[Python学习日记-26] Python 中的文件操作
简介
操作模式
循环文件
其他功能
混合模式
修改文件
简介
在 Python 中的文件操作其实和我们平时使用的 Word 的操作是比较类似的,我们先说一下 Word 的操作流程,流程如下:
- 找到文件,双击打开
- 读或修改
- 保存并关闭
用 Python 操作文件也大差不差,Python 操作文件流程如下:
# 1.
f = open(filename) # 打开文件
# 2.
f.write("世上无难事只怕有心人") # 写操作
f.read() # 读操作,read(100) 中的100为读100个字符
# 3.
f.close() # 保存并关闭不过 Python 的操作文件有一点恶心人的操作与 Word 文档不同,那就是 Word 文档只要打开了,就即可以读、又可以修改,而 Python 比较变态的就是,只能以读(r)、创建(w)、追加(a),这3种模式中的任意一种模式打开文件,不能即写又读(后面有伏笔)。
操作模式
Python 中有3种模式分别为:
- w:创建模式,若文件已存在,则覆盖旧文件
- r:只读模式
- a:追加模式,新数据会写到文件末尾
一、创建模式
Python 创建模式代码如下
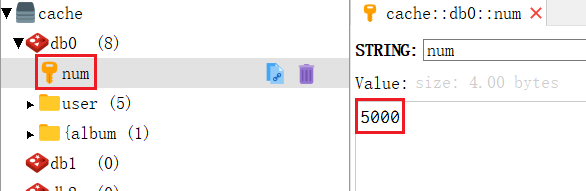
f = open(file = "D:/工作日常/staff.txt",mode = "w") # 现在的是绝对路径,如果只是一个 staff.txt 则会在代码所在的目录下创建
f.write("Jove CEO 60000\n")
f.write("Kerry 行政 5000\n")代码输出如下:

没有报错,文件应该创建成功了。查看该路径下是否已经真是创建,以及文件内容是否和 write 的一直

可以看到是一致的,需要注意的是创建模式下(w)如果有同样文件名的话会把原文件覆盖掉,这个需要特别注意
二、只读模式
Python 只读模式代码如下
美丽学姐联系方式.txt 内容如下:
马纤羽 深圳 173 50 137442345234
乔亦菲 广州 172 52 158234235252
罗梦竹 北京 175 49 186234234212
刘诺涵 北京 170 48 186234237654
岳妮妮 深圳 177 54 188353245535
贺婉萱 深圳 174 52 189334344522
叶梓萱 上海 171 49 180424323244
f = open(file='美丽学姐联系方式.txt',mode='r',encoding='utf-8') # 使用 Windows 的同学需要注意,需要使用 encoding 参数调整为 utf-8,Windows 默认使用的是 GBK
print(f.readline()) # 读取一行
print("------分隔符------")
data = f.read() # 读取当前光标下的所有,前面 f.readline() 已经把光标挪动到第二行了
print(data)
f.close() # 关闭文件代码输出如下:

值得注意的是,open() 方法 mode 参数默认的是只读模式(r)

三、追加模式
Python 追加模式代码如下
f = open(file='美丽学姐联系方式.txt',mode='a',encoding='utf-8') # Windows 默认是 GBK 而 PyCharm 默认是 UTF-8 如果不设置 encoding 参数会导致乱码
f.write("Lucy 北京 168 48 189548675236\n") # 会追加到文件尾部
f.close()代码输出如下:

没有报错,数据应该追加成功了。 我们去查看一下是否追加到文件的末尾

特别注意:在写 open() 的参数时,一定要注意,要不全部参数都已 open(file=xxx,mode=xxx,encoding=xxx) 的形式,要不全部参数都已 open(xxx,xxx,xxx) 的形式,不能一部分加名称,一部分不加,这样会报错
循环文件
数据源如下
美丽学姐联系方式.txt 内容如下:
马纤羽 深圳 173 50 137442345234
乔亦菲 广州 172 52 158234235252
罗梦竹 北京 175 49 186234234212
刘诺涵 北京 170 48 186234237654
岳妮妮 深圳 177 54 188353245535
贺婉萱 深圳 174 52 189334344522
叶梓萱 上海 171 49 180424323244
我们先来简单的把文件数据按行循环
f = open(file='美丽学姐联系方式.txt', mode='r', encoding='utf-8')
for line in f:
print(line)代码输出如下:

