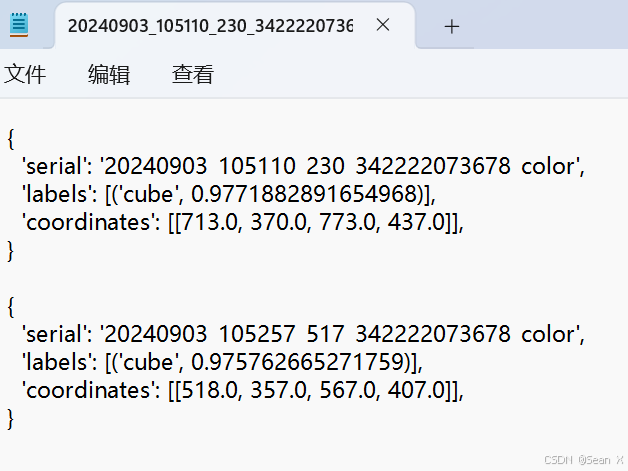
一般源码的测试代码涉及很多文件,因项目需要写一个独立测试的代码。传入的是字典
import time
import cv2
import os
import numpy as np
import torch
from modules.detec.models.common import DetectMultiBackend
from modules.detec.utils.dataloaders import LoadImages
from modules.detec.utils.general import (LOGGER, Profile, check_file, check_img_size, check_imshow, check_requirements, colorstr,
increment_path, non_max_suppression, print_args, scale_boxes, strip_optimizer, xyxy2xywh)
from modules.detec.utils.augmentations import letterbox
from modules.detec.utils.plots import Annotator, colors
class DetectionEstimation:
def __init__(self, model_path, conf_threshold=0.9, iou_threshold=0.45, img_size=(384,640)):
self.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
self.model = DetectMultiBackend(model_path).to(self.device)
self.conf_threshold = conf_threshold
self.iou_threshold = iou_threshold
self.img_size = img_size
def _preprocess_image(self, img_dict):
img_tensor_list = []
original_sizes = {}
for serial, img in img_dict.items():
original_size = img.shape[:2]
img_resized = letterbox(img, self.img_size, stride=32, auto=True)[0]
img_resized = img_resized.transpose((2, 0, 1))[::-1]
img_resized = np.ascontiguousarray(img_resized)
img_tensor = torch.from_numpy(img_resized).float().to(self.device)
img_normalized = img_tensor / 255
if len(img_normalized.shape) == 3:
img_normalized = img_normalized[None]
img_tensor_list.append(img_normalized)
original_sizes[serial] = original_size
image_input = torch.cat(img_tensor_list)
return image_input, original_sizes
def _postprocess_predictions(self, predictions, original_sizes):
results = {}
for i, (det, (serial, img)) in enumerate(zip(predictions, original_sizes.items())):
if det is not None and len(det):
det[:, :4] = scale_boxes(self.img_size, det[:, :4], img).round()
labels = []
coordinates = []
for *xyxy, conf, cls in reversed(det):
label = self.model.names[int(cls)]
labels.append((label, conf.item()))
coordinates.append([xyxy[0].item(), xyxy[1].item(), xyxy[2].item(), xyxy[3].item()])
results[serial] = {
'labels': labels,
'coordinates': coordinates
}
return results
def predict(self, img_dict):
start_total = time.time()
start_preprocess = time.time()
img_tensor, original_sizes = self._preprocess_image(img_dict)
preprocess_time = time.time() - start_preprocess
print(f"Preprocess Time: {preprocess_time * 1000:.2f}ms")
start_inference = time.time()
with torch.no_grad():
predictions = self.model(img_tensor)
inference_time = time.time() - start_inference
print(f"Inference Time:{inference_time * 1000:.2f}ms")
start_non_max_suppression = time.time()
predictions = non_max_suppression(predictions, self.conf_threshold, self.iou_threshold)
non_max_suppression_time = time.time() - start_non_max_suppression
print(f"Non-Max Suppression Time: {non_max_suppression_time * 1000:.2f}ms")
start_postprocess = time.time()
results = self._postprocess_predictions(predictions, original_sizes)
postprocess_time = time.time() - start_postprocess
print(f"Postprocess Time: {postprocess_time * 1000:.2f}ms")
total_time = time.time() - start_total
print(f"Total Processing Time: {total_time * 1000:.2f}ms")
print("res:",results)
return results
def draw_results(self, img_dict, results):
annotated_images = {}
for serial, img in img_dict.items():
if serial in results:
det = results[serial]['coordinates'] # 从 results 中提取处理后的坐标
labels = results[serial]['labels'] # 提取标签和置信度
annotator = Annotator(img, line_width=3, example=self.model.names)
for i, (xyxy, (label, conf)) in enumerate(zip(det, labels)):
# 生成标签信息
label_str = f'{label} {conf:.2f}'
# 绘制检测框和标签
annotator.box_label(xyxy, label_str, color=colors(i, True))
annotated_images[serial] = annotator.result()
return annotated_images
def _save_labels(self, results, output_folder, batch_size=3):
os.makedirs(output_folder, exist_ok=True)
img_serials = list(results.keys())
for i in range(0, len(img_serials), batch_size):
batch = img_serials[i:i + batch_size]
combined_filename = '_'.join(batch) + '_labels.txt'
labels_path = os.path.join(output_folder, combined_filename)
with open(labels_path, 'w') as file:
for serial in batch:
if serial in results:
result = results[serial]
file.write("{\n")
file.write(f" 'serial': '{result['serial']}',\n")
file.write(f" 'labels': {result['labels']},\n")
file.write(f" 'coordinates': {result['coordinates']},\n")
file.write("}\n\n")
if __name__ == "__main__":
model_path = 'data/pt/best.pt'
detector = DetectionEstimation(model_path)
img_folder = './data/images/'
img_dict = {}
img_filenames = []
for img_filename in os.listdir(img_folder):
img_path = os.path.join(img_folder, img_filename)
if img_path.lower().endswith(('.png', '.jpg', '.jpeg')):
img_data = cv2.imread(img_path)
serial = os.path.splitext(img_filename)[0]
img_dict[serial] = img_data
img_filenames.append(img_filename)
batch_size = 2
img_keys = list(img_dict.keys())
for i in range(0, len(img_keys), batch_size):
batch_dict = {k: img_dict[k] for k in img_keys[i:i + batch_size]}
results = detector.predict(batch_dict)
annotated_images = detector.draw_results(batch_dict, results)
os.makedirs('results', exist_ok=True)
for serial, img in annotated_images.items():
output_path = f'results/{serial}.jpg'
success = cv2.imwrite(output_path, img)
if not success:
print(f'Error saving image {output_path}')
else:
print(f'Successfully saved image {output_path}')
detector._save_labels(results, 'results/labels', batch_size=batch_size)
在该代码同级目录下放models、results、utils文件夹和export.py
运行该代码得到的txt文件是字典: