文章目录
- 一、上篇博文复习
- 二、Separable Case
- 三、Non-separable Case
- 四、Considering Errors
- 五、Regularization
- 六、Structured SVM
- 七、Cutting Plane Algorithm for Structured SVM
- 八、Multi-class and binary SVM
- 九、Beyond Structured SVM
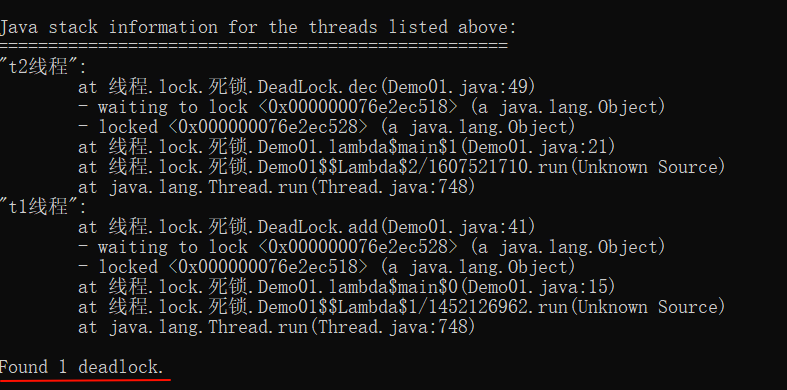
一、上篇博文复习


图中x表示输入的图片,y表示边界框,
ϕ
(
x
,
y
)
\phi (x,y)
ϕ(x,y)表示由x,y确定的特征强度,w表示需要训练学习的权重,

F(x,y)如果是线性的,是有很大的局限性。但如果F(x,y)不是线性的,本篇文章的后续推论,可能都不成立。所以这是一个尚待解决的问题。




二、Separable Case



也就是和y的个数没有关系。

ρ
\rho
ρ是两个向量的夹角,范围是[0,
π
\pi
π],所以
ρ
\rho
ρ越小,
cos
ρ
\cos \rho
cosρ就越大。


这里只证明的
cos
ρ
\cos \rho
cosρ的分子随着k的增大而增大,还需要看看分母是什么情况。


所有feature扩大两边,并不能加快训练。因为 δ \delta δ扩大两倍的同时,R也扩大了两倍。

三、Non-separable Case
在实际问题中很难找到Separable case的情况,即很难找到feature可以让正确和错误的分离,也不知道怎么找到它,所以要考虑Non-separable Case。


C的最小值是零。


除了边界值不能微分,其他地方都能微分。

四、Considering Errors

我们希望所选的
w
w
w, 使得y与正确的那个越接近,计算的
x
⋅
ϕ
x \cdot \phi
x⋅ϕ ,越大,即与正确的越接近。
这样做的好处是,即使testing和training有一些差距,即使testing的第一名不是正确的,但是所输出的第一名和正确的差距不会很大。





上界 C 变小,可能会使 C’ 随之也变小。


五、Regularization


六、Structured SVM

因为我们要最小化C,所以上图中的倒数第三行和倒数第二行等价的。

习惯上,这时我们就把
C
n
C^n
Cn写为
ε
n
\varepsilon^n
εn

本来是找w,去最小化C。即找到w后,
C
n
C^n
Cn就被决定了。
但是在黄色框中,定好w后,
ε
n
\varepsilon^n
εn并不能确定。所以条件要改成:Find
w
,
ε
1
,
⋯
,
ε
n
w,\varepsilon^1,\cdots,\varepsilon^n
w,ε1,⋯,εn minimizing C



由于约束条件,即不等式太多,可能会令w找不到,所以要放宽条件,不等式右边减去一个
ε
\varepsilon
ε (
ε
≥
0
\varepsilon \ge0
ε≥0)。但
ε
\varepsilon
ε又不能太大,否则w取任何值都能满足不等式,约束条件就失去意义了。


七、Cutting Plane Algorithm for Structured SVM













下面以 object detection 为例:


这里相当于
y
ˉ
\bar y
yˉ是有个函数公式,给定w后,直接能算出来哪个y最大。



八、Multi-class and binary SVM

这里y代表类别。y为哪个类别,就把
x
⃗
\vec x
x放在
ϕ
(
x
,
y
)
\phi(x,y)
ϕ(x,y)对应的维度上。




这里我们可以定义,只要类别不一样就定义为
Δ
(
y
^
n
,
y
)
=
1
\Delta (\widehat y^n,y)=1
Δ(y
n,y)=1
九、Beyond Structured SVM

















![[Simpfun游戏云1]搭建MC Java+基岩互通生存游戏服务器](https://i-blog.csdnimg.cn/direct/aabde7f742634a2db3d6695450a55f92.png)