文章目录
- 第一题
- 问题描述
- 解决思路
- 第二题
- 问题描述
- 解决思路
- 核心大表如何优化
- 数据迁移过程是怎么样的
- 如何将流量从旧系统迁移到新系统上
- 第三题
- 问题描述
- 解决思路
- 第四题
- 问题描述
- 解决思路
- 方案一:双写机制
- 方案二:基于时间戳的分流机制
- 方案三:灰度发布与监控
- 方案四:数据同步工具优化
- 第五题
- 问题描述
- 解决思路
- 高TPS和高QPS的接口如何优化?
- 请求合并是什么?有什么优势?如何实现?
- 聊聊CPU飙高时的排查过程以及解决的过程?
- 线上遇到一个接口很慢怎么办?
- MySQL亿级大表如何优化
- 流量突增百万如何保障系统高可用?
- 第六题
- 问题描述
- 解决思路
- SIT(系统集成测试)
- UAT(用户验收测试)
- 金丝雀发布
- 灰度发布
- 回归测试
- 第七题
- 问题描述
- 解决思路
- 第八题
- 问题描述
- 第九题
- 问题描述
- 回答思路
- 第十题
- 问题描述
- 解决思路
- 第十一题
- 问题描述
- 解决思路
- 第十二题
- 问题描述
- 回答思路
- 第十三题
- 问题描述
- 问题分析
- 其他问题
- 文件上传的分片上传,秒传,断点续传
- 组长要我改HTTP2 我通过spring-boot-starter-undertow实现HTTP2后 但是前端访问不到 他说他前端是通过ReadableStream流来访问的,我查使用Flux去读写ReadableStream流 但是我不知道怎么去测试了 一直报错
- 要使用netty写一个基于UDP协议的物联网设备服务器,有没有什么参考资料
第一题
问题描述
Java怎么调用 Python算法等其他语言的代码呀,有个需求要跟第三方对接,有Python写的算法,又有C# 的代码,不知道如何调用与对接
解决思路
以python为例: 通过网络接口(例如HTTP REST API),将Python或C#代码封装在一个服务中,然后从Java进行网络请求调用这些服务
1,在windows本地安装python环境 可以参考 https://blog.csdn.net/xzz_777c/article/details/138125089
2,将python程序作为一个第三方服务 需要安装Flask 安装步骤如下:
- 安装Python:由于Flask是一个Python Web框架,首先必须确认安装了Python。可以在官方网站下载Python的安装包,并按照提示进行安装。安装完成后,通过在终端输入以下命令来检查Python是否已经成功安装:
python --version。 - 安装virtualenv:为了防止不同项目间的依赖版本冲突,推荐在虚拟环境中进行Flask的开发。可以使用下面的命令安装virtualenv:
pip install virtualenv。然后创建并激活一个名为"venv"的虚拟环境:virtualenv venv,之后激活虚拟环境的命令为:在Windows使用venv\Scripts\activate,在Linux或macOS使用source venv/bin/activate。 - 安装Flask:在确保Python和virtualenv已经安装,并且虚拟环境已经激活后,就可以通过下面的命令来安装Flask:
pip install Flask。这个命令将自动安装Flask及其相关依赖包

3,编译一段python web案例 保存到windows 并运行
# app.py
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/hello')
def hello():
return jsonify(message="Hello from Python!")
