ddia-v2中文版地址:https://github.com/Vonng/ddia/tree/v2
ddia-v2看完感觉爱不释手,只要是数据相关的知识都娓娓道来,为什么会这样?现在是怎样的?这样有什么问题?其中的看法和想法实在精辟、干练,甚至连每个章节的航海图都很有意思。
注意:本文只是对原作的一点摘抄,基本没有自己的思路和想法。仅仅是把一些非常爱的东西摘下来,有些已经掌握和太遥远的知识是略过的!
ch1 数据系统架构中的利弊权衡
OLTP&OLAP
OLTP和分析之间的区别并不总是明确的,但下表列出了一些典型的特征
| 属性 | 业务系统 (OLTP) | 分析系统 (OLAP) |
|---|---|---|
| 主要读取模式 | 点查询(按键提取个别记录) | 在大量记录上聚合 |
| 主要写入模式 | 创建、更新和删除个别记录 | 批量导入(ETL)或事件流 |
| 人类用户示例 | 网络/移动应用的终端用户 | 内部分析师,用于决策支持 |
| 机器使用示例 | 检查是否授权某项行动 | 检测欺诈/滥用模式 |
| 查询类型 | 固定的查询集合,由应用预定义 | 分析师可以进行任意查询 |
| 数据表示 | 数据的最新状态(当前时间点) | 随时间发生的事件历史 |
| 数据集大小 | GB,TB | TB,PB |
数据仓库是一个单独的数据库,分析师可以尽情查询,而不影响OLTP操作.数据仓库通常以与OLTP数据库非常不同的方式存储数据,以优化常见于分析的查询类型
将数据获取到数据仓库的过程称为提取-转换-加载(Extract–Transform–Load,ETL)
有些数据库系统提供混合事务/分析处理(HTAP),旨在在单一系统中同时启用OLTP和分析,无需从一个系统向另一个系统进行ETL 。
尽管存在HTAP,由于它们目标和要求的不同,事务性和分析性系统之间的分离仍然很常见。特别是,每个业务系统拥有自己的数据库被视为良好的实践,导致有数百个独立的操作数据库;另一方面,一个企业通常只有一个数据仓库,这样业务分析师可以在单个查询中合并来自几个业务系统的数据。
数据湖一个集中的数据存储库,存放可能对分析有用的任何数据,通过ETL过程从业务系统获取。与数据仓库的不同之处在于,数据湖只包含文件,不强加任何特定的文件格式或数据模型。数据仓库通常使用关系数据模型,通过SQL查询。
数据湖仓不仅是单独的数据仓库,还可以直接在数据湖中的文件上运行典型的数据仓库工作负载(SQL查询和商业分析),以及数据科学/机器学习工作负载,这种架构被称为数据湖仓。它需要一个查询执行引擎和一个元数据(例如,模式管理)层来扩展数据湖的文件存储 。Apache Hive、Spark SQL、Presto和Trino是这种方法的例子。
云服务和自托管
云服务的优缺点
使用云服务,而不是自己运行可比软件,本质上是将该软件的运营外包给云提供商。支持和反对使用云服务的理由都很充分。
优势:
- 当你使用云时,仍然需要一个运营团队,但将基本的系统管理外包可以释放你的团队,专注于更高层次的问题
- 如果你的系统负载随时间变化很大,云服务特别有价值。如果你配置你的机器能够处理高峰负载,但这些计算资源大部分时间都处于空闲状态,系统的成本效益就会降低。
- 与物理机相比,云实例可以更快地配置,并且大小种类更多
缺点:
- 云服务最大的缺点是你对它没有控制权
- 如果你已经有设置和操作所需系统的经验,并且你的负载相当可预测(即,你需要的机器数量不会剧烈波动),那么通常购买自己的机器并自己运行软件会更便宜。
- 如果它缺少你需要的功能,你唯一能做的就是礼貌地询问供应商是否会添加它;你通常无法自己实现它。
- 如果服务出现故障,你只能等待它恢复。
- 如果你以某种方式使用服务,触发了一个错误或导致性能问题,你很难诊断问题。对于你自己运行的软件,你可以从业务系统获取性能指标和调试信息来帮助你了解其行为,你可以查看服务器日志,但使用供应商托管的服务时,你通常无法访问这些内部信息。
- 此外,如果服务关闭或变得无法接受地昂贵,或者如果供应商决定以你不喜欢的方式更改其产品,你将受制于他们——继续运行软件的旧版本通常不是一个选项,因此你将被迫迁移到另一个服务 。如果有提供兼容API的替代服务,这种风险可以缓解,但对于许多云服务,没有标准的API,这增加了切换的成本,使供应商锁定成为一个问题。
- 像高频交易这样对延迟极其敏感的应用需要完全控制硬件,这样的业务上云不是一个好的选择。
云原生
| 类别 | 自托管系统 | 云原生系统 |
|---|---|---|
| 事务型/OLTP | MySQL, PostgreSQL, MongoDB | AWS Aurora , Azure SQL DB Hyperscale , Google Cloud Spanner |
