线程1先执行 则
flag=false则c的值=1 -
情况2:如果线程2先执行
num=2 flag=true则在执行线程1flag=true则c的值=4; -
情况3: 如果线程2发生了重排序先执行
flag = true;在执行num = 2;则c的值=0- 先执行线程2
flag=true但是还没有走完num=2赋值操作; - 另外线程1执行判断
if(flag=>c=num(0)*2c=0;
- 先执行线程2
7.4 编译重排序
优化前:cpu在执行的过程中需要读取两次x和y的值。
int x=1;
int y=2;
int a1=x*1; load x=1
int b1=y*1; load y=2
int a2=x*2; load x=1
int b2=y*2; load y=2
优化后:CPU只读一次的x和y值,不需反复读取寄存器来交替x和y值。
int x=1;
int y=2;
int a1=x*1; load x--
int a2=x*2; x*2
int b1=y*1; load y
int b2=y*2; y*
7.5 内存屏障
为了解决上述问题(编译重排序),处理器提供内存屏障指令(Memory Barrier):
内存屏障是一类特殊的指令,用于阻止处理器对内存操作的重排序,并确保某些内存操作按特定顺序完成。这些屏障可以分为读屏障和写屏障。
- 读内存屏障(Load Memory Barrier):在读指令前插入读屏障,可以让高速缓存中的数据失效,重新从主内存加载数据,确保任何后续的读操作都从主内存中获取最新的数据,而不是使用可能过时的高速缓存副本。
new Thread(() -> {
while (true) {
int c = 0;
// 读屏障 读屏障之后的代码读取主内存中的最新的数据
// 读屏障 之前的代码不会发生在读屏障之后执行
if (flag) {
c = num * 2;
} else {
c = 1;
}
System.out.println(c);
}
}, "线程1").start();
- 写内存屏障(Store Memory Barrier):在写指令之后插入写屏障,能让写入缓存的最新数据写回到主内存,确保所有先前的写操作都已完成,并且其结果已刷新到主内存中,以便其他处理器可以看见这些更新。
new Thread(() -> {
while (true) {
num = 2; // 及时刷新到主内存中
flag = true;// ready 读 Volatile赋值带写屏障
// 加上写屏障 1.处理器将存储缓存值写回主存 2.写屏障之前的代码不会发生在写屏障后面
}
}, "线程2").start();
volatile读前插读屏障,写后加写屏障,避免CPU重排导致的问题,实现多线程之间数据的可见性。
Java 语言中的 volatile
在 Java 中,volatile 关键字提供了一种轻量级的同步机制,它通过引入内存屏障来实现线程间的可见性和有序性。
- 写屏障:当一个线程写入一个
volatile变量时,会在写操作之后插入一个写屏障,以确保写入的数据立即可见于其他线程。 - 读屏障:当一个线程读取一个
volatile变量时,会在读操作之前插入一个读屏障,以确保读取的是最新的值。
Java 内存模型中的 happens-before 规则
Java 内存模型定义了一系列 happens-before 规则,这些规则定义了不同线程间操作的顺序性和可见性。
- 程序次序规则:每个线程内的操作按程序顺序执行。
- 锁规则:释放锁前的操作对获取该锁的线程可见。
- volatile 变量规则:写入
volatile变量的操作对读取该变量的线程可见。 - 线程启动规则:线程启动前的操作对启动的线程可见。
- 线程终止规则:线程结束前的操作对等待该线程结束的线程可见。
- 线程中断规则:调用线程中断的方法先于检查中断状态。
- 传递性规则:如果 A 先于 B,且 B 先于 C,则 A 也先于 C。
通过使用 volatile 和这些 happens-before 规则,开发者可以在不使用重量级同步(如锁)的情况下编写出正确且高效的并发代码。
7.6 演示重排序效果
使用jcstress并发压力测试
1. Maven依赖模板
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>mayikt-jcstress</artifactId>
<version>1.0-SNAPSHOT</version>
<prerequisites>
<maven>3.0</maven>
</prerequisites>
<dependencies>
<dependency>
<groupId>org.openjdk.jcstress</groupId>
<artifactId>jcstress-core</artifactId>
<version>0.3</version>
</dependency>
</dependencies>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!--
jcstress version to use with this project.
