MATLAB系列08:输入/输入函数
- 8. 输入/输入函数
- 8.1 函数textread
- 8.2 关于load和save命令的进一步说明
- 8.3 MATLAB文件过程简介
- 8.4 文件的打开和关闭
- 8.4.1 fopen函数
- 8.4.2 fclose函数
- 8.5 二进制 I/O 函数
- 8.5.1 fwrite 函数
- 8.5.2 fread函数
- 8.6 格式化 I/O 函数
- 8.6.1 fprintf函数
- 8.6.2 格式转换指定符的理解
- 8.6.3 如何使用格式字符串
- 8.6.4 fscanf 函数
- 8.6.5 fgetl函数
- 8.6.6 fgets 函数
- 8.7 格式化和二进制 I/O 函数的比较
- 8.8 文件位置和状态函数
- 8.8.1 exist函数
- 8.8.2 函数ferror
- 8.8.3 函数foef
- 8.8.4 函数ftell
- 8.8.5 函数frewind
- 8.8.6 函数fseek
- 8.9 函数uiimport
- 8.10 总结
8. 输入/输入函数
8.1 函数textread
它可以按列读取 ascii 文件中的元素,每一列中可能含有不同的数据类型。这函数读取其他程序生成的数据表时非常地有用。
假设test_input.dat文件如下:
[first, last, blood, gpa, age, answer] =
textread('test_input.dat','%s %s %s %f %d %s')
读取命令和结果:
>> [first, last, blood, gpa, age, answer] =textread('test_input.dat','%s %s %s %f %d %s')
first =
2×1 cell 数组
{'James'}
{'Sally'}
last =
2×1 cell 数组
{'Jones'}
{'Smith'}
blood =
2×1 cell 数组
{'O+'}
{'A+'}
gpa =
3.5100
3.2800
age =
22
23
answer =
2×1 cell 数组
{'Yes'}
{'No' }
这个函数可以通过在格式描述符前面加一个星号的方式来跳过某些所选项。例如,下面的语句只从文件只读取 first, last 和 gpa。
>> [first, last, gpa] =textread('test_input.dat','%s %s %*s %f %*d %*s')
first =
2×1 cell 数组
{'James'}
{'Sally'}
