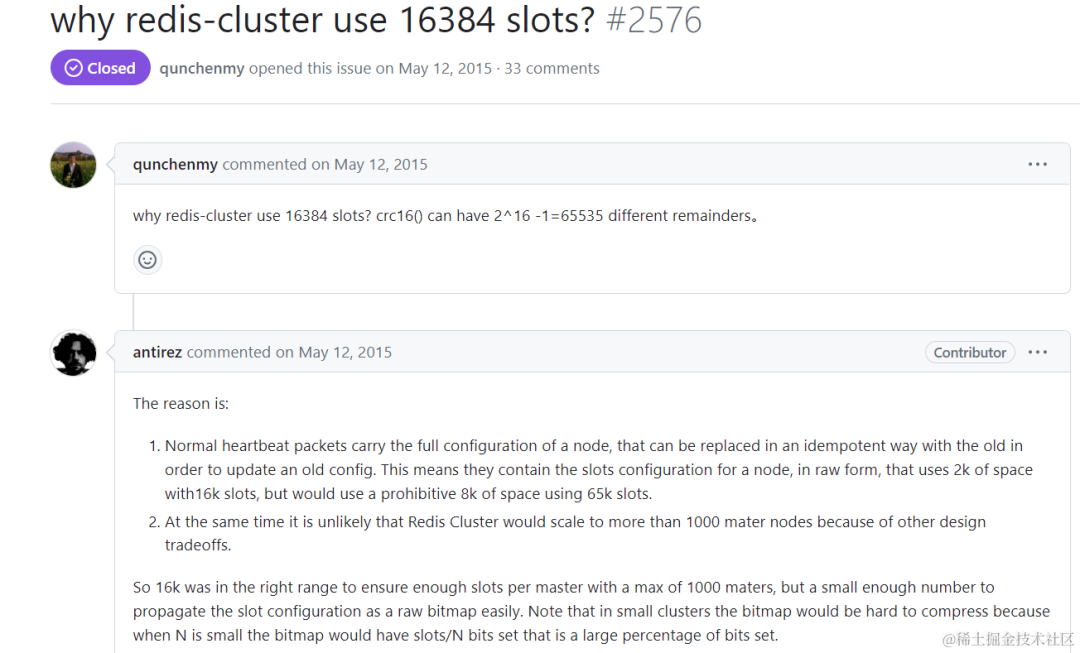
1、The Large Language Models (LLMs) Landscape
1.1、Introducing large language models
1.1.1、LLMs development lifecycle

1.1.2、Pre-training and fine-tuning

We can often use a pre-trained LLM as a foundation and fine-tune it with our specific data, saving plenty of time and training effort.
1.1.3、Using Hugging Face models
from transformers import pipeline
text_classifier = pipeline(task = "text-classification",
model = "nlptown/bert-base-multilingual-uncased-sentiment")
text = "xxx"
sentiment = text_classifier(text)
print(sentiment)1.2、Tasks LLMs can perform
1.2.1、Language tasks: overview

1.2.2、Text classification

1.2.3、Text generation

1.2.4、Text summarization

1.2.5、Question-answering

1.2.6、Language translation

1.3、The transformer architecture
1.3.1、What is a transformer?
Deep learning architecture for text processing, understanding, and generation.
Characteristics:
- No recurrent (RNN) architecture.
- Capture long-range dependencies in text.
- Tokens are handled simultaneously.
- Attention mechanisms + positionall encoding.
1.3.2、The original transformer architecture

- Two main stacks: encoder and decoder.
- Each layer: attention mechanisms and feed-forward computations.
- Capture complex semantic patterns and dependencies.
- No recurrence nor convolutions.
- Intended for various language tasks: Translation、Summarization、Question-answering.
1.3.3、Our first PyTorch transformer
import torch
import torch.nn as nn
# d_model: model embedding dimension(模型维度),表示模型内的输入、输出和中间信息
d_model = 512
# n_heads: number of attention heads(头部),专门捕获不同类型的文本依赖关系;
# 头数量通常是模型维度的除数
n_heads = 8
# num_encoder_layers, num_decoder_layers: number of encoder and decoder layers
# 模型深度由编码器和解码器层的数量决定
num_encoder_layer = 6
num_decoder_layer = 6
# torch.nn.Transformer class,Transformer骨架,但尚未实现功能的结构
model = nn.Transformer(
d_model = d_model,
nhead = n_heads,
num_encoder_layer = num_encoder_layer,
num_decoder_layer = num_decoder_layer
)1.3.4、Types of transformer architectures

2、Building a Transformer Architecture
2.1、Attention mechanisms and positional encoding
2.1.1、Why attention mechanisms?