| 分析型/OLAP | Teradata, ClickHouse, Spark | Snowflake , Google BigQuery, Azure Synapse Analytics |
云原生服务的关键思想是不仅使用由业务系统管理的计算资源,还要构建在更低层级的云服务之上,创建更高层级的服务。例如:
- 对象存储服务,如亚马逊 S3、Azure Blob 存储和 Cloudflare R2 存储大文件。它们提供的 API 比典型文件系统的 API 更有限(基本的文件读写),但它们的优势在于隐藏了底层的物理机器:服务自动将数据分布在许多机器上,因此你无需担心任何一台机器上的磁盘空间耗尽。即使某些机器或其磁盘完全失败,也不会丢失数据。
- 许多其他服务又是建立在对象存储和其他云服务之上的:例如,Snowflake 是一种基于云的分析数据库(数据仓库),依赖于 S3 进行数据存储 ,还有一些服务又建立在 Snowflake 之上。
云原生系统通常是多租户的,这意味着它们不是为每个客户配置单独的机器,而是在同一共享硬件上由同一服务处理来自几个不同客户的数据和计算。多租户可以实现更好的硬件利用率、更容易的可扩展性和云提供商更容易的管理。
云时代的运营
传统上,管理组织服务器端数据基础设施的人被称为数据库管理员(DBAs)或系统管理员(sysadmins)。近年来,许多组织试图将软件开发和运营的角色整合到一个团队中,共同负责后端服务和数据基础设施;DevOps哲学指导了这一趋势。站点可靠性工程师(SREs)是谷歌实施这一理念的方式。
DevOps/SRE哲学更加强调:
- 自动化——偏好可重复的过程而不是一次性的手工作业,
- 偏好短暂的虚拟机和服务而不是长时间运行的服务器,
- 促进频繁的应用更新,
- 从事件中学习,
- 即使个别人员来去,也要保留组织对系统的知识。
基础设施公司的运营团队专注于向大量客户提供可靠服务的细节,而服务的客户尽可能少地花时间和精力在基础设施上。除了传统意义上的容量规划的需要,采用云服务可能比运行自己的基础设施更容易且更快。虽然云正在改变运营的角色,但运营的需求依旧迫切。
ch2 定义非功能性要求
硬件和软件缺陷
在大规模系统中,硬件故障发生得足够频繁,以至于它们成为正常系统运作的一部分:
- 每年大约有 2-5% 的磁盘硬盘出现故障;在一个拥有 10,000 块硬盘的存储集群中,我们因此可以预计平均每天会有一块硬盘故障。
- 每年大约有 0.5-1% 的固态硬盘(SSD)故障。不可纠正的错误大约每年每块硬盘发生一次
- 大约每 1,000 台机器中就有一台的 CPU 核心偶尔计算出错误的结果
- RAM 中的数据也可能被破坏,原因可能是宇宙射线等随机事件,或是永久性物理缺陷。此外,某些病态的内存访问模式可以高概率地翻转位。
- 其他硬件组件如电源供应器、RAID 控制器和内存模块也会发生故障
- 整个数据中心可能变得不可用(例如,由于停电或网络配置错误)或甚至被永久性破坏(例如火灾或洪水)。
软件故障往往是难以预料,而且因为是跨节点相关的,所以硬件故障往往可能造成更多的系统失效:
- 接受特定的错误输入,便导致所有应用服务器实例崩溃的 BUG。例如 2012 年 6 月 30 日的闰秒,由于 Linux 内核中的一个错误,许多应用同时挂掉了。
- 失控进程会用尽一些共享资源,包括 CPU 时间、内存、磁盘空间或网络带宽。
- 系统依赖的服务变慢,没有响应,或者开始返回错误的响应。
- 级联故障,一个组件中的小故障触发另一个组件中的故障,进而触发更多的故障
运维配置错误是导致服务中断的首要原因,而硬件故障(服务器或网络)仅导致了 10-25% 的服务中断。
可伸缩性原则
一个关于可扩展性的好的一般原则是将系统分解成可以相对独立运行的小组件。这是微服务背后的基本原则。然而,挑战在于知道应该在一起的事物和分开的事物之间划线的位置。
如果单机数据库可以完成工作,它可能比复杂的分布式设置更可取。一个拥有五个服务的系统比拥有五十个服务的系统简单。好的架构通常涉及到方法的混合使用。
运维
运维团队对于保持软件系统顺利运行至关重要。一个优秀运维团队的典型职责如下(或者更多):
- 监控系统的运行状况,并在服务状态不佳时快速恢复服务。
- 跟踪问题的原因,例如系统故障或性能下降。
- 及时更新软件和平台,比如安全补丁。
- 了解系统间的相互作用,以便在异常变更造成损失前进行规避。
- 预测未来的问题,并在问题出现之前加以解决(例如,容量规划)。
- 建立部署、配置、管理方面的良好实践,编写相应工具。
- 执行复杂的维护任务,例如将应用程序从一个平台迁移到另一个平台。
- 当配置变更时,维持系统的安全性。
- 定义工作流程,使运维操作可预测,并保持生产环境稳定。
- 铁打的营盘流水的兵,维持组织对系统的了解。
