目录
前言:
1.开散列
1. 开散列概念
2. 开散列实现
2.1哈希链表结构体的定义
2.2哈希表类即私有成员变量
2.3哈希表的初始化
2.4迭代器的实现
1.迭代器的结构
2.构造
3.*
4.->
5.++
6.!=
2.5begin和end
2.6插入
2.7Find查找
2.8erase删除
3.unordered_map的封装
4.unordered_set的封装
5.5. 开散列与闭散列比较
前言:
我建议大家看过我《哈希表的底层实现之闭散列(C++)》、《红黑树模拟实现STL中的map与set——C++》这两篇文章之后再来看这一篇,因为这一篇的一部分哈希实现和一部分unordered_map和unordered_set的实现原理是建立在这两篇的基础之上的。
1.开散列
1. 开散列概念
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地 址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链 接起来,各链表的头结点存储在哈希表中。
从上图可以看出,开散列中每个桶中放的都是发生哈希冲突的元素。
2. 开散列实现
2.1哈希链表结构体的定义
//哈希链表 template<class T> struct HashNode { T _data; HashNode<T>* _next; HashNode(const T& data) :_data(data) , _next(nullptr) {} };跟闭散列不同,这回我们的结构体里就没有状态码的设置了,因为我们这回是以链表的方式进行哈希桶的实现来处理哈希冲突,所以我们需要next指针指向产生哈希冲突的元素。
2.2哈希表类即私有成员变量
template<class K,class T,class KeyofT,class Hash> class Hashtable { //typedef HashNode<T> Node; using Node = HashNode<T>; private: vector<Node*> _tables; size_t _n; };我们的私有成员变量就两个,一个是std库里的vector容器,它里面的元素就是我们的一个个链表;然后再来一个_n代表有效元素的个数。
大家可能发现了我们的重命名是using Node = HashNode<T>;这个写法是C++11的语法,我们后面会专门用一篇文章来讲解C++11的语法。
2.3哈希表的初始化
//初始化 Hashtable() :_n(0) { _tables.resize(10,nullptr); }我们这里就不弄的那么复杂,我们就简单开一个10空间大小的vector就可以了。
2.4迭代器的实现
在讲哈希表的增删查改之前我们要先来讲一下迭代器,因为我们后续的实现是建立在迭代器之上的。
我们本篇采用内部类的方式来进行迭代器的思想,将迭代器包在哈希表实现的里面。
1.迭代器的结构
//内部类实现迭代器 template<class Ptr,class Ref> struct __HIterator { typedef HashNode<T> Node; typedef __HIterator<Ptr,Ref> Self; Node* _node; const Hashtable* _pht; };这里Ptr和Ref的作用还是跟之前一样,分别代表数据的指针和引用。然后里面我们对哈希链表和迭代器本身进行重命名,我们还需要哈希链表类型的变量以及哈希表指针类型的变量,具体都有什么作用,在后续的讲解中我们就会知道了。
2.构造
//构造 __HIterator(Node* node, const Hashtable* pht) :_node(node) ,_pht(pht) {}构造我们就采用哈希链表的节点指针以及整个哈希表的指针来进行初始化。因为迭代器的操作实际上都是对哈希表进行操作,所以我们需要知道具体的哈希表是哪个,然后确定是哪个节点。
3.*
//* Ref operator*() { return _node->_data; }解引用就返回我们的数据就好了。
4.->
//-> Ptr operator->() { return &_node->_data; }->的作用自然就是返回我们的数据的地址。
5.++
//++ Self& operator++() { if (_node->_next) { _node = _node->_next; } else { Hash hs; KeyofT kot; size_t hashi = hs(kot(_node->_data)) % _pht->_tables.size(); ++hashi; while (hashi<_pht->_tables.size()) { if (_pht->_tables[hashi]) break; hashi++; } if (hashi == _pht->_tables.size()) { _node = nullptr; } else { _node = _pht->_tables[hashi]; } } return *this; }++的操作就是为了让我们找到下一个元素。我们是以一个个链表的形式进行存储的,所以我们要先在本条链表里访问完,再进行其它链表的访问。因此,我们的第一步就是访问本条链表的next节点,如果next节点有数据,我们就返回访问到这个数据的迭代器,如果next节点的位置为NULL,我们就要计算当前节点的哈希值,计算出来后继续访问下一个哈希值,如果下一个哈希值所指向的位置是空的,那么我们就要将hash++,继续往下找直到不为空。倘若后续没有数据了,我们就将_node设为空,否则将数据赋值给_node。
6.!=
//!= bool operator!=(const Self& s) { return _node != s._node; }!=操作就是把两迭代器的_node进行一下比对就好了。
2.5begin和end
typedef __HIterator<T*, T&> iterator; typedef __HIterator<const T*, const T&> const_iterator; //begin iterator begin() { for (size_t i = 0; i < _tables.size(); i++) { if (_tables[i]) { return iterator(_tables[i], this); } } return end(); } //end iterator end() { return iterator(nullptr, this); } //const begin const_iterator begin() const { for (size_t i = 0; i < _tables.size(); i++) { if (_tables[i]) { return const_iterator(_tables[i], this); } } return end(); } //const end const_iterator end() const { return const_iterator(nullptr, this); }我们先将我们所写的普通迭代器和const迭代器进行一下重命名,然后进行接下来的操作。
我们的begin()就是哈希值为0的元素,end()就是为空的元素。我们再分别为他们实现const修饰的版本。
2.6插入
//插入 pair<iterator,bool> Insert(const T& data) { Hash hs; KeyofT kot; iterator it = Find(kot(data)); if (it!=end()) { return make_pair(it,false); } if (_n == _tables.size()) { vector<Node*> newtables(_tables.size() * 2, nullptr); for (size_t i = 0; i < _tables.size(); i++) { Node* cur = _tables[i]; while (cur) { Node* next = cur->_next; size_t hashi = hs(kot(cur->_data)) % newtables.size(); cur->_next = newtables[hashi]; newtables[hashi] = cur; cur = next; } _tables[i] = nullptr; } _tables.swap(newtables); } size_t hashi = hs(kot(data)) % _tables.size(); Node* newNode = new Node(data); //头插 newNode->_next = _tables[hashi]; _tables[hashi] = newNode; ++_n; return make_pair(iterator(_tables[hashi], this), true); }在解决完前置内容之后,我们就要来进行插入操作的讲解了。我们先来看插入操作的返回值类型,大家是不是感到很疑惑?为什么是pair类型的呢?我也不卖关子,这实际上是为了我们后续对其进行封装时能够更加方便而设计的。我们先来把当个功能的思路搞懂,等我后面封装的时候大家就很清楚了。