-->
<jcstress.version>0.5</jcstress.version>
<!--
Java source/target to use for compilation.
-->
<javac.target>1.8</javac.target>
<!--
Name of the test Uber-JAR to generate.
-->
<uberjar.name>jcstress</uberjar.name>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<compilerVersion>${javac.target}</compilerVersion>
<source>${javac.target}</source>
<target>${javac.target}</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<executions>
<execution>
<id>main</id>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<finalName>${uberjar.name}</finalName>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>org.openjdk.jcstress.Main</mainClass>
</transformer>
<transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/TestList</resource>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
2. 相关测试例子
* 测试指令重排序
*/
@JCStressTest // 标记此类为一个并发测试类
@Outcome(id = {"0"}, expect = Expect.ACCEPTABLE_INTERESTING, desc = "wrong result") // 描述测试结果
@State //标记此类是有状态的
public class TestInstructionReorder {
private volatile boolean flag;
private int num = 0;
public TestInstructionReorder() {
}
@Actor
public void actor1(I_Result r) {
if (flag) {
r.r1 = num * 2;
} else {
r.r1 = 1;
}
}
@Actor
public void actor2(I_Result r) {
this.num = 2;
flag = true;
}
}
-- 打包
1.mvn clean install
--执行
2.java -jar jcstress.jar
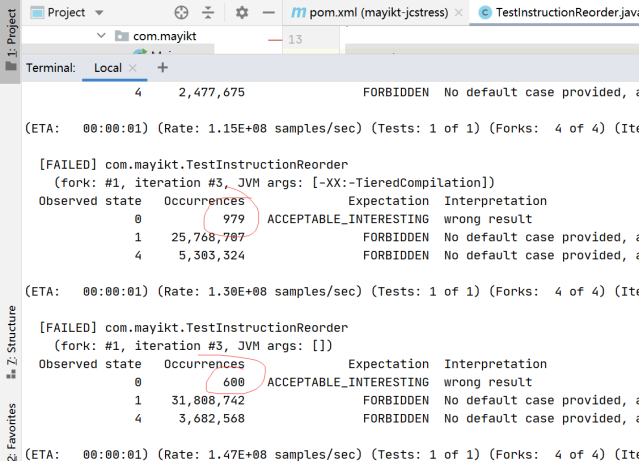
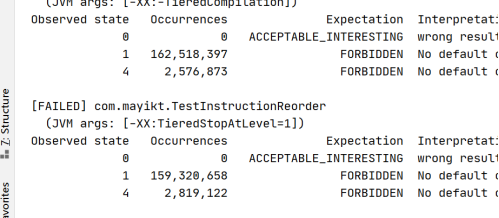
加上volatile关键字可以禁止重排序
8. 双重检验锁
8.1 单例模式
什么是单例模式:jvm中该对象只有一个实例的存在。
应用场景
- 项目中定义的配置文件
- Servlet对象默认就是单例
- 线程池、数据库连接池,复用机制,提前创建一个线程一直复用执行 任务
- Spring中Bean对象默认就是单例
- 实现网站计数器
- Jvm内置缓存框架(定义单例HashMap)
- 枚举(单例—最安全单例)
优缺点
-
优点:能够节约当前堆内存空间,不需要频繁New对象,能够快速访问;
-
缺点:当多个线程访问同一个单例对象的时候可能会存在线程安全问题;
特点
-
构造方法私有化;
-
实例化的变量引用私有化;
-
获取实例的方法共有。
8.2 单例的(7种)写法
8.2.1 懒汉式线程不安全
懒汉式基本概念:当真正需要获取到该对象时,才会创建该对象,节约内存,该写法存在线程安全性问题
public class Singleton {
//实例化的变量引用私有化
private static Singleton singleton = null;
/**
* 私有化构造函数
*/
private Singleton() {
}
public static Singleton getSingleton() {
if (singleton == null) {
singleton = new Singleton();
}
return singleton;
}
public static void main(String[] args) {
Singleton singleton1 = Singleton.getSingleton();
Singleton singleton2 = Singleton.getSingleton();
System.out.println(singleton1 == singleton2);
}
}
8.2.2 懒汉式线程安全
什么情况下需要保证线程安全性问题呢?
做写操作时:懒汉式在第一次new出该对象已经赋值singleton 后面的所有线程直接获取该singleton 对象不需要重复new,当该对象还么有new出来的时候多个线程刚好同时执行到if (singleton == null) {,会同时进入,同时执行singleton = new Singleton01();,此时发生了线程安全性问题。
// 创建和读取对象都需要获取 synchronized 锁
public static synchronized Singleton getSingleton() {
if (singleton == null) {
singleton = new Singleton();
}
return singleton;
}
给getSingleton()方法加上synchronized即可保证线程安全性问题
8.2.3 懒汉式双重检验锁(DCL,即 double-checked locking)
虽然给getSingleton()方法加上synchronized,可以避免singleton对象为空的时候有多条线程同时new Singleton(),但是当singleton不为空的时候只需要 return singleton;,并不会发生线程安全性问题,加上锁会造成每个线程获取singleton时要进行锁的竞争,导致效率过低。
解决方法:能够保证线程安全,只会创建该单例对象的时候上锁,获取该单例对象不会上锁,效率比较高。
注意:volatile 关键字避免重排序(new 操作会发生重排序)
public class Singleton {
//实例化的变量引用私有化
private static volatile Singleton singleton = null;
/**
* 私有化构造函数
*/
private Singleton() {
}
// 创建和读取对象都需要获取 Singleton 锁
public static Singleton getSingleton() {
//t1和t2 同时 判断singleton ==null; 同时进入
if (singleton == null) {
//t1和t2 线程都会进入该临界区
//假设t1线程获取锁成功, t2阻塞等待
synchronized (Singleton.class) {
//t1释放锁后 t2获取到锁进入后判断 singleton == null 此时Singleton已经被t1创建了,所以不进入,不会再次创建 Singleton 对象了
if (singleton == null) {
//t1线程创建 Singleton 对象并赋值
singleton = new Singleton();
}
}
}
return singleton;
}
public static void main(String[] args) {
Singleton singleton1 = Singleton.getSingleton();
Singleton singleton2 = Singleton.getSingleton();
System.out.println(singleton1 == singleton2);
}
}
懒汉式优点:懒加载,当我们真正需要该对象时才会创建该对象,节约内存
懒汉式缺点:使用该单例对象时需要保证线程安全性问题
8.2.4 饿汉式
饿汉式基本概念:提前创建单例对象,优点先天性保证线程安全,比较占用内存
public class Singleton {
// 当我们class被加载时,就会提前创建singleton对象
private static Singleton singleton = new Singleton();
/**
* 私有化构造函数
*/
private Singleton() {
}
public static Singleton getSingleton() {
return singleton;
}
public static void main(String[] args) {
Singleton singleton1 = Singleton.getSingleton();
Singleton singleton2 = Singleton.getSingleton();
System.out.println(singleton1 == singleton2);
}
}
8.2.5 静态代码块
public class Singleton {
// 当我们class被加载时,就会提前创建singleton对象
private static Singleton singleton = null;
static {
singleton = new Singleton();
System.out.println("static执行");
}