有的小伙伴会疑惑,我们明明没有换行啊,为什么会自动换行了呢?这是因为 print() 会在结尾自动加一个 \n,我们只需要稍加改进就可以解决这个问题了,解决这个问题有两种方式代码如下
方式一:
f = open(file='美丽学姐联系方式.txt', mode='r', encoding='utf-8')
for line in f:
print(line, end='')方式二:
f = open(file='美丽学姐联系方式.txt', mode='r', encoding='utf-8')
for line in f:
print(line.strip())两种方式代码输出都一样如下图所示:

循环文件时我们需要打印出身高大于 170cm 和体重小于等于 50kg 的美丽学姐,代码如下
f = open(file='美丽学姐联系方式.txt', mode='r', encoding='utf-8')
for line in f:
line = line.split() # 以空格为间隔,转换为列表
name,addr,height,weight,phone = line # 把列表按顺序赋值给变量
height = int(height)
weight = int(weight)
if height > 170 and weight <= 50:
print(line)
f.close()代码输出如下:

其他功能
一、返回文件打开的模式
f = open(file='美丽学姐联系方式.txt', mode='r', encoding='utf-8')
print(f.mode)
f.close()代码输出如下:

二、返回文件名
f = open(file='美丽学姐联系方式.txt', mode='r', encoding='utf-8')
print(f.name)
f.close()代码输出如下:

三、返回文件句柄在内核中的索引值
f = open(file='美丽学姐联系方式.txt', mode='r', encoding='utf-8')
print(f.fileno()) # 以后做 IO 多路复用时可以用到
f.close()代码输出如下:

四、把文件从内存 buffer 里强制刷新到硬盘
在 Python 中文件操作并不是操作一个数据就写一个数据进硬盘的,如果这样操作效率会非常之低,因为转速高的机械硬盘最高只有两200-300MB/S左右的读写速度,这个看起来是相当快了,但是对于计算机来说还是太慢了,有的人说那固态不行吗?固态是快但是远不及内存来的快,并且不是每个人的电脑都有固态的,也不是所有数据都存在固态当中的,所以我们进行文件操作时实际上是先把文件中的数据放到内存当中,然后在内存当中进行操作,最后在程序关闭或者强制写入时才写入硬盘。其实 Word 文档也是如此,在你没保存的情况下关闭程序是不是会提示你要不要保存,其实这个过程就是问你要不要强制刷新到硬盘当中,下面我们来学习一下如何实现把文件从内存 buffer 里强制刷新到硬盘当中,代码如下
f = open(file='美丽学姐联系方式.txt', mode='a', encoding='utf-8')
f.write("Lucy 北京 168 48 189548675236\n")
n = input("这是第一次阻断:正在等待输入...\n请按下回车键...") # 使用 input 进行阻断,然后去查看一下文件是否已经写入
f.flush()
n = input("这是第二次阻断:正在保存关闭...\n请按下回车键...")
f.close() # 若程序关闭也会刷新到硬盘当中input 阻断后输出如下:

可以看到程序还在等待输入用户输入,这个时候我们去看看文件是否已经写入了刚刚我们 write 的数据

在第一次阻断的情况下可以看到文件并没有刚刚写入的数据,这个时候只要我们回车一下跳过第一次阻断执行 flush() 就可以看到文件当中已写入刚刚 write 的数据了,注意这个时候程序还未结束!