我们先用Find函数来查找一下这个元素是否存在,如果存在,我们直接返回,如果不存在,我们就可以进行后续的操作了。如果有效元素个数_n跟表的有效空间相等,我们就要进行扩容操作。我们先创个两倍大小的新表,然后将旧表的内容拷贝到新表中,同时不要忘记了我们拷贝到新表的时候要重新计算哈希值,因为我们的表的有效空间已经变了。
扩完容之后我们在进行插入,我们先计算要插入的数据的哈希值,然后以头插的方式插入到哈希表当中。将有效元素++就好了。
2.7Find查找
//查找 iterator Find(const K& key) { Hash hs; KeyofT kot; size_t hashi = hs(key) % _tables.size(); Node* cur = _tables[hashi]; while (cur) { if (kot(cur->_data) == key) { return iterator(cur, this); } cur = cur->_next; } return end(); }查找就很简单了,我们只需要计算哈希值,然后循环查找就可以了。返回的类型为迭代器也是为了我们后续的封装。
2.8erase删除
//删除 bool Erase(const K& key) { Hash hs; KeyofT kot; size_t hashi = hs(key) % _tables.size(); Node* prev = nullptr; Node* cur = _tables[hashi]; while (cur) { if (kot(cur->_data) == key) { //删除的是第一个 if (prev == nullptr) { _tables[hashi] = nullptr; } else { prev->_next = cur->_next; } delete cur; _n--; return true; } prev = cur; cur = cur->_next; } return false; }删除操作也不复杂,我们只需要多一个prev节点记录当前节点的上一个节点就好了,我们的思路是这样的:我们先计算哈希值,然后用cur去指向哈希值所在的位置,如果当前位置没有数据,我们直接返回false,如果有我们就要看看是否与要删除的key值相等,若相等我们就要判断prev是否为空,为空就说明它是当前哈希值的第一个元素,我们就直接将当前哈希值的链表设为空就行,如果不为空,我们就要用prev链接cur的下一个节点。删除成功后不要忘记将n--。
3.unordered_map的封装
template<class K,class V,class Hash=HashFunc<K>> class unordered_map { struct MapkeyofT { const K& operator()(const pair<K,V>& kv) { return kv.first; } }; public: typedef typename Hashtable<K, pair<const K, V>, MapkeyofT, Hash>::iterator iterator; typedef typename Hashtable<K, pair<const K, V>, MapkeyofT, Hash>::const_iterator const_iterator; //begin() iterator begin() { return _ht.begin(); } //end() iterator end() { return _ht.end(); } //begin() const const_iterator begin() const { return _ht.begin(); } //end() const const_iterator end() const { return _ht.end(); } //[] V& operator[](const K& key) { pair<iterator, bool> ret = Insert(make_pair(key, V())); return ret.first->second; } //插入 pair<iterator, bool> Insert(const pair<K,V>& kv) { return _ht.Insert(kv); } private: Hashtable< K, pair<const K, V>, MapkeyofT, Hash> _ht; };unordered_map跟我之前那篇文章里map的封装非常类似,我这里就说说【】重载吧,insert为什么返回值是这个类型我们是参照标准库来定义的。(如图所示)
insert函数这么设计可以让我们重载【】的时候更加方便,我们可以直接复用它。
在说明【】前我们要知道【】能做什么?很简单,就是根据我们的key来返回对应的值。
我们知道插入成功或失败(表里有同样的数据)的时候都会返回它这个键值对,所以我们可以里利用这一点直接复用我们的insert然后取出我们的值就可以了。
4.unordered_set的封装
template<class K,class Hash=HashFunc<K>> class unordered_set { struct SetkeyofT { const K& operator()(const K& key) { return key; } }; public: typedef typename Hashtable<K,const K, SetkeyofT, Hash>::iterator iterator; typedef typename Hashtable<K,const K, SetkeyofT, Hash>::const_iterator const_iterator; //begin() iterator begin() { return _ht.begin(); } //end() iterator end() { return _ht.end(); } //begin() const const_iterator begin() const { return _ht.begin(); } //end() const const_iterator end() const { return _ht.end(); } //插入 pair<iterator, bool> Insert(const K& key) { return _ht.Insert(key); } //find iterator Find(const K& key) { return _ht.Find(key); } //erase bool Erase(const K& key) { return _ht.Erase(key); } private: Hashtable< K,const K, SetkeyofT, Hash> _ht; };unordered_set的封装跟set也是非常相似,没有什么新鲜的东西,只要看过我 《红黑树模拟实现STL中的map与set——C++》这篇文章的同学看这里的代码就几乎没什么难度。
5.5. 开散列与闭散列比较
应用链地址法处理溢出,需要增设链接指针,似乎增加了存储开销。事实上: 由于开地址法必须保持大量的空闲空间以确保搜索效率,如二次探查法要求装载因子a ,而表项所占空间又比指针大的多,所以使用链地址法反而比开地址法节省存储空间。
unordered_map/set(底层实现)——C++
news2026/2/14 22:20:28



