写在前面
【三年面试五年模拟】旨在整理&挖掘AI算法工程师在实习/校招/社招时所需的干货知识点与面试经验,力求让读者在获得心仪offer的同时,增强技术基本面。也欢迎大家提出宝贵的优化建议,一起交流学习💪
欢迎大家关注Rocky的公众号:WeThinkIn
欢迎大家关注Rocky的知乎:Rocky Ding
AIGC算法工程师面试面经秘籍分享:WeThinkIn/Interview-for-Algorithm-Engineer欢迎大家Star~
获取更多AI行业的前沿资讯与干货资源
WeThinkIn最新福利放送:大家只需关注WeThinkIn公众号,后台回复“简历资源”,即可获取包含Rocky独家简历模版在内的60套精选的简历模板资源,希望能给大家在AIGC时代带来帮助。
Rocky最新发布Stable Diffusion 3和FLUX.1系列模型的深入浅出全维度解析文章,点击链接直达干货知识:https://zhuanlan.zhihu.com/p/684068402
大家好,我是Rocky。
又到了定期阅读《三年面试五年模拟》文章的时候了!本周期共更新了80多个AIGC面试高频问答,依旧干货满满!诚意满满!
《三年面试五年模拟》系列文章帮助很多读者获得了心仪的算法岗offer,收到了大家的很多好评,Rocky觉得很开心也很有意义。
在AIGC时代到来后,Rocky对《三年面试五年模拟》整体战略方向进行了重大的优化重构,在秉持着Rocky创办《三年面试五年模拟》项目初心的同时,增加了AIGC时代核心的版块栏目,详细的版本更新内容如下所示:
- 整体架构:分为AIGC知识板块和AI通用知识板块。
- AIGC知识板块:分为AI绘画、AI视频、大模型、AI多模态、数字人这五大AIGC核心方向。
- AI通用知识板块:包含AIGC、传统深度学习、自动驾驶等所有AI核心方向共通的知识点。
Rocky已经将《三年面试五年模拟》项目的完整版构建在Github上:https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer/tree/main,本周期更新的80+AIGC面试高频问答已经全部同步到项目中了,欢迎大家star!
本文是《三年面试五年模拟》项目的第二十二式,考虑到易读性与文章篇幅,Rocky本次只从Github完整版项目中摘选了2024年9月2号-2024年9月15号更新的部分经典&干货面试知识点和面试问题,并配以相应的参考答案(精简版),供大家学习探讨。
在《三年面试五年模拟》版本更新白皮书,迎接AIGC时代中我们阐述了《三年面试五年模拟》项目在AIGC时代的愿景与规划,也包含了项目共建计划,感兴趣的朋友可以一起参与本项目的共建!
《三年面试五年模拟》系列将陪伴大家度过整个AI行业的职业生涯,并且让大家能够持续获益。
So,enjoy(与本文的BGM一起食用更佳哦):
正文开始
目录先行
AI绘画基础:
-
介绍一下DiT模型的基本概念
-
DiT输入图像的Patch化过程是什么样的?
AI视频基础:
-
AI视频经典的工作流有哪些?
-
CogVideoX-5B和CogVideoX-2B有哪些异同?
深度学习基础:
-
什么是SiLU激活函数?
-
什么是xavier初始化?
机器学习基础:
-
机器学习中数据增强的本质是什么?
-
机器学习中音频数据有哪些特点?
Python编程基础:
-
python中有哪些内建数据类型?
-
有哪些提高python运行效率的方法?
模型部署基础:
-
AI模型在端侧部署时有哪些维度需要考虑?
-
介绍一下xformers技术
计算机基础:
-
介绍一下计算机中“0.0.0.0”ip地址的意义
-
什么是计算机中的端口号?
开放性问题:
-
如何判断AI业务与AI算法解决方案在未来的价值?
-
AI产品和AI算法解决方案落地需要把握哪些核心关键?
AI绘画基础
【一】介绍一下DiT模型的基本概念
DiT(Diffusion Transformer)模型由Meta在2022年首次提出,其主要是在ViT(Vision Transformer)的架构上进行了优化设计得到的。DiT是基于Transformer架构的扩散模型,将扩散模型中经典的U-Net架构完全替换成了Transformer架构。
同时DiT是一个可扩展的架构,DiT不仅证明了Transformer思想与扩散模型结合的有效性,并且还验证了Transformer架构在扩散模型上具备较强的Scaling能力,在稳步增大DiT模型参数量与增强数据质量时,DiT的生成性能稳步提升。其中最大的DiT-XL/2模型在ImageNet 256x256的类别条件生成上达到了当时的SOTA(FID为2.27)性能。
DiT的整体框架并没有采用常规的Pixel Diffusion(像素扩散)架构,而是使用和Stable Diffusion相同的Latent Diffusion(潜变量扩散)架构。
为了获得图像的Latent Feature,所以DiT使用了和SD一样的VAE(基于KL-f8)模型。当我们输入512x512x3的图像时,通过VAE能够压缩生成64x64x4分辨率的Latent特征,这极大地降低了扩散模型的计算复杂度(减少Transformer的token的数量)。
同时,DiT扩散过程的nosie scheduler采用简单的Linear scheduler(timesteps=1000,beta_start=0.0001,beta_end=0.02),这与SD模型是不同的。在SD模型中,所采用的noise scheduler通常是Scaled Linear scheduler。
【二】DiT输入图像的Patch化过程是什么样的?