last =
2×1 cell 数组
{'Jones'}
{'Smith'}
gpa =
3.5100
3.2800
函数 textread 要比 load 命令简单有效的多。 load 命令假设输入文件中的所有数据都是同一类型——它不支持在不同的列上有不同的数据。此外,它把所有的数据都存储在一个数据中。相反地,函数 textread 允许每一列都有独立的变量,当和由不同类型的数据组成的列运算时,它更加的方便。
8.2 关于load和save命令的进一步说明
save 命令把 MATLAB 工作区数据存储到硬盘, load 命令把硬盘上的数据拷贝到工作区中。 save 命令即可用特殊的二进制格式 matfile 存储数据,也可用普通的 ascii 码格式存储数据。 save 命令的形式为
save filename [list of variables] [options]
save命令的参数:

load命令参数:

这两个命令的优点:
- 易于使用
- mat文件的平台独立
- mat文件存储数据是高精度的
- mat文件存储了工作区每一个变量的所有信息
8.3 MATLAB文件过程简介
在 MATLAB 中有一种非常灵活的读取/写入文件的方法,不管这个文件是在磁盘还是在磁带上或者是其他的存储介质。这种机制就叫做文件标识(file id)(有时可简写为 fid),当文件被打开,读取,写入或操作时,文件标识是赋值于一个文件的数。文件标识是一个正整数。两种文件标识是公开的——文件标识 1 是标准输出机制,文件标识 2 是标准错误机制(stderr)。其他的文件标识,在文件打开时创立,文件关闭时消逝。
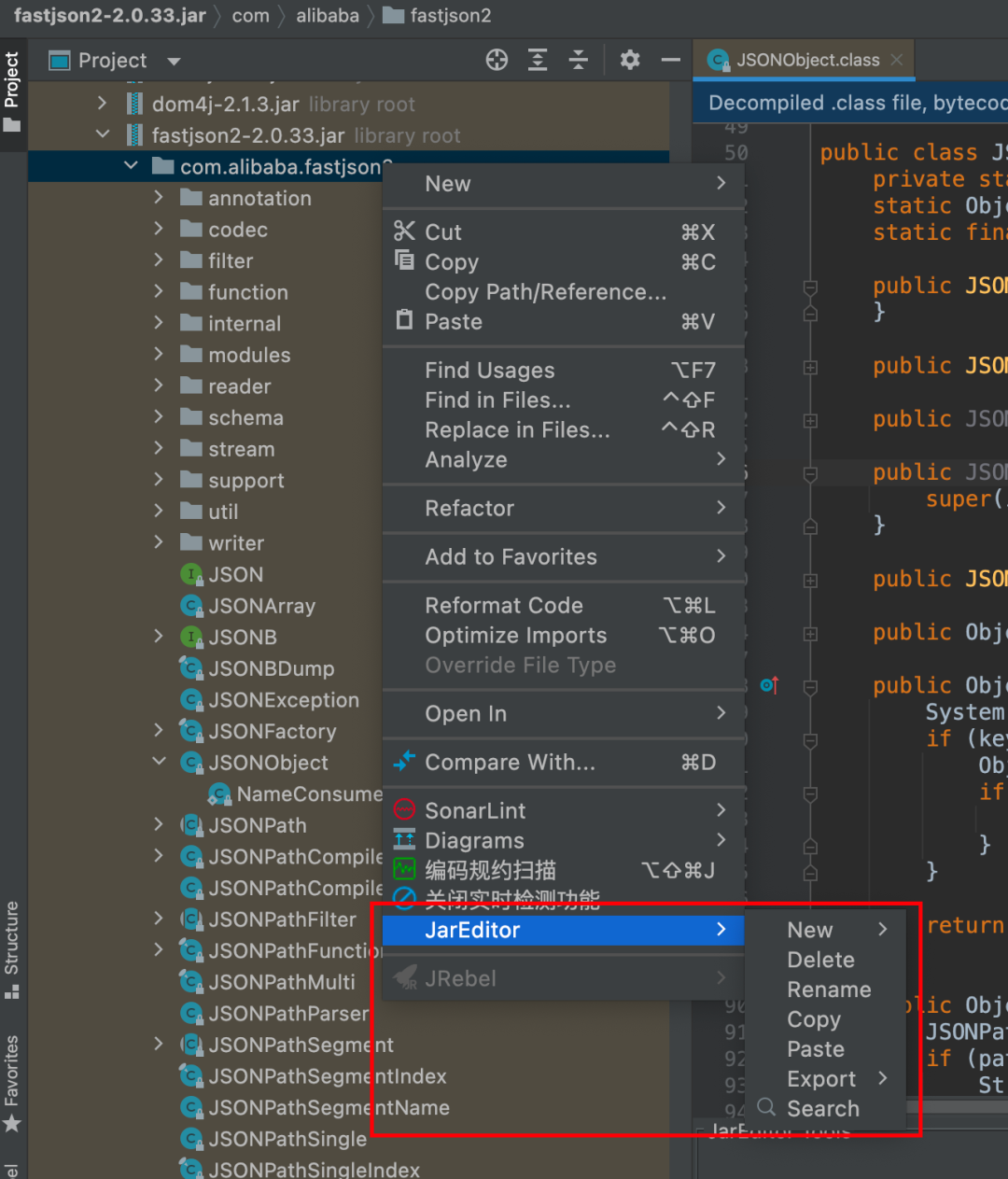
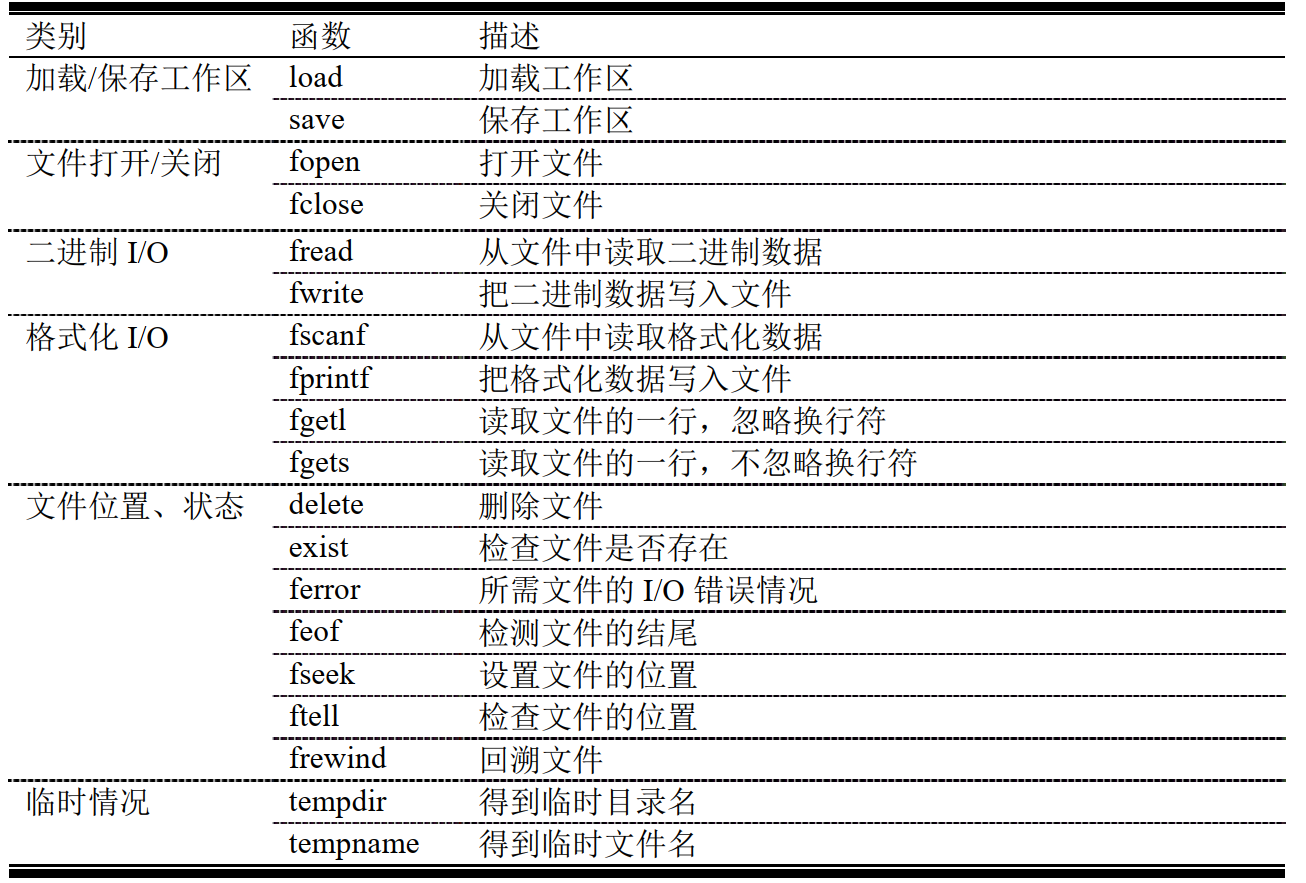
常用控制磁盘文件的输入或输出的函数:
我们可以用 fopen 语句把文件标识传递给磁盘文件或设备,用 fclose 语句把他们从中分开。一旦一个文件用 fopen 语句得到一个文件标识,我们就可以利用 MATLAB 输入输出语句。当我们对这个文件操作完后, fclose 语句关闭并使文件标识无效。当文件打开时,函数 frewind和 fseek 常用于改变当前文件读取和写入的位置。
8.4 文件的打开和关闭
8.4.1 fopen函数
fopen 函数打开一个文件并对返回这个文件的文件标识数。它的基本形式如下:
fid = fopen(filename, permission)
[fid, message] = fopen(filename, permission)