本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2149932.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

mybatisplus中id生成策略
使用Tableld(value,type)
1.typeIdType.AUTO自增主键
2.typeIdType.ASSIGN,雪花算法生成 mybatisplus id生成策略全局配置
配置表前缀以及id生成策略 mybatis-plus:global-config:db-config:id-type: autotable-prefix: :t_

热点|创邻图查询范式引爆LDBC TUC2024
2024年8月30日至31日,创邻科技Galaxybase团队联合蚂蚁集团TuGraph团队、阿里巴巴GraphScope团队共同主办第18届LDBC TUC会议。在本次会议中,来自全球图数据库领域的学者和技术专家做了很多精彩的分享,共同探讨图技术的最新进展。创邻科技Gala…
![EC Shop安装指南 [ Apache PHP Mysql ]](https://i-blog.csdnimg.cn/direct/7eece64910bc48649a0c43507ad06bcf.png)
EC Shop安装指南 [ Apache PHP Mysql ]
这个是软件测试课上老师布置的一个作业,期间老师也出现了不少错误,所以还是有必要记录一下吧,凑一篇文章
主要是老师的文档以及自己的一些尝试记录,试错记录,解决方案等
主要介绍了Apache的安装,MySQL的安…

weblogic CVE-2020-14882 靶场攻略
漏洞描述 32 CVE-2020-14882 允许远程⽤户绕过管理员控制台组件中的身份验证。 CVE-2020-14883 允许经过身份验证的⽤户在管理员控制台组件上执⾏任何命令。 使⽤这两个漏洞链,未经身份验证的远程攻击者可以通过 HTTP 在 Oracle WebLogic 服务器上执⾏任意命令并…

基于协同过滤算法+PHP的新闻推荐系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、SSM项目源码 系统展示
【2025最新】基于协同过滤算法PHPMySQL的新…