if __name__ == '__main__':
app.run(port=5000)
运行示意图:

访问浏览器

4, 通过REST API调用Python代码
package com.spzx.demo01;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
public class ApiCaller {
public static void main(String[] args) {
try {
// 创建一个URL对象,指向目标API地址
URL url = new URL("http://localhost:5000/hello");
// 打开一个到该URL的连接
HttpURLConnection con = (HttpURLConnection) url.openConnection();
// 设置请求方法为GET
con.setRequestMethod("GET");
创建一个BufferedReader来读取服务器响应的内容
BufferedReader in = new BufferedReader(new InputStreamReader(con.getInputStream()));
String inputLine;
// 逐行读取响应内容,并将其添加到content中
StringBuffer content = new StringBuffer();
while ((inputLine = in.readLine()) != null) {
content.append(inputLine);
}
// 关闭BufferedReader和连接
in.close();
con.disconnect();
// 输出响应内容
System.out.println(content.toString());
} catch (Exception e) {
e.printStackTrace();
}
}
}
第二题
问题描述
最近遇到了几个问题不知道怎么解决1、核心大表如何优化;2、数据迁移过程是怎么样的;3、如何将流量从旧系统迁移到新系统上
解决思路
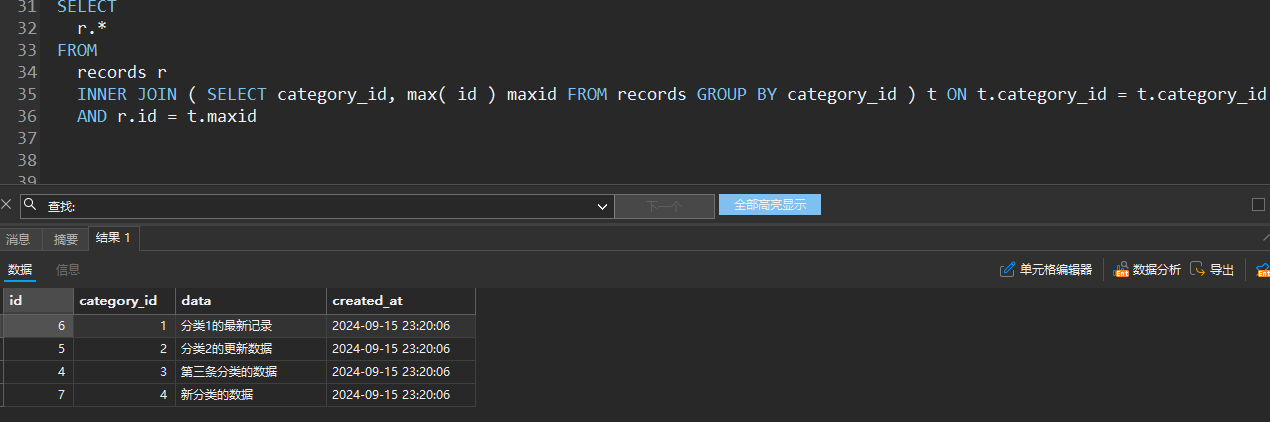
核心大表如何优化
案例背景
假设一个电商系统,其中有一个大表叫做orders,该表有数百万条记录,并且这张表几乎每时每刻都在被插入新数据或更新。用户反馈订单查询速度慢,需要优化。
一、问题背景
- 查看慢查询日志。
- 检查索引使用情况:利用explain或命令分析查询,查看是否缺少索引或者索引未被正确使用。
- 分析表结构:查看表的字段类型,是否有不必要的大字段,如blob或text,它们可能导致行迁移,影响性能。
二、方案
- 规范化: 如果发现某些字段并不经常使用,可以将其拆分到单独的表中。
- 反规范化:如果查询经常联合多个表,考虑将一些字段合并到一个表中以减少连接操作。
- 索引优化:添加或优化索引,包括使用复合索引来满足多个查询条件。
- 分区表:如果表非常巨大,考虑按时间或其他逻辑分区。
- 归档旧数据:不常用的历史数据可以移动到归档表中,或者使用olap数据库存储。
- 更改引擎:例如,从innodb切换到myisam(只读表),或者相反。
- 优化查询语句:改写sql查询,避免全表扫描和不必要的加载。
三、实施优化
- 数据备份:在执行任何操作前,确保对数据库进行完整备份。
- 逐项实施:一次只实施一项优化措施,并进行测试。
- 索引优化:创建或调整索引
- 修改表结构:如有必要,进行表的规范化或反规范化操作。
- 实施分区:如果选择了分区策略,根据业务逻辑实施它。
- 数据归档:将旧数据移到另一个表或数据库中。
- 更改存储引擎:如果决定更改存储引擎,确保测试其对性能的影响。
数据迁移过程是怎么样的
数据迁移通常涉及将数据从一个数据库或存储系统迁移到另一个数据库或存储系统
案例背景
假设我们有一个旧系统使用MySQL数据库存储数据,现在需要将数据迁移到新的PostgreSQL数据库中。
步骤1:准备环境
-
设置旧数据库(MySQL)和新数据库(PostgreSQL)
- 确保旧的MySQL数据库和新的PostgreSQL数据库都已设置好,并且可以通过JDBC连接。
- 创建新的PostgreSQL数据库表结构,这个表结构应该与MySQL数据库中的表结构匹配。
-
添加依赖
- 在Java项目的
pom.xml文件中添加MySQL和PostgreSQL的JDBC驱动依赖。
<dependencies> <!-- MySQL JDBC Driver --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.23</version> </dependency> <!-- PostgreSQL JDBC Driver --> <dependency> <groupId>org.postgresql</groupId> <artifactId>postgresql</artifactId> <version>42.2.18</version> </dependency> </dependencies> - 在Java项目的
步骤2:建立数据库连接
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class DatabaseUtils {
private static final String MYSQL_URL = "jdbc:mysql://localhost:3306/old_database_atguigu";