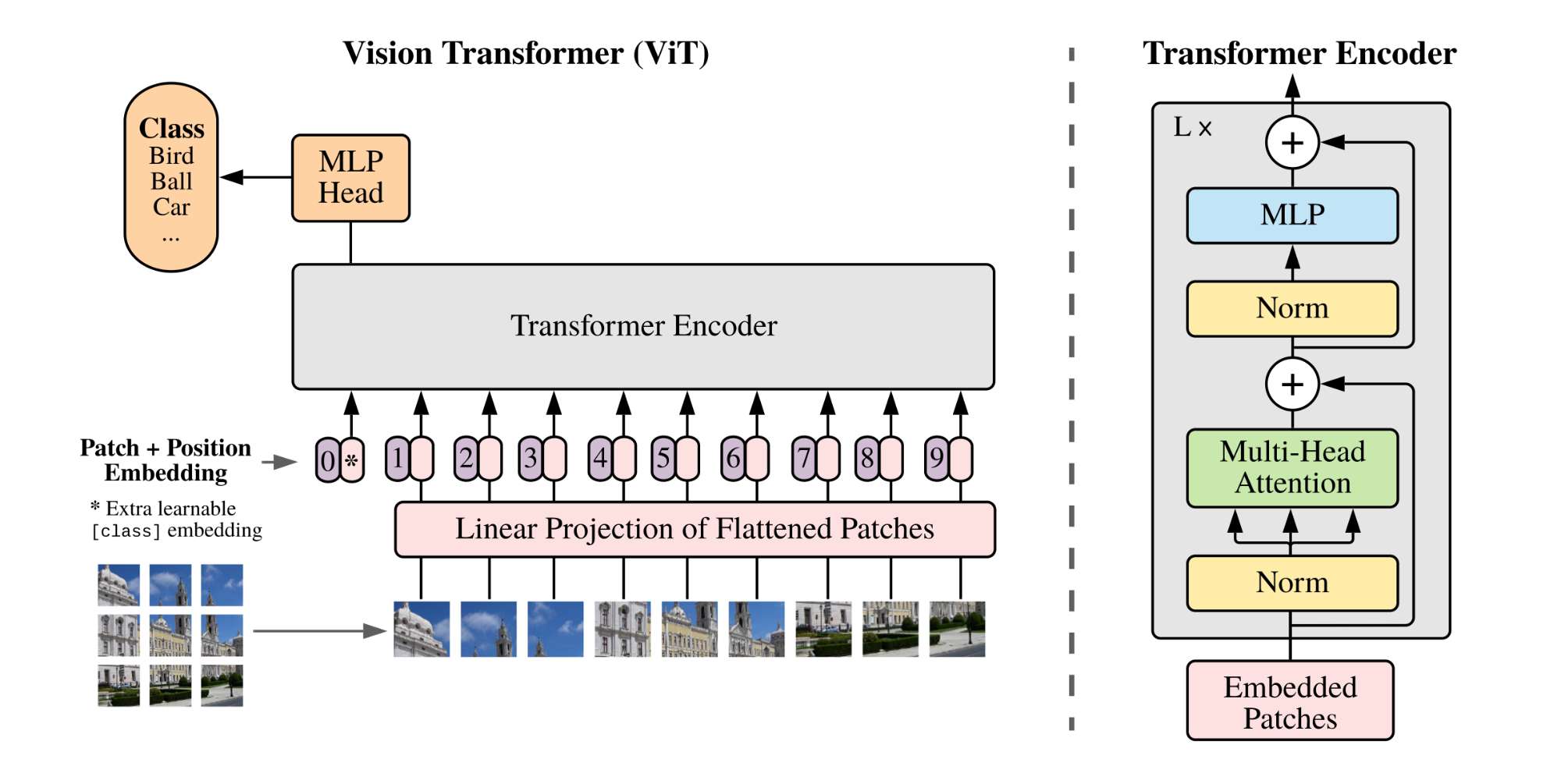
DiT和ViT一样,首先采用一个Patch Embedding来将输入图像Patch化,主要作用是将VAE编码后的二维特征转化为一维序列,从而得到一系列的图像tokens,具体如下图所示:
同时,DiT在这个图像Patch化的过程中,设计了patch size这个超参数,它直接决定了图像tokens的大小和数量,从而影响DiT模型的整体计算量。DiT论文中共设置了三种patch size,分别是
p
=
2
,
4
,
8
p = 2,4,8
p=2,4,8 。同时和其他Transformers模型一样,在得到图像tokens后,还要加上Positional Embeddings进行位置标记,DiT中采用经典的非学习sin&cosine位置编码技术。具体流程如下图所示:
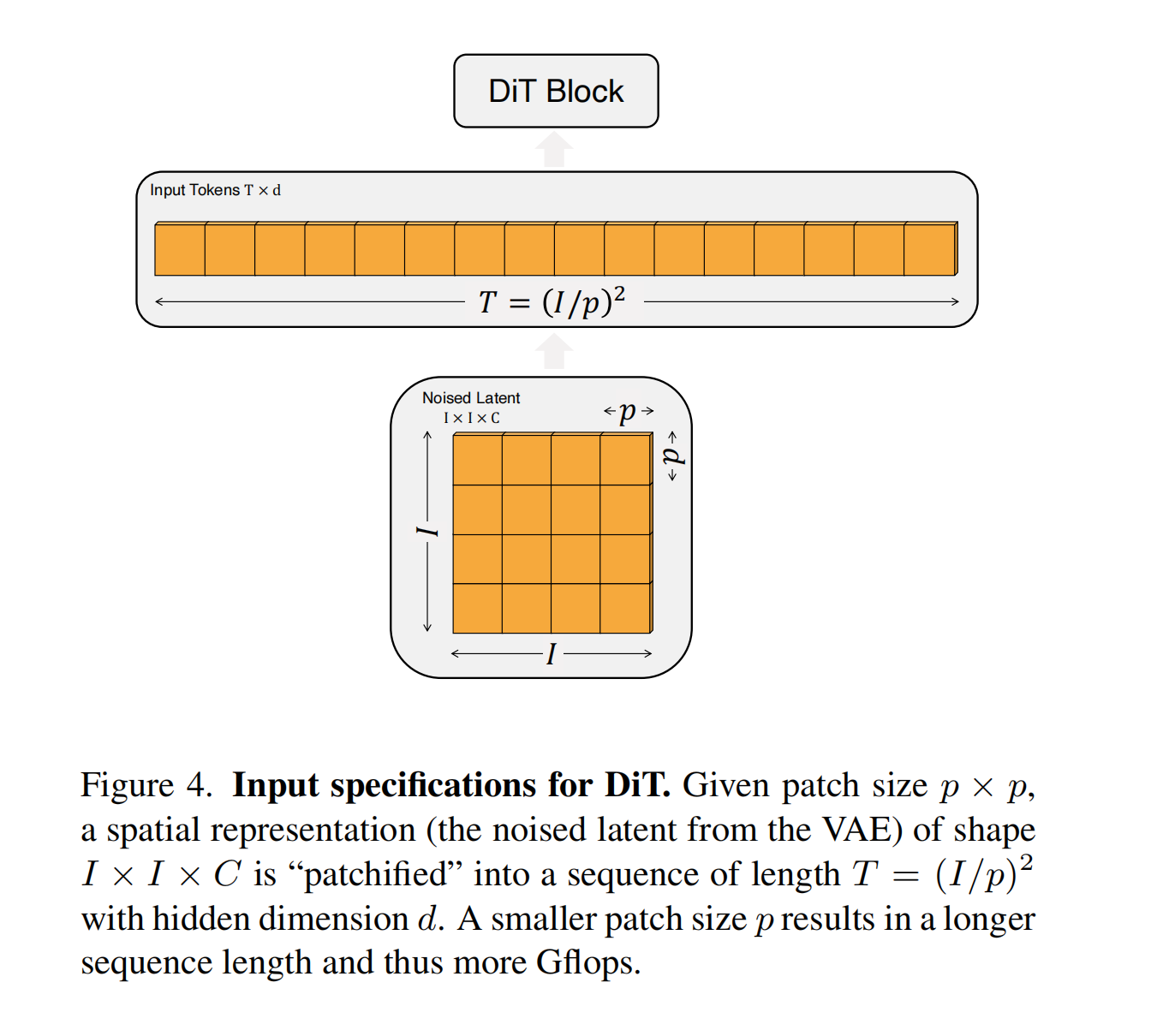
输入图像在经过VAE编码器处理后,生成一个Latent特征,我们假设其尺寸为 I × I × C I \times I \times C I×I×C,其中 I I I 是Latent特征的宽度或高度, C C C 是Latent特征的通道数。
接下来,用我们设定的patch size来将Latent特征进行Patch化,假设我们设定 p = 16 p = 16 p=16 ,那么这时每个patch的尺寸为 p × p p \times p p×p 。
由于Latent特征的尺寸是 I × I I \times I I×I ,因此在宽度和高度方向可以分别划分出 I P \frac{I}{P} PI 个patch。因此,整个Latent特征可以被分成 I P \frac{I}{P} PI 个patch。
最后我们将生成的每个尺寸为 p × p p \times p p×p 的patch展平(flatten)成一个向量,其尺寸为 [ 1 , p × p × C ] [1,p\times p\times C] [1,p×p×C] ,这些向量就构成了DiT模型的输入tokens,总的来说,生成的token数量为:
T = ( I p ) 2 T = \left(\frac{I}{p}\right)^2 T=(pI)2
同时每个token的维度为 d d d ,这是DiT输入的Latent空间维度。
如果我们设置的patch大小较小,那么生成的tokens数量就会较多,这时DiT的输入序列长度会变长,这会增加整体的计算复杂度。
AI视频基础
【一】AI视频经典的工作流有哪些?
