数据结构入门学习(全是干货)——树(下)
1 堆 (Heap)
1.1 什么是堆
堆 (Heap) 是一种特殊的完全二叉树,分为最大堆和最小堆。
- 最大堆:每个节点的值都大于或等于其子节点的值,根节点是整个堆的最大值。
- 最小堆:每个节点的值都小于或等于其子节点的值,根节点是整个堆的最小值。
堆常用来实现优先队列,支持高效的最大值/最小值查找、插入和删除操作。
优先队列(Priority Queue):特殊的"队列",取出元素的顺序是依照元素的优先权(关键字)大小,而不是元素进入队列的先后顺序

是否可以采用二叉树存储结构?
- 二叉搜索树? 堆不是二叉搜索树,虽然堆可以用二叉树的形式表示,但它并不满足二叉搜索树的“左小右大”性质。
二叉树结构对插入与删除的影响
- 插入或删除时,堆的顺序如何安排? 堆通常存储在数组中,插入或删除元素时必须保持二叉树的完全性,并且调整堆的结构以满足最大堆或最小堆的性质。
优先队列的完全二叉树表示

- 堆通常用数组存储,每个节点的父节点和子节点的索引可以通过简单的数学运算确定:
- 父节点:
parent(i) = (i-1)/2 - 左子节点:
left(i) = 2*i + 1 - 右子节点:
right(i) = 2*i + 2
- 父节点:
堆的抽象数据类型描述
- 插入:
Insert(x)插入元素x到堆中,保持堆的有序性。 - 删除:
DeleteMax()或DeleteMin()删除堆中最大或最小的元素,保持堆的有序性。
1.2 堆的插入
在最大堆中插入一个新元素时,必须保持最大堆的特性,即每个父节点的值必须大于等于其子节点的值。
最大堆的插入步骤:
- 将新元素插入到堆的末尾。
- 比较新元素与其父节点的值,如果新元素比父节点大,则交换两者的位置。
- 重复此过程,直到新元素的父节点不再比它小,或者新元素成为根节点。
插入算法:
void insert(MaxHeap *H, int value) {
int i = ++H->size; // 将新元素插入堆的最后一个位置
for (; i > 1 && value > H->Elements[i / 2]; i /= 2) {
H->Elements[i] = H->Elements[i / 2]; // 向上移动父节点
}
H->Elements[i] = value; // 插入新元素
}
关键问题:
- “哨兵”:在堆的创建过程中,常常会在堆的数组索引 0 处设置一个“哨兵”元素,用于简化插入和删除操作。通常哨兵的值设为一个极大值(如
MaxData),使得堆中的其他值都比它小。

1.3 堆的删除
在最大堆中,删除操作通常指的是删除堆的根节点,即堆中的最大值。
最大堆的删除步骤:
- 取出堆的根节点(最大值),同时将堆的最后一个节点移到根位置。


- 比较新根节点与其子节点的值,选择较大的子节点与根节点交换,保持堆的有序性。
- 重复此过程,直到根节点不再比子节点小,或节点成为叶子节点。
删除算法:
int deleteMax(MaxHeap *H) {
int maxElement = H->Elements[1]; // 最大值
int temp = H->Elements[H->size--]; // 用最后一个元素填补根
int parent, child;
for (parent = 1; parent * 2 <= H->size; parent = child) {
child = parent * 2; // 左孩子
if (child != H->size && H->Elements[child] < H->Elements[child + 1]) {
child++; // 右孩子
}
if (temp >= H->Elements[child]) break; // 找到位置
H->Elements[parent] = H->Elements[child]; // 向下移动
}
H->Elements[parent] = temp; // 插入最后的元素
return maxElement; // 返回最大值
}
1.4 堆的建立
堆排序 是堆的一个常见应用,在堆排序中,我们首先需要将数组构建为一个堆。
最大堆的建立:
最大堆的建立可以通过下滤(Sift Down)方法,从堆中间位置开始,逐步调整每个子堆。
建立最大堆:将已经存在的N个元素按最大堆的要求存放在一个一维数组中
方法1:通过插入操作,将N个元素一个个相继插入到一个初始为空的堆中去,其时间代价最大为O(NlogN)
每次插入 它的时间复杂性是log2N
总共循环N遍,所以整个时间复杂性是Nlog2N
上方这个方法1的效率是不够的,我们可以有更好的方法
方法2:在线性时间复杂度下建立最大堆.
(1)将N个元素按输入顺序存入,先满足完全二叉树的结构特性
(2)调整各结点位置,以满足最大堆的有序特性
问题:
对于元素个数为12的堆,其各结点的高度之和是多少?答案是 10。