private static final String MYSQL_USER = "root";
private static final String MYSQL_PASSWORD = "root";
private static final String POSTGRES_URL = "jdbc:postgresql://localhost:5432/new_database_atguigu";
private static final String POSTGRES_USER = "root";
private static final String POSTGRES_PASSWORD = "root";
public static Connection getMySqlConnection() throws SQLException {
return DriverManager.getConnection(MYSQL_URL, MYSQL_USER, MYSQL_PASSWORD);
}
public static Connection getPostgresConnection() throws SQLException {
return DriverManager.getConnection(POSTGRES_URL, POSTGRES_USER, POSTGRES_PASSWORD);
}
}
步骤3:读取和迁移数据
import java.sql.*;
public class DataMigration {
public static void main(String[] args) {
try {
Connection mysqlConn = DatabaseUtils.getMySqlConnection();
Connection postgresConn = DatabaseUtils.getPostgresConnection();
String selectSQL = "SELECT id, name, email FROM users";
PreparedStatement selectStmt = mysqlConn.prepareStatement(selectSQL);
ResultSet resultSet = selectStmt.executeQuery();
String insertSQL = "INSERT INTO users (id, name, email) VALUES (?, ?, ?)";
PreparedStatement insertStmt = postgresConn.prepareStatement(insertSQL);
while (resultSet.next()) {
insertStmt.setInt(1, resultSet.getInt("id"));
insertStmt.setString(2, resultSet.getString("name"));
insertStmt.setString(3, resultSet.getString("email"));
insertStmt.executeUpdate();
}
resultSet.close();
selectStmt.close();
insertStmt.close();
mysqlConn.close();
postgresConn.close();
System.out.println("迁移完成!");
} catch (SQLException e) {
e.printStackTrace();
}
}
}
步骤4:验证迁移结果
迁移完成后,编写一个简单的验证程序来检查新数据库中的数据是否正确迁移。
import java.sql.*;
public class DataVerification {
public static void main(String[] args) {
try {
Connection postgresConn = DatabaseUtils.getPostgresConnection();
String selectSQL = "SELECT id, name, email FROM users";
PreparedStatement selectStmt = postgresConn.prepareStatement(selectSQL);
ResultSet resultSet = selectStmt.executeQuery();
while (resultSet.next()) {
System.out.println("ID: " + resultSet.getInt("id"));
System.out.println("Name: " + resultSet.getString("name"));
System.out.println("Email: " + resultSet.getString("email"));
}
resultSet.close();
selectStmt.close();
postgresConn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
如何将流量从旧系统迁移到新系统上
案例背景
假设我们有一个电子商务平台,该平台的旧系统(System A)使用传统的单体架构,并且已经在生产环境中运行多年。现在,团队决定将系统迁移到新的微服务架构(System B)上,以提高系统的可扩展性和维护性。
迁移步骤
- 评估和规划
- 评估现状:了解System A的现有功能、流量模式和瓶颈。