2.1.2、Positional encoding
- Attention mechanisms require positional information for each token in the sequence.

2.1.3、Positional encoder class
class PositionalEncoder(nn.Module):
def __init__(self, d_model, max_seq_length=512):
super(PositionalEncoder, self).__init__()
# 设置最大序列长度 和 embedding维度
self.d_model = d_model
self.max_seq_length = max_seq_length
# pe,用于对序列进行位置编码,直至达到我们指定的最大长度
# pe 是一个形状为 (max_seq_length, d_model) 的全零张量,用于存储位置编码。
# position 是一个形状为 (max_seq_length, 1) 的张量,存储了从 0 到 max_seq_length - 1 的位置索引。
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
# 位置索引使用存储在 div_term 变量中的因子进行缩放,并与正余弦函数结合
# 这一行计算了一个形状为 (d_model // 2,) 的张量 div_term。它将被用于对位置索引进行缩放,以便将位置编码嵌入到不同的频率中。
div_term = torch.exp(torch.arange(0, d_model, 2, dtype=torch.float) * -(math.log(10000.0) / d_model))
# 这两行计算了位置编码,将正弦函数应用于偶数索引,将余弦函数应用于奇数索引。
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 在位置编码张量的开头添加一个维度,使其形状变为 (1, max_seq_length, d_model)。
pe = pe.unsqueeze(0)
# 将矩阵设置成不可训练的模型参数
self.register_buffer('pe', pe)
# 前向函数将位置编码添加到张量x中
def forward(self, x):
x = x + self.pe[:, :x.size(1)]
return x
2.2、Multi-headed self attention
2.2.1、Self-attention mechanism anatomy
- Self-attention helps transformers understand the interrelationship between words in a squence, allowing them to focus on the most important words for the given language task.

2.2.2、Multi-headed self-attention

2.2.3、Multi-headed attention class
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
# num_heads表示多头注意力机制中头部的数量。
# d_model表示模型的输入和输出维度。
# head_dim表示每个头部的维度,等于d_model除以num_heads。
self.num_heads = num_heads
self.d_model = d_model
self.head_dim = d_model // num_heads
# 定义了四个线性层,用于将输入分别映射到查询(query)、键(key)、值(value)和输出。每个线性层的输入维度和输出维度都是d_model。
self.query_linear = nn.Linear(d_model, d_model)
self.key_linear = nn.Linear(d_model, d_model)
self.value_linear = nn.Linear(d_model, d_model)
self.output_linear = nn.Linear(d_model, d_model)
# split_heads() 使用张量操作将输入拆分到各个head中
# 这个方法用于将输入张量x分割成多个头部。首先,它将x重新调整形状为(batch_size, sequence_length, num_heads, head_dim)。然后,它使用permute函数交换第二和第三个维度,使头部维度位于第二个位置。最后,它使用view函数将张量展平成(batch_size * num_heads, sequence_length, head_dim)的形状。
def split_heads(self, x, batch_size):
x = x.view(batch_size, -1, self.num_heads, self.head_dim)
return x.permute(0, 2, 1, 3).contiguous().view(batch_size * self.num_heads, -1, self.head_dim)
# compute_attention() 计算每个头部内部的注意力权重
# 这个方法计算注意力权重。它首先计算查询和键的点积,得到一个scores张量。如果提供了掩码mask,则将掩码为0的位置的分数设置为一个非常小的值(-1e9),以确保这些位置在softmax后的注意力权重接近于0。然后,它对scores的最后一个维度应用softmax函数,得到注意力权重张量。
def compute_attention(self, query, key, mask=None):
# torch.matmul()计算查询和键矩阵之间的点积
scores = torch.matmul(query, key.permute(1, 2, 0))
if mask is not None:
scores = scores.masked_fill(mask == 0, float("-1e9"))
attention_weights = F.softmax(scores, dim=-1)
return attention_weights
# 前向传播函数协调机制工作流程,计算注意力权重 qkv 然后将输出连接并投影到原始模型维度
# 1、获取输入张量的批次大小。
# 2、将输入查询、键和值分别通过线性层,并使用split_heads方法将它们分割成多个头部。
# 3、使用compute_attention方法计算注意力权重。
# 4、将注意力权重与值张量相乘,得到注意力输出。
# 5、将注意力输出重新调整形状为(batch_size, sequence_length, d_model)。
# 6、通过输出线性层,将注意力输出映射回原始的模型维度d_model。
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
query = self.split_heads(self.query_linear(query), batch_size)
key = self.split_heads(self.key_linear(key), batch_size)
value = self.split_heads(self.value_linear(value), batch_size)
attention_weights = self.compute_attention(query, key, mask)
output = torch.matmul(attention_weights, value)
output = output.view(batch_size, self.num_heads, -1, self.head_dim).
permute(0, 2, 1, 3).contiguous().view(batch_size, -1, self.d_model)
return self.output_linear(output)2.3、Building an encoder transformer
2.3.1、From original to encoder-only transformer
Original:

Encoder-only:

2.3.2、Feed-forward sublayer in encoder layer

2.3.3、Encoder layer


2.3.4、Masking the attention process

2.3.5、Transformer body: encoder

2.3.6、Transformer head

2.3.7、Testing the encoder transformer

2.4、Building a decoder transformer
2.4.1、From original to decoder-only transformer


The architecture is similar to an encoder-only approach, with two differences.
- One is the use of masked multi-head self-attention, which helps the model specialize in predicting the next word in a sequence one step at a time.
- The other difference lies in the model head, which generally consists of a linear layer with softmax activation over the entire vocabulary to estimate the likelihood of each word or token being the next one to generate, and returning the most likely one.
2.4.2、Masked self-attention

2.4.3、Transformer body (decoder) and head


class TransformerDecoder(nn.Module):
def __init__(self, vocab_size, d_model, num_layers, num_heads, d_ff, dropout, max_sequence_length):
super(TransformerDecoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_sequence_length)
self.layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
# Add a linear layer (head) for next-word prediction
# 用于将解码器的输出映射回词汇表的大小,以进行下一个单词的预测。
self.fc = nn.Linear(d_model, vocab_size)
def forward(self, x, self_mask):
# 首先将输入序列通过嵌入层 self.embedding 映射到向量空间
# 然后将位置编码应用到嵌入向量 x
# 接下来,将编码后的向量 x 依次传递给每一个解码器层 layer,同时传递注意力掩码 self_mask
# 将解码器层的输出 x 传递给全连接层 self.fc,得到词汇表大小的输出
# 对输出应用 log_softmax 函数,得到每个单词的对数概率分布
x = self.embedding(x)
x = self.positional_encoding(x)
for layer in self.layers:
x = layer(x, self_mask)
# Apply the forward pass through the model head
x = self.fc(x)
return F.log_softmax(x, dim=-1)2.4.4、Testing the decoder transformer

input_sequence = torch.randint(0, vocab_size, (batch_size, sequence_length))
# Create a triangular attention mask for causal attention
self_attention_mask = (1 - torch.triu(torch.ones(1, sequence_length, sequence_length), diagonal=1)).bool() # Upper triangular mask
# Instantiate the decoder transformer
decoder = TransformerDecoder(vocab_size, d_model, num_layers, num_heads, d_ff, dropout, max_sequence_length=sequence_length)
output = decoder(input_sequence, self_attention_mask)
print(output.shape)
print(output)2.5、Building an encoder-decoder transformer
2.5.1、Transformer architecture: encoder recap

2.5.2、Cross-attention mechanism
Cross-attention (link the transformer's two main building blocks): double inputs
- Information processed throughout decoder.
- Final hiden states from encoder block.
It is crucial for the decoder to "look back" at the input sequence to figure out what to generate next in the target sequence.


class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
# Initialize the causal (masked) self-attention and cross-attention
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = FeedForwardSubLayer(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, causal_mask, encoder_output, cross_mask):
# Pass the necessary arguments to the causal self-attention and cross-attention
self_attn_output = self.self_attn(x, x, x, causal_mask)
x = self.norm1(x + self.dropout(self_attn_output))
cross_attn_output = self.cross_attn(x, encoder_output, encoder_output, cross_mask)
x = self.norm2(x + self.dropout(cross_attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return xThe forward() method now requires two masks:
- The causal mask for the first attention stage.
- The cross-attention mask, which can be the usual padding mask like the one used in the encoder.
Importantly, the variable y in this method contains the encoder outputs, passed as key and value arguments to the cross-attention mechanism.
Meanwhile, the decoder flow, associated with generating the target sequence, only adopts the role of the attention query in this case.
2.5.3、Encoder meets decoder


Notice that only the final encoder outputs are fed to every layer in the decoder for cross-attention.
2.5.4、Transformer head
Similar to decoder-only transformers, the model's output head consists of a linear layer followed by softmax activation, converting decoder outputs into next-word probabilities.