2 哈夫曼树与哈夫曼编码
2.1 什么是哈夫曼树
哈夫曼树(Huffman Tree) 又称为最优二叉树,是一种带权路径长度最短的树。带权路径长度(WPL)指的是所有叶子节点的权重乘以它们到根节点的路径长度之和。
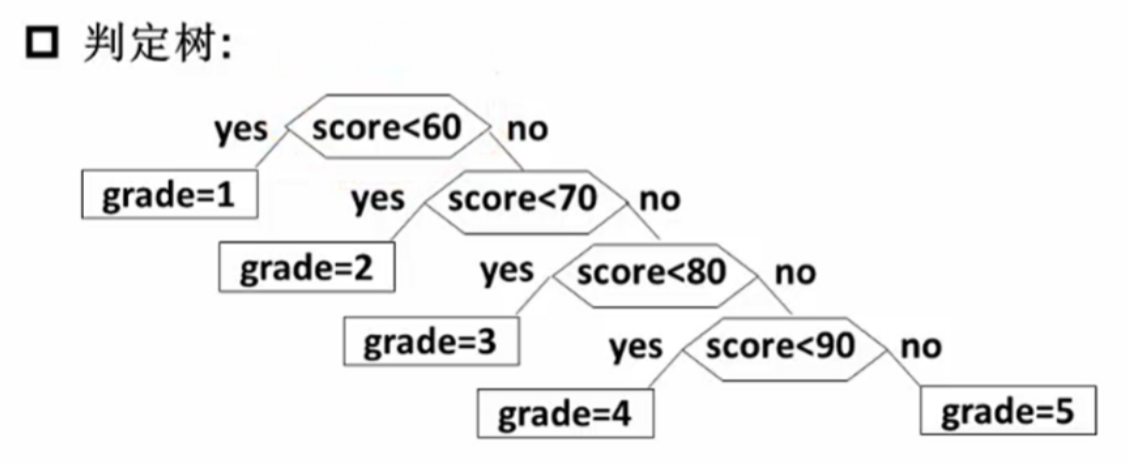
[例]将百分制的考试成绩转换成五分制的成绩
if(score < 60 ) grade = 1;
else if(score < 70) grade = 2;
else if(score < 80) grade = 3;
else if(score < 90) grade = 4;
else grade = 5;
上述代码中,其实对应着就有一棵树,如下图:

优化后的效率:

if(score < 80)
{
if(score < 70 )
if(score < 60) grade = 1;
else grade = 2;
}else if(score < 90 )grade = 4;
else grade = 5;
哈夫曼树的性质:
- 哈夫曼树是带权路径长度最小的二叉树。
- 没有度为1的节点。
- 如果有
n个叶子节点,则哈夫曼树有2n - 1个节点。
举例:
有5个叶子节点,它们的权值为 {1,2,3,4,5}。根据这些权值可以构造多个不同的二叉树,但哈夫曼树保证了最小的带权路径长度。
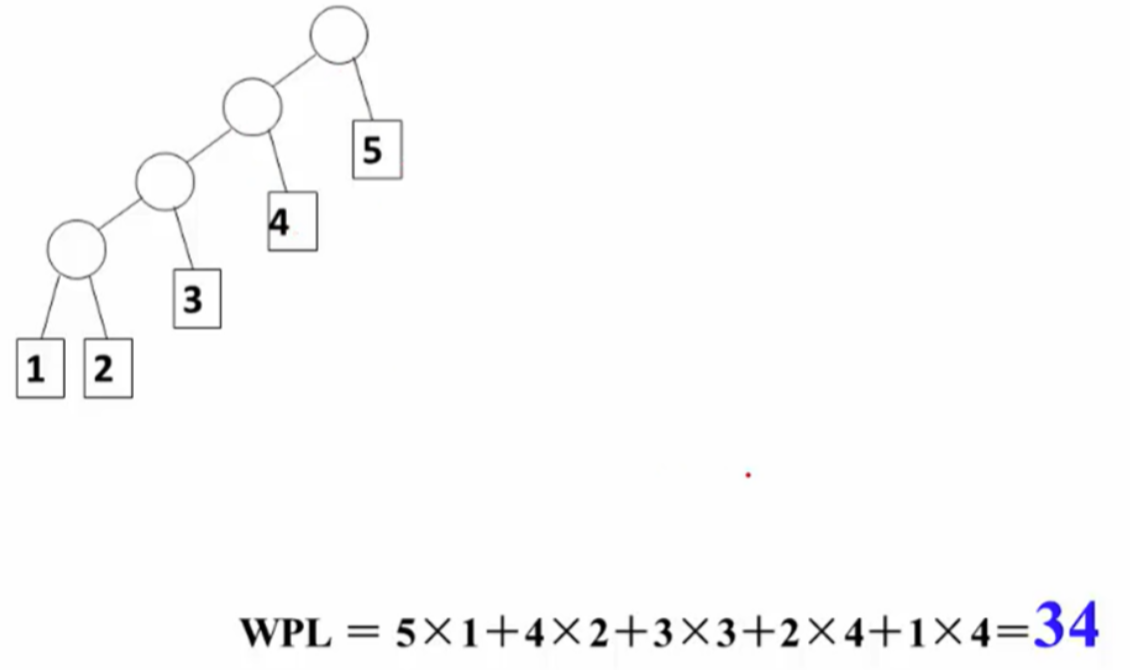