- 确定迁移策略:决定是一次性迁移(Big Bang)还是逐步迁移(Incremental)。在本案例中,我们选择逐步迁移,以降低风险。
- 搭建新系统(System B)
- 设计微服务架构:根据业务需求,设计新的微服务架构。
- 实现核心功能:在System B中实现旧系统的核心功能。
- 搭建基础设施:部署服务注册中心、API网关、负载均衡等基础设施。
- 双写模式
- 双写策略:在System A中实现数据写入时,同时向System B写入数据。这可以通过改造旧系统的代码或使用中间件实现。
- 数据同步:确保数据在两个系统中保持一致。可以使用数据同步工具或自定义脚本。
- 流量切换
- 灰度发布:逐步将流量从System A切换到System B。例如,先切换10%的流量,观察系统表现,然后逐步增加比例。
- 监控和回滚机制:在流量切换过程中,设置监控报警机制,确保新系统稳定运行。一旦发现问题,可以迅速回滚流量到旧系统。
- 功能验证
- 功能测试:在每次流量切换后,进行全面的功能测试,确保新系统的各项功能正常。
- 性能测试:对新系统进行压力测试,确保其能承受实际生产环境中的流量。
- 全面切换
- 全量切换:当灰度发布阶段顺利完成后,可以进行全量切换,将所有流量导入新系统。
- 下线旧系统:确认新系统稳定运行后,可以逐步下线旧系统。
具体案例中的关键点
- 双写策略的实现
- 代码改造:在旧系统的数据库操作代码中,增加对新系统API的调用,将数据同步写入新系统。
- 中间件使用:使用消息队列(如Kafka)进行数据双写。旧系统将数据写入消息队列,新系统从队列中消费数据进行处理。
- 流量切换的实现
- API网关配置:在API网关中配置流量分配策略,将一定比例的请求转发到新系统。
- 负载均衡策略:使用负载均衡器(如Nginx),根据预设的规则进行流量分配。
- 监控和回滚机制
- 监控系统:使用监控工具(如Prometheus和Grafana)实时监控新系统的性能和健康状态。
- 自动回滚:设置自动回滚机制,一旦监控到关键指标异常,立即将流量回滚到旧系统。
第三题
问题描述
Redis的大Key问题如何解决:怎么检测出大Key 和大Key怎么拆分,网上看了一些方案,感觉都是纸上谈兵没有实际操作o(╥﹏╥)o
解决思路
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.1</version>
</dependency>
具体案例idea中演示
第四题
问题描述
关于旧系统迁移到新系统的问题,我考虑使用canal假扮从库从主库拉取新数据。但这个方案有问题,当需要拉取的数据比较多时,一定有主从延迟导致新数据还没有从旧库迁移到新库,这个时候如果引流,将旧系统的部分流量引到新系统,而此时刚好有一个访问旧系统的请求想要访问新数据,但这个新数据还没同步到新系统,该怎么办?
解决思路
方案一:双写机制
- 描述:在数据迁移过程中,将所有对旧系统的写操作同时写入新系统。
- 实现步骤
- 修改旧系统的代码,使得每次有写操作时,同时写入新系统的数据库。
- 可以使用消息队列(如Kafka)来保证数据写入的顺序和可靠性。
- 确保新系统能够处理这些并发写入,并保证数据一致性。
- 优点
- 能够确保新系统数据的实时性和一致性。
- 迁移过程中可以随时切换流量,不会出现数据不一致问题。
- 缺点
- 需要对旧系统进行改造,工作量较大。
- 需要保证双写操作的原子性和幂等性,避免数据重复或丢失。
方案二:基于时间戳的分流机制
- 描述:通过记录数据的时间戳,来判断数据是否已经迁移完毕,并进行分流处理。
- 实现步骤
- 在数据迁移过程中,记录每一条数据的最后修改时间。
- 新系统和旧系统的访问请求都带有时间戳参数。
- 当请求到达时,根据时间戳判断数据是否已经迁移到新系统,如果数据尚未迁移则路由到旧系统。
- 优点
- 无需对旧系统进行大的改动。
- 能够保证数据访问的一致性。
- 缺点
- 实现较为复杂,需要对请求进行额外处理。
- 时间戳精度要求较高,可能会存在极端情况下的数据延迟。
方案三:灰度发布与监控
- 描述:逐步将流量引导到新系统,实时监控数据一致性,发现问题及时回滚。
- 实现步骤
- 初期将一小部分流量引导到新系统,剩余流量仍然访问旧系统。
- 实时监控新系统的数据一致性,特别是新写入的数据是否能及时同步到新系统。
- 逐步增加引流比例,直到所有流量全部切换到新系统。
- 在发现数据不一致或同步延迟较大时,及时回滚流量到旧系统。
- 优点
- 风险可控,问题可以在早期发现并解决。
- 可以逐步验证新系统的稳定性和性能。
- 缺点
- 实施周期较长,需要反复监控和调整。
- 需要较为完善的监控和回滚机制。
方案四:数据同步工具优化
- 描述:使用更高效的数据同步工具,减少主从延迟。
- 实现步骤
- 评估现有的Canal同步方案,优化同步参数和配置。
- 引入其他高效的数据同步工具,如Maxwell等,比较不同工具的性能和延迟。
- 配置实时监控和告警,确保数据同步的延迟在可接受范围内。
- 优点
- 无需对现有系统进行大的改动。
- 能够有效减少数据同步的延迟。
- 缺点
- 需要对不同同步工具进行调研和测试。
- 无法彻底避免同步延迟,只能尽量减小。
第五题
问题描述
面试被问麻了,动不动就是亿级大表和百万高并发: 1. 高TPS和高QPS的接口如何优化? 2. 请求合并是什么?有什么优势?如何实现? 3. 聊聊CPU飙高时的排查过程以及解决的过程? 4. 线上遇到一个接口很慢怎么办? 5. MySQL亿级大表如何优化? 6. 流量突增百万如何保障系统高可用?
