之前小编也写过多篇AI存储相关的文章,包括AI背景与分层存储的分析,以及AI存储重点从训练转向推理等内容。具体参考:
-
深度剖析:AI存储架构的挑战与解决方案
-
存储正式迈入超大容量SSD时代!
-
这可能是最清晰的AI存储数据流动图解
-
机器学习中的内存优化
一、生成式人工智能对存储市场的影响
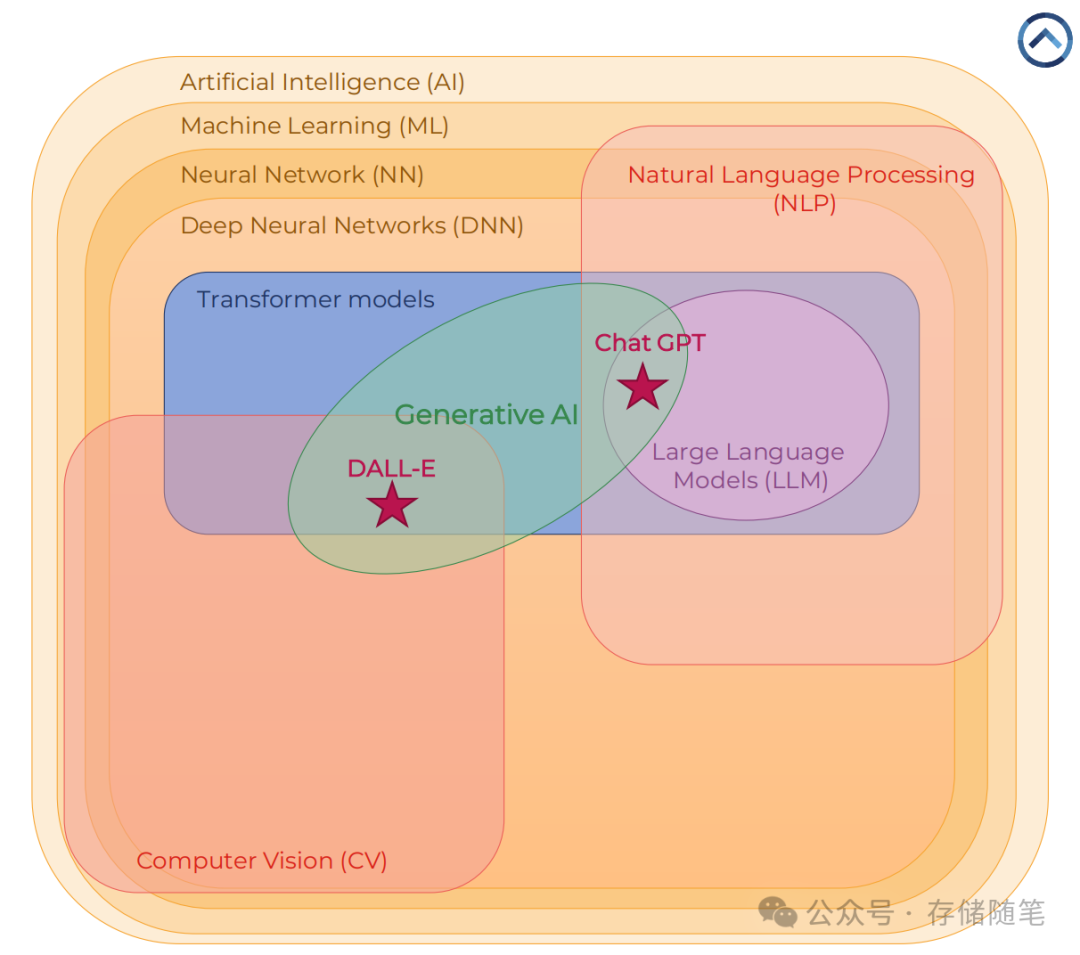
生成式人工智能(Generative AI)是近年来发展迅猛的领域之一,其能够根据提示生成文本、图像、视频、音频、代码及三维模型等多种类型的内容。生成式AI背后的技术基础包括机器学习(ML)、深度神经网络(DNN)以及转换器模型等,这些技术共同推动了自然语言处理(NLP)领域的进步,使得如生成、总结及翻译文字等应用得以实现。
-
人工智能(Artificial Intelligence, AI)的主要目标是创建一个能够自主运作的系统。为了实现这个目标,大量的研究集中在使系统能够理解和在环境中导航。这包括感知环境中的物体、理解其动态以及规划路径等能力,以便系统能够有效地在物理或虚拟空间中移动和互动。
-
机器学习(Machine Learning, ML)是实现上述目标的关键领域之一。机器学习的核心理念是通过向算法展示解决方案的例子来教导算法如何解决问题,而不是直接解释解决问题的具体步骤。这种方法允许算法从示例中学习并识别模式,从而找到解决问题的方法。