[fid, message] = fopen(filename,permission, format)
其中 filename 是要打开的文件的名字, permission 用于指定打开文件的模式, format 是一个参数字符串,用于指定文件中数据的数字格式。如果文件被成功打开,在这个语句执行之后, fid 将为一个正整数, message 将为一个空字符。如果文件打开失败,在这个语句执行之后, fid 将为-1, message 将为解释错误出现的字符串。
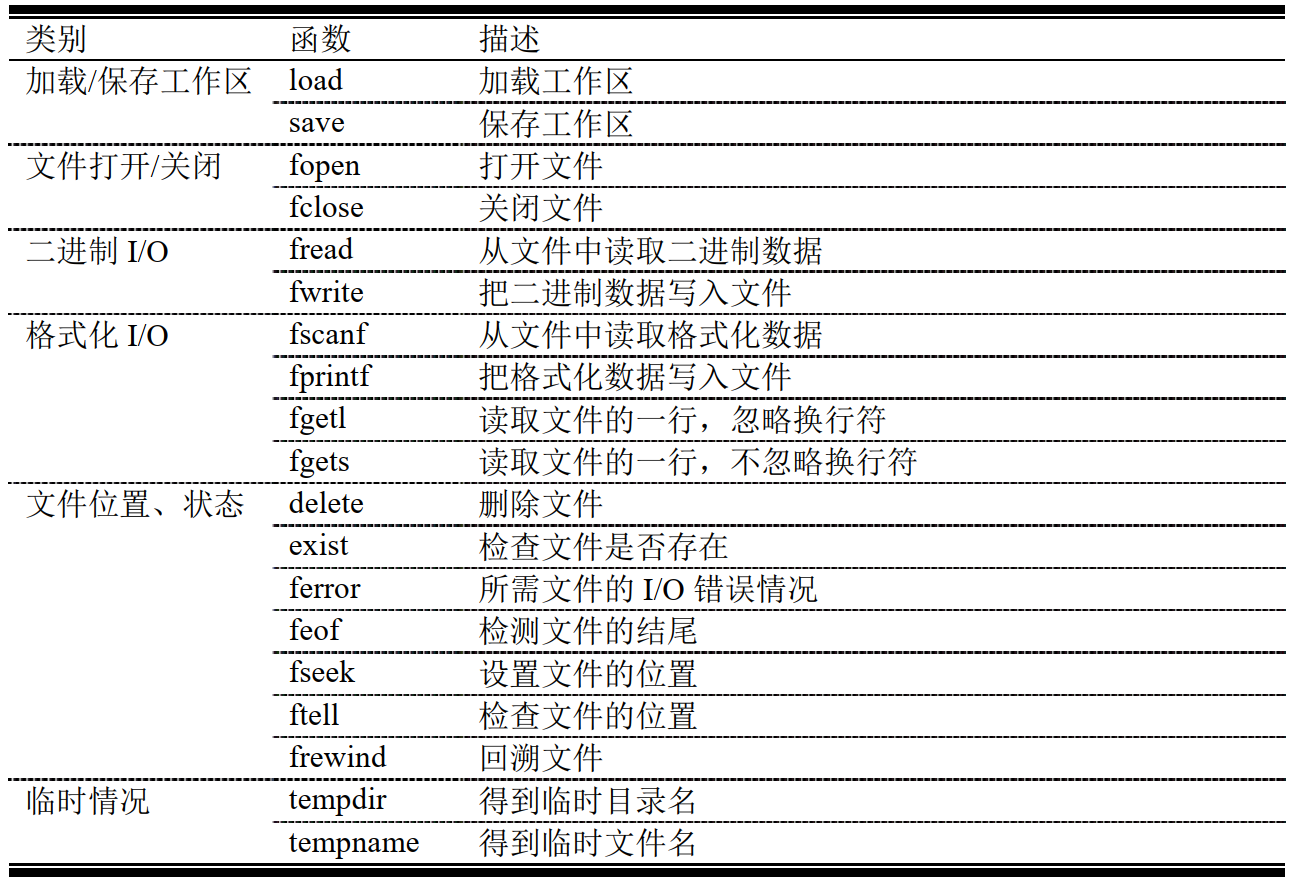
permission 的字符串如表:
对于一些如 PC 一样的平台,它更重要的是区分文本文件和二进制文件。如果文件以文本格式打开,那么一个“t”就应加入到 permission 字符串中(例如“rt”或“rt+”)。如果是以二进制模式找开,那么“b”应加到 permission 字符串中(例如“rb”)。这实际上是不需要的,因为文件默认打开的方式是二进制模式。文本文件和二进制文件在 Unix系统上是没有区别的,所以在这系统上, r 和 b 都不需要。
一些正确应用 fopen 函数的例子:
-
为输入而打开一二进制文件
fid = fopen('example.dat','r') -
为文本输出打开一文件
重写:权限字符串“wt”指定这个文件为新建文本文件。
fid = fopen('outdat','wr')续写:权限运算符“at”指定一个我们想要增加数据的文本文件。
fid = fopen('outdat','at') -
以读写模式打开文件
fid = fopen('junk', 'r+')或
fid = fopen('junk','w+')第一个语句与第二个语句的不同为第一句打开已存在文件,而第二个语句则会删除已存在的文件
8.4.2 fclose函数
fclose 函数用于关闭一文件。它的形式为
status = fclose(fid)
status = fclose('all')
其中 fid 为文件标识, status 是操作结果,如果操作成功,status 为 0,如果操作失败,status 为-1。函数 status = fclose(‘all’)关闭了所有的文件,除了 stdout( fid = 1)和 stderr( fid = 0)。如果所有的文件关闭成功, status 将为 0,否则为-1。
8.5 二进制 I/O 函数
8.5.1 fwrite 函数
函数 fwrite 以自定义格式把二进制数据写入一文件。它的形式为
count = fwrite(fid, array, precision)