本问答Rocky将根据AI视频领域的发展阶段持续更新,将最有价值的AI视频工作流分享给大家:
- 文生视频:可以使用Sora、可灵、CogVideoX + LoRA + ControlNet组成的工作流。
- 图生视频:可以使用SVD + LoRA + ControlNet组成的工作流。
- 视频编辑(视频生视频):AnimateDiff + LoRA + ControlNet组成的工作流。
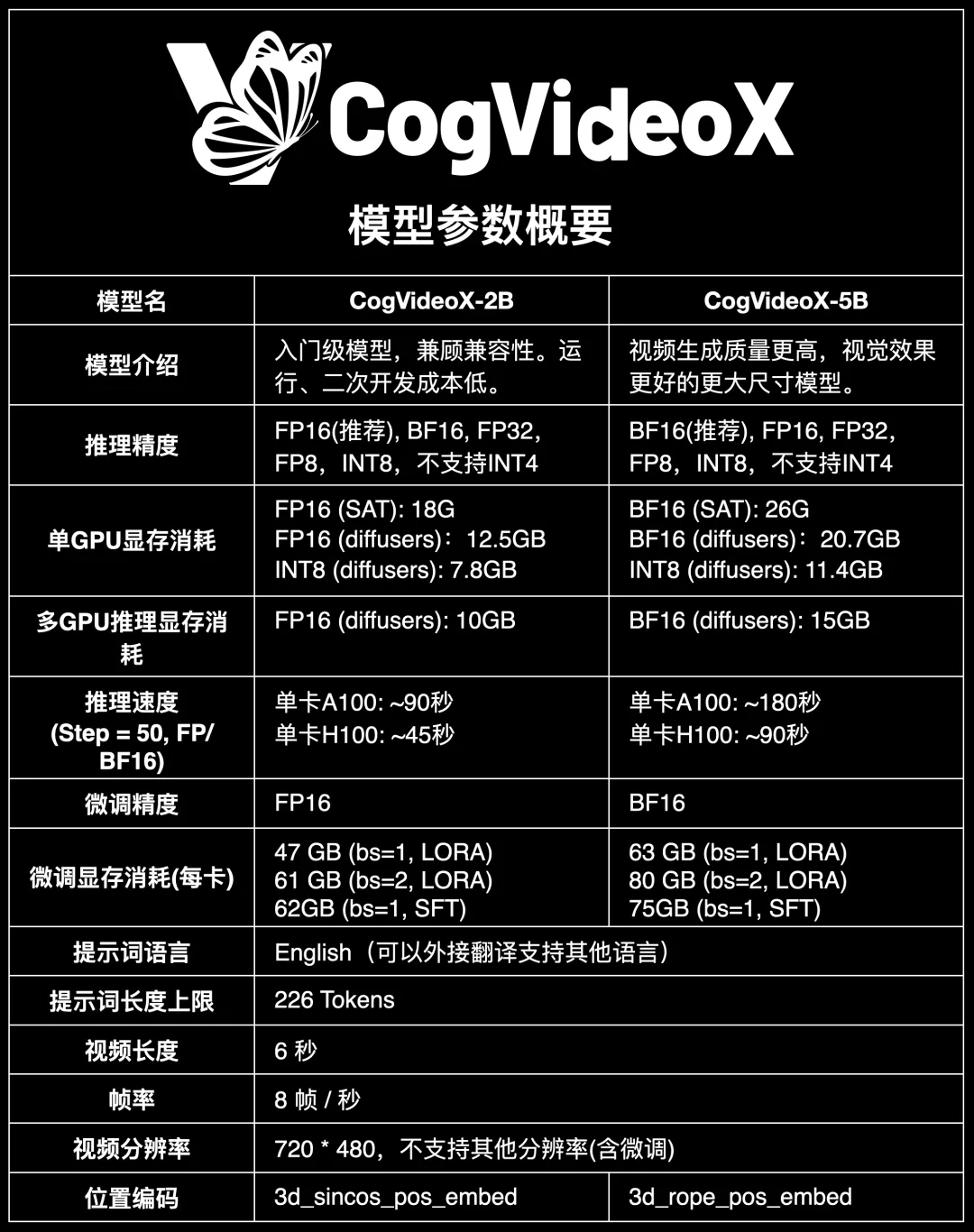
【二】CogVideoX-5B和CogVideoX-2B有哪些异同?
CogVideoX-5B模型是CogVideoX-2B模型的升级版本,CogVideoX-2B模型的特点是入门级模型,兼顾兼容性。运行、二次开发成本低。CogVideoX-5B模型的特点是视频生成质量更高,视觉效果更好,同时模型参数量也更大。
下面汇总了CogVideoX-5B模型和CogVideoX-2B模型的异同,供大家参考:
深度学习基础
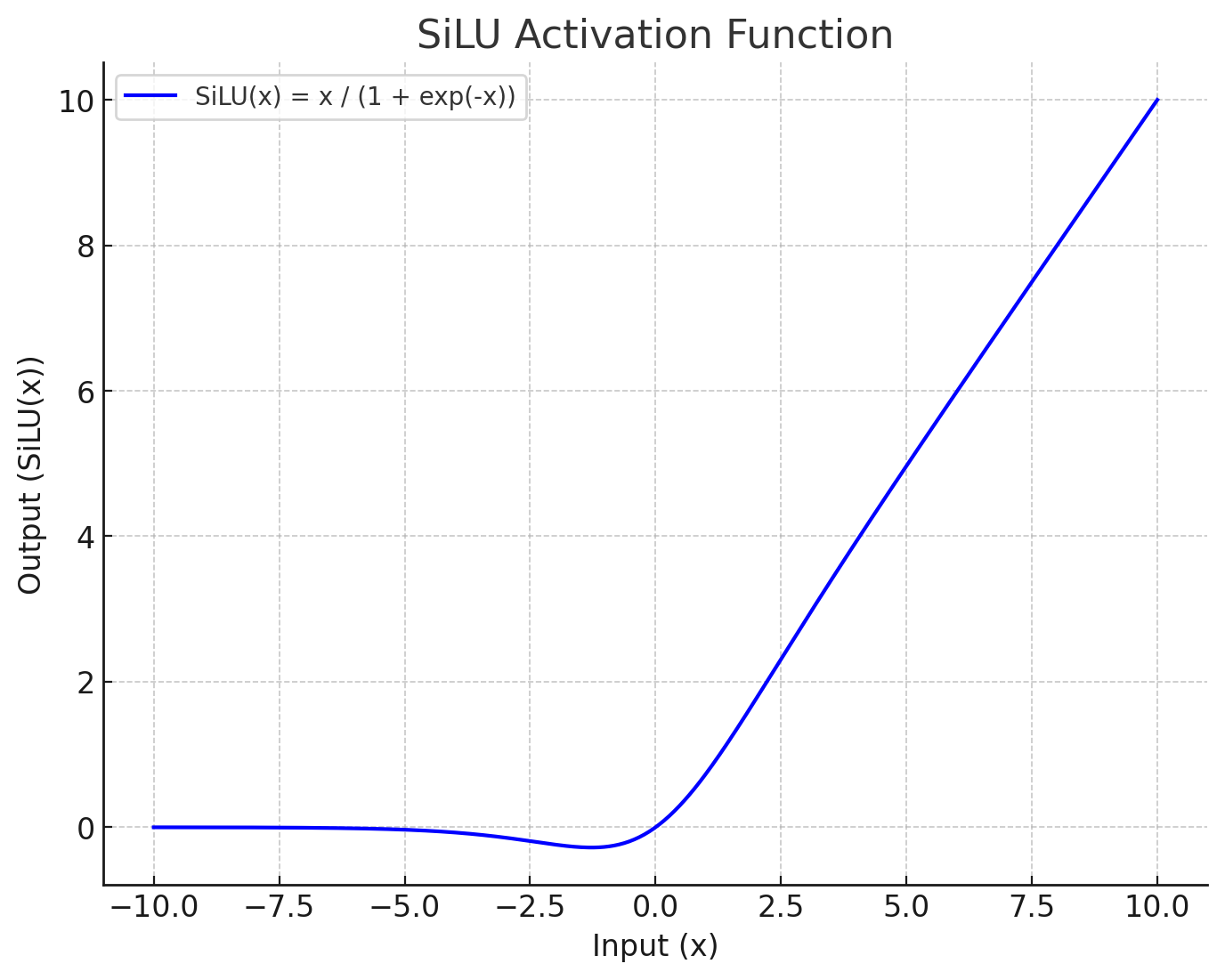
【一】什么是SiLU激活函数?