-
人工神经网络是由被称为神经元的基本单元构成的网络,它是机器学习的一种方法。神经元按照层级组织,当网络包含多个层级时,就称之为深度神经网络(Deep Neural Network, DNN)。当我们把机器学习的原则应用于DNN时,就进入了深度学习(Deep Learning, DL)的领域。深度学习通过多层神经网络捕捉输入数据中的复杂特征,从而实现更高级的任务处理能力。
-
转换器(Transformer)神经网络是一种使用自注意力机制(Self-Attention Mechanism)的深度神经网络架构。这种架构专为处理顺序输入数据而设计,由两个主要组件构成:编码器网络(Encoder Network)和解码器网络(Decoder Network)。编码器负责处理输入序列并提取其特征,而解码器则根据编码器传递的信息生成输出序列。
-
大型语言模型(Large Language Models, LLMs)是一类具有转换器架构并且包含大量参数的网络。它们通过无监督或半监督学习方法,在大量的未标注文本上进行训练。这类模型支持多种自然语言处理(Natural Language Processing, NLP)应用,如文本生成、摘要生成和机器翻译等。
-
生成式AI是一种能够根据提示生成文本、图像、视频、音频、代码、三维模型等内容的人工智能。这种类型的AI可以根据需求创造出新的、原创的内容。生成式AI的应用场景十分广泛,从艺术创作到软件开发,再到娱乐产业,都有着广泛的应用潜力。