count = fwrite(fid, array, precision skip)
其中 fid 是用于 fopen 打开的一个文件的文件标识, array 是写出变量的数组, count 是写入文件变量的数目。MATLAB以列顺序输出数据,它的含义为第一列全部输出后,再输出第二列等等。例如,如果 a r r a y = [ 1 2 3 4 5 6 ] \mathrm{array}=\begin{bmatrix}1&2\\3&4\\5&6\end{bmatrix} array=⎣⎡135246⎦⎤,那么数据输出的顺序为 1, 3, 5, 2, 4, 6。
MATLAB精度字符串如下:
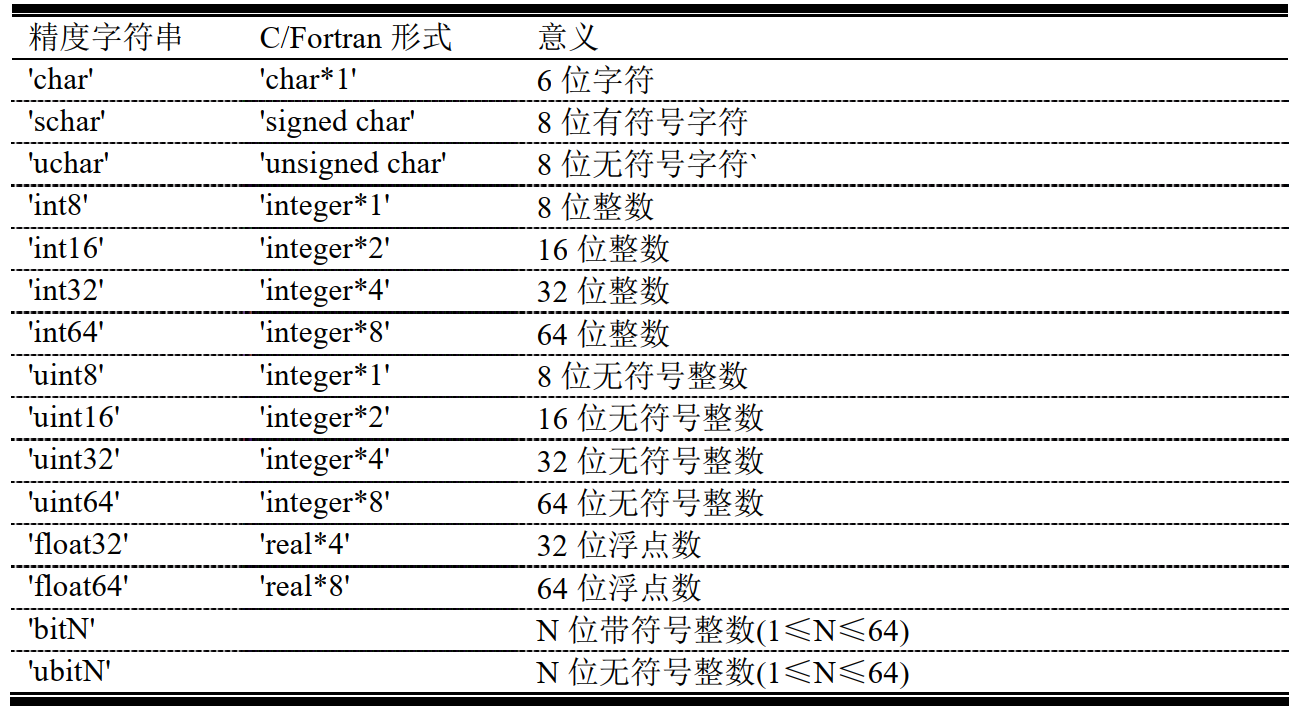
选择性参数 skip 指定在每一次写入输出文件之前要跳过的字节数。在替换有固定长度的值的时侯,这个参数将非常的有用。注意如果 precision 是一个像“bitN”或“ubitN”的一位格式, skip 则用位当作单位。
8.5.2 fread函数
函数 fread 读取用用户自定义格式从一文件中读取二进制数据。它的格式如下:
[array, count] = fread(fid, size, precision)
[array, count] = fread(fid, size, precision, skip)
其中 fid 是用于 fopen 打开的一个文件的文件标识, array 是包含有数据的数组, count是读取文件中变量的数目, size 是要读取文件中变量的数目。
size参数的三种形式:
- n:准确地读取 n 个值。执行完相应的语句后, array 将是一个包含有 n 个值的列向量
- Inf:读取文件中所有值。执行完相应的语句后, array 将是一个列向量,包含有从文件所有值
- [n,m]:从文件中精确定地读取 n×m 个值。 array 是一个 n×m 的数组
如果 fread 到达文件的结尾,而输入流没有足够的位数写满指定精度的数组元素, fread就会用最后一位的数填充,或用 0 填充,直到得到全部的值。如果发生了错误,读取将直接到达最后一位。
8.6 格式化 I/O 函数
8.6.1 fprintf函数
函数 fprintf 把以户自定义格式编写的格式化数据写入一个文件。它的形式为
count = fprintf(fid, format, val1, val2, ...)
fprintf(format, val1, val2, ...)