SiLU激活函数全称为 Sigmoid Linear Unit,是一种结合了线性和非线性特性的激活函数,也是Swish激活函数的一种特殊形式。它是一种非线性激活函数,用于神经网络的各层之间,以引入非线性,从而使神经网络能够学习更复杂的模式和特征。
SiLU 激活函数的定义
SiLU 函数的数学定义如下:
SiLU ( x ) = x ⋅ σ ( x ) \text{SiLU}(x) = x \cdot \sigma(x) SiLU(x)=x⋅σ(x)
其中:
- x x x 是输入张量。
- σ ( x ) \sigma(x) σ(x) 是输入的 Sigmoid 函数,即:
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
因此,SiLU 函数可以被表达为:
SiLU ( x ) = x 1 + e − x \text{SiLU}(x) = \frac{x}{1 + e^{-x}} SiLU(x)=1+e−xx
下面是SiLU激活函数的示意图:
SiLU 函数的特性
-
平滑性:SiLU 是一个平滑的函数,它不像 ReLU 那样在原点处有一个“拐角”,而是具有光滑的过渡,这对优化过程可能更有利。
-
非线性:SiLU 是非线性的,允许模型学习复杂的模式。这也是所有激活函数的核心属性。
-
无界性:SiLU 是无界的(即它的输出可以任意大),这与 ReLU 类似,但不同于 Sigmoid 或 Tanh 这类函数(它们的输出是有界的)。
-
有梯度消失的风险:虽然 SiLU 的输出范围是无界的,但对于负值输入,其输出接近零,因此在深度网络的训练中可能存在类似于 ReLU 的梯度消失问题,但通常比 ReLU 要好一些,因为它的负值部分并不是完全归零,而是有少量的负梯度。
SiLU 与其他激活函数相比的优势
-
与 ReLU 的比较:ReLU 函数(即 ReLU ( x ) = max ( 0 , x ) \text{ReLU}(x) = \max(0, x) ReLU(x)=max(0,x) )在负值时输出为零,而 SiLU 在负值时输出为负,但仍保留了一定的梯度,这在某些情况下可以改进梯度流动的问题。
-
与 Sigmoid 的比较:Sigmoid 函数输出值在 0 到 1 之间,而 SiLU 保持了输入的线性部分,因此在正值范围内表现出更大的动态范围。
-
与 Swish 的关系:SiLU 实际上就是 Swish 函数的一个特殊形式。Swish 函数通常被定义为 Swish ( x ) = x ⋅ σ ( β x ) \text{Swish}(x) = x \cdot \sigma(\beta x) Swish(x)=x⋅σ(βx) ,其中 β \beta β 是一个可调参数。当 β = 1 \beta = 1 β=1 时,Swish 就变成了 SiLU。
【二】什么是xavier初始化?
Xavier初始化(也称为Glorot初始化)是深度学习中用于神经网络权重初始化的一种方法,它在训练深层神经网络时非常重要,尤其是为了避免梯度消失或梯度爆炸问题。Xavier初始化通过设置权重,使得网络层的输入和输出的方差保持一致,从而稳定梯度的传播。
在深度神经网络中,如果权重初始化得不当,随着网络的层数增加,可能会出现梯度消失(vanishing gradient)和梯度爆炸(exploding gradient)的问题。
1. Xavier 初始化的原理
Xavier初始化的核心思想是保持网络中的输入和输出的方差相等,以此来稳定梯度的传播。它假设激活函数是线性的,且每一层的输入和输出分布应该保持相似。
具体来说,设某一层有 n in n_{\text{in}} nin 个输入神经元和 n out n_{\text{out}} nout 个输出神经元,Xavier 初始化会将权重 W W W 初始化为满足以下分布:
- 均匀分布:权重从一个均匀分布中采样,其范围为:
W ∼ U ( − 1 n in , 1 n in ) W \sim \mathcal{U}\left(-\frac{1}{\sqrt{n_{\text{in}}}}, \frac{1}{\sqrt{n_{\text{in}}}}\right) W∼U(−nin1,nin1)
- 正态分布:权重从一个均值为 0,标准差为 1 n in \frac{1}{\sqrt{n_{\text{in}}}} nin1 的正态分布中采样:
W ∼ N ( 0 , 1 n in ) W \sim \mathcal{N}\left(0, \frac{1}{n_{\text{in}}}\right) W∼N(0,nin1)
这种初始化方式保证了前向传播和反向传播时,梯度不会因为层数增加而出现消失或爆炸的情况。
2. Xavier 初始化的推导
在 Xavier 初始化中,目标是保持每一层输出的方差与输入的方差大致相同。假设:
- 输入 x x x 的方差为 Var ( x ) = σ x 2 \text{Var}(x) = \sigma_x^2 Var(x)=σx2
- 权重 W W W 的方差为 Var ( W ) = σ W 2 \text{Var}(W) = \sigma_W^2 Var(W)=σW2
在前向传播时,假设每层的输入 x x x 具有 n in n_{\text{in}} nin 个神经元,权重矩阵为 W W W ,那么输出 y y y 的方差应该满足以下条件:
Var ( y ) = n in ⋅ Var ( W ) ⋅ Var ( x ) \text{Var}(y) = n_{\text{in}} \cdot \text{Var}(W) \cdot \text{Var}(x) Var(y)=nin⋅Var(W)⋅Var(x)
为了防止参数权重的方差在传递过程中不断增大或减小,Xavier初始化的目标是让输出方差等于输入方差,即 Var ( y ) = Var ( x ) \text{Var}(y) = \text{Var}(x) Var(y)=Var(x) 。这样可以推导出权重初始化的条件:
n in ⋅ σ W 2 = 1 ⇒ σ W 2 = 1 n in n_{\text{in}} \cdot \sigma_W^2 = 1 \quad \Rightarrow \quad \sigma_W^2 = \frac{1}{n_{\text{in}}} nin⋅σW2=1⇒σW2=nin1
这解释了 Xavier 初始化为什么将权重的方差设置为 1 n in \frac{1}{n_{\text{in}}} nin1 。
3. Xavier 初始化的适用范围
Xavier 初始化适合用于激活函数是对称且线性或接近线性的情况,例如:
- 线性激活函数
- 双曲正切函数(tanh)
然而,当激活函数是 ReLU 或其变体(如 Leaky ReLU)时,由于这些激活函数的非线性性质,Xavier 初始化可能不太合适。这时,通常使用 He 初始化,它是 Xavier 初始化的变体,专门针对 ReLU 激活函数做了调整。
4. Xavier 初始化的改进:He 初始化
对于非对称的激活函数(例如 ReLU),Xavier 初始化的假设可能不再成立。He 初始化专门为这些激活函数设计,公式类似于 Xavier,但调整了方差的计算:
W ∼ N ( 0 , 2 n in ) W \sim \mathcal{N}(0, \frac{2}{n_{\text{in}}}) W∼N(0,nin2)
这种初始化方式能更好地保持梯度在深层网络中的传播。
机器学习基础
【一】机器学习中数据增强的本质是什么?
