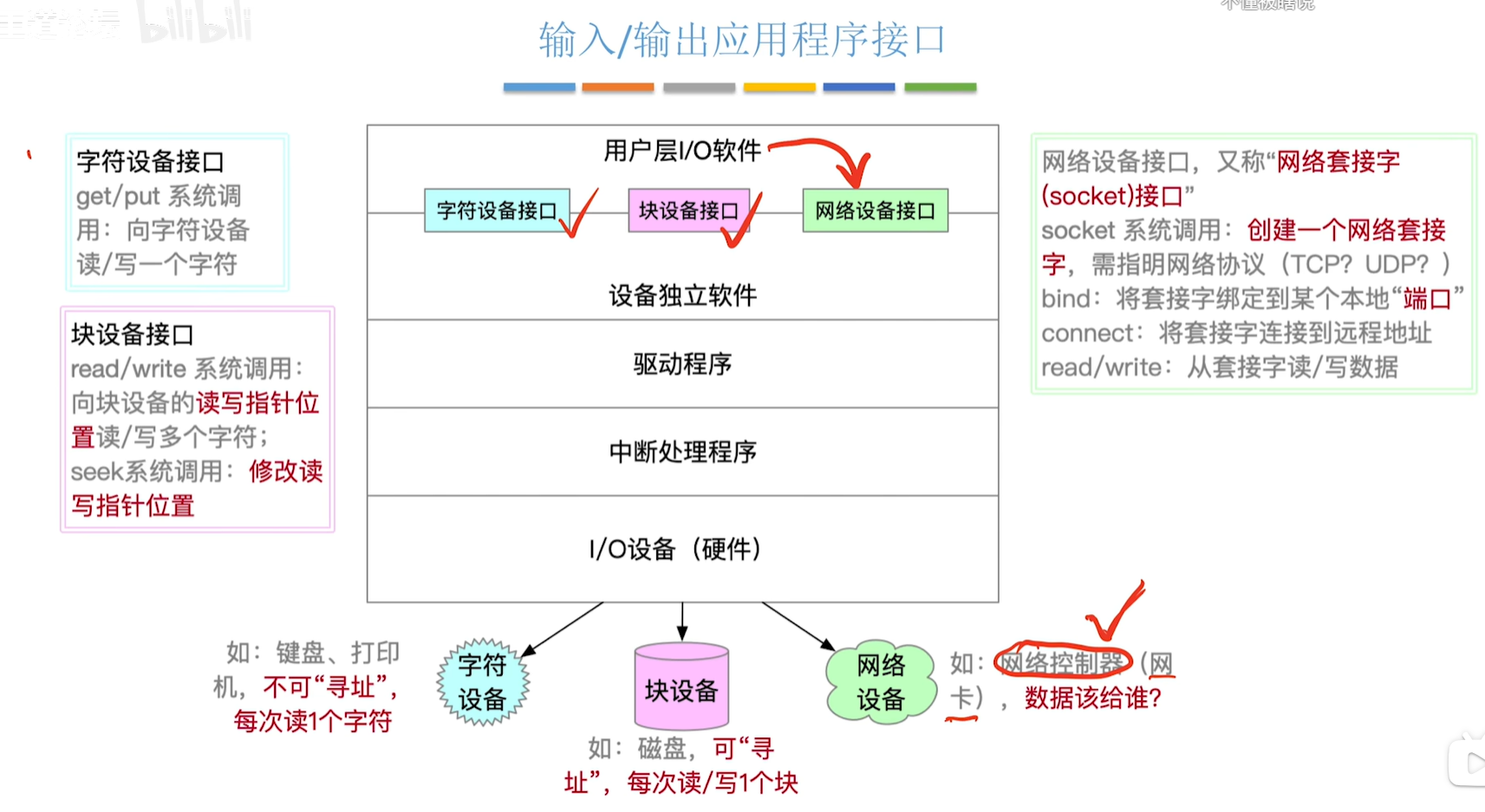
自注意力机制和多头自注意力机制在深度学习,尤其是Transformer模型中是核心组件。它们的主要区别在于如何处理输入信息和增强模型的表达能力。
1. 自注意力机制(Self-Attention)
自注意力机制的主要作用是让模型在处理每个输入元素时,能够“关注”输入序列中的其他元素,从而捕捉全局依赖关系。它计算每个元素与序列中所有其他元素的相关性(注意力权重),并基于这些权重来更新输入。
自注意力的核心步骤:
- 生成查询(Q)、键(K)、值(V)矩阵:对于每个输入元素,生成三个向量:查询(Query)、键(Key)、值(Value),分别表示输入与其他元素的相关性、比对的依据和要输出的值。
- 计算注意力权重:通过查询和键的点积,计算每个元素与其他元素的相似度,然后使用softmax归一化得到注意力权重。
- 加权求和:使用注意力权重对值向量进行加权求和,生成更新后的输入表示。
这种机制能够捕捉到输入序列中的全局信息,但它只使用了单一的注意力头,可能限制了捕捉多样化特征的能力。
下图附上自注意力模块的计算过程图:

2. 多头自注意力机制(Multi-Head Self-Attention)
多头自注意力机制是对自注意力机制的扩展,能够增强模型的表达能力和捕捉不同层面信息的能力。与单头自注意力不同,多头自注意力将输入分为多个子空间,每个子空间使用一个独立的自注意力机制进行计算,最后将这些结果拼接起来。
多头自注意力的核心步骤:
- 多组查询、键、值矩阵:将输入通过不同的线性变换生成多个查询、键、值矩阵(每组称为一个注意力头)。
- 并行计算多组注意力:每个注意力头独立计算注意力权重和加权和,处理相同的输入但在不同的子空间上工作。
- 拼接结果并线性变换:将所有注意力头的输出拼接起来,通过一个线性层进一步融合这些信息。
多头自注意力的优势:
- 多样性:通过多个注意力头,模型能够在不同的子空间中关注不同的特征,捕捉到更多样化的全局信息。
- 鲁棒性:多头机制使得模型在计算注意力时可以从多个角度理解输入序列中的关系,增强了模型的鲁棒性和泛化能力。
- 同样附上多头自注意力机制的计算过程图

区别总结:
- 单头 vs. 多头:自注意力机制是单一的,模型只能从一个角度计算注意力,而多头自注意力机制通过多个独立的注意力头进行计算,使得模型能够捕捉更丰富的特征。
- 子空间处理:多头机制将输入划分为多个低维子空间,使得每个注意力头可以专注于输入的不同部分,从而提升模型对不同特征的表达能力。
- 计算复杂度:虽然多头自注意力的计算量较大,但通过并行计算多个注意力头,提升了模型的表现力,而不会显著增加计算开销。
对比其两张图片也可得知两者之间的差别
总结:
多头自注意力机制是对自注意力机制的扩展,通过并行的多个注意力头增强了模型的多样性和全局特征捕捉能力,使得Transformer模型在自然语言处理和计算机视觉等任务中表现优异。