/**
* 私有化构造函数
*/
private Singleton() {
}
public static Singleton getSingleton() {
return singleton;
}
public static void main(String[] args) {
Singleton singleton1 = Singleton.getSingleton();
Singleton singleton2 = Singleton.getSingleton();
System.out.println(singleton1 == singleton2);
}
}
8.2.6 静态内部类
在spring框架源码中 经常会发现使用静态内部类单例,它是懒加载的形式,先天性保证线程安全问题。
public class Singleton {
/**
* 私有化构造函数
*/
private Singleton() {
}
private static class SingletonHolder {
private static Singleton singleton = new Singleton();
}
public static Singleton getSingleton() {
return SingletonHolder.singleton;
}
public static void main(String[] args) {
Singleton singleton1 = Singleton.getSingleton();
Singleton singleton2 = Singleton.getSingleton();
System.out.println(singleton1 == singleton2);
}
}
8.2.7 枚举实现单例
public enum Singleton {
INSTANCE;
public void getInstance() {
System.out.println("<<<getInstance>>>");
}
}
枚举属于目前最安全的单例,不能够被反射,序列化保证单例
8.3 双重检验锁单例为什么需要加上 volatile
javap -c -v Singleton.class查看汇编指令
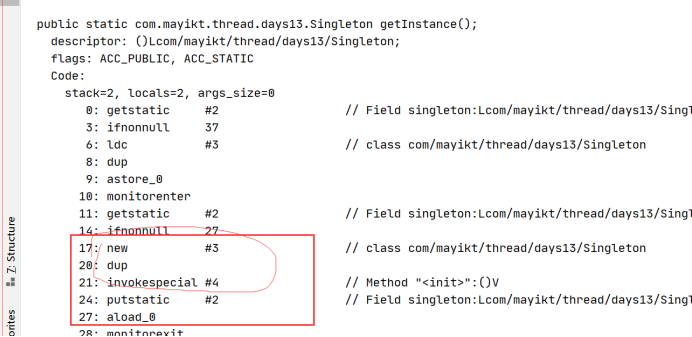
// 创建 Singleton 对象实例,分配内存
0: new //
// 复制栈顶地址,并再将其压入栈顶
3: dup
// 调用构造器方法,初始化 Singleton 对象 对象里面还会有一些成员属性对象
4: invokespecial // Method "<init>":()V
// 存入局部方法变量表
7: astore_0
创建对象过程:
-
分配内存空间;
-
初始化对象;
-
将内存空间的地址赋值给对应的引用。
2和3会被处理器优化,发生重排序,如果发生重排序则:
-
A线程
singleton = new Singleton()发生重排序,将分配的内存空间引用赋值给了静态属性singleton(即singleton != null),而对象还未初始化(即Integer a == null); -
B线程此时调用
getInstance()方法,因为singleton != null,直接返回singleton。当B线程使用singleton的a`属性时就会空指针。
所以:**懒加载双重检验锁需要加上volatile关键字,目的是为了禁止new对象操作时发生重排序,避免另外的线程拿到的对象是一个不完整的对象。**在单线程的情况下 new操作发生重排序对结果没有任何的影响。
**例如:**这个源代码里面也加上了volatile关键字,使用的也是双重检验锁单例。
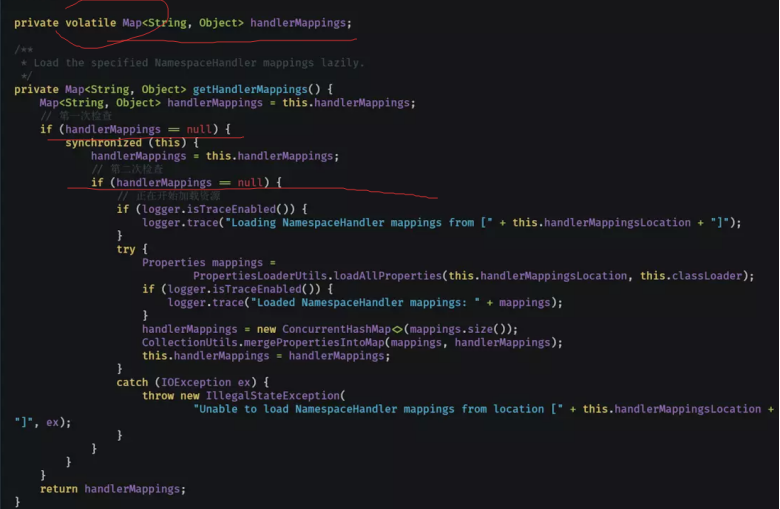
8.4 如何破解单例模式
8.4.1 创建对象的方式有哪些
-
直接new对象
-
采用克隆对象
-
使用反射创建对象
-
序列化与反序列化
8.4.2 反射破解单例
反射如何破解单例
public class Singleton {
private static Singleton singleton;
static {
/**
* 静态代码快初始化单例模式
*/
try {
singleton = new Singleton();
} catch (Exception e) {
e.printStackTrace();
}
}
private Singleton() throws Exception {
if (singleton != null) {
throw new Exception("不能够重复初始化对象");
}
}
public static Singleton getSingleton() {