良好的可操作性意味着更轻松的日常工作,进而运维团队能专注于高价值的事情。数据系统可以通过各种方式使日常任务更轻松:
- 通过良好的监控,提供对系统内部状态和运行时行为的可见性。
- 为自动化提供良好支持,将系统与标准化工具相集成。
- 避免依赖单台机器(在整个系统继续不间断运行的情况下允许机器停机维护)。
- 提供良好的文档和易于理解的操作模型(“如果做 X,会发生 Y”)。
- 提供良好的默认行为,但需要时也允许管理员自由覆盖默认值。
- 有条件时进行自我修复,但需要时也允许管理员手动控制系统状态。
- 行为可预测,最大限度减少意外。
运维的某些方面可以,而且应该是自动化的,但在最初建立正确运作的自动化机制仍然取决于人。
带有太强个人色彩的系统无法成功。当最初的设计完成并且相对稳定时,不同的人们以自己的方式进行测试,真正的考验才开始。
—— 高德纳
ch3 数据模型与查询语言
大多数应用程序是通过在一个数据模型之上层叠另一个数据模型来构建的。
- 作为应用开发者,你观察现实世界(其中有人、组织、商品、行动、资金流动、传感器等),并以对象或数据结构以及操作这些数据结构的 API 的形式对其进行建模。这些结构通常是针对你的应用特定的。
- 当你想存储这些数据结构时,你会用通用数据模型来表达它们,比如 JSON 或 XML 文档、关系数据库中的表,或图中的顶点和边。这些数据模型是本章的主题。
- 构建你的数据库软件的工程师决定了一种将该 JSON/关系/图数据表示为内存、磁盘或网络上的字节的方式。这种表现可能允许数据被查询、搜索、操作和以各种方式处理。我们将在[后续链接]中讨论这些存储引擎设计。
- 在更低的层次上,硬件工程师已经找出了如何将字节以电流、光脉冲、磁场等形式表示。
SQL & NOSQL
数据库能够在多个 CPU 核心和机器上并行执行声明式查询,而你无需担心如何实现该并行性。在手工编码的算法中,自行实现这种并行执行将是一项巨大的工作。
关系模型,尽管已有半个世纪之久,仍然是许多应用程序的重要数据模型——特别是在数据仓库和商业分析中,关系星型或雪花型架构和SQL查询无处不在。然而,在其他领域,几种替代关系数据的模型也变得流行:
- 文档模型 针对数据以自包含的 JSON 文档形式出现,且文档之间的关系罕见的用例。
- 图数据模型 则走向相反方向,针对任何事物都可能与一切相关的用例,查询可能需要跨多个跳点寻找感兴趣的数据(这可以通过在 Cypher、SPARQL 或 Datalog 中使用递归查询来表达)。
- dataframe 将关系数据概括为大量的列,从而在数据库和构成大部分机器学习、统计数据分析和科学计算基础的多维数组之间架起了一座桥梁。
数据库也趋向于通过添加对其他数据模型的支持来扩展到相邻领域:例如,关系数据库增加了对文档数据的支持,以 JSON 列的形式,文档数据库增加了类似关系的连接,对 SQL 中图数据的支持也在逐渐改进。
ch4 存储和索引
散列索引
键值存储与在大多数编程语言中可以找到的 字典(dictionary) 类型非常相似,通常字典都是用 散列映射(hash map) 或 散列表(hash table) 实现的。
一般来说,HASH索引的散列映射完全保留在内存中。而数据值可以使用比可用内存更多的空间,因为可以在硬盘上通过一次硬盘查找操作来加载所需部分。
散列索引的缺陷:
- 原则上可以在硬盘上维护一个散列映射,不幸的是硬盘散列映射很难表现优秀。它需要大量的随机访问 I/O,而后者耗尽时想要再扩充是很昂贵的,并且需要很烦琐的逻辑去解决散列冲突
- 范围查询效率不高。例如,你无法轻松扫描 kitty00000 和 kitty99999 之间的所有键 —— 你必须在散列映射中单独查找每个键
B树索引
B树索引在1970年就已经出现,并且广泛被行业接受和使用。
该部分内容大部分人较为熟悉,略。
SStables & LSM tree
HASH索引中键值对的顺序并不重要,但我们可以要求键值对的序列按键排序。这个格式称为 排序字符串表(Sorted String Table),简称 SSTable。
与使用散列索引的日志段相比,SSTable 有几个大的优势:
- 即使文件大于可用内存,合并段的操作仍然是简单而高效的。这种方法就像归并排序算法中使用的方法一样,如 图 3-4 所示:你开始并排读取多个输入文件,查看每个文件中的第一个键,复制最低的键(根据排序顺序)到输出文件,不断重复此步骤,将产生一个新的合并段文件,而且它也是也按键排序的。

- 为了在文件中找到一个特定的键,你不再需要在内存中保存所有键的索引。你仍然需要一个内存中的索引来告诉你一些键的偏移量,但它可以是稀疏的:每几千字节的段文件有一个键就足够了,因为几千字节可以很快地被扫描完。