2.5.5、Everything brought together!

One last important aspect to understand is the role of the decoder inputs, called "output embedding" in our diagram: the decoder only needs to take actual target sequences during training time.
- In translation, these would be examples of translations associated with the source-language sequences fed to the encoder.
- In text summarization, the output embeddings for the decoder are summarized versions of the input embeddings for the encoder, and so on.
Words in the target sequence act as our training labels during the next-word generation process.
At inference time, the decoder assumes the role of generating a target sequence, starting with an empty output embedding and gradually taking as its inputs the target words it is generating.

2.5.6、Trying out an encoder-decoder transformer

# Create a batch of random input sequences
# 1、生成了一个形状为 (batch_size, sequence_length) 的随机输入序列,每个元素的值在 0 到 vocab_size-1 之间。vocab_size 表示词汇表的大小。
# 2、padding_mask 是一个二值掩码,用于标记输入序列中的填充元素。
# 3、causal_mask 是一个三角形掩码,用于在解码器的自注意力机制中,防止当前位置的输出依赖于未来位置的输入。
input_sequence = torch.randint(0, vocab_size, (batch_size , sequence_length ))
padding_mask = torch.randint(0, 2, (sequence_length, sequence_length))
causal_mask = torch.triu(torch.ones(sequence_length, sequence_length), diagonal=1)
# Instantiate the two transformer bodies
encoder = TransformerEncoder(vocab_size, d_model, num_layers, num_heads, d_ff, dropout, max_sequence_length=sequence_length)
decoder = TransformerDecoder(vocab_size, d_model, num_layers, num_heads, d_ff, dropout, max_sequence_length=sequence_length)
# Pass the necessary masks as arguments to the encoder and the decoder
encoder_output = encoder(input_sequence, padding_mask)
decoder_output = decoder(input_sequence, causal_mask, encoder_output, padding_mask)
print("Batch's output shape: ", decoder_output.shape)2.5.7、Transformer assembly bottom-up

# Initialize positional encoding layer and stack of EncoderLayer modules
class TransformerEncoder(nn.Module):
def __init__(self, vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_len, dropout):
super(TransformerEncoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_seq_len)
self.layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
x = self.embedding(x)
x = self.positional_encoding(x)
x = self.dropout(x)
# Pass the sequence through each layer in the encoder
for layer in self.layers:
x = layer(x, mask)
return x
class Transformer(nn.Module):
def __init__(self, vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_len, dropout):
super(Transformer, self).__init__()
# Initialize the encoder stack of the Transformer
self.encoder = TransformerEncoder(vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_len, dropout)
def forward(self, src, src_mask):
encoder_output = self.encoder(src, src_mask)
return encoder_output3、Harnessing Pre-trained LLMs
3.1、LLMs for text classification and generation
3.1.1、Loading a pre-trained LLM

3.1.2、The AutoModel and AutoTokenizer classes


3.1.3、Auto class for text classification

3.1.4、Auto class for text generation

3.1.5、Exploring a dataset for text classification


3.1.6、How text generation LLM training works

3.1.7、Classifying two movie opinions

# Load the tokenizer and pre-trained model
# 加载了指定模型的tokenizer
# Tokenizer用于将原始文本转换为模型可以理解的数字序列。AutoTokenizer会自动选择合适的tokenizer类。
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 加载了指定的预训练序列分类模型。
# AutoModelForSequenceClassification会自动选择合适的模型架构。num_labels=2指定了这是一个二分类问题(正面或负面)。
model = AutoModelForSequenceClassification.from_pretrained(
model_name, num_labels=2)
text = ["The best movie I've ever watched!", "What an awful movie. I regret watching it."]
# Tokenize inputs and pass them to the model for inference
# 使用tokenizer将原始文本转换为模型可以理解的数字序列。return_tensors="pt"指定返回PyTorch张量格式。padding=True表示对较短的序列进行填充,使所有序列长度一致(这是模型的要求)。
inputs = tokenizer(text, return_tensors="pt", padding=True)
# 将输入传递给模型进行推理,并获取模型输出的logits(原始的未经过归一化的分数)。
outputs = model(**inputs)
logits = outputs.logits
# 计算出每个样本的预测类别。torch.argmax(logits, dim=1)返回每个样本在logits中最大值的索引,也就是模型预测的类别。.tolist()将张量转换为Python列表。
predicted_classes = torch.argmax(logits, dim=1).tolist()
# 循环打印出每个文本示例的预测类别(0或1)。
for idx, predicted_class in enumerate(predicted_classes):
print(f"Predicted class for \"{text[idx]}\": {predicted_class}")3.2、LLMs for text summarization and translation
3.2.1、Inside text summarization
- Goal: create a summarized version of a text, preserving important information.
- Inputs: Original text.
- Target (labels): summarized text.
There are two types of summarization processes:
- Extractive summarization: select, extract, and combine parts of the original text.