解决思路
高TPS和高QPS的接口如何优化?
高TPS(每秒事务数)和高QPS(每秒查询数)接口的优化策略包括以下几点:
- 缓存:使用缓存来减少数据库或远程服务的请求。例如,使用Redis、Memcached等缓存系统。
- 异步处理:对于不需要实时响应的操作,可以使用异步处理,避免阻塞主线程。JUC异步编排
- 负载均衡:使用负载均衡器(如Nginx、HAProxy)将请求分发到多个服务器,分散负载。
- 数据库优化:优化SQL查询,添加索引,使用读写分离,分库分表等。
- 连接池优化:使用数据库连接池(如HikariCP、Druid)来复用数据库连接,减少连接建立和关闭的开销。
- 代码优化:优化代码逻辑,减少不必要的计算和IO操作。
- 压缩和批处理:对于大量小请求,可以通过压缩或批处理的方式减少请求次数和数据传输量。
- 限流和降级:使用限流和降级策略(如Guava RateLimiter、Sentinel)来应对突发流量,保障系统稳定性。
请求合并是什么?有什么优势?如何实现?
请求合并(Request Merging)是一种将多个相同或相似的请求合并成一个请求处理的技术。
优势:
- 减少请求数量:合并多个请求为一个,可以减少网络IO,提高系统吞吐量。
- 节省资源:合并请求减少了处理开销,节省了CPU、内存等资源。
- 提升性能:减少了请求的处理次数和延迟,提高了系统的整体性能。
实现方法:
- 批量处理:将多个请求合并为一个批量请求进行处理。例如,将多条插入操作合并为一条批量插入操作。
- 异步处理:使用异步队列(如Disruptor)将多个请求合并在一起,然后由一个消费者处理。
- 缓存和合并:使用缓存系统(如Guava Cache)暂存请求,然后定期从缓存中取出合并处理。
聊聊CPU飙高时的排查过程以及解决的过程?
arthas https://arthas.aliyun.com/doc/
https://github.com/alibaba/arthas/issues/1202
排查CPU飙高的过程包括以下步骤:
- 监控和报警:通过监控系统(如Prometheus、Grafana)检测到CPU使用率异常。
- 查看进程和线程:使用
top、htop、vmstat等工具查看系统进程和线程的CPU使用情况。 - 分析Java应用:使用
jstack生成线程栈,查看是否有线程在进行高CPU占用的操作。 - 分析GC:使用
jstat、jvisualvm等工具查看垃圾回收情况,是否有频繁GC导致CPU飙高。 - 性能分析:使用性能分析工具(如YourKit、JProfiler)进行应用的性能分析,找出CPU热点代码。
- 日志分析:查看应用日志,是否有异常操作或大量日志输出导致CPU占用高。
解决过程:
- 优化代码逻辑,减少CPU密集型操作。
- 调整GC参数,减少频繁GC对CPU的影响。
- 进行系统扩容,增加服务器资源。
- 使用限流、降级等策略,减少系统负载。
- 优化数据库查询,减少高CPU消耗的复杂查询。
线上遇到一个接口很慢怎么办?
https://github.com/alibaba/arthas/issues/1202
解决接口慢的问题可以按以下步骤进行:
- 监控和报警:通过监控系统检测到接口响应时间异常。
- 日志分析:查看接口的调用日志,分析响应时间和请求参数。
- 链路追踪:使用分布式链路追踪工具(如SkyWalking、Zipkin)分析请求在各个微服务中的耗时。
- 数据库查询:分析接口涉及的数据库查询,查看是否有慢查询,可以通过增加索引、优化SQL等方式解决。
- 代码优化:查看接口实现代码,是否有性能瓶颈,如循环嵌套、复杂计算等。
- 缓存优化:使用缓存减少数据库或远程服务的调用,提升响应速度。
- 负载均衡:查看接口服务器的负载情况,是否需要增加服务器实例,分散压力。
- 限流和降级:对于高并发请求,可以使用限流和降级策略,保护接口不被过载。
MySQL亿级大表如何优化
优化MySQL亿级大表的方法包括:
- 分库分表:将大表按某种规则(如按时间、用户ID)拆分为多个小表,分布到不同的数据库中。
- 索引优化:添加适当的索引,提高查询性能,避免使用全表扫描。
- 查询优化:优化SQL查询,避免复杂的JOIN操作和子查询,使用索引覆盖查询。
- 数据归档:将历史数据归档到其他表或数据库,减少主表的数据量。
- 分区表:使用MySQL的分区表功能,将大表按某种规则进行分区,提高查询性能。
- 垂直拆分:将表按列拆分为多个表,减少单表的宽度,提高查询性能。
- 读写分离:使用主从复制,将读操作分配到从库,减轻主库的压力。
- 缓存应用: redis
流量突增百万如何保障系统高可用?