在AI行业中,不管是AIGC、传统深度学习还是自动驾驶领域,数据增强都是一个非常重要的技术手段。
数据增强通过扩展训练数据集的数量,让训练数据分布逼近真实的细分领域数据分布。举个例子,比如说我们要检测识别花卉种类,那么我们的训练数据集要尽可能包含真实世界的所有花卉,还要考虑到他们的所处的环境干扰。在这里花卉就是一个细分领域,是我们需要使用数据增强技术进行逼近的分布。
更宽泛的来讲,未来的AGI时代,AGI模型需要知晓真实世界的所有数据分布,那么这时训练数据集就要逼近真实世界的所有分布。
实际效果上看,通过数据增强技术,从而丰富AI模型学习的特征空间,能够提高AI模型的泛化性和鲁棒性。
【二】机器学习中音频数据有哪些特点?
在机器学习中,音频数据具有一些独特的特点,了解这些特点有助于我们设计更有效的算法和模型:
1. 时序性 (Temporal Nature)
音频信号是一种典型的时序数据,随着时间变化而变化。这意味着音频数据中的每个样本都是时间序列的一部分,音频数据的处理需要考虑时间的连续性。时间维度的存在使得音频数据不同于普通的静态数据,分析音频时,必须理解每个时间点的声音如何与上下文相关联。我们可以使用 RNN(循环神经网络)、LSTM 或者 Transformer 模型来处理音频时序性。
2. 频率特性 (Frequency Characteristics)
音频信号的频率特征反映了其波动的快慢。声音可以分解为不同的频率分量,每个频率对应不同的音调。频率特性是音频信号的关键特征之一,可以通过傅里叶变换或小波变换将音频数据从时域转换到频域,来捕捉其中的频率信息。
3. 非平稳性 (Non-Stationarity)
音频信号通常是非平稳的,即音频信号的统计特性(如均值和方差)会随时间变化。例如,语音信号中的不同语音片段对应不同的频率和能量分布。为了更好地处理这种非平稳性,音频信号通常被分割成多个短时间窗口,每个窗口假设为平稳信号。我们可以使用短时傅里叶变换 (STFT) 等特征提取方法可以帮助分析音频的非平稳性。
4. 高维度 (High Dimensionality)
原始音频数据(如采样后的波形)往往具有非常高的维度。以 CD 质量音频为例,采样率为 44.1kHz,这意味着每秒音频需要处理 44,100 个采样点。对于长时间音频或高采样率音频,维度极高,处理起来非常耗时且复杂。我们可以使用降维方法,如 MFCC 或频谱图,可以从高维音频数据中提取重要特征,减少计算开销。
5. 噪声敏感性 (Noise Sensitivity)
音频数据通常会受到噪声的影响,包括环境噪声、麦克风噪声和其他干扰信号。噪声会对音频的质量和特征提取过程产生负面影响。因此,处理音频数据时,通常需要进行降噪或噪声处理,我们可以使用降噪技术包括自回归模型、维纳滤波、神经网络降噪方法等。
6. 多模态特性 (Multimodal Nature)
音频信号往往与其他模态(如文本、视频等)相关联。例如,语音数据通常可以与文本数据配对,用于语音识别或自然语言处理任务。在多模态学习中,音频信号是一个重要的输入信号。
7. 周期性 (Periodicity)
音频信号(尤其是音乐信号)往往表现出一定的周期性。例如,音调、节奏、乐器的声音等具有固定的频率和重复的结构。这种周期性特征是音频处理中的重要信息。通过频域分析可以提取音频信号的周期特征,如音高检测和节奏分析。
8. 能量分布 (Energy Distribution)
音频信号的能量分布能够反映声音的强弱,语音信号中的不同片段可能具有不同的能量。常见的音频特征如谱图能量可以帮助分析音频信号中的不同部分,能量的变化有时可以用于检测音频的起始或终止点。
9. 阶段性 (Phases)
音频信号除了频率和幅度之外,还包含相位信息。相位描述了信号在特定时间点的周期性波动的开始和结束位置。在某些应用中,如音乐生成或音频修复,相位信息是关键的,但在特征提取时,通常主要关注频率和幅度特征,相位信息可以忽略。
10. 心理声学 (Psychoacoustics)
由于人耳对不同频率的声音有不同的敏感性,音频数据中的一些高频或低频成分可能并不重要。在音频处理中,通常会使用类似于梅尔刻度的频率变换来模拟人耳的听觉感知。
11. 时频域联合特性 (Time-Frequency Joint Representation)
为了同时捕获音频的时间和频率特性,通常会采用时频分析工具,如短时傅里叶变换 (STFT)、梅尔谱图或连续小波变换 (CWT),这些工具能够同时展示音频信号在时间和频率上的变化。
Python编程基础
【一】python中有哪些内建数据类型?