其中 fid 是我们要写入数据那个文件的文件标识, format 是控制数据显示的字符串。如果 fid 丢失,数据将写入到标准输出设备(命令窗口)。格式( format)字符串指定队列长度,小数精度,域宽和输出格式的其他方面。如图

格式转换指定符:
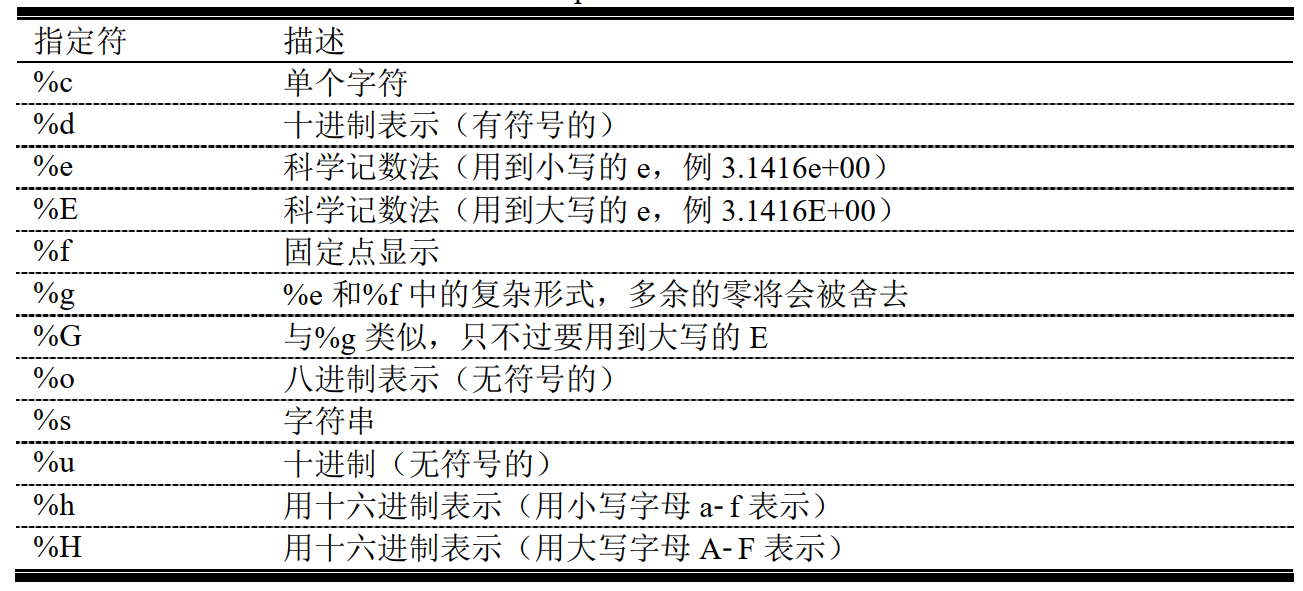
格式标识(修饰符):

格式字符串的转义字符:


8.6.2 格式转换指定符的理解
一些例子
-
显示十进制整数数据
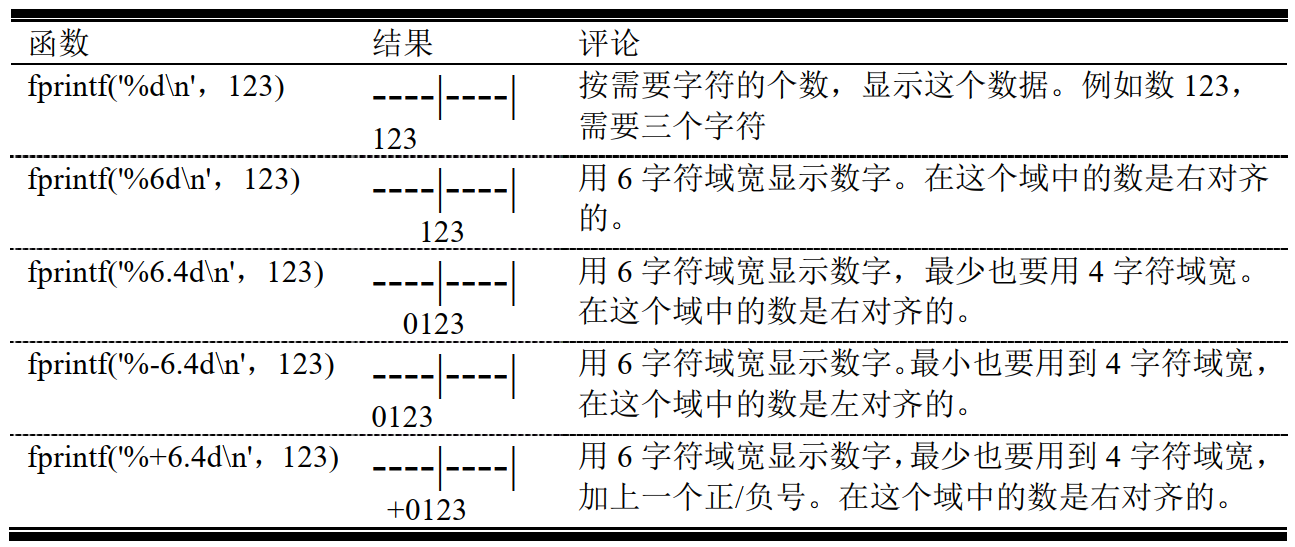
-
显示浮点数数据
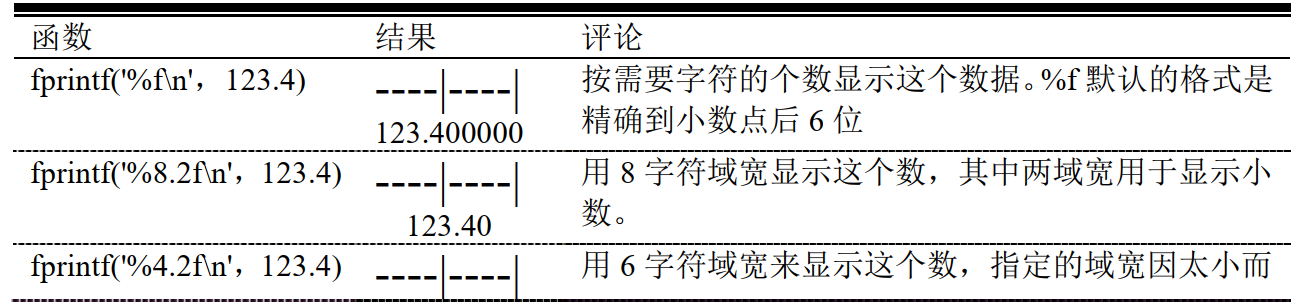

-
显示字符数据
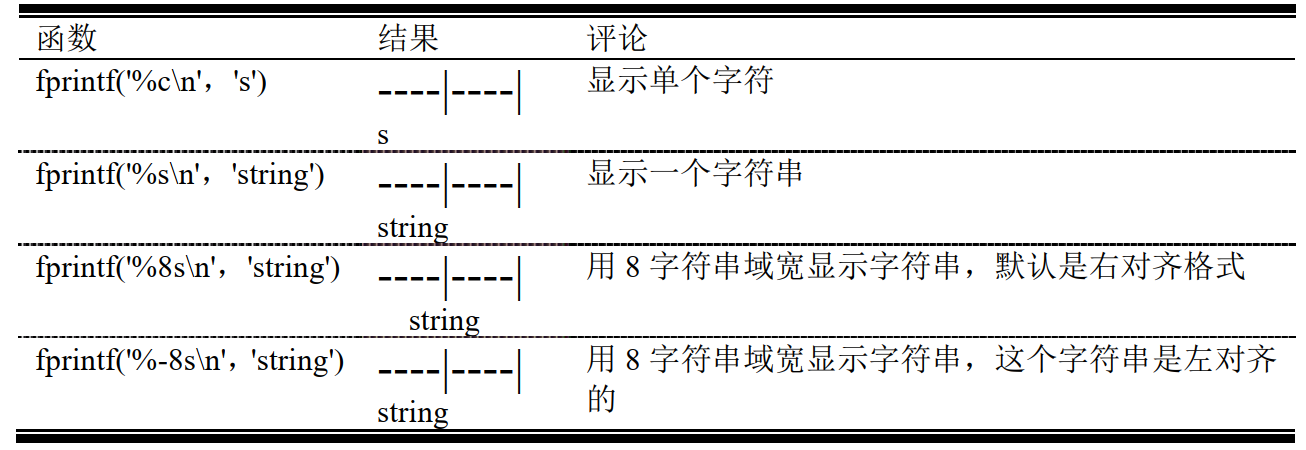
8.6.3 如何使用格式字符串
当函数 fprintf 执行时,函数 fprintf 的输出参数列表将会按格式字符串的指示输出。这个函数从从变量的左端和格式字符的左端开始执行,并从左向右扫描,输出列表的第一个值与格式字符串中第一个格式输出符联合,等等。在输出参数列表中的值必须是相同的类型,格式必须与对应的格式描述符相对应,否则的话,意外的结果将会产生。例如,假设我们要用%c 或%d 描述符显示浮点数 123.4,这个描述符将会全部被忽略,这个数将会以科学记数的方式打印出来。
-
按从左向右的顺序扫描格式字符串。
>> a = 10; b = pi; c = 'Hello'; fprintf('Output: %d %f %s\n', a, b, c); Output: 10 3.141593 Hello -
在函数 fprintf 运行完所有的变量之前,如果扫描还未到达格式字符串的结尾,程序再次从头开始扫描格式字符串。
>> a = [10 20 30 40]; fprintf('Output = %4d %4d\n',a); Output = 10 20 Output = 30 40 -
如果函数 fprintf 在到达格式字符结束之前运行完所有的变量,格式字符串的应用停止在第一个格式指定符,而没有对应的变量,或者停止在格式字符串的末端。
>> a = 10; b = 15; c = 20; fprintf('Output = %4d\nOutput = %4.1f\n', a, b, c); Output = 10 Output = 15.0 Output = 20 Output = >>格式字符串的应停止在%4.1f。
8.6.4 fscanf 函数
函数 fscanf 可以从一个文件中按用户自定义格式读取格式化数据。形式如下:
array = fscanf(fid, format)
[array, count] = fscanf(fid, format, size)
其中 fid 是所要读取的文件的文件标识( fileid), format 是控制如何读取的格式字符串, array 是接受数据的数组,输出参数 count 返回从文件读取的变量的个数。
size参数的三种形式:
- n:准确地读取 n 个值。执行完相应的语句后, array 将是一个包含有 n 个值的列向量
- Inf:读取文件中所有值。执行完相应的语句后, array 将是一个列向量,包含有从文件所有值
- [n,m]:从文件中精确定地读取 n×m 个值。 array 是一个 n×m 的数组
函数 fscanf把文件中的数据与文件字符串的格式转换指定符进行对比。只要两者区配, fscanf 把值进行转换并把它存储在输出数组中。这个过程直到文件结束或读取的文件当数目达到了 size ,数组才会结束,无论那一种情况先出现。如果文件中的数据与格式转换指定符不匹配, fscanf 的操作就会突然中止。示例:
文件x.dat内容如下:
10.00 20.00
30.00 40.00
-
>> fid=fopen("x.dat",'r') fid = 3 >> [z, count] = fscanf(fid, '%f') z = 10 20 30 40 count = 4 >> fclose(fid) ans = 0 -
>> [z, count] = fscanf(fid, '%f', [2 2]) z = 10 30 20 40 count = 4 >> fclose(fid) ans = 0 -
>> fid=fopen("x.dat",'r') fid = 3 >> [z, count] = fscanf(fid, '%d', Inf) z = 10 count = 1 >> fclose(fid) ans = 0z 为 10, count 的值为 1。这种情况的发生是因为 10.00 的小数点与格式转义指定符不匹配,函数 fscanf 函数停止在第一次出现不匹配时。
-
>> fid=fopen("x.dat",'r') fid = 3 >> [z, count] = fscanf(fid, '%d.%d',[1 Inf]) z = 10 0 20 0 30 0 40 0 count = 8 >> fclose(fid) ans = 0z 为行向量[10 0 20 0 30 0 40 0], count 的值为 8。这种情况的发生是因为小数点与格式转义指定符匹配,小数点前后的数可以看作独立的整数。
-
>> fid=fopen("x.dat",'r') fid = 3 >> [z, count] = fscanf(fid, '%c') z = '10.00 20.00 30.00 40.00' count = 24 >> fclose(fid) ans = 0变量 z 是一个包含文件中每一个字符的行向量,包括所有的空格和换行符!变量 count等于文件中字符的个数。
-
>> fid=fopen("x.dat",'r') fid = 3 >> [z, count] = fscanf(fid, '%s') z = '10.0020.0030.0040.00' count = 4 >> fclose(fid) ans = 0z 是一个行向量,包括 20 个字符 10.0020.0030.0040.00, count 为 4。这种结果的产生是因为字符串指定符忽略空白字符,这个函数在这个文件中发现 4 个独立的字符串
fscanf的格式转化指定符:

8.6.5 fgetl函数
函数 fgetl 从一文件中把下一行(最后一行除外)当作字符串来读取。它的形式为
line = fgetl(fid)
如果 fid 是我们所要读取的文件的标识(file id)。 line 是接受数据的字符数组。如果函数 fgetl 遇到文件的结尾, line 的值为-1。
8.6.6 fgets 函数
函数 fgets 从一文件中把下一行(包括最后一行)当作字符串来读取。它的形式为
line = fgets(fid)
如果 fid 是我们所要读取的文件的标识(file id)。 line 是接受数据的字符数组。如果函数 fgets 遇到文件的结尾, line 的值为-1。
8.7 格式化和二进制 I/O 函数的比较

8.8 文件位置和状态函数
在打开文件之前, MATLAB 函数 exist 用于判断这个文件是否存在。一旦一个文件打开,我们就可以用函数 feof 和 ftell 判断当前数据在文件中的位置。还用两个函数帮助我们在文件中移动: frewind 和 fseek。最后,当程序发生 I/O 错误时, MATLAB 函数 ferror 将会对这个错误进行详尽的描述。
8.8.1 exist函数
exist 函数用来检测工作区中的变量,内建函数或 MATLAB 搜索路径中的文件是否存在。它的形式如下
ident = exist('item');
ident = exist('item', 'kind');
'kind’的类型有:“var”,“file”,“builtin”和“dir”。
exist的返回值:

8.8.2 函数ferror