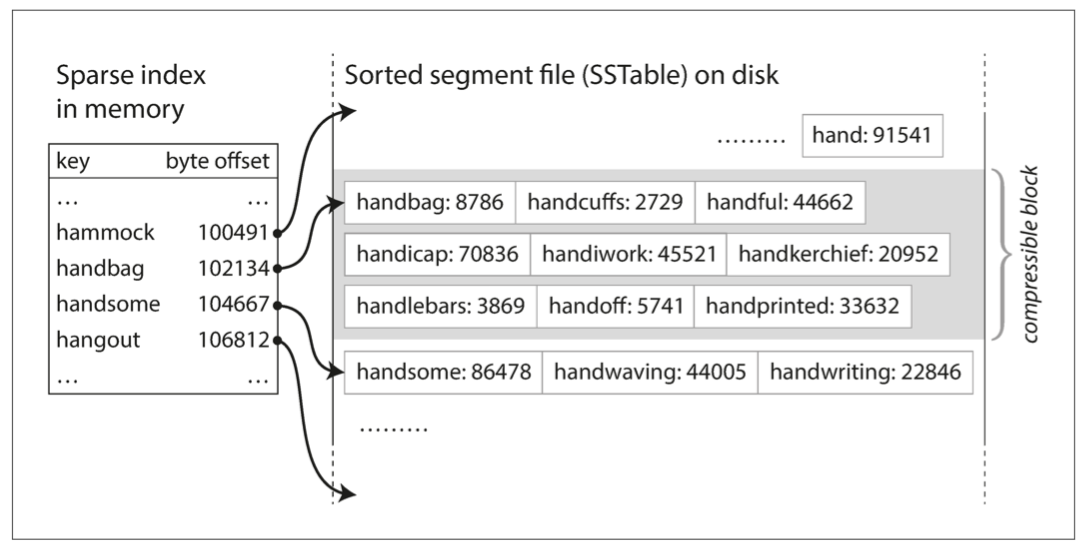
使用这些数据结构,你可以按任何顺序插入键,并按排序顺序读取它们。
现在我们可以让我们的存储引擎以如下方式工作:
- 有新写入时,将其添加到内存中的平衡树数据结构(例如红黑树)。这个内存树有时被称为 内存表(memtable)。
- 当内存表大于某个阈值(通常为几兆字节)时,将其作为 SSTable 文件写入硬盘。这可以高效地完成,因为树已经维护了按键排序的键值对。新的 SSTable 文件将成为数据库中最新的段。当该 SSTable 被写入硬盘时,新的写入可以在一个新的内存表实例上继续进行。
- 收到读取请求时,首先尝试在内存表中找到对应的键,如果没有就在最近的硬盘段中寻找,如果还没有就在下一个较旧的段中继续寻找,以此类推。
- 时不时地,在后台运行一个合并和压缩过程,以合并段文件并将已覆盖或已删除的值丢弃掉。
这里描述的算法本质上是LevelDB和RocksDB这些键值存储引擎库所使用的技术,这些存储引擎被设计嵌入到其他应用程序中。在 Cassandra和HBase中也使用了类似的存储引擎,而且他们都受到了Google的Bigtable 论文(引入了术语 SSTable 和 memtable )的启发。
内存数据库
内存数据库:
随着 RAM 变得更便宜,每GB成本比RAM低的论据被侵蚀了。许多数据集不是那么大,所以将它们全部保存在内存中是非常可行的,包括可能分布在多个机器上。这导致了内存数据库的发展。
在重新启动计算机时丢失的数据是可以接受的。也可以通过特殊的硬件(例如电池供电的 RAM)来实现持久性,也可以将更改日志写入硬盘,还可以将定时快照写入硬盘或者将内存中的状态复制到其他机器上。
典型的内存数据库Redis通过异步写入硬盘提供了较弱的持久性。其他内存数据库还有Memcached、VoltDB、MemSQL、Oracle TimesTen、RAM Cloud。
反直觉的是,内存数据库的性能优势并不是因为它们不需要从硬盘读取,相反,它们更快的原因在于省去了将内存数据结构编码为硬盘数据结构的开销。
物化视图与OLAP
如 SQL 中的 COUNT、SUM、AVG、MIN 或 MAX。如果相同的聚合被许多不同的查询使用,那么每次都通过原始数据来处理可能太浪费了。为什么不将一些查询使用最频繁的计数或总和缓存起来?创建这种缓存的一种方式是物化视图(Materialized View)。
当底层数据发生变化时,物化视图需要更新,因为它是数据的非规范化副本。数据库可以自动完成该操作,但是这样的更新使得写入成本更高,这就是在 OLTP 数据库中不经常使用物化视图的原因。在读取繁重的数据仓库中,它们可能更有意义,因为数仓不会有小而多的更新。
物化数据立方体的优点是可以让某些查询变得非常快,因为它们已经被有效地预先计算了。例如,如果你想知道每个商店的总销售额,则只需查看合适维度的总计,而无需扫描数百万行的原始数据。
数据立方体的缺点是不具有查询原始数据的灵活性。例如,没有办法计算有多少比例的销售来自成本超过 100 美元的项目,因为价格不是其中的一个维度。因此,大多数数据仓库试图保留尽可能多的原始数据,并将聚合数据(如数据立方体)仅用作某些查询的性能提升手段。
列式存储
列式存储背后的想法很简单:不要将所有来自一行的值存储在一起,而是将来自每一列的所有值存储在一起。列式存储在关系数据模型中是最容易理解的,但它同样适用于非关系数据。例如,Parquet是一种列式存储格式,支持基于 Google 的 Dremel 的文档数据模型。
这些优化(列压缩、排序等等)在数据仓库中是有意义的,因为其负载主要由分析人员运行的大型只读查询组成。列式存储、压缩和排序都有助于更快地读取这些查询。然而,他们的缺点是写入更加困难。
ch5 编码和演化
REST与RPC
服务器通过网络公开 API,并且客户端可以连接到服务器以向该 API 发出请求。服务器公开的 API 被称为服务。通过 GET 请求下载,通过 POST 请求提交数据到服务器。
当服务使用 HTTP 作为底层通信协议时,可称之为 Web 服务。有两种流行的 Web 服务方法:REST 和 SOAP。REST 不是一个协议,而是一个基于 HTTP 原则的设计哲学,根据 REST 原则设计的 API 称为 RESTful。
远程过程调用(RPC)与本地函数调用非常不同
- 本地函数调用是可预测的,并且成功或失败仅取决于受你控制的参数。网络请求是不可预测的:请求或响应可能由于网络问题会丢失,或者远程计算机可能很慢或不可用
- 本地函数调用要么返回结果,要么抛出异常,或者永远不返回(因为进入无限循环或进程崩溃)。网络请求有另一个可能的结果:由于超时,它返回时可能没有结果。
- 等等。