保障系统在流量突增情况下的高可用性可以采用以下策略:
- 弹性扩容:使用容器化技术(如Docker、Kubernetes),根据流量自动扩展服务实例,增加处理能力。
- 负载均衡:使用负载均衡器(如Nginx、HAProxy)分发请求,均衡服务器负载。
- 缓存:使用缓存系统(如Redis、Memcached)缓存热点数据,减少数据库和应用服务器的压力。
- 限流和降级:使用限流和降级策略(如Guava RateLimiter、Sentinel),限制高并发请求,保护系统不被过载。
- 异步处理:将耗时操作异步化,避免阻塞主线程,提高系统响应速度。
- 数据库优化:优化数据库查询,增加索引,使用读写分离和分库分表,提升数据库性能。
- 监控和报警:使用监控系统(如Prometheus、Grafana)实时监控系统性能,及时发现和处理异常情况。
- 备份和恢复:定期备份数据,建立灾备系统,确保系统在故障时能够快速恢复。
第六题
问题描述
老师能讲讲SIT、UAT、金丝雀发布、灰度发布、回归测试等一些知识吗?刚进公司同事们聊的这些东西都听不懂,如果公司要我进行这些测试或者配合测试我应该如何做呢?应该怎么实践而不是只能聊?谢谢老师。
解决思路
因地制宜 每个公司的具体操作细则是不一样的
SIT(系统集成测试)
定义:系统集成测试是指将多个组件或系统集成在一起进行测试,确保它们在一起协同工作时的正确性。SIT通常在开发阶段完成,目标是发现集成问题。
如何做:
- 准备测试环境:确保所有相关组件和系统都已部署在测试环境中。
- 编写测试用例:覆盖所有集成点和交互场景。
- 执行测试:按照测试用例执行测试,记录结果和发现的问题。
- 修复和回归:对发现的问题进行修复,并执行回归测试以确保修复没有引入新的问题。
UAT(用户验收测试)
定义:用户验收测试是由最终用户或客户进行的测试,以确保系统满足其业务需求和要求。UAT通常在发布前进行。
如何做:
- 定义测试用例:与用户或客户合作,定义覆盖业务需求的测试用例。
- 准备测试环境:确保测试环境尽可能与生产环境一致,并准备好测试数据。
- 执行测试:用户根据测试用例执行测试,记录结果和反馈。
- 修复问题:根据用户反馈修复问题,并可能需要重新进行UAT。
金丝雀发布
定义:金丝雀发布是一种逐步发布的策略,先将新版本部署到一部分用户(通常是较小的一部分),在确认没有问题后,再逐步推广到所有用户。
如何做:
- 选择金丝雀用户:选择一部分用户作为金丝雀用户,可以是特定的用户群体或随机选择的用户。
- 部署新版本:将新版本部署到金丝雀用户所使用的服务器或实例上。
- 监控和反馈:密切监控金丝雀用户的反馈和系统性能,发现问题立即回滚或修复。
- 全面发布:在确认金丝雀发布没有问题后,将新版本推广到所有用户。
灰度发布
定义:灰度发布是逐步将新版本的系统功能在一部分用户中进行验证,在确保稳定后再逐步扩大到全部用户。与金丝雀发布类似,但灰度发布通常分阶段逐步增加新版本的用户比例。
如何做:
- 阶段性发布:定义发布阶段,每个阶段逐步增加新版本的用户比例。
- 监控和反馈:在每个阶段监控用户反馈和系统性能,发现问题及时处理。
- 逐步推广:如果当前阶段没有问题,继续扩大新版本的用户范围,直到覆盖所有用户。
回归测试
定义:回归测试是指在修改或升级系统后,重新进行的测试,以确保新代码没有引入新的问题并且没有破坏现有功能。
如何做:
- 选择回归测试用例:选择覆盖修改和关键功能的测试用例。
- 自动化测试:尽量使用自动化测试工具(如JUnit、TestNG)进行回归测试,提高效率和准确性。
- 执行测试:执行回归测试,记录结果和发现的问题。
- 修复和重新测试:对发现的问题进行修复,并重新执行回归测试,确保问题已解决。
实践建议
- 了解项目需求和背景:在进行测试前,先了解项目的业务需求和背景,以便更好地设计测试用例。
- 使用版本控制:使用版本控制工具(如Git)管理测试用例和测试代码,确保一致性和可追溯性。
- 搭建测试环境:熟悉测试环境的搭建和配置,确保测试环境尽可能与生产环境一致。
- 编写自动化测试脚本:尽量编写自动化测试脚本,提高测试效率和覆盖率。
- 参与团队沟通:积极参与团队的测试计划和进度讨论,了解测试任务和进展。
- 学习和使用测试工具:掌握常用的测试工具和框架,如Selenium、JMeter、Postman等。
第七题
问题描述
云服务器出故障导致生产环境出现了问题,要人工介入修正数据,这个所谓的人工介入和修正/钉数据是个什么操作,老师可以结合案例说明讲讲嘛
解决思路
在生产环境中,如果云服务器出故障导致数据出现问题,需要进行人工介入和修正数据。这里的人工介入和修正数据指的是运维人员或开发人员手动介入,检查和修正由于故障引起的错误数据,确保系统恢复正常运行。这种操作一般包括数据校验、修正和钉数据(数据锁定),以防止错误数据进一步传播和影响系统。
案例:在线电商系统中的人工介入和数据修正
场景描述
假设管理一个在线电商平台,突然由于云服务器故障导致订单处理系统出现问题,部分订单状态未能正确更新。这可能导致一些订单的支付状态不一致,影响客户体验和财务结算。
操作步骤
-
确认问题
首先,需要确认问题的范围和影响:
- 检查日志和监控系统,确定哪些订单受到影响。
- 与相关团队(如客服、财务)沟通,了解问题的具体表现和客户反馈。
- 数据备份
在进行任何数据修正操作之前,务必备份当前数据:
- 可以使用数据库的备份工具(如MySQL的mysqldump)导出受影响的订单数据。
mysqldump -u username -p database_name orders --where="order_status='pending'" > backup_orders.sql
