大家好,文本信息转化为知识图谱的技术,自问世以来一直是研究界的宠儿。大型语言模型(LLMs)的兴起让这个领域受到更多关注,但LLMs的成本之高令人却步。然而通过对小型模型微调优化,可以找到一种更经济高效的解决方案。
今天向大家介绍Relik,这是由罗马大学(Sapienza University of Rome)自然语言处理团队精心研发的快速、轻量级信息提取框架。
1.信息提取流程
在不依赖LLMs的情况下,信息提取流程通常包括:
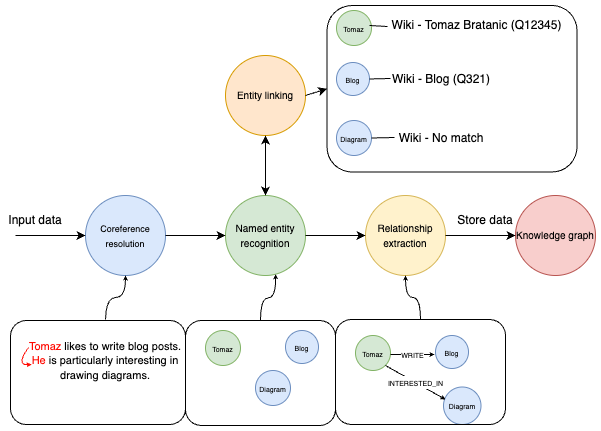
上图呈现了信息提取的完整流程。始于一段简单的文本输入:“Tomaz likes to write blog posts. He is particularly interested in drawing diagrams.”。流程首先进行指代消解,将“Tomaz”和“He”识别为同一人。紧接着,命名实体识别(NER)技术辨识出“Tomaz”、“Blog”和“Diagram”等关键实体。
随后,实体链接环节将这些识别出的实体与数据库或知识库中的相应条目相对应。例如,“Tomaz”对应到“Tomaz Bratanic (Q12345)”,“Blog”对应到“Blog (Q321)”。然而,"Diagram"在知识库中未找到匹配项。
接下来,关系提取步骤进一步分析实体间的联系,如识别出“Tomaz”与“Blog”之间存在“WRITES”关系,说明Tomaz撰写博客;“Tomaz”与“Diagram”之间存在“INTERESTED_IN”关系,表明他对图表有兴趣。
最后,这些经过结构化的实体和关系信息被整合进知识图谱中,为后续的数据分析或信息检索提供了有序且易于访问的资源。
在没有大型语言模型(LLMs)支持的情况下,信息提取工作通常依赖一系列专业模型来分别处理指代消解、命名实体识别、实体链接和关系提取等任务。整合这些模型需要付出额外的工作和细致的调整,但这种方法能够有效降低成本。通过使用和优化这些小型、特定任务的模型,可以在整体上减少系统的构建和维护成本。
2.环境搭建与数据准备
推荐使用独立的Python环境,例如Google Colab,以便管理项目依赖项。
接下来配置Neo4j图数据库以存储解析出的数据。推荐使用Neo4j Aura(https://neo4j.com/cloud/platform/aura-graph-database/),它提供便捷的免费云服务,且与Google Colab笔记本完美兼容。
完成数据库的搭建后,可通过LlamaIndex建立数据库连接。
from llama_index.graph_stores.neo4j import Neo4jPGStore
username="neo4j"
password="rubber-cuffs-radiator"
url="bolt://54.89.19.156:7687"
graph_store = Neo4jPGStore(
username=username,
password=password,
url=url,
refresh_schema=False
)
数据集
这里使用一个新闻数据集进行分析,这个数据集是通过Diffbot API(https://www.diffbot.com/data/article/)获取的。
import pandas as pd
NUMBER_OF_ARTICLES = 100
news = pd.read_csv(
"https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/news_articles.csv"
)
news = news.head(NUMBER_OF_ARTICLES)
3.技术实现
信息提取流程首先从指代消解着手,其任务是识别文本中指代相同实体的不同表述。
据了解,目前可用于指代消解的开源模型相对较少。经过尝试比较,这里选择使用spaCy的Coreferee(https://spacy.io/universe/project/coreferee)。需要注意的是,使用Coreferee可能会遇到一些依赖性问题。
加载spaCy中的指代消解模型,使用以下代码实现:
import spacy, coreferee
coref_nlp = spacy.load('en_core_web_lg')
coref_nlp.add_pipe('coreferee')
Coreferee模型能够识别文本中指代相同实体或实体组的表达式集群。为了根据这些识别出的集群对文本进行重写,需要自定义函数来实现这一过程。
def coref_text(text):
coref_doc = coref_nlp(text)
resolved_text = ""
for token in coref_doc:
repres = coref_doc._.coref_chains.resolve(token)
if repres:
resolved_text += " " + "and".join(
[
t.text
if t.ent_type_ == ""
else [e.text for e in coref_doc.ents if t in e][0]
for t in repres
]
)
else:
resolved_text += " " + token.text
return resolved_text
测试下这个函数,确保模型和依赖项设置正确:
print(
