一、基于redis的HyperLogLog数据结构实现的布隆过滤器在信息流中历史数据的应用
做信息流服务端的左发一定会遇到用户历史数据的集合,对于一些有限信息流(因DT数据中心的推荐数据变化较慢,推荐量不大),历史数据可以使用一般的hash结构来实现,存储用户的访问历史数据,我们曾经有块业务就是这样,用户从第一屏开始请求到最后一屏,整个过程的信息流数据不能出现已经访问的内容,于是我们使用了一个hash结构,而且在访问完所有内容之后下次再进入时进行清除历史数据以防止用户无数据。但对于一些无限信息流(DT推荐数据变化较快,甚至是实时变化的情况),此时就需要长时间甚至永久记录用户的历史已看数据)。从而实现用户在每次访问的时候在给用户展现数据前对数据进行过滤,对已阅读过的数据进行过滤。
一般的实现方法,可能使用KV存储进行get/Set判断,也可以考虑使用hashMap数据结构,这种方式在数据量小的时候都是完全可以的,但随着数据量的急剧增大,hash数据的存储以及在查询方面都会存一些问题,比如占用内存较大的问题。这时我们就可以了解一下redis的HyperLogLog数据结构以及布隆过滤器了。
HyperLogLog与布隆过滤器都是针对大数据统计存储应用场景下的知名算法。HyperLogLog是在大数据的情况下关于数据基数的空间复杂度优化实现,布隆过滤器是在大数据情况下关于检索一个元素是否在一个集合中的空间复杂度优化后的实现,它是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。比起hashmap它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的,虽然牺牲了一个小概率的准确性,但可以达到工程上的需求,对于准确度要求不是特别高,但数据量巨大的场景是非常合适的,比如上面提到的信息流内容判断是否在用户已阅历史中。
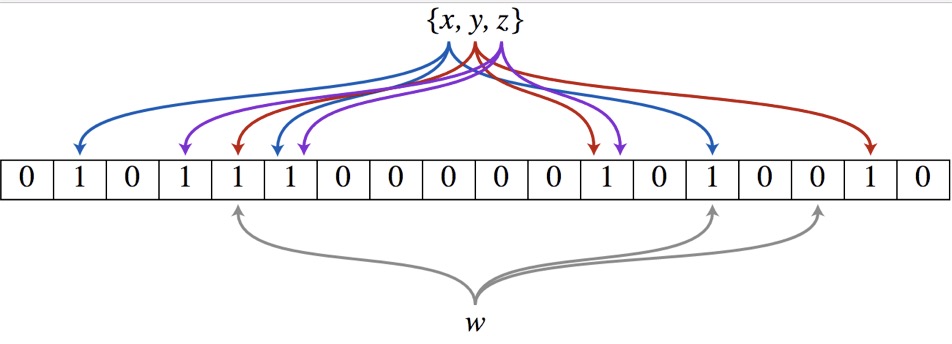
布隆过滤器原理如下图:我们在集合中存储有三个元素x,y,z,但实际其并未存储这三个原始元素(空间占用较大),而是将这三个元素各通过一些hash算法将其对应到一个超大的位数组(初始时各位置的值均为1)上,从图中可看到其是通过三种hash算法将x,y,z计算出的hash值映射到位数组并将位数组上的值置成1。当我们判断x是否在集合中时,对x也进行同样的hash计算找到位置,如果位置上的值都是1,说明x可能存在,如果我们对于t进行hash计算,发现对应的三个位置中有一个位置不存在,说明t一定不存在。这就能基本实现我们的历史已阅文章的判断上了。原理图如下:
比如我们刷头条的信息流文章,每一个用户已经看过的文章ID都单独存在redis中的HyperLogLog结构中,而当这个用户来刷新信息流的时候,我们取到了一个文章ID列表,然后逐个将文章ID扔到HyperLogLog结构中判断这个ID是否存在,如果返回false,则表示这篇文章一定没有看过,于是我们就可以将这篇文章推给用户。如果返回true,则这篇文章有可能用户看过,这个时候可以过滤这篇文章,从而可以保证用户看到的所有文章一定是其没有看过的。而使用REDIS中的HyperLogLog可以支持的已看历史文章数据级占用内存有效率在数据量大的时候肯定优于redis的hash,因为上面说过的HyperLogLog并未存储每篇文章的ID值,而只是把这些ID值hash处理后转化为了对应位上的1/0标志,因而内存占用很少,而其计算量就是对key的几次hash计算。
二、关于MySQL中Innodb的事务日志(redo log和undo log)
下方这篇文章中大多可能为转载的某处相关内容,如作者有意见,请联系我删除。
事务的实现是基于数据库的存储引擎,mysql中支持事务的存储引擎有innoDB和NDB。innoDB是mysql默认的和主要应用的存储引擎,默认的隔离级别是RR,并且通过多版本并发控制(MVCC,Multiversion Concurrency Control )解决不可重复读问题。因此innoDB的RR隔离级别是一个在串行和并发性能中间的一个折衷方案。