Python的内建数据类型分为几大类,每一类包含不同的具体数据类型,主要包括:
1. None 类型
NoneType:None是一个特殊的常量,表示空值或无值的对象。用于表示缺少值或空对象。
2. 数值类型
- 整数(int): 表示整数类型,可以是正数、负数或者零。例如:
42,-5,0。 - 浮点数(float): 表示带小数点的数字。例如:
3.14,-0.001。 - 复数(complex): 表示复数,由实部和虚部组成,例如:
3 + 4j。
3. 序列类型
- 字符串(str): 用于存储文本,使用单引号或双引号定义,例如:
'hello'或"world"。 - 列表(list): 有序且可变的序列,可以包含不同类型的元素,例如:
[1, 'apple', 3.14]。 - 元组(tuple): 有序且不可变的序列,可以包含不同类型的元素,例如:
(1, 'apple', 3.14)。 - 范围(range): 表示一系列数字,常用于循环中,例如:
range(0, 10)。
4. 集合类型
- 集合(set): 无序且不重复的元素集合,例如:
{1, 2, 3}。 - 冻结集合(frozenset): 不可变的集合,元素不能被修改,例如:
frozenset([1, 2, 3])。
5. 映射类型
- 字典(dict): 存储键值对的无序集合,键是唯一的,例如:
{'name': 'Alice', 'age': 25}。
6. 布尔类型
- 布尔值(bool): 只有两个值
True和False,表示布尔真值。
7. 二进制类型
- 字节(bytes): 不可变的字节序列,用于处理二进制数据,例如:
b'hello'。 - 字节数组(bytearray): 可变的字节序列,例如:
bytearray(b'hello')。 - 内存视图(memoryview): 提供对其他二进制数据类型的访问,例如:
memoryview(b'hello')。
8. 特殊类型
- 可调用对象(callable): 可以被调用的对象,如函数、方法、类等。
Python 内建数据类型示例
# None
none_type = None
# 数值类型
integer = 10
floating_point = 3.14
complex_number = 2 + 3j
# 序列类型
string = "hello"
list_type = [1, 2, 3]
tuple_type = (1, 2, 3)
range_type = range(5)
# 集合类型
set_type = {1, 2, 3}
frozenset_type = frozenset([1, 2, 3])
# 映射类型
dict_type = {'key': 'value'}
# 布尔类型
boolean = True
# 二进制类型
bytes_type = b'hello'
bytearray_type = bytearray(b'hello')
memoryview_type = memoryview(b'hello')
【二】有哪些提高python运行效率的方法?
一. 优化代码结构
1. 使用高效的数据结构和算法
- 选择合适的数据结构:根据需求选择最佳的数据结构。例如,使用
set或dict进行元素查找,比使用list更快。 - 优化算法:使用更高效的算法降低时间复杂度。例如,避免在循环中进行昂贵的操作,使用快速排序算法等。
2. 减少不必要的计算
- 缓存结果:使用
functools.lru_cache或自行实现缓存,避免重复计算相同的结果。 - 懒加载:延迟加载数据或资源,减少启动时的开销。
3. 优化循环
-
列表解析:使用列表解析或生成器表达式替代传统循环,代码更简洁,执行速度更快。
# 传统循环 result = [] for i in range(1000): result.append(i * 2) # 列表解析 result = [i * 2 for i in range(1000)] -
避免过深的嵌套:简化嵌套循环,减少循环次数。
4. 使用生成器
-
节省内存:生成器按需生成数据,适用于处理大型数据集。
def generate_numbers(n): for i in range(n): yield i
二、利用高性能的库和工具
1. NumPy和Pandas
- NumPy:用于高效的数值计算,底层由C语言实现,支持向量化操作。
- Pandas:提供高性能的数据结构和数据分析工具。
2. 使用Cython
-
Cython:将Python代码编译为C语言扩展,显著提高计算密集型任务的性能。
# 使用Cython编写的示例函数 cpdef int add(int a, int b): return a + b
3. JIT编译器
- PyPy:一个支持JIT编译的Python解释器,能自动优化代码执行。
- Numba:为NumPy提供JIT编译,加速数值计算。
4. 多线程和多进程
- 多线程:适用于I/O密集型任务,但受限于全局解释器锁(GIL),对CPU密集型任务效果不佳。
- 多进程:使用
multiprocessing模块,适用于CPU密集型任务,能充分利用多核CPU。
5. 异步编程
-
asyncio:用于编写异步I/O操作,适合处理高并发任务。
import asyncio async def fetch_data(): # 异步I/O操作 pass
三、性能分析和监控
1. 使用性能分析工具
-
cProfile:标准库中的性能分析器,帮助找出程序的性能瓶颈。
python -m cProfile -o output.prof WeThinkIn_script.py -
line_profiler:逐行分析代码性能,需要额外安装。
2. 内存分析
- memory_profiler:监控内存使用情况,优化内存占用。
四、优化代码实践
1. 避免全局变量
- 使用局部变量:局部变量访问速度更快,能提高函数执行效率。
2. 减少属性访问
- 缓存属性值:将频繁访问的属性值缓存到局部变量,减少属性查找时间。
3. 字符串连接
-
使用
join方法:连接多个字符串时,''.join(list_of_strings)比使用+号效率更高。# 效率较低 result = '' for s in list_of_strings: result += s # 效率较高 result = ''.join(list_of_strings)
4. 合理使用异常
- 避免过度使用异常处理:异常处理会带来额外的开销,应在必要时使用。
五、核心思想总结
我们在这里做一个总结,想要提高Python运行效率需要综合考虑代码优化、工具使用等多个方面。以下是关键步骤:
- 性能分析:首先使用工具找出性能瓶颈,避免盲目优化。
- 代码改进:通过优化算法、数据结构和代码实践,提高代码效率。
- 利用高性能库:使用如NumPy、Cython等库,加速计算密集型任务。
- 并行和异步:根据任务类型,选择多线程、多进程或异步编程。
通过以上方法,我们可以在保持代码可读性的同时,大幅提高Python程序的运行效率。
模型部署基础
【一】AI模型在端侧部署时有哪些维度需要考虑?
不管是AIGC、传统深度学习还是自动驾驶领域,我们对AI模型进行端侧部署时,都需要从以下几个大的维度进行通盘考虑,这样才能对AI模型部署的成本与周期有所掌握:
- 模型压缩技术:为了实现高效的端侧部署,模型压缩技术至关重要。核心技术包括量化(Quantization)、剪枝(Pruning)、模型蒸馏(Knowledge Distillation)、高效模型架构设计、分块执行(Tiling Execution)等。
- 硬件加速技术:端侧设备通常配备有限的计算资源,因此充分利用设备的硬件加速能力尤为重要。硬件加速核心技术包括使用GPU加速、使用NPU(Neural Processing Unit)加速、使用FPGA和ASIC加速等。