coref_text("Tomaz is so cool. He can solve various Python dependencies and not cry")
)
在这个例子中,模型成功识别出“Tomaz”和“He”实际上指向同一实体。通过应用coref_text函数,将“Tomaz”替换“He”。
请注意,这种重写机制并不总能生成完全符合语法规则的句子,因为它采用了一种直接的替换逻辑来处理文本中的实体集群。尽管如此,对于大多数应用场景,这种方法已经足够有效。
现在把这一指代消解技术应用于我们的新闻数据集,并将其转换为LlamaIndex文档格式:
from llama_index.core import Document
news["coref_text"] = news["text"].apply(coref_text)
documents = [
Document(text=f"{row['title']}: {row['coref_text']}")
for i, row in news.iterrows()
]
Relik库集成了实体链接和关系提取两大功能,能够将这两种技术融合应用。实体链接时,Relik以维基百科为依托,实现文本实体与百科条目的精准对应。
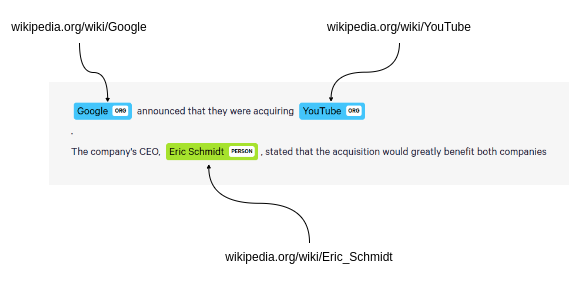
将实体链接到维基百科
在关系提取方面,Relik通过辨识和定义文本中实体间的关系,帮助我们将原始的非结构化数据转化为有序的结构化信息。
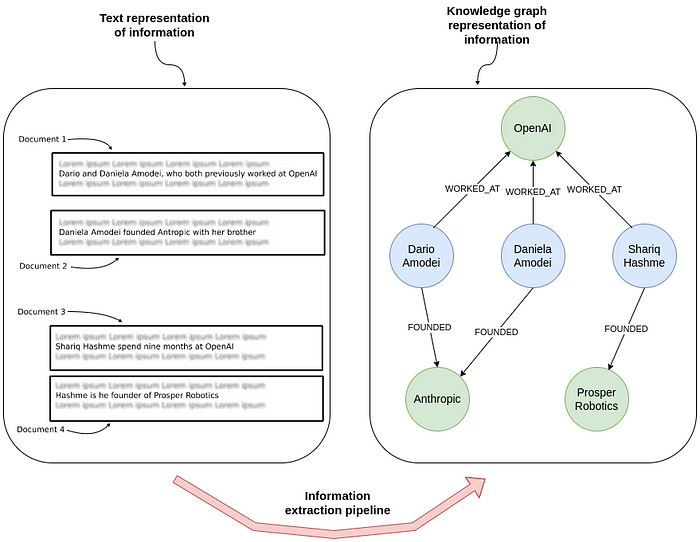
关系提取
如果你使用的是Colab的免费版本,请选择relik-ie/relik-relation-extraction-small模型,这个模型专门负责关系提取。如果有Colab Pro版本,或者打算在本地更高性能的机器上运行,那么可以尝试relik-ie/relik-cie-small模型,它不仅包含关系提取,还能进行实体链接的功能。
from llama_index.extractors.relik.base import RelikPathExtractor
relik = RelikPathExtractor(
model="relik-ie/relik-relation-extraction-small"
)
# 在Pro Collab上使用GPU
# relik = RelikPathExtractor(
# model="relik-ie/relik-cie-small", model_config={"skip_metadata": True, "device":"cuda"}
# )
此外,我们必须定义将用于嵌入实体的嵌入模型,以及用于问答流程的LLM:
import os
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
os.environ["OPENAI_API_KEY"] = "sk-"
llm = OpenAI(model="gpt-4o", temperature=0.0)
embed_model = OpenAIEmbedding(model_name="text-embedding-3-small")
注意在构建知识图谱的过程中,不会使用大型语言模型(LLM)。
4.知识图谱的构建与应用
目前,一切准备工作已经就绪。接下来,可以创建PropertyGraphIndex实例,并将新闻文档作为数据输入,整合进知识图谱中。
此外,为了提取文档中的关系,需要将relik模型设置为kg_extractors参数的值。
from llama_index.core import PropertyGraphIndex
index = PropertyGraphIndex.from_documents(
documents,
kg_extractors=[relik],
llm=llm,
embed_model=embed_model,
property_graph_store=graph_store,
show_progress=True,
)
构建图后,可以打开Neo4j浏览器来验证导入的图。通过运行以下Cypher语句获得类似的可视化:
MATCH p=(:__Entity__)--(:__Entity__)
RETURN p LIMIT 250
结果如下:

5.问答功能实现
使用LlamaIndex,现在可以轻松地进行问答。只需利用系统自带的图检索器,便能够直接提出问题:
query_engine = index.as_query_engine(include_text=True)
response = query_engine.query("What happened at Ryanair?")
print(str(response))
这就是定义的 LLM 和嵌入模型发挥作用的地方。
不依赖大型语言模型构建知识图谱是切实可行,具有成本效益且效率高。通过优化调整如Relik框架中的小型、任务专精的模型,检索增强型生成应用便能高效提取信息。
实体链接作为关键步骤,确保了识别出的实体能够准确映射到知识库中的对应条目,从而维持了知识图谱的完整性与实用性。
借助Relik框架和Neo4j平台,我们能够构建出功能强大的知识图谱,这些图谱可以助力复杂的数据分析和检索任务,而且避免了部署大型语言模型所带来的高昂成本。这种方法不仅让先进的数据处理工具变得更加亲民,也推动了信息提取流程的创新与效率。