基于Java的房地产在线营销管理系统研究与实现
目录
前言
功能设计
系统实现
获取源码 博主主页:百成Java
往期系列:Spring Boot、SSM、JavaWeb、python、小程序 前言
随着信息技术的迅猛发展,互联网已经渗透到我们生活的方方面面,为各行各业带来了前所未有的变革。房地产…


8585 栈的应用——进制转换
### 思路 1. **初始化栈**:创建一个空栈用于存储转换后的八进制数的每一位。 2. **十进制转八进制**:将十进制数不断除以8,并将余数依次入栈,直到商为0。 3. **输出八进制数**:将栈中的元素依次出栈并打印,…

navicate连接oracle数据库probable oracle net admin error
没用过oracle数据库 1、数据库版本19c;
使用dbeaver连接是没有问题的 使用navicate一直报错
解决方案: oracle官网下载win64的OCI环境 https://www.oracle.com/database/technologies/instant-client/winx64-64-downloads.html
下载好的压缩包直接解…
Git入门学习(1)
Git
00.准备工作-gitee注册 今天Git的设置中需要用到gitee的注册信息,先自行完成注册工作,可以 参考笔记 或第二天视频(10.Git远程仓库-概念和gitee使用准备) 传送门:
gitee(码云):https://gitee.com/
注…

Hutool树结构工具-TreeUtil构建树形结构
1 pom.xml
<dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.26</version>
</dependency>
2 核心代码
import cn.beijing.satoken.domain.ZhiweiCityArea;
import cn.beijing.sa…

Superset二次开发之优化Mixed Chart 混合图(柱状图+折线)
背景 基于Mixed Chart(柱状图+折线)作图,显示 某维度A Top10 + 其他 数据,接口返回了值为 undefined 的某维度A 数据,前端渲染成 某维度A 值为 0 此图表存在的问题: 图表控件编辑页面,即便数据集正常查询出 Top10 + ‘其他’ 数据,但是堆积图表渲染时,返回了 值为 0…
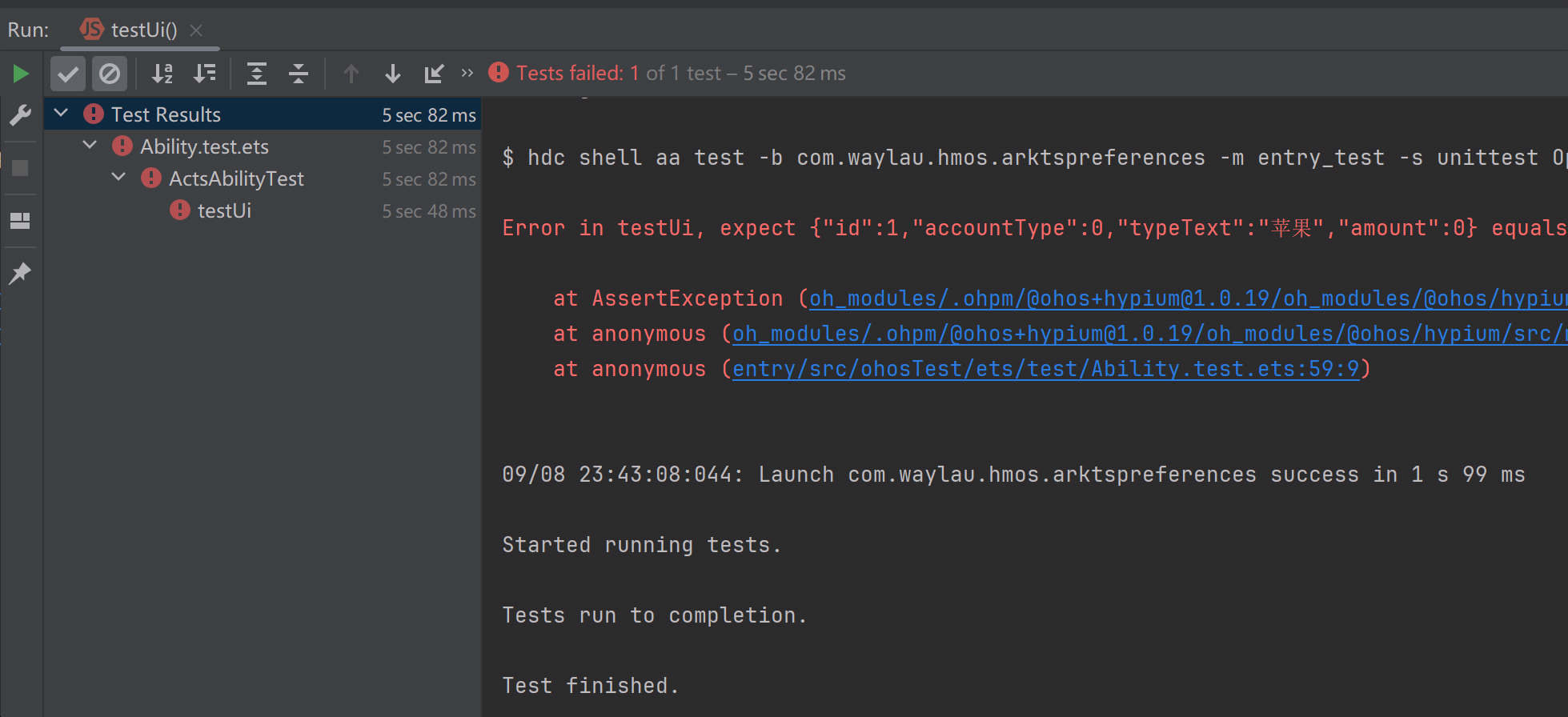
HarmonyOS ArkTS 用户首选项的开发及测试
本节以一个“账本”为例,使用首选项的相关接口实现了对账单的增、删、改、查操作,并使用自动化测试框架arkxtest来对应用进行自动化测试。
为了演示该功能,创建一个名为“ArkTSPreferences”的应用。应用源码可以在文末《跟老卫学HarmonyOS开…
恢复已删除文件的可行方法,如何恢复已删除的文件
在清理 PC 或优化存储设备时无意中删除重要文件是一种常见的人为错误。不可否认,在批量删除文件时,您通常会一起删除垃圾文件和重要文件。您后来意识到一堆文件或文件中缺少一个重要的文档或文件。在这种情况下,您唯一的选择是寻找恢复已删除…