再次回车跳过第二次阻断才会结束程序

把文件从内存 buffer 里强制刷新到硬盘是针对比较重要的数据写入时,让它能及时写入到硬盘当中,使它不会因为断电导致数据丢失,例如在服务器日志当中有广泛的应用
五、判断是否可读
f = open(file='美丽学姐联系方式.txt', mode='r', encoding='utf-8')
print(f.readable())
f.close()代码输出如下:

如果文件以追加模式打开,代码如下
f = open(file='美丽学姐联系方式.txt', mode='a', encoding='utf-8')
print(f.readable())
f.close()代码输出如下:

六、只读一行
f = open(file='美丽学姐联系方式.txt', mode='r', encoding='utf-8')
print(f.readline()) # 只读一行,遇到 \r or\n 为止
f.close()代码输出如下:

七、读多行(每一行作为列表一个元素)
f = open(file='美丽学姐联系方式.txt', mode='r', encoding='utf-8')
print(f.readlines())
f.close()
代码输出如下:

八、光标移位
f = open(file='美丽学姐联系方式.txt', mode='r', encoding='utf-8')
print(f.seek(3)) # 会返回以为的字节数
print(f.read())
f.close()代码输出如下:

特别注意:seek 的长度是按字节算的,字符编码存每个字符所占的字节长度不一样。如“天天向上”用 gbk 存是2个字节一个字,用 utf-8 就是3个字节,因此以 gbk 打开时,seek(4) 就把光标切掉天天两个字;如果是 UTF-8,seek(4) 会导致,只切掉第二个天字的一部分字节,打印的话会报错,因为处理剩下的文本时发现用 UTF-8 处理不了
九、判断文件是否可进行 seek 操作
f = open(file='美丽学姐联系方式.txt', mode='r', encoding='utf-8')
print(f.seekable())
f.close()代码输出如下:

十、返回当前文件操作光标位置
f = open(file='美丽学姐联系方式.txt', mode='r', encoding='utf-8')
print(f.readline())
print(f.tell())
f.close()代码输出如下:

十一、按指定长度截断文件
truncate() 有两种形式,不指定长度和指定长度。
不指定长度:就从光标所在位置到文件尾部的内容全去掉,代码如下
f = open(file='美丽学姐联系方式.txt', mode='a',encoding='utf-8')
f.seek(10)
print(f.truncate())
f.close()代码所造成的文件效果如下:

指定长度:就从文件开头开始截断指定长度
f = open(file='美丽学姐联系方式.txt', mode='a',encoding='utf-8')
f.seek(10)
print(f.truncate(100)) # 这种与光标无关
f.close()代码所造成的文件效果如下:

十二、判断文件是否可写
f = open(file='美丽学姐联系方式.txt', mode='a',encoding='utf-8')
print(f.writable())
f.close()代码输出如下:

混合模式
前面说过 Python 只能以读(r)、创建(w)、追加(a),这3种模式中的任意一种模式打开文件,不能即写又读,其实它还有一种混合模式,可以实现既可以读又可以写,只不过是比较少用,对应的也有3种模式,下面我们来看看这三种模式
- w+:写读,这个功能基本没什么意义,它会创建一个新文件,然后写一段内容,最后可以再把写的内容读出来,其实并没有什么大用
- r+:读写,能读能写,文件一打开光标会在文件开头,写入时会覆盖光标后的文字,并且光标会停留在上次修改的位置
- a+:追加读,文件一打开时光标会在文件尾部,写的数据全会是追加的形式写入
一、w+
f = open("write_and_read","w+")
f.write("Hello world1\n")
f.write("Hello world2\n")
f.write("Hello world3\n")
f.write("Hello world4\n")
f.write("Hello world5\n") # 这个时候光标已经到了末尾了需要 seek 一下
f.seek(0)
print(f.readline())
f.close()代码输出如下:

代码所造成的文件效果如下:

二、r+
f = open(file="write_and_read",mode="r+",encoding="utf-8")
f.seek(10)
f.write("Hello world1\n")
print(f.readline())
f.close()代码输出如下:

代码所造成的文件效果如下:

三、a+
f = open(file="write_and_read",mode="a+",encoding="utf-8")
print(f.readline()) # 一打开文件光标在尾部,所以为空
f.write("Hello world66") # 直接追加到文件尾部
f.seek(0)
print(f.readline())
f.close()代码输出如下:

代码所造成的文件效果如下:

修改文件
尝试直接以 r+ 模式打开文件,想要修改中间的内容的时候会发现光标后的文字被覆盖了,这并不是我们想要的效果,这是为什么原有数据会被覆盖呢?
这是硬盘的存储原理导致的,当你把文件存到硬盘上,就在硬盘上划了一块空间来存数据,在下次打开这个文件,seek 到一个位置,每改一个字,就是把原来的覆盖掉,如果要插入,是不可能的,因为后面的数据在硬盘上不会整体向后移。所以就出现当前这个情况,即原本是想插入到原来的内容之间的却变成了会把旧内容覆盖掉了。
但是人家 Word、vim 都可以修改文件(中间插入,而不删除原来的),你这不能修改看着也没什么大用呀?其实并不是不能修改,只不过不能直接在硬盘当中修改,而是先要把内容全部读到内存里,数据在内存里可以随便增删改查修改之后,把内容再全部写回硬盘,把原来的数据全部覆盖掉。Word、vim 等各种文本编辑器都是这么干的。有一个现象可以很好的证明这个说法,那就是当用 Word 或 vim 打开一个至少几百 MB 的大文件,会发现它的加载过程会花费个数十秒,这段时间就是在努力的把数据从硬盘读到内存里。
聪明的同学会发现如果文件特别大,比如5个 GB 的文件读到内存里,就一下子占用了 5GB 内存,现在一台电脑正常就十多个 GB,这妥妥的浪费资源呀,有没有更好的办法呢?
如果不想占内存,只能用另外一种办法啦,就是边读边改,即在打开旧文件的同时生成一个新文件,而新文件会从旧文件一行行的读过来写入到自己哪里,遇到需要修改就改了再写到新文件,就这样在内存里一直只存一行内容就不占内存了。 但这样也有一个缺点,就是虽然不占内存 ,但是占硬盘,每次修改都要生成一份新文件,虽然改完后可以把旧的覆盖掉,但在改的过程中,还是有2份数据的,就是说如果有个 5GB 的文件需要修改,那么你的硬盘至少要有 5GB 的空闲才能进行修改,但是目前来说硬盘的储存空间远比内存的容量大得多。
占硬盘方式的文件修改代码示例:
f_name ="美丽学姐联系方式.txt"
f_new_name ="%s.new" % f_name
old_str = "刘诺涵"
new_str = "[Lucy]"
f = open(f_name, "r", encoding="utf-8")
f_new = open(f_new_name, "w", encoding="utf-8")
for line in f:
if old_str in line:
new_line = line.replace(old_str, new_str)
else:
new_line = line
f_new.write(new_line)
f.close()
f_new.close()代码所造成的文件效果如下:


上面的代码,会生成一个修改后的新文件,但原文件不动,若想覆盖原文件,上面的代码需要再改进一下
import os # 调用系统动作时需要使用 os(operating system) 库,即 os 库是提供程序与操作系统进行交互的接口
f_name ="美丽学姐联系方式.txt"
f_new_name ="%s.new" % f_name
old_str = "刘诺涵"
new_str = "[Lucy]"
f = open(f_name, "r", encoding="utf-8")
f_new = open(f_new_name, "w", encoding="utf-8")
for line in f:
if old_str in line:
new_line = line.replace(old_str, new_str)
else:
new_line = line
f_new.write(new_line)
f.close()
f_new.close()
os.replace(f_new_name, f_name) # 把新文件名字改成原文件的名字,就会把之前旧的文件覆盖掉了,Windows 使用 os.replace(),Windows 中的 os.rename() 无法覆盖已存在的文件,只是单纯的改名,但是在 mac 中则是使用 os.rename() 来进行旧文件的覆盖代码所造成的文件效果如下:


练习
练习请查看[Python学习日记-27] 文件操作练习题解析