return singleton;
}
public static void main(String[] args) throws ClassNotFoundException, IllegalAccessException, InstantiationException {
// 使用反射破解单例
Singleton singleton01 = Singleton.getSingleton();
// 使用反射破解单例
Class<?> aClass = Class.forName("com.zhaoli.thread.days15.Singleton");
Singleton singleton02 = (Singleton) aClass.newInstance();
System.out.println(singleton01 == singleton02);
}
}
如何防止反射单例被破解
//使用饿汉式单例模式,给无参构造函数加上下面这段代码即可防止单例被反射破解
private Singleton() throws Exception {
if (singleton != null) {
throw new Exception("该对象已经创建");
}
System.out.println("无参构造函数");
}
8.4.3 序列化破解单例
序列化概念:将对象转换成二进制的形式直接存放在本地
反序列化概念:从硬盘读取二进制变为对象
序列化如何破解单例
public class Singleton implements Serializable {
private static Singleton singleton = new Singleton();
public static Singleton getSingleton() {
return singleton;
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
// 1.将对象序列化存入到本地文件中
FileOutputStream fos = new FileOutputStream("d:/code/a.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
Singleton singleton1 = Singleton.getSingleton();
oos.writeObject(singleton1);
oos.close();
fos.close();
System.out.println("----------从硬盘中反序列化对象到内存中------------");
//2.从硬盘中反序列化对象到内存中
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("d:/code/a.txt"));
// 从新获取一个新的对象
Singleton singleton2 = (Singleton) ois.readObject();
System.out.println(singleton1 == singleton2);
}
}
如何防止序列化单例被破解
重写readResolve方法 返回原来对象即可
//在当前的单例类中加上此方法既可防止被破解
private Object readResolve() throws ObjectStreamException {
return singleton;
}
原理:
- 调用
readObject() - 执行
readObject0(); Switch判断tc=115 object class
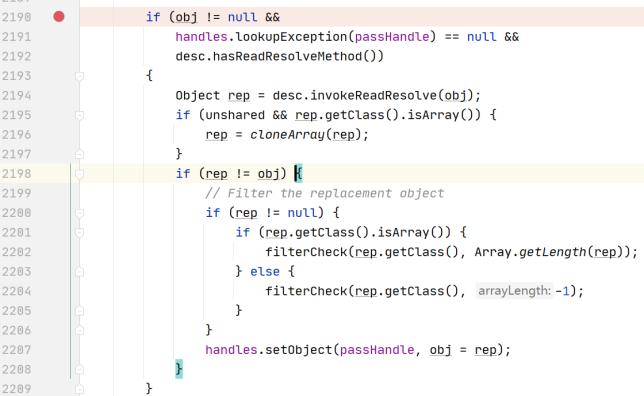
判断反序列化类中如果存在readResolve方法 则通过反射机制调用readResolve方法返回相同的对象
8.4.4 为什么枚举是最安全的单例
枚举单例不可被反射和序列化(在java层面进行的防御)
反射攻击枚举
- 使用
XJad.exe反编译枚举会发现,枚举底层实际上基于类封装的。
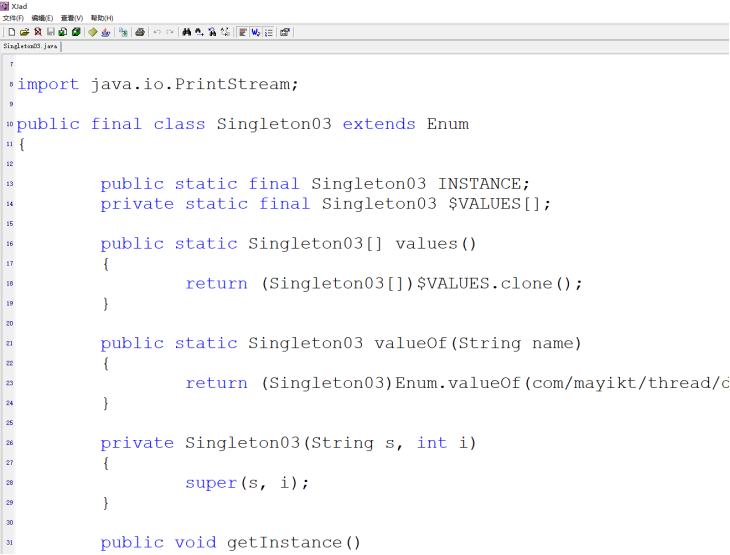
- 枚举底层使用类封装的,没有无参构造函数,所有根据无参构造函数反射都会报错
Singleton instance1 = Singleton.INSTANCE;
Singleton instance2 = Singleton.INSTANCE;
System.out.println(instance1 == instance2);
// 反射攻击枚举
Class<?> aClass = Class.forName("com.zhaoli.thread.days15.Singleton");
Singleton instance3 = (Singleton) aClass.newInstance();