- 数据校验和分析
分析备份数据,确定需要修正的数据项:
- 比如,检查订单状态和支付状态是否一致。
- 使用SQL查询找出不一致的记录。
SELECT order_id, order_status, payment_status
FROM orders
WHERE order_status = 'pending' AND payment_status = 'completed';
- 人工修正数据
根据分析结果,编写SQL语句或使用管理工具(如phpMyAdmin)进行数据修正:
- 更新受影响订单的状态。
UPDATE orders
SET order_status = 'completed'
WHERE order_status = 'pending' AND payment_status = 'completed';
- 数据钉固(锁定)
为了防止在修正过程中数据再次被错误更新,可以临时锁定相关数据表或记录:
- 使用数据库的锁定机制,例如MySQL的表锁或行锁。
LOCK TABLES orders WRITE;
-- Perform data correction
UPDATE orders
SET order_status = 'completed'
WHERE order_status = 'pending' AND payment_status = 'completed';
UNLOCK TABLES;
- 数据验证
修正数据后,进行验证,确保所有问题已解决:
- 重新运行校验查询,确认不再有不一致的记录。
- 检查系统日志和监控,确保没有新的异常。
- 恢复系统
确认数据修正无误后,解锁数据表,并通知相关团队系统已恢复正常。
第八题
问题描述
从一个word表格模板(内容可编辑)导出为word,考虑到后续有较多的模板,这个功能是后端实现还是前端实现方便点
通常情况下,这种操作更适合在后端实现,原因如下:
- 性能:生成Word文档涉及较多的文件读写操作和处理,如果在前端进行处理,可能会增加客户端的负担,影响用户体验。后端服务器通常有更强的处理能力,可以更高效地完成这些任务。
- 安全性:后端处理可以更好地保护模板和数据的安全,避免敏感信息暴露在客户端。
- 统一管理:在后端实现文档生成可以更容易统一管理和维护多个模板,前端则需要处理不同浏览器的兼容性问题。
第九题
问题描述
要用ueditor富文本实现将图片,文档,表格,音视频等各种附件的上传至服务器,网上搜索了只有php的解决方案,没有java的 ,我想知道是否有此业务实现的合适方案
回答思路
参考博客园
https://www.cnblogs.com/liuhd/articles/5900396.html
第十题
问题描述
将pdf文件用HttpServletResponse.getOutputStream()返回前端文件名称乱码
解决思路
// 处理文件名的编码,确保浏览器正确显示中文文件名
String encodedFileName;
String userAgent = request.getHeader("User-Agent");
if (userAgent.contains("MSIE") || userAgent.contains("Trident")) {
// IE浏览器
encodedFileName = URLEncoder.encode(fileName, "UTF-8");
} else {
// 其他浏览器
encodedFileName = new String(fileName.getBytes("UTF-8"), "ISO-8859-1");
}
// 设置响应头,告诉浏览器以附件形式下载,并指定文件名
response.setHeader("Content-Disposition", "attachment; filename=\"" + encodedFileName + "\"");
第十一题
问题描述
有个需求需要对接一个采用webService方式的接口,参数跟返回的都是xml格式,请求方式是http协议,post请求。不知道怎么写,
解决思路
Web服务(Web Service)是一种基于网络的应用程序接口(API),可以通过标准的Web协议(如HTTP、XML、SOAP等)进行通信。它允许不同的应用程序在网络上互相通信,实现数据交换和远程调用。Web服务通常采用面向服务架构(SOA)的思想,通过使用标准化的协议和格式来实现不同平台和语言之间的互操作性。
Spring Boot 中的 RestTemplate 可以实现 具体可以参考springCloud教学课件
第一步: 声明一个RestTemplateConfiguration 表示开启远程调用功能
@Configuration
public class RestTemplateConfiguration {
@Bean
public RestTemplate restTemplate() {
return new RestTemplate() ;
}
}
第二步: 注入RestTemplate远程调用工具
关键代码: getForObject(URL,class)
restTemplate.getForObject(“http://localhost:10100/api/user/findUserByUserId/” + order.getUserId(), User.class);
@Service
public class OrderServiceImpl implements OrderService {
@Autowired // 注入RestTemplate远程调用工具