优思学院|如何通过六西格玛方法优化流程,减少90%的浪费?
随着竞争压力的增加和对更快结果的需求,越来越多的企业开始依赖精益六西格玛来优化流程,减少浪费。精益六西格玛不仅改变了制造业,也影响了几乎所有行业的业务运营,提升了效率,消除了低效环节。这里优思学院和大家探讨…

sheng的学习笔记-AI-强化学习(Reinforcement Learning, RL)
AI目录:sheng的学习笔记-AI目录-CSDN博客 基础知识
什么是强化学习
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体&#…

电机设计及电机仿真APP系列之—高速永磁同步电机仿真APP
电机的各种工作状态和参数变化。用户可通过调整仿真参数,快速得到电机的响应和性能参数,从而进行针对性的优化和改进。借助仿真APP,可大大减少电机设计迭代次数和成本,提高测试效率和准确性。
小编整理了10款不同类型的电机仿真A…
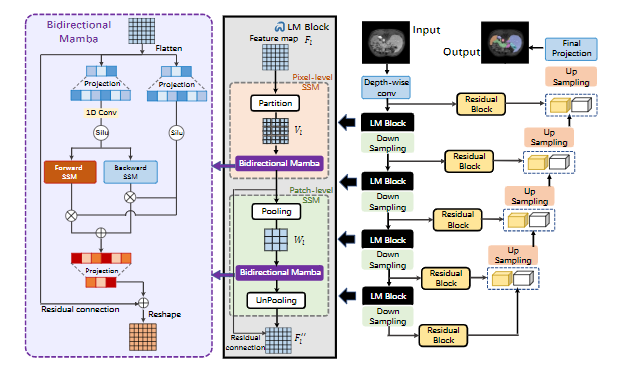
掌握顶会流量密码!“Mamba+CNN”双热点组合!轻松找到创新点!
传统视觉模型在处理大规模或高分辨率图像时存在一定限制。然而Mamba与CNN相结合,在处理序列数据和图像数据时有着显著的优势,并且能够有效提升模型计算效率和准确率。
这种结合可以让Mamba在处理长序列数据时既能够捕捉到序列中的时间依赖关系ÿ…

springboot整合springbatch和xxljob实现定时数据同步(完整代码)
springboot整合springbatch和xxljob实现定时数据同步(完整代码) 前言:公司一些老项目的定时任务使用spring自带的调度器来完成数据同步的,久而久之带来很多的不方便。首先没办法快速定位监控定时任务的执行情况,其次就…

c++11右值引用和移动语义
一.左值引用和右值引用
什么是左值引用,什么是右值引用
左值是一个表示数据的表达式(变量名解引用的指针),我们可以获取到它的地址,可以对它赋值,左值可以出现在符号的左边。使用const修饰后,…