在 MATLAB 的 I/O 系统中有许多的中间数据变量,包括一些专门提示与每一个打开文件相关的错误的变量。每进行一次 I/O 操作,这些错误提示就会被更新一次。函数 ferror 得到这些错误提示变量,并把它转化为易于理解的字符信息。
message = ferror(fid)
message = ferror(fid, 'clear')
[message, errnum] = ferror(fid)
这个函数会返回与 fid 相对应文件的大部分错误信息。它能在 I/O 操作进行后,随时被调用,用来得到错误的详细描述。如果这个文件被成功调用,产生的信息为“…”,错误数为 0。对于特殊的文件标识,参数“clear”用于清除错误提示。
8.8.3 函数foef
函数 feof 用于检测当前文件的位置是否是文件的结尾。它的形式如下
eofstat = feof(fid)
如果是文件的结尾,那么函数返回 1,否则返回 0。
8.8.4 函数ftell
函数 ftell 返回 fid 对应的文件指针读/写的位置。这个位置是一个非负整数,以 byte 为单位,从文件的开头开始计数。返回值-1 代表位置询问不成功。如果这种情况发生了,我们利用 ferror 得知为什么询问不成功。函数的形式如下:
position = ftell(fid)
8.8.5 函数frewind
函数 frewind 允许程序把文件指针复位到文件的开头,形式如下
frewind(fid)
这个函数不返回任何状态信息
8.8.6 函数fseek
函数 fseek 允许程序把文件指针指向文件中任意的一个位置。函数形式如下
status = fseek(fid, offset, origin)
函数用 offsett 和 origin 来重设 fid 对应文件的文件指针。 offset 以字节为单位,带有一个正数,用于指向文件的结尾,带有一个负数,用于指向文件的开头。 origin 是一个字符串,取值为下面三个中的一个。
bof文件的开始位置cof指针中的当前位置eof文件的结束位置
8.9 函数uiimport
函数是一种基于 GUI 的方法从一个文件或从剪贴板中获取数据。这个命令的形式如下
uiimport
structure = uiimport;
在第一种情况下,获取的数据可以直接插入当前的工作区。在第二种情况下,数据可以转化为一个结构数组。并保存在变量 structure 中。
8.10 总结
![[Meachines] [Medium] Sniper RFI包含远程SMB+ powershell用户横向+CHM武器化权限提升](https://img-blog.csdnimg.cn/img_convert/99d0fd5590fa7d665291b648290c145b.jpeg)