是50

2.2 哈夫曼树的构造
哈夫曼树的构造方法:
- 将所有节点看作一个森林,每棵树仅有一个节点,权重为该节点的权值。
- 每次选取权值最小的两棵树,合并成一棵新的树,新树的权值为两棵树的权值之和。
- 重复上述过程,直到所有节点被合并成一棵树。
typedef struct TreeNode *HuffmanTree;
struct TreeNode{
int Weight;
HuffmanTree Left,Right;
}
HuffmanTree Huffman(MinHeap H)
{
//假设H->Size个权值已经存在H->Elements[]->Weight里
int i; HuffmanTree T;
BuildMinHeap(H);//将H->Elements[]按权值调整为最小堆
for(i = 1;i < H->Size; i++){//做H->Size-1次合并
T = malloc(sizeof(struct TreeNode));//建立新结点
T->Left = DeleteMin(H);//从最小堆中删除一个结点,作为新T的左子结点
T->Right = DeleteMin(H);//从最小堆中删除一个结点,作为新T的右子结点
T->Weight = T->Left->Weight+T->Right->Weight;//计算新权值
Insert(H,T);//将新T插入最小堆
}
T = DeleteMin(H);
return T;
}
整体复杂度为O(NlogN)
哈夫曼树的特点:
- 没有度为1的节点。
- 任意非叶子节点的左右子树交换后仍是哈夫曼树。
- n 个叶子节点的哈夫曼树共有
2n - 1个节点。 
2.3 哈夫曼编码
哈夫曼编码是一种前缀编码法,用于对字符进行不等长编码,使得高频字符的编码较短,低频字符的编码较长,从而减少总的编码长度。
哈夫曼编码的步骤:
- 根据字符出现的频率构造哈夫曼树。
- 从根节点到叶子节点的路径表示字符的编码。向左分支为
0,向右分支为1。
举例:
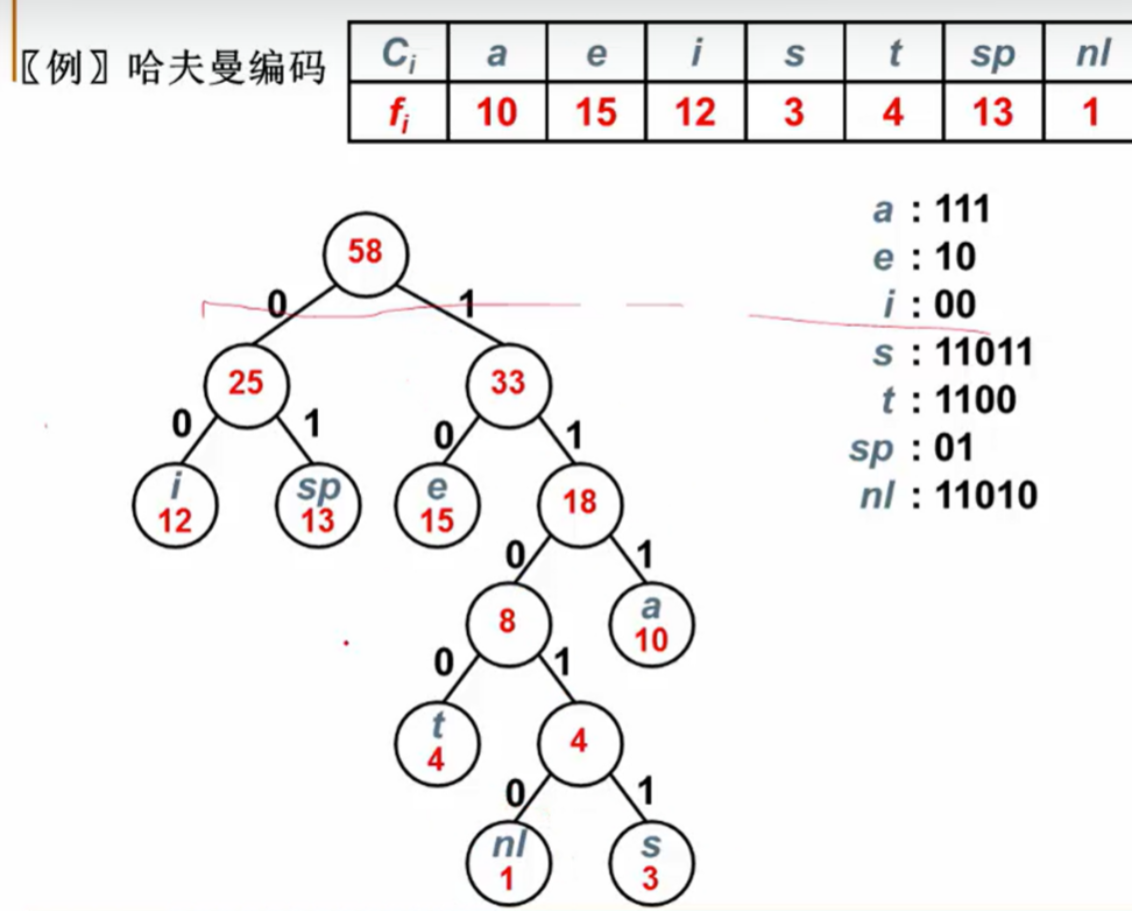
给定字符串 “AAABBCC”,用哈夫曼编码可以为频率高的字符 A 分配较短的编码(如 0),为频率低的字符 B 和 C 分配较长的编码。

分析:
-
用等长ASCII编码:58×8 = 464位
-
用等长3位编码:58×3 = 174位;
-
不等长编码:出现频率高的字符用的编码短些,出现频率低的字符则可以编码长些?
怎么进行不等长编码?
如何避免二义性(就是你这个编码不止一个意思)
-
前缀码prefix code:任何字符的编码都不是另一字符编码的前缀
- 可以无二义地解码(你的这个编码不能是其他编码的前缀)
-
二叉树用于编码:
-
左右分支:0、1
-
字符只在叶结点上
-