二、AI处理器需求的增长与市场变化
随着生成式AI模型复杂度的增加,训练这些模型所需的计算资源也呈指数级增长。从AlexNet到GPT-4等模型的发展过程中,可以看到用于训练模型的浮点运算次数(FLOPs)从2009年的1E+14增长到了接近1E+27。这一增长不仅体现在算法复杂度上,还体现在所需的处理器性能、训练时间和成本上。
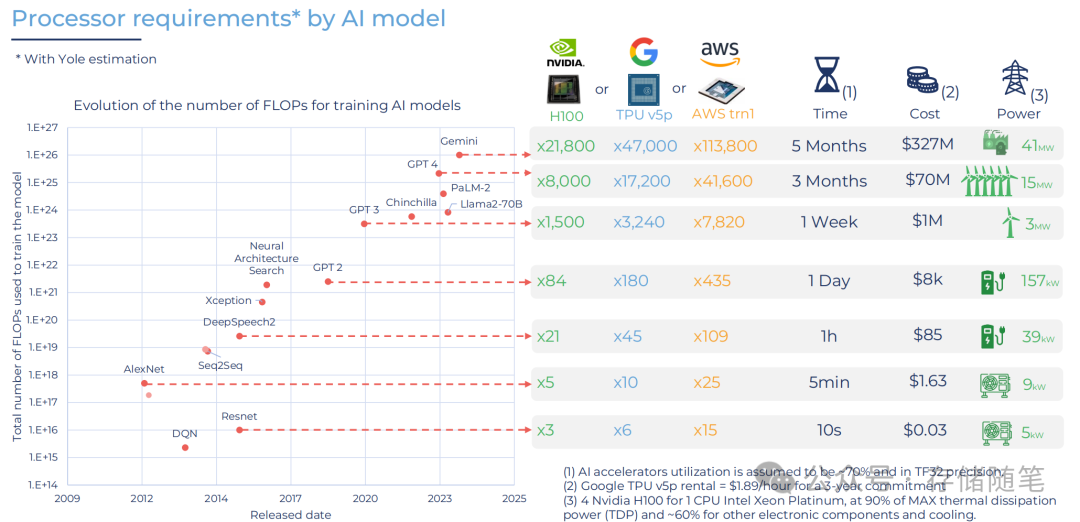
例如,对于某些大型语言模型(LLM),如PaLM-2或Llama2-70B,它们需要成千上万的高性能GPU进行几个月的训练,并且耗资巨大,达到数百万美元。此外,这些模型的训练还会消耗大量的电力,这在环境可持续性方面提出了新的挑战。
随着技术的发展,数据中心AI处理器的性能不断提高,同时功耗也逐渐降低。未来的处理器将会拥有更高的性能和更低的功耗,以满足日益增长的数据中心需求。
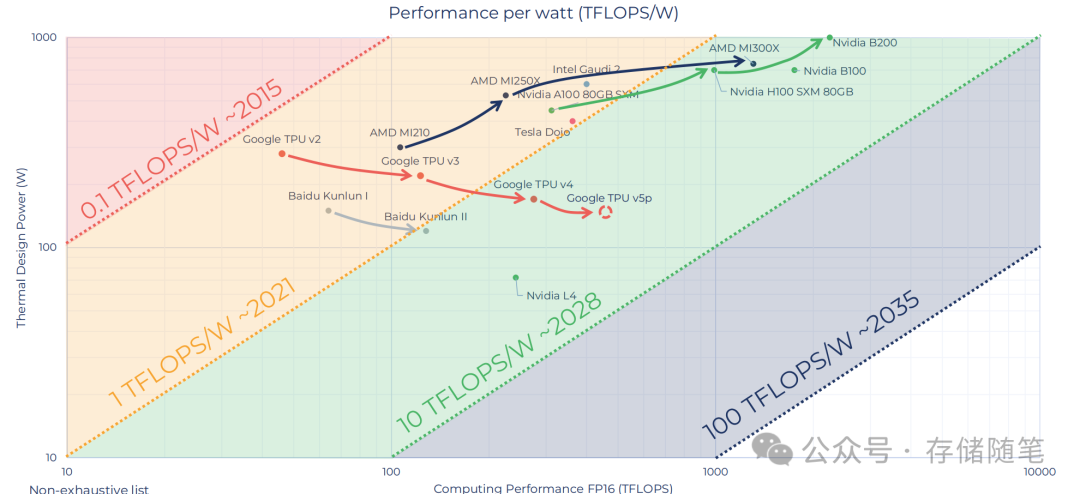
-
Google TPU v2:早期的谷歌张量处理单元,性能较低。
-
AMD MI250X:AMD的MI250X处理器,性能比Google TPU v2要好。
-
Intel Gaudi 2:英特尔的第二代海豚ICP处理器,性能更高。
-