private RestTemplate restTemplate ;
@Autowired
private OrderMapper orderMapper ;
@Override
public Order findOrderByOrderId(Long orderId) {
// 根据id查询订单数据
Order order = orderMapper.findOrderByOrderId(orderId);
// 发起远程调用
User user = restTemplate.getForObject("http://localhost:10100/api/user/findUserByUserId/" + order.getUserId(), User.class);
order.setUser(user);
// 返回订单数据
return order;
}
}
第三步: jackson-dataformat-xml 使用该工具可以返回xml格式的数据
第十二题
问题描述
需要在网关上提供一个接口供别人调用,别人调用这个接口传过来的数据用Rocketmq接收。接收过后,每次消费15-20条左右生成文本存入FTP中,供后续功能采集。
回答思路
//接收外部请求并将数据发送到RocketMQ
@RestController
@RequestMapping("/api/data")
public class DataController {
@Autowired
private RocketMQTemplate rocketMQTemplate;
@PostMapping
public ResponseEntity<String> receiveData(@RequestBody List<String> data) {
rocketMQTemplate.convertAndSend("topic-data", data);
return ResponseEntity.ok("Data received and sent to RocketMQ");
}
}
// 案例 每次消费15-20条消息,并将处理后的数据存储到FTP服务器
@Component
@RocketMQMessageListener(topic = "topic-data", consumerGroup = "data-consumer-group")
public class DataConsumer implements RocketMQListener<List<String>> {
private static final int BATCH_SIZE = 15;
@Override
public void onMessage(List<String> messages) {
List<List<String>> batches = partitionList(messages, BATCH_SIZE);
for (List<String> batch : batches) {
String content = String.join("\n", batch);
uploadToFTP(content);
}
}
private List<List<String>> partitionList(List<String> list, int size) {
List<List<String>> partitions = new ArrayList<>();
for (int i = 0; i < list.size(); i += size) {
partitions.add(list.subList(i, Math.min(i + size, list.size())));
}
return partitions;
}
private void uploadToFTP(String content) {
FTPClient ftpClient = new FTPClient();
try {
ftpClient.connect("ftp.example.com", 21);
ftpClient.login("username", "password");
ftpClient.enterLocalPassiveMode();
ftpClient.setFileType(FTP.BINARY_FILE_TYPE);
InputStream inputStream = new ByteArrayInputStream(content.getBytes(StandardCharsets.UTF_8));
boolean done = ftpClient.storeFile("/path/to/store/file.txt", inputStream);
inputStream.close();
if (done) {
System.out.println("File uploaded successfully.");
}
} catch (IOException ex) {
ex.printStackTrace();
} finally {
try {
if (ftpClient.isConnected()) {
ftpClient.logout();
ftpClient.disconnect();
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
第十三题
问题描述
低代码二开,后续市场咋样?会不会逐渐成为一种主流开发模式,还是说原生开发依旧是主流
若依
问题分析
其他问题
文件上传的分片上传,秒传,断点续传
了解腾讯云中声音点播