REST 似乎是公共 API 的主要风格,RPC 框架的主要重点在于同一组织拥有的服务之间的请求,通常在同一数据中心内。
ch6 复制
复制日志、failover、单主模式,内容比较简单,略。
多主复制
多主复制在许多数据库中都属于改装的功能,所以常常存在微妙的配置缺陷,且经常与其他数据库功能之间出现意外的反应。比如自增主键、触发器、完整性约束等都可能会有麻烦。因此,多主复制往往被认为是危险的领域,应尽可能避免。
但是多主复制确实有一定的优势,例如分散写入IO、容灾、异地多中心减少网络开销(本地写入)等等。
写冲突:
多主复制的最大问题是可能发生写冲突,解决起来也比较棘手。
原则上,可以使冲突检测同步 - 即等待写入被复制到所有副本,然后再告诉用户写入成功。但是这可能违背了多主的初衷,如果你想要同步冲突检测,那么可能不如直接使用单主复制。
解决多主写冲突:
- 避免冲突。例如应用程序控制用户仅编辑自己的数据。
- 收敛一致
- 最后写入胜利(LWW, last write wins)。按时间戳写入,可能会有数据丢失。
- 优先级写入。高优先级的写入,可能会有数据丢失。
- 额外的代码。保持冲突信息,编写额外的冲突解决代码
实时协作编辑应用程序允许多个人同时编辑文档,如Etherpad、Google Docs有许多成熟案例。数据库在多主写入方面还很年轻。
数据库多主写入冲突大部分情况都在应用层面解决或避免,以下比较成熟的写入冲突的研究供参考:
- 无冲突复制数据类型(Conflict-free replicated datatypes,CRDT)是可以由多个用户同时编辑的集合、映射、有序列表、计数器等一系列数据结构,它们以合理的方式自动解决冲突。一些 CRDT 已经在 Riak 2.0 中实现。
- 可合并的持久数据结构(Mergeable persistent data structures)显式跟踪历史记录,类似于 Git 版本控制系统,并使用三向合并功能(而 CRDT 使用双向合并)。
- 操作转换(operational transformation)是 Etherpad 和 Google Docs 等协同编辑应用背后的冲突解决算法。它是专为有序列表的并发编辑而设计的,例如构成文本文档的字符列表。
ch7 分区
范围分区和hash分区
范围分区分区的缺点是某些特定的访问模式会导致热点。如果主键是时间戳,则分区对应于时间范围,写入操作都会转到同一个分区(即今天的分区),这样分区可能会因写入而过载,而其他分区则处于空闲状态。
可以使用除了时间戳以外的其他东西作为主键的第一个部分以打散热点,缺点在于范围查询不会受益。
hash分区可以缓解偏斜和热点的风险。出于分区的目的,散列函数不需要多么强壮的加密算法。
hash分区的缺陷是,通过使用键散列进行分区,我们失去了键范围分区的一个很好的属性:高效执行范围查询的能力。
哈希分区可以帮助减少热点。但是,它不能完全避免。例如,在社交媒体网站上,一个拥有数百万追随者的名人用户在做某事时可能会引发一场风暴。这个事件可能导致同一个键的大量写入(键可能是名人的用户 ID,或者人们正在评论的动作的 ID。此时哈希策略不起作用,因为两个相同 ID 的哈希值仍然是相同的。
如果一个主键很热,一个简单的解决方法是在主键的开始或结尾添加一个随机数。只要一个两位数的十进制随机数就可以将主键分散为 100 种不同的主键,从而存储在不同的分区中。总之还是打散热点,并且要考虑范围查询等副作用。
ch8 事务
ACID、BASE
ACID其实是一个很古老的定义,由于后期发现了很多的“异象”,所以一个系统说自己保证ACID实际上他说不清自己保证了什么。
ACID不管怎样还是深入人心的,他代表了事务的最基本的原则。相反的,不符合 ACID标准的系统有时被称为 BASE,他代表基本可用性(Basically Available),软状态(Soft State)和 最终一致性(Eventual consistency)。BASE是NOSQL常提及的概念。
BASE的定义比ACID还要模糊,一个简单、易理解、容易记忆的BASE理论:BASE(英文含义为碱)是反ACID(英文含义为酸)的概念。
可以简单地这么理解:
| 关系型数据库 | 非关系型数据库 |
| 事务 | 无事务 |
| ACID | BASE |
| SQL | NOSQL |
ACID中的原子性和隔离性比较好理解。
一致性概念实际上很模糊,而且看起来跟数据库关系不大。书中一段引用非常经典:
Joe Hellerstein指出,在 Härder 与 Reuter 的论文中,“ACID 中的 C” 是被 “扔进去凑缩写单词的”,而且那时候大家都不怎么在乎一致性
而隔离性的定义非常模糊,可串行话的工业化的实践也停滞不前。
事务的隔离性可谓“一团浆糊”,但是可串行化是灵丹妙药为什么没人用呢?