Nvidia A100 80GB SXM:英伟达A100 80GB SXM处理器,性能更强。
-
Tesla Dojo:特斯拉的Dojo超级计算机,性能更高。
-
Nvidia H100 SXM:英伟达的H100 SXM处理器,性能强。
-
Nvidia B200:英伟达的B200处理器,性能最高。
还有一些其他的处理器,如AMD MI210、Google TPU v3、Google TPU v4、Baidu Kunlun I、Baidu Kunlun II等,它们的位置都在Google TPU v2和AMD MI250X之间,表示它们的性能介于两者之间。
GPU的内存容量对人工智能至关重要。内存主要有两个作用:存储AI模型参数、存储K-V缓存。
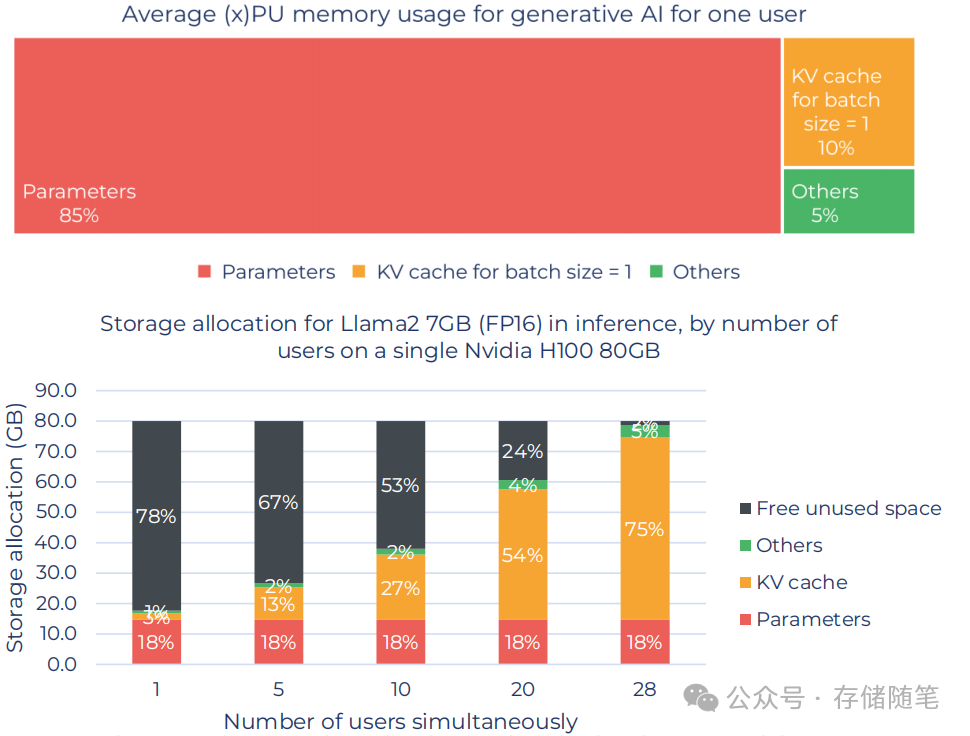
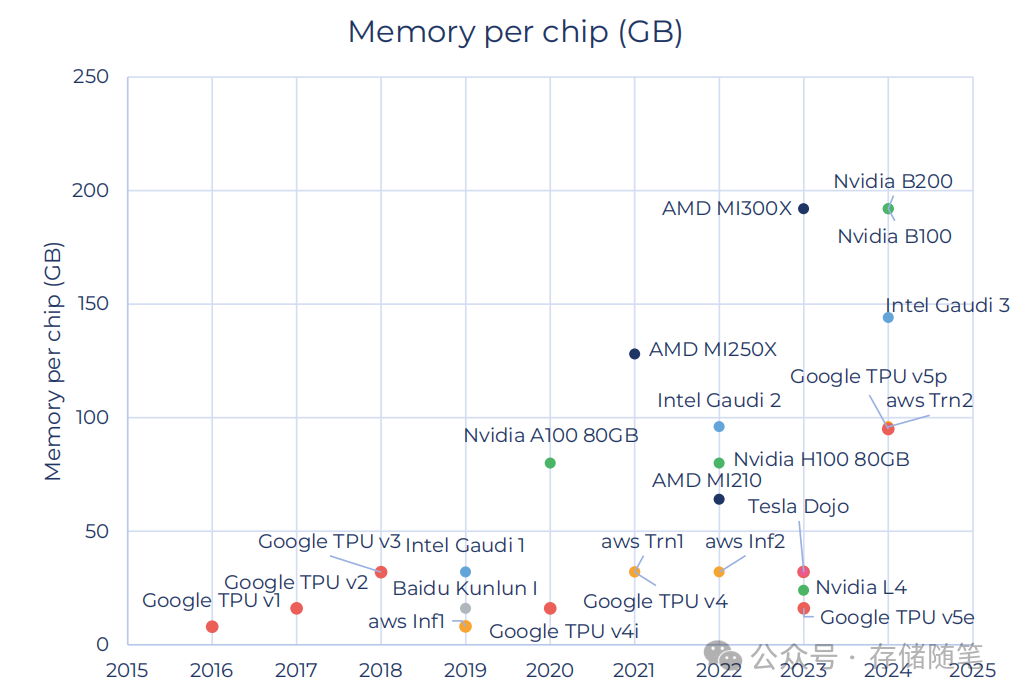
这两个功能都是AI运行过程中必不可少的部分,因此GPU的内存容量越大,能够处理的模型规模也就越大,能够支持更多的并发用户数。
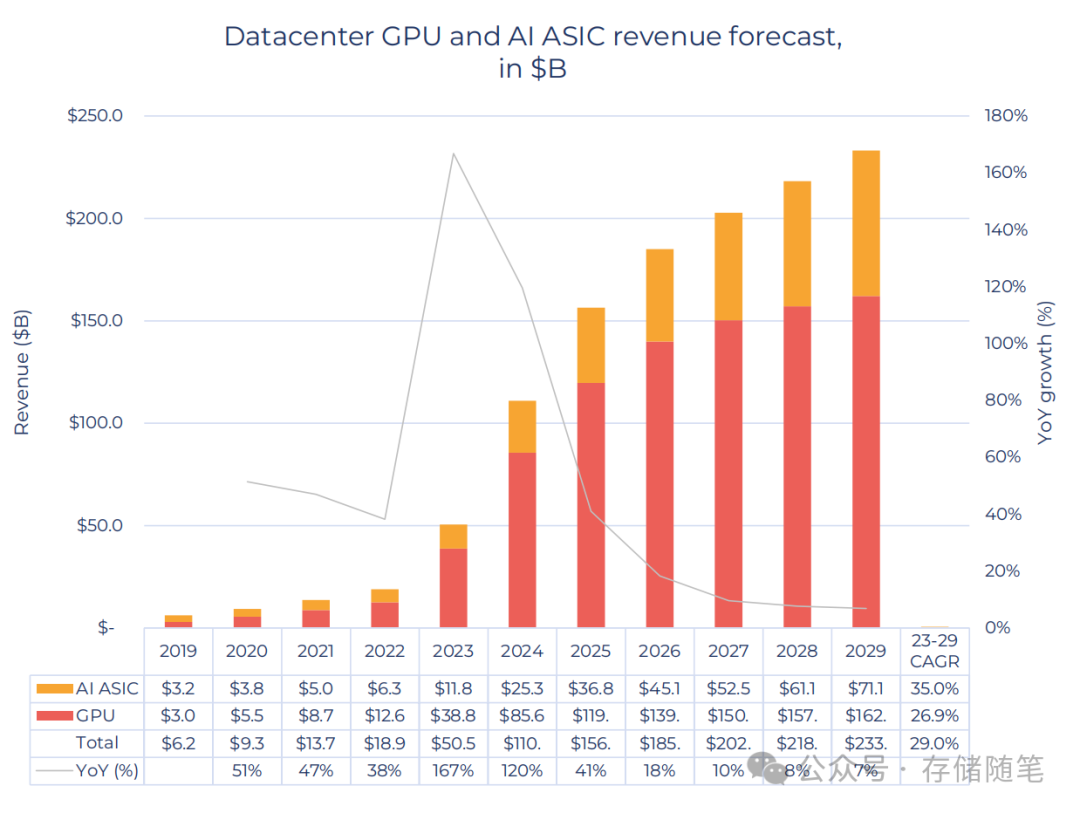
三、数据中心GPU和AI ASIC市场预测