System.out.println(instance1 == instance3);
报错内容:
Exception in thread "main" java.lang.InstantiationException: com.zhaoli.thread.days15.Singleton03
at java.lang.Class.newInstance(Class.java:427)
at com.zhaoli.thread.days15.Test01.main(Test01.java:21)
Caused by: java.lang.NoSuchMethodException: com.zhaoli.thread.days15.Singleton.<init>()
at java.lang.Class.getConstructor0(Class.java:3082)
at java.lang.Class.newInstance(Class.java:412)
- 在根据该返回可以发现是有参构造函数,第一个参数为
String类型,第二参数为int类型
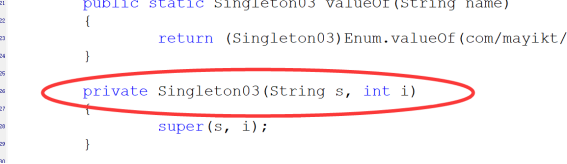
- 使用有参构造函数调用,还是报错
Class<?> aClass = Class.forName("com.zhaoli.thread.days15.Singleton");
Constructor<?> declaredConstructor = aClass.getDeclaredConstructor(String.class, int.class);
declaredConstructor.setAccessible(true);
Singleton singleton03 = (Singleton) declaredConstructor.newInstance("1", 0);
Singleton instance3 = (Singleton) aClass.newInstance();
System.out.println(instance3 == instance1);
报错内容:
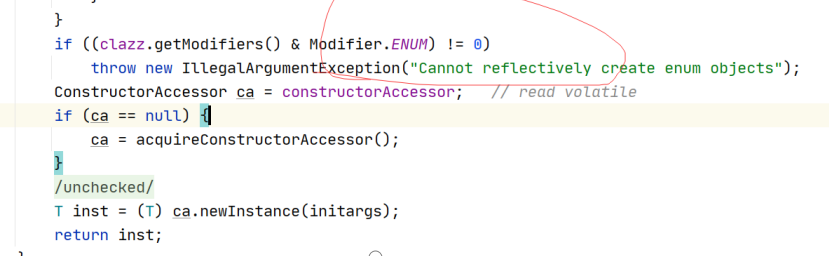
Exception in thread "main" java.lang.IllegalArgumentException: Cannot reflectively create enum objects
at java.lang.reflect.Constructor.newInstance(Constructor.java:417)
at com.zhaoli.thread.days15.Test01.main(Test01.java:23)
枚举不能够被反射 ,反射底层代码有判断处理
序列化攻击枚举
FileOutputStream fos = new FileOutputStream("d:/code/a.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
Singleton singleton3 = Singleton.INSTANCE;
oos.writeObject(singleton3);
oos.close();
fos.close();
System.out.println("----------从硬盘中反序列化对象到内存中------------");
//2.从硬盘中反序列化对象到内存中
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("d:/code/a.txt"));
// 从新获取一个新的对象
Singleton singleton4 = (Singleton) ois.readObject();
System.out.println(instance2 == singleton4);
序列化无法破解枚举的原理:Enum.valueOf((Class)cl, name),这样实现的过程其实就是EnumClass.name(我代码的体现是Singleton.INSTANCE),这样来看的话无论是EnumClass.name获取对象,还是Enum.valueOf((Class)cl, name)获取对象,它们得到的都是同一个对象,这其实就是枚举保持单例的原理。
8.5 缓存行
8.5.1 什么是缓存行
Cpu读取数据不是单个字节进行读取的,采用缓存行的形式,Cpu会以缓存行的形式读取主内存中数据,缓存行的大小为2的幂次数字节,一般的情况下是为64个字节。
如果该变量共享到同一个缓存行,就会影响到整理性能。