- 推理优化框架技术:为了实现高效的推理,AI绘画模型的部署需要依赖一些经过优化的推理框架,这些框架能够针对不同硬件平台和操作系统进行优化。推理优化框架的核心技术包括:TensorFlow Lite、ONNX Runtime、PyTorch Mobile、MNN等。
- 跨平台支持技术:端侧部署的一个重要技术挑战是如何实现不同设备和操作系统上的兼容性。AI模型需要在Android、iOS、Linux等多个平台上运行,保证模型的跨平台一致性。跨平台支持核心技术包括:模型转换工具、多平台编译和适配、设备检测和动态加载等。
【二】介绍一下xformers技术
Xformers 技术原理概述
Xformers 是 Meta 开发的一个高效、模块化的深度学习库,专注于优化 Transformer 架构的性能。Xformers 提供了对 Transformer 组件的多种加速技术,当模型规模庞大时,它能够显著提高训练速度和降低显存占用,特别是在资源受限的环境下(如嵌入式设备、移动设备)。随着 Transformer 架构的不断普及,Xformers 将继续在 AIGC 、传统深度学习以及自动驾驶领域中扮演重要角色。
1. Xformers 的背景与目标
Transformer 模型在自然语言处理(NLP)和计算机视觉(CV)任务中已经取得了巨大的成功,但随着模型规模的扩大,其巨大的计算开销和显存需求成为了模型部署中的瓶颈。Xformers的核心目标是:
- 降低显存消耗:通过高效的注意力机制和其他模块优化来减少计算资源的占用。
- 提高计算效率:在不损失性能的前提下,加速模型训练和推理的过程。
- 模块化与可扩展性:提供易于集成的模块,便于用户按需组合和优化模型。
2. Xformers 的技术原理
2.1 Sparse Attention(稀疏注意力)
Transformer 模型的主要瓶颈之一是自注意力机制的计算复杂度,标准的全连接注意力(Full Attention)在序列长度为 N N N 的情况下,其计算复杂度为 O ( N 2 ) O(N^2) O(N2) 。这对于长序列任务,如机器翻译或长文本生成任务,代价非常高。
Xformers 提供了稀疏注意力机制,即通过减少不必要的查询-键值对(Query-Key pairs)的计算来降低复杂度,通常可以将计算复杂度降至 O ( N log N ) O(N \log N) O(NlogN) 或 O ( N ) O(N) O(N) :
- 局部注意力(Local Attention):仅计算局部范围内的注意力权重,而忽略远程依赖关系。
- 因式分解注意力(Factorized Attention):将注意力计算分解为更小的矩阵运算,降低计算需求。
2.2 Memory-Efficient Attention(显存高效的注意力机制)
Transformer 模型的另一个重要问题是其显著的显存占用。标准的注意力机制需要为整个输入序列保留注意力矩阵(即 Query-Key 和 Value 之间的所有匹配),这会占用大量显存。
Xformers 引入了内存高效注意力(Memory-Efficient Attention)机制,即只在需要时计算注意力权重和中间值,而不保留整个矩阵。这可以通过逐步计算的方式实现,将显存占用从原先的 O ( N 2 ) O(N^2) O(N2) 降低到 O ( N ) O(N) O(N) ,在不影响准确率的情况下大幅减少显存开销。
2.3 Block-Sparse Attention
在一些应用中(例如图像生成任务),并不需要全局范围的注意力,某些位置的交互作用可以忽略。因此,Xformers 提供了 Block-Sparse Attention,它通过在稀疏矩阵中定义固定的稀疏模式来降低计算复杂度。这种方法特别适用于图像处理任务,例如使用块级操作来计算注意力。
- 局部窗口:例如在图像生成任务中,注意力只在局部窗口内进行计算,可以跳过与远距离像素的注意力交互,从而减少计算负担。
- 灵活性与可定制性:Block-Sparse Attention 的稀疏模式可以根据具体任务灵活定义,提供了更多的自定义选项。
2.4 Flash Attention
Xformers 引入了 Flash Attention 技术,进一步优化了注意力机制的性能。Flash Attention 通过将注意力的计算与显存优化结合,允许在 GPU 上高效执行注意力操作。它可以通过在低精度硬件(如混合精度训练)中使用时,进一步提升计算效率。
3. Xformers 在实际应用中的优势
3.1 更快的训练速度
通过使用稀疏注意力和内存高效注意力,Xformers 可以显著减少训练时间。在处理长序列任务时,Xformers 的优化能将训练时间减少 50% 以上,同时保持相似的性能。这对于需要快速迭代的大规模模型训练尤其重要。
3.2 显存占用大幅减少
Xformers 的稀疏注意力机制和内存优化技术,使得显存占用可以减少一半以上。特别是在使用大型模型时,显存的节省能够使得相同的硬件资源可以训练更大的模型或处理更长的输入序列。
3.3 广泛的应用领域
Xformers 不仅适用于 NLP 任务,也被广泛应用于计算机视觉、图像生成、时间序列预测等多种任务中。它的灵活性使其能够适配多种 Transformer 架构(如 Vision Transformers、BERT、GPT 等)。
计算机基础
Rocky从工业界、应用界、竞赛界以及学术界角度出发,总结沉淀AI行业中需要用到的实用计算机基础知识,不仅能在面试中帮助到我们,还能让我们在日常工作中提高效率。
【一】介绍一下计算机中“0.0.0.0”ip地址的意义
在计算机网络中,0.0.0.0 是一个特殊的 IP 地址,具有多种用途,取决于具体使用场景。它并不指向任何特定的设备,而是用来表示 “所有 IP 地址” 或 “没有指定的地址”。下面是 0.0.0.0 在不同情况下的含义和用途:
1. 表示所有可用的 IPv4 地址
当 0.0.0.0 被用在服务器或服务监听时,它表示该服务会监听设备上所有可用的网络接口。这是最常见的用途。
使用场景:
-
服务监听:例如,在 Web 服务器中,如果服务器绑定到
0.0.0.0,那么该服务将监听所有可用的网络接口。这意味着无论你通过哪一个网络接口的 IP 地址访问(例如localhost、局域网 IP 或公网 IP),服务器都会接受连接。示例:
http://0.0.0.0:8080表示服务器在端口 8080 上监听所有接口。你可以通过localhost:8080或设备的局域网 IP 访问它。
解释:
- 在网络接口上,有多个可能的地址,例如本地回环地址
127.0.0.1,或设备的实际 IP 地址(例如192.168.1.100)。0.0.0.0作为绑定地址时,意味着服务会监听这些所有的地址,不管请求是从哪一个网络接口进入的。
2. 表示一个未指定的地址
当一个设备或网络配置为 0.0.0.0 时,意味着该设备或网络接口目前没有被分配具体的 IP 地址,或者还没有获得一个有效的 IP 地址。
使用场景:
- DHCP 客户端请求:当一个设备通过 DHCP(动态主机配置协议)请求 IP 地址时,它会使用
0.0.0.0作为自己的源地址,因为在这个阶段,它还没有被分配一个实际的 IP 地址。
解释:
- 在 DHCP 请求阶段,设备还没有获取到合法的 IP 地址,因此会暂时使用
0.0.0.0来表示自己。
3. 默认路由
在路由表中,0.0.0.0/0 通常表示默认路由。它告诉操作系统,当无法通过更具体的路由找到目的地时,将流量发往默认网关。
使用场景:
- 网络路由表:例如,在路由器或计算机的网络路由表中,
0.0.0.0/0表示匹配所有未明确路由的流量。默认路由通常会指向外部网关(如互联网的路由器),从而将流量引向更大的网络(例如互联网)。
解释:
- 如果一个数据包的目标地址没有匹配到任何其他更具体的路由条目,则
0.0.0.0默认路由会将它发送到预定义的网关进行进一步的路由。
4. 表示无效或未知的源地址
在某些情况下,0.0.0.0 也可以表示一个无效的源地址,即设备在某种状态下不清楚自己的 IP 地址,或故意不设置源地址(例如测试或调试的目的)。
【二】什么是计算机中的端口号?