从2019年至2029年,数据中心GPU和AI ASIC的收入预计将持续增长。特别是AI ASIC,其收入将从2019年的32亿美元增长至2029年的711亿美元,复合年增长率CAGR为35.0%,而GPU的收入则预计在2029年达到162亿美元,CAGR为26.9%。总体而言,数据中心GPU和AI ASIC的总收入预计将超过230亿美元,并在2029年前保持29.0%的CAGR。
四、AI服务器将成为服务器市场的主导力量
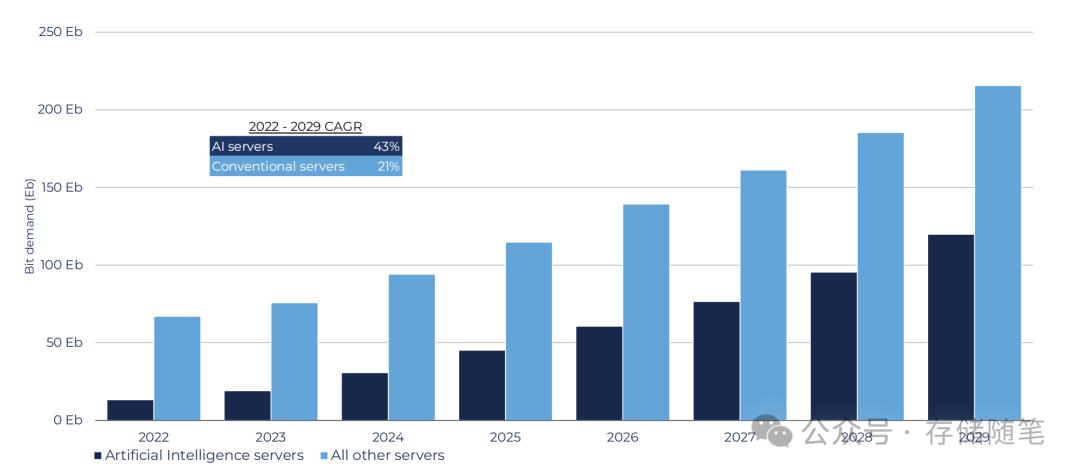
2022年至2029年期间,AI服务器与传统服务器的需求对比:可以看到,AI服务器的需求增速明显快于整体服务器市场,其复合年增长率(CAGR)达到43%,而传统服务器仅为21%。这意味着AI服务器将在未来几年内成为服务器市场的主导力量,并且其需求的增长速度远超其他类型的服务器。此外,从2022年开始,AI服务器的需求量就已经超过了所有其他类型服务器的总和,预计到2029年将达到近250艾字节(Eb),而传统服务器则保持在150至200 Eb之间。这一趋势表明AI正在推动整个服务器市场的发展,并且在未来几年内将继续引领市场增长。
五、AI对存储市场的影响
HBM(高带宽内存)的生产相比DDR5更为复杂,因为它需要几乎三倍的晶圆启动次数来获得相同的位输出。这是由于以下几个原因:
-
Die尺寸:HBM的Die尺寸较大,需要更多的晶圆来制造。
-
TSV区域和TSV工艺良率:TSV(硅通孔)是HBM的关键技术之一,它使得多层堆叠成为可能。然而,TSV的制作过程较为复杂,导致了较低的良率。
-