例如:线程1修改了long类型变量A,long类型定义变量占用8个字节,在由于缓存一致性协议,线程2的变量A副本会失效,线程2在读取主内存中的数据的时候,以缓存行的形式读取,无意间将主内存中的共享变量B也读取到内存中,而化主内存中的变量B没有发生变化

缓存行:
-
缓存行越大,cpu高速缓存(局域空间缓存)更多的内容,读取时间慢;
-
缓存行越小,cpu高速缓存局域空间缓存比较少的内容,读取时间快;
-
折中值:64个字节。
8.5.2 缓存行案例演示
public class FalseShareTest implements Runnable {
// 定义4和线程
public static int NUM_THREADS = 4;
// 递增+1
public final static long ITERATIONS = 500L * 1000L * 1000L;
private final int arrayIndex;
// 定义一个 VolatileLong数组
private static VolatileLong[] longs;
// 计算时间
public static long SUM_TIME = 0l;
public FalseShareTest(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
for (int j = 0; j < 10; j++) {
System.out.println(j);
if (args.length == 1) {
NUM_THREADS = Integer.parseInt(args[0]);
}
longs = new VolatileLong[NUM_THREADS];
for (int i = 0; i < longs.length; i++) {
longs[i] = new VolatileLong();
}
final long start = System.nanoTime();
runTest();
final long end = System.nanoTime();
SUM_TIME += end - start;
}
System.out.println("平均耗时:" + SUM_TIME / 10);
}
private static void runTest() throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseShareTest(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
@Override
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = i;
}
}
public final static class VolatileLong {
public long value = 0L;
}
}
这个程序通过创建多个线程,并让每个线程对 longs 数组中的不同 VolatileLong 对象进行写操作,以此来测试多线程环境下的性能。由于 VolatileLong 中的 value 字段被声明为 volatile,这确保了线程之间的可见性,避免了数据竞争条件。然而,如果这些对象在内存中紧密相邻,可能会导致假共享问题,即虽然每个线程访问的是不同的对象,但由于它们位于同一个缓存行内,因此每次写操作都会导致整个缓存行的无效化,从而降低了性能。
8.5.3 解决缓存行解为共享问题
Jdk1.6中实现方案
将对象的大小填充至64字节
public final static class VolatileLong {
public volatile long value = 0L;
private int p0;
// // 伪填充
public volatile long p1, p2, p3, p4, p5;
}
Jdk1.7中实现方案
专门建一个类,负责让目标类继承使其达到64字节
public final static class VolatileLong extends AbstractPaddingObject {
public volatile long value = 0L;
}
public class AbstractPaddingObject {
private int p0;
// // 伪填充
public volatile long p1, p2, p3, p4, p5;
}
8.5.4 @sun.misc.Contended
@sun.misc.Contended
public final static class VolatileLong {
public volatile long value = 0L;
}
可以直接在类上加上该注解@sun.misc.Contended ,启动的时候需要加上该参数-XX:-RestrictContended