参考这篇文章事务的历史与SSI
- 非可串行化隔离级别的异常现象,一般都需要在高并发情况下才会发生,低并发数据库不太会出现问题;
- 当异常现象真的发生的时候,有些应用可能没发现异常现象或检查到异常但对他们不重要;
- 有可能数据异常了,但应用只是返回报错,并进入数据异常处理程序;
- 成本过高。不仅是数据库串行化隔离级别开发成本高,应用对可串行化也需要适应成本。光是理解这部分复杂的理论就不是一件容易的事;
- 高级别的隔离会丢失一些性能。大量的改造工作可能是吃力不讨好的,应用需要在“高并发”和“无异常现象”间做抉择;
- 业务基于机制开发,而不是规则开发。业务多少有点适应弱隔离级别的异常现象,特别是RC 。
总结为一句话的话:又不是不能用!
悲观和乐观事务模型
两阶段锁是一种所谓的悲观并发控制机制(pessimistic):它是基于这样的原则:如果有事情可能出错(如另一个事务持有锁),最好等到情况安全后再做事情。这就像互斥,用于保护多线程编程中的数据结构。
从某种意义上说,串行执行可以称为悲观到了极致:在事务持续期间,每个事务对整个数据库(或数据库的一个分区)具有排它锁,作为对悲观的补偿,我们让每笔事务执行得非常快,所以只需要短时间持有“锁”。
相比之下,串行化快照隔离是一种乐观(optimistic)的并发控制技术。在这种情况下,乐观意味着,如果存在潜在的危险也不阻止事务,而是继续执行事务,希望一切都会好起来。当一个事务想要提交时,数据库检查是否有什么不好的事情发生(即违反隔离原则);如果是的话,事务将被中止,并且必须重试。只有可串行化的事务才被允许提交。如果存在很多争用(contention,即很多事务试图访问相同的对象),则表现不佳,因为这会导致很大一部分事务需要中止。如果系统已经接近最大吞吐量,来自重试事务的额外负载可能会使性能变差。
ch9 分布式系统
时钟
时钟在分布式系统中十分关键,它可能会直接影响事务的可见性/隔离性/正确性。
实际上准确的读取时间点是没有意义的(从量子理论上看就没有绝对的时间点的概念,实际情况要更复杂)。 Spanner 中的 Google TrueTime API 地报告了本地时钟的置信区间。置信区间会报告一个极短且可信的时间范围,而不是一个时间点。
例如,如果你有两个置信区间,每个置信区间包含最早和最晚可能的时间戳(
A
=
[
A
e
a
r
l
i
e
s
t
,
A
l
a
t
e
s
t
]
A = [A_{earliest}, A_{latest}]
A=[Aearliest,Alatest],
B
=
[
B
e
a
r
l
i
e
s
t
,
B
l
a
t
e
s
t
]
B=[B_{earliest}, B_{latest}]
B=[Bearliest,Blatest]),这两个区间不重叠(即:
A
e
a
r
l
i
e
s
t
<
A
l
a
t
e
s
t
<
B
e
a
r
l
i
e
s
t
<
B
l
a
t
e
s
t
A_{earliest} <A_{latest} <B_{earliest} <B_{latest}
Aearliest<Alatest<Bearliest<Blatest)的话,那么 B 肯定发生在 A 之后 —— 这是毫无疑问的。只有当区间重叠时,我们才不确定 A 和 B 发生的顺序。
为了确保事务时间戳反映因果关系,在提交读写事务之前,Spanner 在提交读写事务时,会故意等待置信区间长度的时间。Spanner 为了保持尽可能小的时钟不确定性,Google 在每个数据中心都部署了一个 GPS 接收器或原子钟,这允许时钟同步到大约 7 毫秒以内。
**逻辑时钟(logic clock)**是基于递增计数器而不是振荡石英晶体。逻辑时钟仅测量事件的相对顺序。
实时可能不存在。响应优先级高于一切。对于大多数服务器端数据处理系统来说,实时保证是不经济或不合适的。因此,这些系统必须承受在非实时环境中运行的暂停和时钟不稳定性。
ch10 一致性与共识
我们假设的所有问题都可能发生:网络中的数据包可能会丢失、重新排序、重复推送或任意延迟;时钟只是尽其所能地近似;且节点可以暂停(例如,由于垃圾收集)或随时崩溃。
CAP
CAP 定理的正式定义仅限于很狭隘的范围,它只考虑了一个一致性模型(即线性一致性)和一种故障(网络分区,或活跃但彼此断开的节点)。它没有讨论任何关于网络延迟,死亡节点或其他权衡的事。因此,尽管 CAP 在历史上有一些影响力,但对于设计系统而言并没有实际价值。
分布式事务和共识
迄今为止所讨论的所有共识协议,在内部都以某种形式使用一个领导者,但它们并不能保证领导者是独一无二的。相反,它们可以做出更弱的保证:协议定义了一个纪元编号(epoch number,在 Paxos 中被称为投票编号,即 ballot number,在视图戳复制中被称为视图编号,即 view number,以及在 Raft 中被为任期号码,即 term number),并确保在每个时代中,领导者都是唯一的。