封装良率和累积良率效应:HBM的封装过程也比DDR5复杂,因为要实现多层堆叠,所以封装良率较低。而且,随着层数的增加,累积良率效应也会变得更加显著,进一步增加了生产难度。
这些因素共同导致了HBM的生产成本较高,同时也要求更高的技术水平和更严格的品质控制。

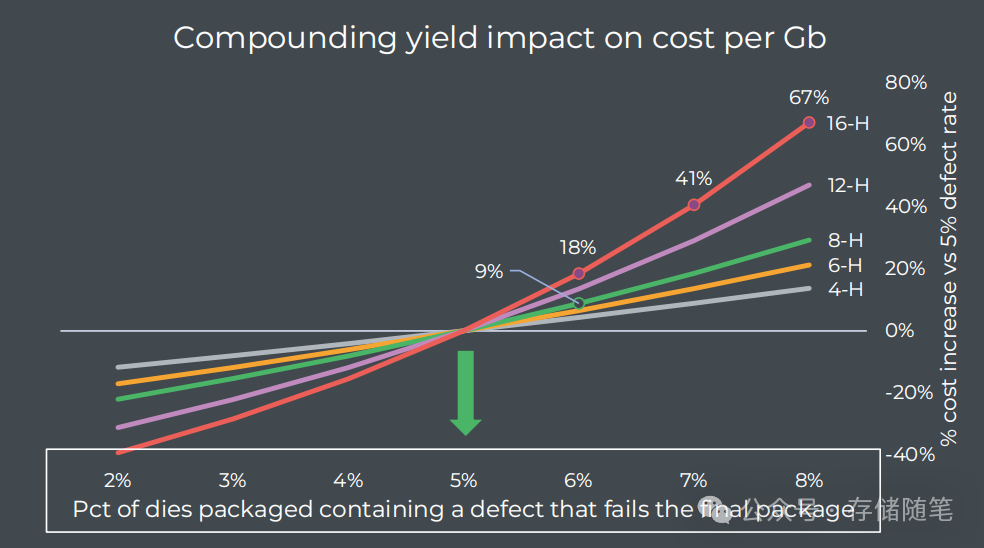
在HBM生产过程中,即使很小的良率变化也可能大大影响产品成本。例如,在8层高的封装中,如果良率下降1个ppm(百万分之1),那么每比特的成本就会增加9%;而在16层高的封装中,同样的良率下降会导致每比特成本增加18%。这就意味着HBM的生产必须非常精确和稳定,以确保成本可控并满足市场需求。
AI发展对内存需求的巨大影响,特别是随着模型规模的扩大和精度要求的变化,对高性能内存的需求也在不断增加。
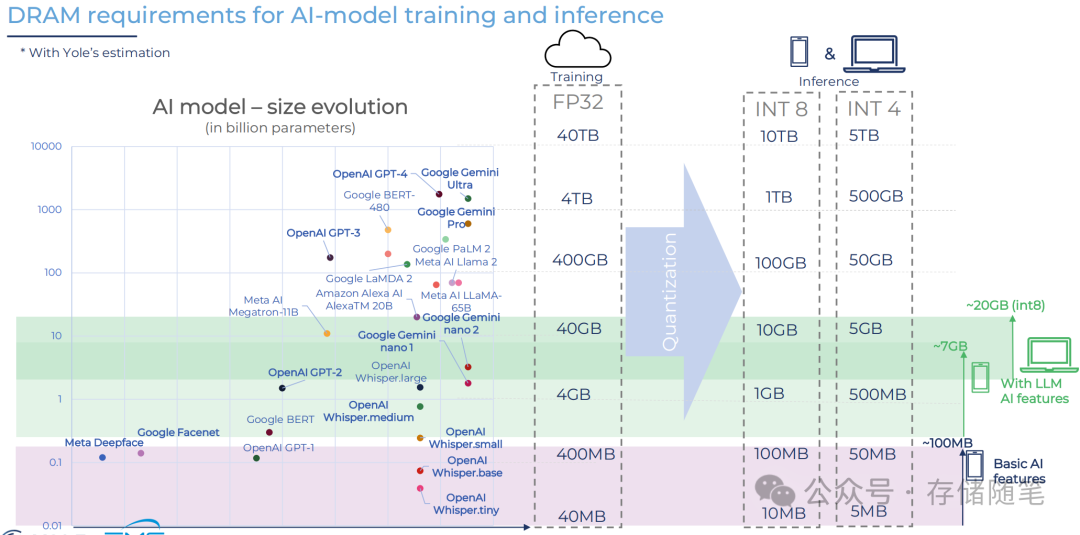
训练通常需要大量的浮点运算能力,因此消耗的内存资源更多,例如使用FP32精度进行训练时,需要40TB的内存。通过量化(Quantization)技术,可以在一定程度上降低内存需求,但仍然需要较大的内存空间。推理阶段则可以根据应用的不同选择不同的精度级别,如INT8或INT4,对应的内存需求也随之减少。例如,使用INT8精度进行推理时,所需内存约为训练阶段的十分之一左右。