- Abstractive summarization: generate a summary word by word.

3.2.2、Exploring a text summarization dataset

3.2.3、Loading a pre-trained LLM for summarization

3.2.4、Inside language translation
- Goal: produce translated version of a text, conveying same meaning and context.
- Inputs: text in source language.
- Target (labels): target language translation.
Encoder source language sequence.
Decode into target language sequence, using learned language patterns and associations.

3.4.5、Exploring a language translation dataset

3.4.6、Loading a pre-trained LLM for translation

3.4.7、Summarizing a product opinion

# 打印出训练数据集中的实例数量。dataset['train']是训练数据集的一部分,len()函数用于获取其长度。
print(f"Number of instances: {len(dataset['train'])}")
# Show the names of features in the training fold of the dataset
# 打印出训练数据集中的特征名称。column_names是一个属性,它包含了数据集中每个特征的名称。
print(f"Feature names: {dataset['train'].column_names}")
# Encode the input example, obtain the summary, and decode it
# 从训练数据集中选取倒数第二个实例的第一条评论文本作为示例输入。dataset['train'][-2]选择倒数第二个实例,['reviews'][0]['review_text']则选取该实例中第一条评论的文本。
example = dataset['train'][-2]['reviews'][0]['review_text']
# 使用tokenizer将输入文本("summarize: " + example)编码为token ID序列。return_tensors="pt"表示返回PyTorch张量格式的输出。max_length=512限制了输入序列的最大长度为512个token,truncation=True表示如果超过最大长度则进行截断。
input_ids = tokenizer.encode("summarize: " + example, return_tensors="pt", max_length=512, truncation=True)
# 使用预训练的语言模型model基于输入token ID序列input_ids生成摘要的token ID序列。max_length=150限制了生成摘要的最大长度为150个token。
summary_ids = model.generate(input_ids, max_length=150)
# 使用tokenizer将生成的token ID序列summary_ids[0]解码为文本形式的摘要。skip_special_tokens=True表示在解码时跳过特殊token(如开始和结束token)。
summary = tokenizer.decode(
summary_ids[0], skip_special_tokens=True)
print("\nOriginal Text (first 400 characters): \n", example[:400])
print("\nGenerated Summary: \n", summary)3.4.8、The Spanish phrasebook mission

model_name = "Helsinki-NLP/opus-mt-en-es"
# Load the tokenizer and the model checkpoint
# 使用 from_pretrained 方法从 Hugging Face 模型中心加载预训练的 tokenizer 和模型。tokenizer 用于将文本转换为模型可以理解的数字序列,而 AutoModelForSeq2SeqLM 是一个用于序列到序列的语言模型,适合于机器翻译任务。
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
english_inputs = ["Hello", "Thank you", "How are you?", "Sorry", "Goodbye"]
# Encode the inputs, generate translations, decode, and print them
# 这个循环遍历了 english_inputs 列表中的每个英语句子。对于每个句子:
# 1、tokenizer.encode 将英语句子转换为一个数字序列 input_ids,并将其转换为 PyTorch 张量。
# 2、model.generate 使用该数字序列作为输入,并生成翻译后的数字序列 translated_ids。
# 3、tokenizer.decode 将翻译后的数字序列解码为文本 translated_text,并跳过任何特殊标记。
# 4、最后,打印原始的英语句子和翻译后的西班牙语句子。
for english_input in english_inputs:
input_ids = tokenizer.encode(english_input, return_tensors='pt')
translated_ids = model.generate(input_ids)
translated_text = tokenizer.decode(translated_ids[0], skip_special_tokens=True)
print(f"English: {english_input} | Spanish: {translated_text}")3.3、LLMs for question answering
3.3.1、Types of question answering (QA) tasks