每次当现任领导被认为挂掉的时候,节点间就会开始一场投票,以选出一个新领导。这次选举被赋予一个递增的纪元编号,因此纪元编号是全序且单调递增的。如果两个不同的时代的领导者之间出现冲突(也许是因为前任领导者实际上并未死亡),那么带有更高纪元编号的领导说了算。
设计能健壮应对不可靠网络的算法仍然是一个开放的研究问题。
ch11 批处理
-
服务(在线系统)
服务等待客户的请求或指令到达。每收到一个,服务会试图尽快处理它,并发回一个响应。响应时间通常是服务性能的主要衡量指标,可用性通常非常重要(如果客户端无法访问服务,用户可能会收到错误消息)。 -
批处理系统(离线系统)
一个批处理系统有大量的输入数据,跑一个作业(job) 来处理它,并生成一些输出数据,这往往需要一段时间(从几分钟到几天),所以通常不会有用户等待作业完成。相反,批量作业通常会定期运行(例如,每天一次)。批处理作业的主要性能衡量标准通常是吞吐量(处理特定大小的输入所需的时间)。本章中讨论的就是批处理。 -
流处理系统(准实时系统)
流处理介于在线和离线(批处理)之间,所以有时候被称为准实时(near-real-time)或准在线(nearline)处理。像批处理系统一样,流处理消费输入并产生输出(并不需要响应请求)。但是,流式作业在事件发生后不久就会对事件进行操作,而批处理作业则需等待固定的一组输入数据。这种差异使流处理系统比起批处理系统具有更低的延迟。
2004 年发布的批处理算法 Map-Reduce(可能被过分热情地)被称为 “造就 Google 大规模可伸缩性的算法”,MapReduce 是一个相当低级别的编程模型。
MapReduce和分布式文件系统
与关系数据库的查询优化器相比,即使 Unix 工具非常简单,但仍然非常有用。
Unix 工具的最大局限在于它们只能在一台机器上运行 —— 而 Hadoop 这样的工具即应运而生
MapReduce 有点像 Unix 工具,但分布在数千台机器上。像 Unix 工具一样,它相当简单粗暴,但令人惊异地管用。
MapReduce 作业在分布式文件系统上读写文件。在 Hadoop 的 MapReduce 实现中,该文件系统被称为 HDFS(Hadoop 分布式文件系统),一个 Google 文件系统(GFS)的开源实现。
除 HDFS 外,还有各种其他分布式文件系统,如 GlusterFS 和 Quantcast File System(QFS)。诸如 Amazon S3、Azure Blob 存储和 OpenStack Swift等对象存储服务在很多方面都是相似的
要创建 MapReduce 作业,你需要实现两个回调函数,Mapper 和 Reducer,其行为如下:
-
Mapper
Mapper 会在每条输入记录上调用一次,其工作是从输入记录中提取键值。对于每个输入,它可以生成任意数量的键值对(包括 None)。它不会保留从一个输入记录到下一个记录的任何状态,因此每个记录都是独立处理的。 -
Reducer
MapReduce 框架拉取由 Mapper 生成的键值对,收集属于同一个键的所有值,并在这组值上迭代调用 Reducer。Reducer 可以产生输出记录(例如相同 URL 的出现次数)。
使用 MapReduce 编程模型,能将计算的物理网络通信层面(从正确的机器获取数据)从应用逻辑中剥离出来(获取数据后执行处理)。这种分离与数据库的典型用法形成了鲜明对比,从数据库中获取数据的请求经常出现在应用代码内部。由于 MapReduce 处理了所有的网络通信,因此它也避免了让应用代码去担心部分故障,例如另一个节点的崩溃:MapReduce 在不影响应用逻辑的情况下能透明地重试失败的任务。
“把相关数据放在一起” 的另一种常见模式是,按某个键对记录分组(如 SQL 中的 GROUP BY 子句)。使用 MapReduce 实现这种分组操作的最简单方法是设置 Mapper,以便它们生成的键值对使用所需的分组键。然后分区和排序过程将所有具有相同分区键的记录导向同一个 Reducer。
Hadoop与分布式数据库的对比
正如我们所看到的,Hadoop 有点像 Unix 的分布式版本,其中 HDFS 是文件系统,而 MapReduce 是 Unix 进程的怪异实现(总是在 Map 阶段和 Reduce 阶段运行 sort 工具)。我们了解了如何在这些原语的基础上实现各种连接和分组操作。
当 MapReduce 论文发表时,它从某种意义上来说 —— 并不新鲜。我们在前几节中讨论的所有处理和并行连接算法已经在十多年前所谓的大规模并行处理(MPP,massively parallel processing)数据库中实现了。比如 Gamma database machine、Teradata 和 Tandem NonStop SQL 就是这方面的先驱。