参考文献:FMS2024-Generative AI – Memory Market Impacts | www.yolegroup.com
如果您看完有所受益,欢迎点击文章底部左下角“关注”并点击“分享”、“在看”,非常感谢!
精彩推荐:
-
这可能是最清晰的AI存储数据流动图解
-
DWPD指标:为何不再适用于大容量SSD?
-
突破内存墙:DRAM的过去、现在与未来
-
E1.S接口如何解决SSD过热问题?
-
ZNS SSD是不是持久缓存的理想选择?
-
存储正式迈入超大容量SSD时代!
-
FMS 2024: 带来哪些存储技术亮点?
-
IEEE报告解读:存储技术发展趋势分析
-
什么?陶瓷也可以用来存储数据了?
-
都说固态硬盘寿命短,那么谁把使用寿命用完了吗?
-
内存原生CRAM技术将会颠覆计算存储的未来?
-
浅析SSD性能与NAND速率的关联
-
关于SSD LDPC纠错能力的基础探究
-
存储系统如何规避数据静默错误?
-
PCIe P2P DMA全景解读
-
深度解读NVMe计算存储协议
-
浅析不同NAND架构的差异与影响
-
SSD基础架构与NAND IO并发问题探讨
-
字节跳动ZNS SSD应用案例解析
-
CXL崛起:2024启航,2025年开启新时代
-
NVMe SSD:ZNS与FDP对决,你选谁?
-
浅析PCI配置空间
-
浅析PCIe系统性能
-
存储随笔《NVMe专题》大合集及PDF版正式发布!