3.3.2、Exploring a QA dataset


3.3.3、Extractive QA: framing the problem

3.3.4、Extractive QA: tokenizing inputs

3.3.5、Extractive QA: loading and using model

3.3.6、Managing long context sequences

3.3.7、Load and inspect a QA dataset

# Load a specific subset of the dataset
mlqa = load_dataset("xtreme", name="MLQA.en.en")
question = mlqa["test"]["question"][0]
context = mlqa["test"]["context"][0]
print("Question: ", question)
print("Context: ", context)
# Initialize the tokenizer using the model checkpoint
tokenizer = AutoTokenizer.from_pretrained("deepset/minilm-uncased-squad2")
# Tokenize the inputs returning the result as tensors
inputs = tokenizer(question, context, return_tensors='pt')
print("First five encoded tokens: ", inputs["input_ids"][0][:5])3.3.8、Extract and decode the answer

# Initialize the LLM upon the model checkpoint
model = AutoModelForQuestionAnswering.from_pretrained(model_ckp)
# 创建了一个上下文管理器,在这个上下文中,PyTorch张量的计算将不会跟踪梯度。这是因为在推理阶段不需要计算梯度。
with torch.no_grad():
# Forward-pass the input through the model
# 将输入数据(inputs)传递给预训练的问答模型,并获取模型的输出。**inputs是Python中的解包操作符,它将字典inputs解包为关键字参数。
outputs = model(**inputs)
# Get the most likely start and end answer position from the raw LLM outputs
# 从模型的输出中获取最可能的答案起始位置和结束位置的索引。outputs.start_logits和outputs.end_logits分别表示答案起始位置和结束位置的概率分布。torch.argmax函数返回具有最大值的索引。
start_idx = torch.argmax(outputs.start_logits)
end_idx = torch.argmax(outputs.end_logits) + 1
# Access the tokenized inputs tensor to get the answer span
answer_span = inputs["input_ids"][0][start_idx:end_idx]
# Decode the answer span to get the extracted answer text
answer = tokenizer.decode(answer_span)
print("Answer: ", answer)3.4、LLM fine-tuning and transfer learning
3.4.1、Revisiting the LLM lifecycle

There are two different fine-tuning approaches depending on how the model weights are updated.
- One is full-fine tuning, which entails updating weights across the entire model and being more computationally expensive.

- The other is partial fine-tuning, where weights in lower layers of the model body responsible for capturing general language understanding remain fixed, updating task-specific layers in the model head only.

3.4.2、Demystifying transfer learning
Transfer learning: a model trained on one task is adapted for a different but related task.
- In pre-trained LLMs, fine-tune on a smaller dataset for a specific task.

- Zero-shot learning: perform tasks never "seen" during training.
- One-shot, few-shot learning: adapt a model to a new task with one or a few examples only.
3.4.3、Fine-tuning a pre-trained Hugging Face LLM


3.4.4、Inference and saving a fine-tuned LLM

3.4.5、Matching LLM use cases and architectures

4、Evaluating and Leveraging LLMs in the Real World
4.1、Guidelines and standard metrics for evaluating LLMs
4.1.1、Evaluation metrics: classification accuracy


4.1.2、The evaluate library



4.1.3、LLM task and metrics

4.2、Specialized metrics for language tasks
4.2.1、Perplexity in text generation

4.2.2、ROUGE score in text summarization

4.2.3、BLEU score in translation

4.2.4、METEOR score in translation

4.2.5、Exact Match (EM) in question answering

4.3、Model fine-tuning using human feedback
4.3.1、Why human feedback in LLMs

4.3.2、Reinforcement Learning from Human Feedback (RLHF)

4.3.3、Building a reward model

4.3.4、TRL: Transformer Reinforcement Learning

4.4、Challenges and ethical considerations
4.4.1、LLM challenges in the real world

4.4.2、Truthfulness and hallucinations

4.4.3、Metrics for analyzing LLM bias: toxicity

4.4.4、Metrics for analyzing LLM bias: regard

4.5、The finish line
4.5.1、Chapter 1: The LLMs landscape

4.5.2、Building a transformer architecture

4.5.3、Chapter 3: Harnessing pre-trained LLMs

4.5.4、Evaluating and leveraging LLMs in the real world

4.5.5、What to learn next?