事务在进行操作的时候可以提交成功,也可以进行回滚,这是怎么实现的呢?这里就需要说一下事务日志了,事务是通过事务日志来实现的,innodb事务日志包括redo log和undo log。redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作。要注意undo log不是redo log的逆向过程,其实它们都算是用来恢复的日志。
#. 关于redo log和undo log
1.redo log
通常是物理日志,记录的是数据页的物理修改,而不是某一行或某几行修改成怎样怎样,它用来恢复提交后的物理数据页(恢复数据页,且只能恢复到最后一次提交的位置)。redo log包括两部分:一是内存中的日志缓冲(redo log buffer),该部分日志是易失性的;二是磁盘上的重做日志文件(redo log file),该部分日志是持久的。
2.undo log
是用来回滚行记录到某个版本。undo log一般是逻辑日志,根据每行记录进行记录。
#. 需要注意的几点:
1.redo log不是二进制日志。虽然二进制日志中也记录了innodb表的很多操作,也能实现重做的功能,但是它们之间有很大区别。二进制日志是在存储引擎的上层产生的,不管是什么存储引擎,对数据库进行了修改都会产生二进制日志。而redo log是innodb层产生的,只记录该存储引擎中表的修改。并且二进制日志先于redo log被记录。
2.二进制日志记录操作的方法是逻辑性的语句。即便它是基于行格式的记录方式,其本质也还是逻辑的SQL设置,如该行记录的每列的值是多少。而redo log是在物理格式上的日志,它记录的是数据库中每个页的修改。
3.二进制日志只在每次事务提交的时候一次性写入缓存中的日志"文件"(对于非事务表的操作,则是每次执行语句成功后就直接写入)。而redo log在数据准备修改前写入缓存中的redo log中,然后才对缓存中的数据执行修改操作;而且保证在发出事务提交指令时,先向缓存中的redo log写入日志,写入完成后才执行提交动作。
4.因为二进制日志只在提交的时候一次性写入,所以二进制日志中的记录方式和提交顺序有关,且一次提交对应一次记录。而redo log中是记录的物理页的修改,redo log文件中同一个事务可能多次记录,最后一个提交的事务记录会覆盖所有未提交的事务记录。而且redo log是并发写入的,不同事务之间的不同版本的记录会穿插写入到redo log文件中,例如可能redo log的记录方式如下。
5.事务日志记录的是物理页的情况,它具有幂等性,因此记录日志的方式极其简练。幂等性的意思是多次操作前后状态是一样的,例如新插入一行后又删除该行,前后状态没有变化。而二进制日志记录的是所有影响数据的操作,记录的内容较多。例如插入一行记录一次,删除该行又记录一次。
innodb通过force log at commit机制实现事务的持久性,即在事务提交的时候,必须先将该事务的所有事务日志写入到磁盘上的redo log file和undo log file中进行持久化。为了确保每次日志都能写入到事务日志文件中,在每次将log buffer中的日志写入日志文件的过程中都会调用一次操作系统的fsync操作(即fsync()系统调用)。因为MariaDB/MySQL是工作在用户空间的,MariaDB/MySQL的log buffer处于用户空间的内存中。要写入到磁盘上的log file中(redo:ib_logfileN文件,undo:share tablespace或.ibd文件),中间还要经过操作系统内核空间的os buffer,调用fsync()的作用就是将OS buffer中的日志刷到磁盘上的log file中。从redo log buffer写日志到磁盘的redo log file中,过程如下:
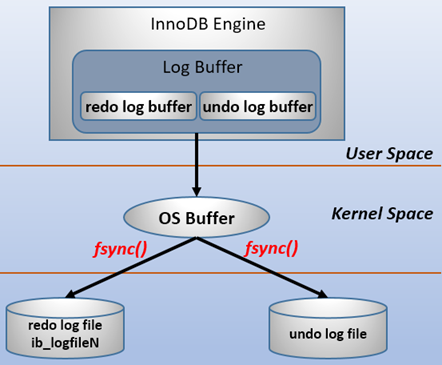
为什么要经过一层os buffer,是因为open日志文件的时候,open没有使用O_DIRECT标志位,该标志位意味着绕过操作系统层的os buffer,IO直写到底层存储设备。不使用该标志位意味着将日志进行缓冲,缓冲到了一定容量,或者显式fsync()才会将缓冲中的刷到存储设备。使用该标志位意味着每次都要发起系统调用。比如写abcde,不使用o_direct将只发起一次系统调用,使用o_object将发起5次系统调用。