最大的区别是,MPP 数据库专注于在一组机器上并行执行分析 SQL 查询,而 MapReduce 和分布式文件系统的组合则更像是一个可以运行任意程序的通用操作系统。
处理模型的多样性
只有两种处理模型,SQL 和 MapReduce,还不够,需要更多不同的模型!而且由于 Hadoop 平台的开放性,实施一整套方法是可行的,而这在单体 MPP 数据库的范畴内是不可能的。
传统上,MPP 数据库满足了商业智能分析和业务报表的需求,但这只是许多使用批处理的领域之一。
自 MapReduce 开始流行的这几年以来,分布式批处理的执行引擎已经很成熟了。
ch12 流处理
略。
事件溯源
事件溯源是一种强大的数据建模技术:从应用的角度来看,将用户的行为记录为不可变的事件更有意义,而不是在可变数据库中记录这些行为的影响。事件溯源类似于编年史(chronicle)数据模型
与变更数据捕获类似,事件溯源涉及到 将所有对应用状态的变更存储为变更事件日志。
使用事件溯源的应用需要拉取事件日志(表示写系统的数据),并将其转换为适合向用户显示的应用状态。从事件日志中派生出当前状态。
ch13 数据系统的未来
lambda架构
如果批处理用于重新处理历史数据,而流处理用于处理最近的更新,那么如何将这两者结合起来?Lambda 架构是这方面的一个建议
Lambda 架构的核心思想是通过将不可变事件附加到不断增长的数据集来记录传入数据,这类似于事件溯源。
在 Lambda 方法中,流处理器消耗事件并快速生成对视图的近似更新;批处理器稍后将使用同一组事件并生成衍生视图的更正版本。
Unix 发展出的管道和文件只是字节序列,而数据库则发展出了 SQL 和事务。
哪种方法更好?当然这取决于你想要的是什么。Unix 是 “简单的”,因为它是对硬件资源相当薄的包装;关系数据库是 “更简单” 的,因为一个简短的声明性查询可以利用很多强大的基础设施(查询优化、索引、连接方法、并发控制、复制等),而不需要查询的作者理解其实现细节。
我将 NoSQL 运动解释为,希望将类 Unix 的低级别抽象方法应用于分布式 OLTP 数据存储的领域。
应用代码和状态的分离
理论上,数据库可以是任意应用代码的部署环境,就如同操作系统一样。然而实践中它们对这一目标适配的很差。它们不满足现代应用开发的要求,例如依赖和软件包管理、版本控制、滚动升级、可演化性、监控、指标、对网络服务的调用以及与外部系统的集成。
我认为让系统的某些部分专门用于持久数据存储并让其他部分专门运行应用程序代码是有意义的。这两者可以在保持独立的同时互动。
趋势是将无状态应用程序逻辑与状态管理(数据库)分开:不将应用程序逻辑放入数据库中,也不将持久状态置于应用程序中。
我断言在大多数应用中,完整性比及时性重要得多。违反及时性可能令人困惑与讨厌,但违反完整性的结果可能是灾难性的。
交给算法所带来的问题
1.偏见与其实:例如在种族隔离地区中,一个人的邮政编码,甚至是他们的 IP 地址,都是很强的种族指示物。这样的话,相信一种算法可以以某种方式将有偏见的数据作为输入,并产生公平和公正的输出似乎是很荒谬的。然而这种观点似乎常常潜伏在数据驱动型决策的支持者中,这种态度被讽刺为 “在处理偏差上,机器学习与洗钱类似”(machine learning is like money laundering for bias)。预测性分析系统只是基于过去进行推断;如果过去是歧视性的,它们就会将这种歧视归纳为规律
2.责任与问责:自动决策引发了关于责任与问责的问题。如果一个人犯了错误,他可以被追责,受决定影响的人可以申诉。算法也会犯错误,但是如果它们出错,谁来负责?
3.隐私与监视:让我们做一个思想实验,尝试用 监视(surveillance) 一词替换 数据(data),再看看常见的短语是不是听起来还那么漂亮。比如:“在我们的监视驱动的组织中,我们收集实时监视流并将它们存储在我们的监视仓库中。我们的监视科学家使用高级分析和监视处理来获得新的见解。”
盲目相信数据决策至高无上,这不仅仅是一种妄想,而是有切实危险的。随着数据驱动的决策变得越来越普遍,我们需要弄清楚,如何使算法更负责任且更加透明,如何避免加强现有的偏见,以及如何在它们不可避免地出错时加以修复。
用户几乎不知道他们提供给我们的是什么数据,哪些数据被放进了数据库,数据又是怎样被保留与处理的 —— 大多数隐私政策都是模棱两可的,忽悠用户而不敢打开天窗说亮话。如果用户不了解他们的数据会发生什么,就无法给出任何有意义的同意。
对于不同意监视的用户,唯一真正管用的备选项,就是简单地不使用服务。但这个选择也不是真正自由的:如果一项服务如此受欢迎,以至于 “被大多数人认为是基本社会参与的必要条件”,那么指望人们选择退出这项服务是不合理的 —— 使用它事实上是强制性的。
总结
由于软件和数据对世界产生了如此巨大的影响,我们工程师们必须牢记,我们有责任为我们想要的那种世界而努力:一个尊重人,尊重人性的世界。我希望我们能够一起为实现这一目标而努力。