端口号在计算机网络中起着至关重要的作用,它用于区分同一主机上的多个网络服务。每当我们通过网络进行通信时,除了 IP 地址来标识主机之外,还需要使用端口号来标识特定的应用程序或服务。这可以帮助计算机在处理多个网络连接时,将数据发送到正确的进程。
1. 端口号的定义
端口号是一个 16 位的整数,范围是从 0 到 65535。每个端口号都可以用来标识一个特定的进程或网络服务。
- IP 地址 用于定位网络中的主机或设备。
- 端口号 用于定位主机上的具体服务或应用程序。
2. 端口号的分类
端口号根据其范围通常被划分为三类:
-
知名端口(Well-known Ports):0 - 1023
- 这些端口号通常被分配给一些常见的、标准的服务和协议。例如:
- 80:HTTP(网页浏览)
- 443:HTTPS(安全网页浏览)
- 22:SSH(安全外壳协议,用于远程登录)
- 25:SMTP(简单邮件传输协议,用于发送邮件)
- 这些端口号由互联网号码分配局(IANA)正式分配和管理。
- 这些端口号通常被分配给一些常见的、标准的服务和协议。例如:
-
注册端口(Registered Ports):1024 - 49151
- 这些端口号用于为特定的用户应用程序和服务注册。通常用于不需要系统权限的应用程序。例如:
- 3306:MySQL 数据库
- 5432:PostgreSQL 数据库
- 8080:HTTP 的替代端口,常用于开发和测试环境
- 这些端口号用于为特定的用户应用程序和服务注册。通常用于不需要系统权限的应用程序。例如:
-
动态或私有端口(Dynamic/Private Ports):49152 - 65535
- 这些端口号没有固定的分配,通常用于客户端应用程序与服务器建立短暂的通信。在通信结束后,端口号会被释放。例如:
- 当你通过浏览器访问网页时,浏览器会临时分配一个动态端口(例如 52345),用于与网页服务器通信。
- 这些端口号没有固定的分配,通常用于客户端应用程序与服务器建立短暂的通信。在通信结束后,端口号会被释放。例如:
3. 端口的工作原理
在计算机网络通信中,**传输层协议(TCP 和 UDP)**会利用端口号来标识发送方和接收方的具体应用程序或服务。
- TCP(传输控制协议)端口:面向连接,提供可靠的数据传输。常用于需要高可靠性的服务,如 HTTP、HTTPS、FTP 等。
- UDP(用户数据报协议)端口:面向无连接,不提供数据重传。适合实时通信或容忍少量数据丢失的应用程序,如视频流、在线游戏等。
当数据通过网络传输时,报文会携带两个端口号:
- 源端口号:表示发起通信的应用程序的端口号。
- 目标端口号:表示接收方应用程序监听的端口号。
例如:
- 当我们使用浏览器访问网页时,浏览器会使用一个动态源端口号(如 52345)与网页服务器的目标端口号(如 80,用于 HTTP)通信。
4. 常见端口号列表
以下是一些常见服务的端口号:
| 协议/服务 | 默认端口号 |
|---|---|
| HTTP | 80 |
| HTTPS | 443 |
| FTP | 21 |
| SSH | 22 |
| SMTP | 25 |
| DNS | 53 |
| MySQL | 3306 |
| PostgreSQL | 5432 |
开放性问题
Rocky从工业界、应用界、竞赛界以及学术界角度出发,思考总结AI行业的一些开放性问题,这些问题不仅能够用于面试官的提问,也可以用作面试者的提问,在面试的最后阶段让面试双方进入更深入的探讨与交流。
与此同时,这些开放性问题也是贯穿我们职业生涯的本质问题,需要我们持续的思考感悟。这些问题没有标准答案,Rocky相信大家心中都有自己对于AI行业的认知与判断,欢迎大家在留言区分享与评论。
【一】如何判断AI业务与AI算法解决方案在未来的价值?
Rocky认为这是一个非常有价值的问题,我们不管是在AI业务和AI算法解决方案的启动前、进行中还是完成后,都需要对其未来的发展进行判断与评估,才能获取本质洞察。
【二】AI产品和AI算法解决方案落地需要把握哪些核心关键?
Rocky认为这是一个非常有价值的问题,只有从每个AI产品和AI算法解决方案的落地过程中持续思考沉淀,才能获取对AI行业的本质洞察。
推荐阅读
1、加入AIGCmagic社区知识星球
AIGCmagic社区知识星球不同于市面上其他的AI知识星球,AIGCmagic社区知识星球是国内首个以AIGC全栈技术与商业变现为主线的学习交流平台,涉及AI绘画、AI视频、ChatGPT等大模型、AI多模态、数字人、全行业AIGC赋能等50+应用方向,内部包含海量学习资源、专业问答、前沿资讯、内推招聘、AIGC模型、AIGC数据集和源码等。
那该如何加入星球呢?很简单,我们只需要扫下方的二维码即可。知识星球原价:299元/年,前200名限量活动价,终身优惠只需199元/年。大家只需要扫描下面的星球优惠卷即可享受初始居民的最大优惠:


2、Sora等AI视频大模型的核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用AI视频大模型,AI视频大模型性能测评,AI视频领域未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Sora等AI视频大模型文章地址:https://zhuanlan.zhihu.com/p/706722494
3、Stable Diffusion3和FLUX.1核心原理,核心基础知识,网络结构,从0到1搭建使用Stable Diffusion 3和FLUX.1进行AI绘画,从0到1上手使用Stable Diffusion 3和FLUX.1训练自己的AI绘画模型,Stable Diffusion 3和FLUX.1性能优化等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
Stable Diffusion 3和FLUX.1文章地址:https://zhuanlan.zhihu.com/p/684068402
4、Stable Diffusion XL核心基础知识,网络结构,从0到1搭建使用Stable Diffusion XL进行AI绘画,从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型,AI绘画领域的未来发展等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
Stable Diffusion XL文章地址:https://zhuanlan.zhihu.com/p/643420260
5、Stable DiffusionV1-V2核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用Stable Diffusion进行AI绘画,从0到1上手使用Stable Diffusion训练自己的AI绘画模型,Stable Diffusion性能优化等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
Stable Diffusion文章地址:https://zhuanlan.zhihu.com/p/632809634
6、ControlNet核心基础知识,核心网络结构,从0到1使用ControlNet进行AI绘画,从0到1上手构建ControlNet高级应用等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
ControlNet文章地址:https://zhuanlan.zhihu.com/p/660924126
7、LoRA系列模型核心基础知识,从0到1使用LoRA模型进行AI绘画,从0到1上手训练自己的LoRA模型,LoRA变体模型介绍,优质LoRA推荐等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
LoRA文章地址:https://zhuanlan.zhihu.com/p/639229126
8、最全面的AIGC面经《手把手教你成为AIGC算法工程师,斩获AIGC算法offer!(2024年版)》文章正式发布
码字不易,欢迎大家多多点赞:
AIGC面经文章地址:https://zhuanlan.zhihu.com/p/651076114
9、10万字大汇总《“三年面试五年模拟”之算法工程师的求职面试“独孤九剑”秘籍》文章正式发布
码字不易,欢迎大家多多点赞:
算法工程师三年面试五年模拟文章地址:https://zhuanlan.zhihu.com/p/545374303
《三年面试五年模拟》github项目地址(希望大家能给个star):https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer
10、Stable Diffusion WebUI、ComfyUI、Fooocus三大主流AI绘画框架核心知识,从0到1搭建AI绘画框架,从0到1使用AI绘画框架的保姆级教程,深入浅出介绍AI绘画框架的各模块功能,深入浅出介绍AI绘画框架的高阶用法等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
AI绘画框架文章地址:https://zhuanlan.zhihu.com/p/673439761
11、GAN网络核心基础知识、深入浅出解析GAN在AIGC时代的应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
GAN网络文章地址:https://zhuanlan.zhihu.com/p/663157306
12、其他
Rocky将YOLOv1-v7全系列大解析文章也制作成相应的pdf版本,大家可以关注公众号WeThinkIn,并在后台 【精华干货】菜单或者回复关键词“YOLO” 进行取用。
Rocky一直在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于技术话题的讨论与学习,包括但不限于算法,开发,竞赛,科研以及工作求职等。群里有很多人工智能行业的大牛,欢迎大家入群一起学习交流~(请添加小助手微信Jarvis8866,拉你进群~)