-

-

-
怎么构造一颗编码代价最小的二叉树?
-
-
3 集合及运算
3.1 集合的表示及查找
集合运算包括交集、并集、差集等操作。
并查集(Union-Find):
并查集是一种用于处理动态连通性问题的树形结构。它支持两个主要操作:
-
查找(Find):查找某元素所属的集合。
int Find(SetType S[],ElementType X) { //在数组S中查找值为X的元素所属的集合 //MaxSize是全局变量,为数组S的最大长度 int i; for(i = 0;i < MaxSize && S[i].Data != X; i++); if(i >= MaxSize) return -1;//未找到X,返回-1 for(;S[i].Parent >= 0; i = S[i].Parent);//Parent的值为-1的时候就是找到根结点。i = S[i].Parent:原本指向i的位置现在跳到了s[i].Parent return i;//找到X所属集合,返回树根结点在数组S中的下标 } -
合并(Union):合并两个元素所属的集合。
集合的树结构表示:
每个元素是一个节点,每个集合是由这些元素组成的树。根节点表示集合的代表元素,父节点指向上级节点。
3.2 集合的并运算
并运算的实现通过找到两个元素的根节点,然后将其中一个根节点指向另一个根节点。
void Union(SetType S[ ],ElementType X1,ElementType X2 )
{
int Root1,Root2;
Root1 = Find(S,X1);//得到X1与X2对应的树根
Root2 = Find(S,X2);
if( Root1 != Root2 ) S[Root2].Parent = Root1;//判断如果不是本身就是同一个集合的,如果是同一个集合的话就不需要做这个并的操作。不同则合并
}
优化:
为了减少树的高度,提高查找效率,可以采用按秩合并或按大小合并的方法,将较小的树合并到较大的树上。
小测验:
已知 a 和 b 均为所在集合的根节点,分别位于数组分量3和2位置上,parent值分别为-3和-2。按集合大小合并后,a 和 b 的 parent 值分别是 -5 和 3。
集合的定义与并查
#define MAXN 1000 /* 集合最大元素个数 */
typedef int ElementType; /* 默认元素可以用非负整数表示 */
typedef int SetName; /* 默认用根结点的下标作为集合名称 */
typedef ElementType SetType[MAXN]; /* 假设集合元素下标从0开始 */
void Union( SetType S, SetName Root1, SetName Root2 )
{ /* 这里默认Root1和Root2是不同集合的根结点 */
/* 保证小集合并入大集合 */
if ( S[Root2] < S[Root1] ) { /* 如果集合2比较大 */
S[Root2] += S[Root1]; /* 集合1并入集合2 */
S[Root1] = Root2;
}
else { /* 如果集合1比较大 */
S[Root1] += S[Root2]; /* 集合2并入集合1 */
S[Root2] = Root1;
}
}
SetName Find( SetType S, ElementType X )
{ /* 默认集合元素全部初始化为-1 */
if ( S[X] < 0 ) /* 找到集合的根 */
return X;
else
return S[X] = Find( S, S[X] ); /* 路径压缩 */
4 小白专场:堆中的路径

题目描述:
给定5个数据构成一个最小堆,并进行3次查询。查询的目的是给定堆中的某个节点,求从根节点到该节点的路径。

解决思路:
将给定的数据插入堆中,维护堆的有序性。查询时,逐层向上追溯,从给定节点回到根节点,并记录路径。
堆的表示及其操作(堆是一种按一定顺序组织的完全二叉树)
#define MAXN 1001
#define MINH -10001
int H[MAXN],size;//由于堆在存储的时候是把根结点放在数组下标为1的地方,也就是说0是空缺的
//这样子按照一层层顺序逐个往数组后面存放,使得堆中的任何一个元素可以很容易的找到他的父节点在哪里,左右儿子在哪里
//整数size表示当前堆大小
void Create()//堆的初始化,就是建立一个空堆(size设置为0)
{
size = 0;
H[0] = MINH;//设置岗哨
}
//插入操作
void Insert(int X)
{
//将X插入H。这里省略检查堆是否已满的代码
int i;
for(i = ++size;H[i/2]>X;i/=2)
H[i] = H[i/2];//i挪到父节点(i/2)的位置
H[i] = X;
}
主程序
int main()
{
1.读入n和m
2.根据输入序列建堆
3.对m个要求:打印到根的路径
return 0;
}
//具体实现程序
int main()
{
int n,m,x,i,j;
scanf("%d%d",&n,&m);
Create();//堆初始化
for(i = 0;i < n; i++ ) {//以逐个插入方式建堆
scanf("%d",&x);
Insert(x);//利用Insert函数插到堆中
}
//m个查询
for(i=0;i<m;i++){
scanf("%d",&j);
printf("d",H[j]);
while(j < 1){//沿根方向输出各结点(也就是说把他的祖先全部打印出来了)当j>1是代表还没有到根的时候,根的位置是1,这时候j/2就代表了他父节点的位置
j /= 2;
printf("%d",H[j]);
}
printf("\n");
}
return 0;
}