1、安装Tesseract Mac版本,通过Homebrew进行安装即可
brew install tesseractwindows版本安装
下载地址:https://digi.bib.uni-mannheim.de/tesseract/

2、更换语言包
下载语言包
https://github.com/tesseract-ocr/tesseract
亦可参照这个 Tesseract最新版语言包chi_sim.traineddata(4.0.0)GitHub官方获取免csdn积分,各个版本语言包全有_tesseract github releases-CSDN博客
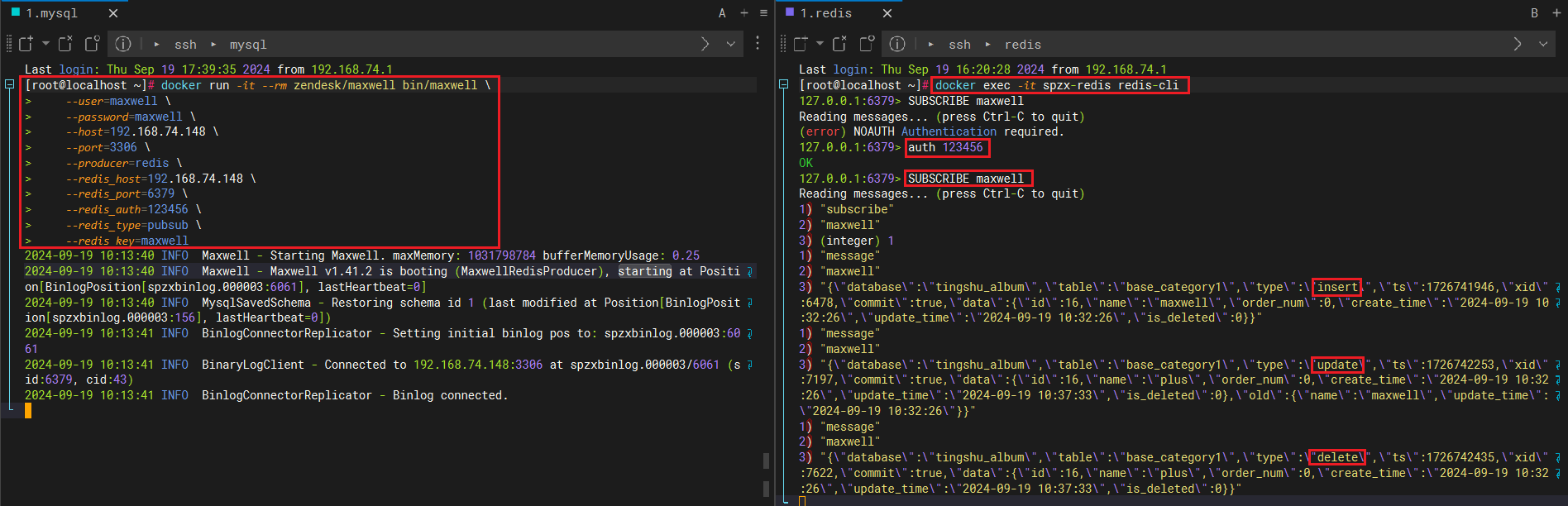
3、 程序
import os
from PIL import Image
import pytesseract
import re
import pandas as pd
# 如果你使用 Windows,指定 Tesseract 的安装路径
# pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# 1. 遍历文件夹中的所有图片并进行OCR识别
def process_images(folder_path, output_txt):
with open(output_txt, 'w', encoding='utf-8') as f:
for filename in os.listdir(folder_path):
if filename.endswith(('.png', '.jpg', '.jpeg', '.bmp', '.tiff')):
image_path = os.path.join(folder_path, filename)
print(f"Processing image: {filename}")
img = Image.open(image_path)
# 进行OCR识别
text = pytesseract.image_to_string(img, lang='chi_sim')
# 替换错误识别的符号为 ¥
text = text.replace('#', '¥')
text = text.replace('Y', '¥')
text = text.replace('*', '¥')
# 处理每一行中的多余空格
lines = text.splitlines()
processed_lines = []
for line in lines:
# 移除行内的字符间空格
processed_line = re.sub(r'\s', '', line)
processed_lines.append(processed_line)
processed_text = '\n'.join(processed_lines)
f.write(f"Image: {filename}\n")
f.write(processed_text)
f.write("\n" + "=" * 40 + "\n")
# 处理完图片后,清理txt文件并保存为新的文件
cleaned_txt_file = 'cleaned_' + output_txt # 创建清理后的文件名
clean_txt(output_txt, cleaned_txt_file) # 调用清理函数
print(f"Cleaned text saved to {cleaned_txt_file}")
return cleaned_txt_file
# 2. 清理txt文件中的无关内容,只保留指定信息
def clean_txt(txt_file, cleaned_txt_file):
headers = ["券码", "券类型", "套餐内容", "验证时间", "消费金额", "消费明细", "订单号", "验券账号"]
with open(txt_file, 'r', encoding='utf-8') as f:
lines = f.readlines()
with open(cleaned_txt_file, 'w', encoding='utf-8') as f:
buffer = ''
is_in_taocan = False # 标识是否在"套餐内容"部分
for line in lines:
line = line.strip()
if any(header in line for header in headers):
if "套餐内容" in line:
buffer += line # 如果遇到"套餐内容",开始处理
is_in_taocan = True
else:
if is_in_taocan: # 如果之前是在"套餐内容"内
f.write(buffer + '\n') # 把完整的"套餐内容"写入文件
buffer = '' # 清空buffer
is_in_taocan = False # 退出"套餐内容"模式
f.write(line + '\n') # 写入其他字段
elif is_in_taocan:
# 如果是在处理"套餐内容"部分,合并多行内容
buffer += line # 合并到buffer
else:
continue # 跳过非关键信息行
if buffer: # 写入最后一部分的"套餐内容"(如果有)
f.write(buffer + '\n')
# 运行流程
image_folder = '/pytorchPeoject/testDemo1/img/' # 图片文件夹路径
output_txt_file = 'output_02.txt' # 临时存储OCR结果的txt文件
# 执行图像处理和OCR识别,并清理txt文件
cleaned_txt_file = process_images(image_folder, output_txt_file) # 获取清理后的文件路径
# 打开并读取txt文件
with open(cleaned_txt_file, 'r', encoding='utf-8') as file:
data = file.read()
# 使用正则表达式提取需要的数据
pattern = re.compile(r'券码:(\d+)\s+券类型:(.+?)\s+套餐内容:(.+?)\s+验证时间:(\d{4}-\d{2}-\d{2})(\d{2}:\d{2}:\d{2})\s+消费金额:(.+?)\s+消费明细:(.+?)\s+订单号:(\d+)\s+验券账号:(\w+)')
matches = pattern.findall(data)
# 创建DataFrame
columns = ['券码', '券类型', '套餐内容', '验证时间', '时间', '消费金额', '消费明细', '订单号', '验券账号']
df = pd.DataFrame(matches, columns=columns)
# 合并验证时间和时间列
df['验证时间'] = df['验证时间'] + ' ' + df['时间']
df.drop('时间', axis=1, inplace=True)
# 保存到Excel文件
df.to_excel('output.xlsx', index=False)
print("数据提取并保存到Excel文件成功!")