关联比赛: “新内容 新交互”全球视频云创新挑战赛--算法挑战赛道
赛题回顾
本次赛题核心为高清视频人像分割,属于无监督视频物体分割任务,要求在未提供任何额外输入的情况下,识别并定位视频中的主要人物,并精确到图像的每个像素。
赛题数据多来自于影视剧、运动、舞蹈、街拍等视频片段,这些多样的场景会带来以下技术难点:
- 高精度:要求关注人物边缘细节及附属物的分割,包括背包、手持物、复杂的发饰服饰等;
- 多目标:实例级分割,存在目标间相互遮挡、相似目标及背景人物的干扰;
- 多尺度:目标尺寸跨度较大,人物形变,小目标识别等。
其中,镜头切换,人物遮挡,人物快速运动及目标人物的中途出现或消失等问题都可能成为算法的瓶颈,部分难例如下图所示:

初赛方案设计
无监督VOS可被拆解成人物分割和人物追踪两部分。在初赛方案中我们使用了用于显著人物分割的SOLOv2算法,用于时序人物分割的STM算法,并创新性地提出了将两者结合的动态融合推理算法。
SOLOv2具有较好的速度和精度的trade-off,能够高效地生成显著人物的初始mask。有了初始mask后,可以将无监督VOS问题转化为半监督VOS,因此可以使用STM算法进行时序上人物的追踪分割。原生的STM算法对于本次比赛的数据存在以下不足:
- 随着帧数的增加,可能出现误差累积现象,容易造成目标混淆、跟错等情况;
- 当目标在视频中途消失或被遮挡时容易跟丢目标;
- 对于小目标跟踪效果较差,或分割精度不够高。
为此,我们引入Motion Guided Attention和ASPP模块,进一步提高STM的运动捕捉能力以及对小目标的分割能力。其中motion-guided模块使用了前一帧的分割mask,旨在使模型更好地学习到目标运动的连续性,减少同帧内相似目标的混淆。使用ASPP模块,提高对小目标的分割效果。
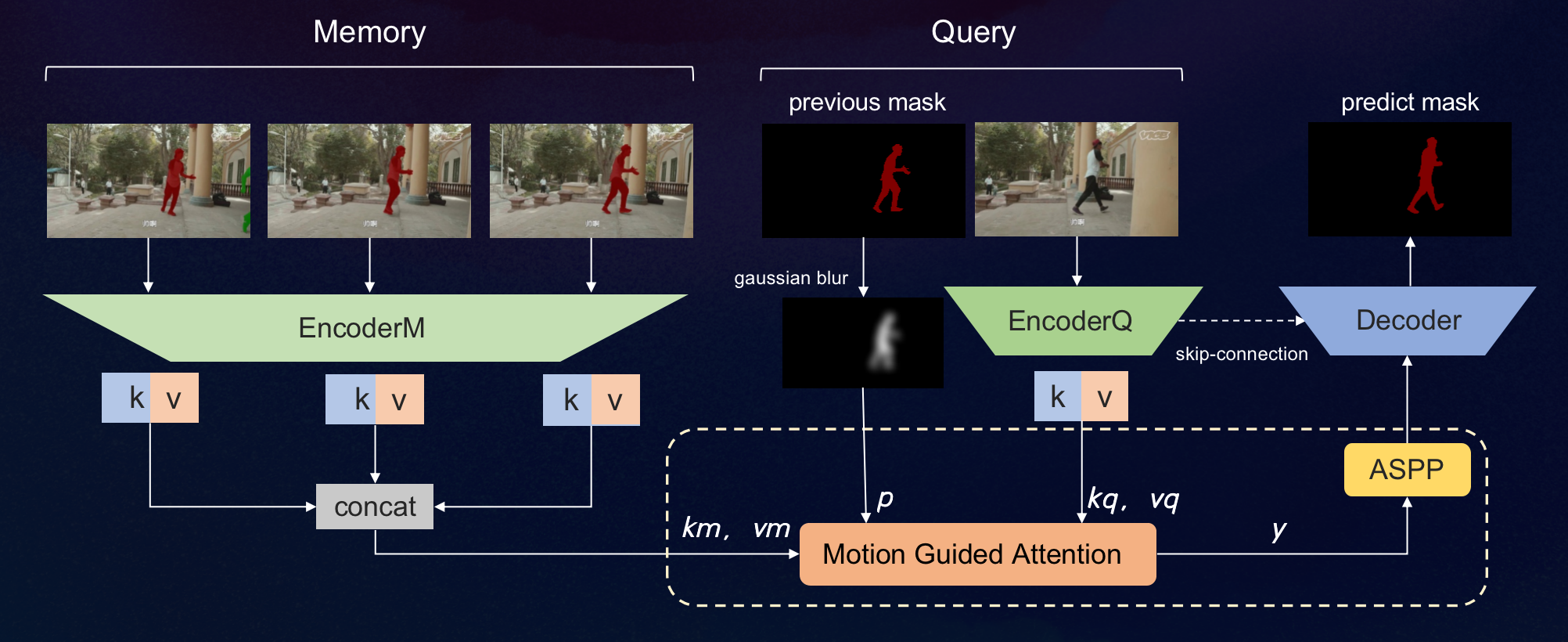
使用Motion-Guided STM能够在一定程度缓解以上问题,但如果只用某一帧的solo mask作为起始mask进行半监督VOS,仍然存在严重的误差累积。为了进一步解决该问题,并尽可能多地捕捉视频中的主要人物,以及更充分地利用SOLOv2和STM的分割结果,我们提出了一种动态融合的无监督推理算法。
动态融合(Dynamic Fusion)模块不涉及参数训练,是基于规则的推理算法,可以简单高效地结合实例分割算法和半监督VOS算法的分割结果,其主要流程如下图所示:
我们发现,使用Dynamic Fusion模块,不但可以在一定程度上解决STM的误差累积现象,还可以对视频中途出现或消失的人物进行持续分割,因此可以应用于较长的视频片段。
复赛方案设计
本次复赛不同于以往的赛题,需要在CPU上进行推理,且200段视频测试时间不得超过10小时,对网络性能提出了很高的要求。这就要求参赛者在保证模型高精度的同时,更多地考虑模型推理加速的优化工作。
为此,我们在初赛方案上进行了以下几点改进:
1、为了进一步提高人物分割精度,且不增加太多额外计算,我们在SOLOv2后面增加了一个轻量的RefineNet模块,优化人物边缘细节及分割mask的完整性。
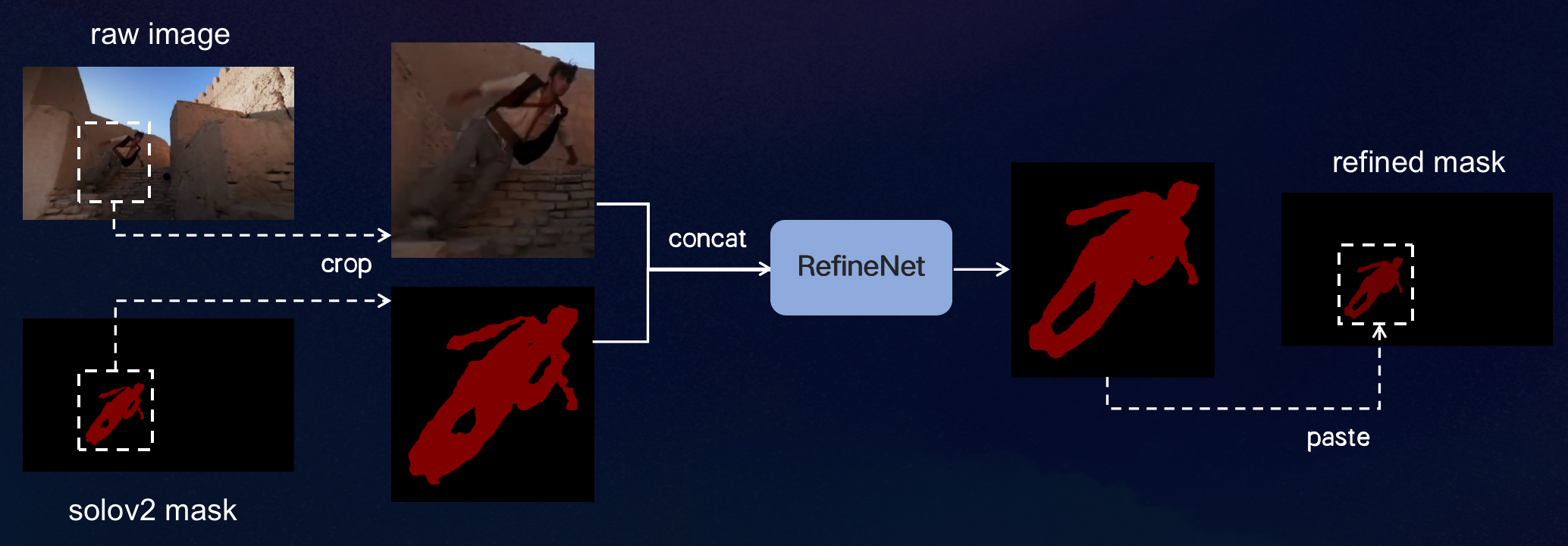
2、为了提高STM推理效率,先使用SORT(Simple Online and Real-time Tracking)算法提供人物初始跟踪序列,再用STM对初始跟踪序列进行关联和补全。
SORT算法是一种快速多目标跟踪算法,基于卡尔曼滤波与匈牙利算法来进行目标跟踪。对镜头固定,人物位移小的视频能够有较好的跟踪效果。但对于目标遮挡、快速运动、镜头切换等场景,其跟踪效果不佳,主要表现为目标ID的频繁切换。
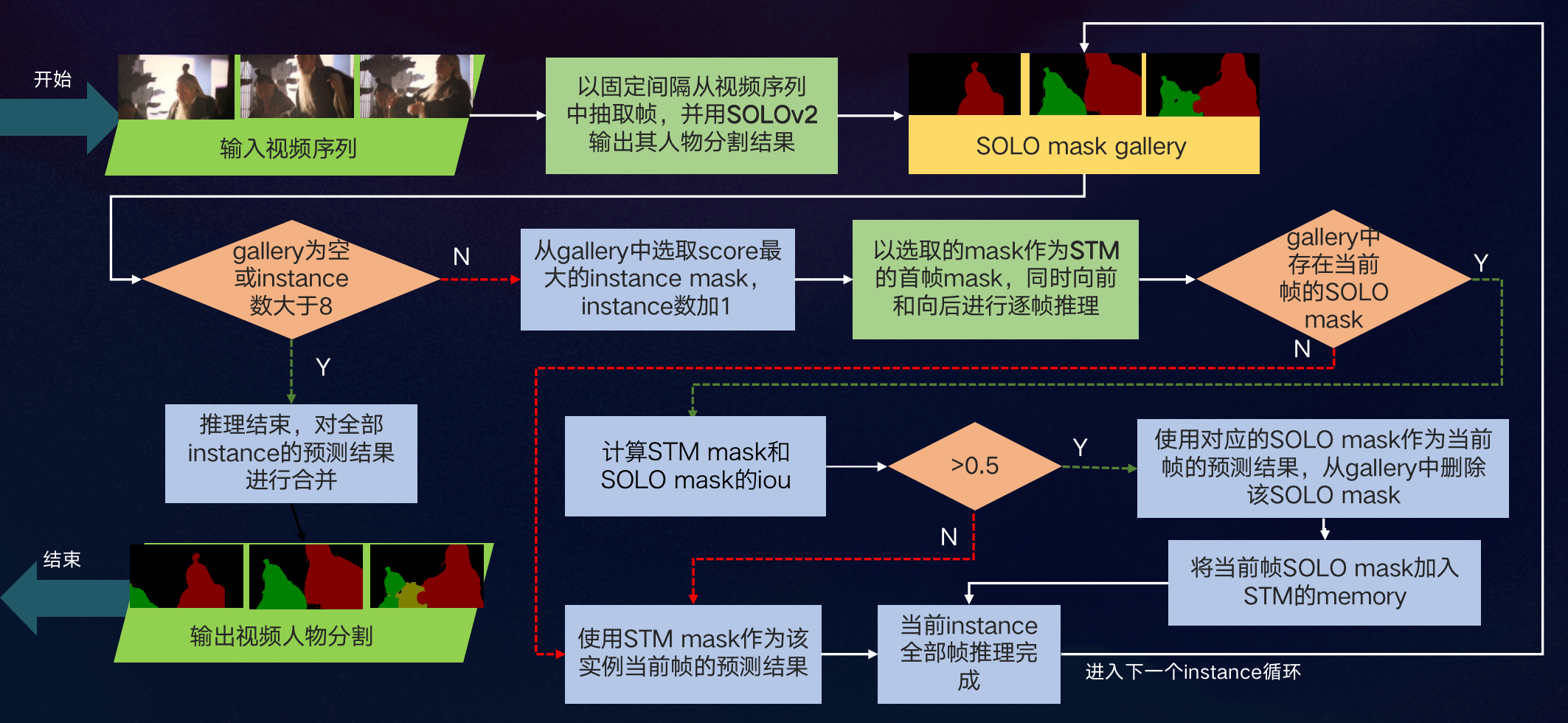
为此,我们优化了初赛的Dynamic Fusion模块,提出了新的SORT+STM两阶段推理流程,如下图所示:
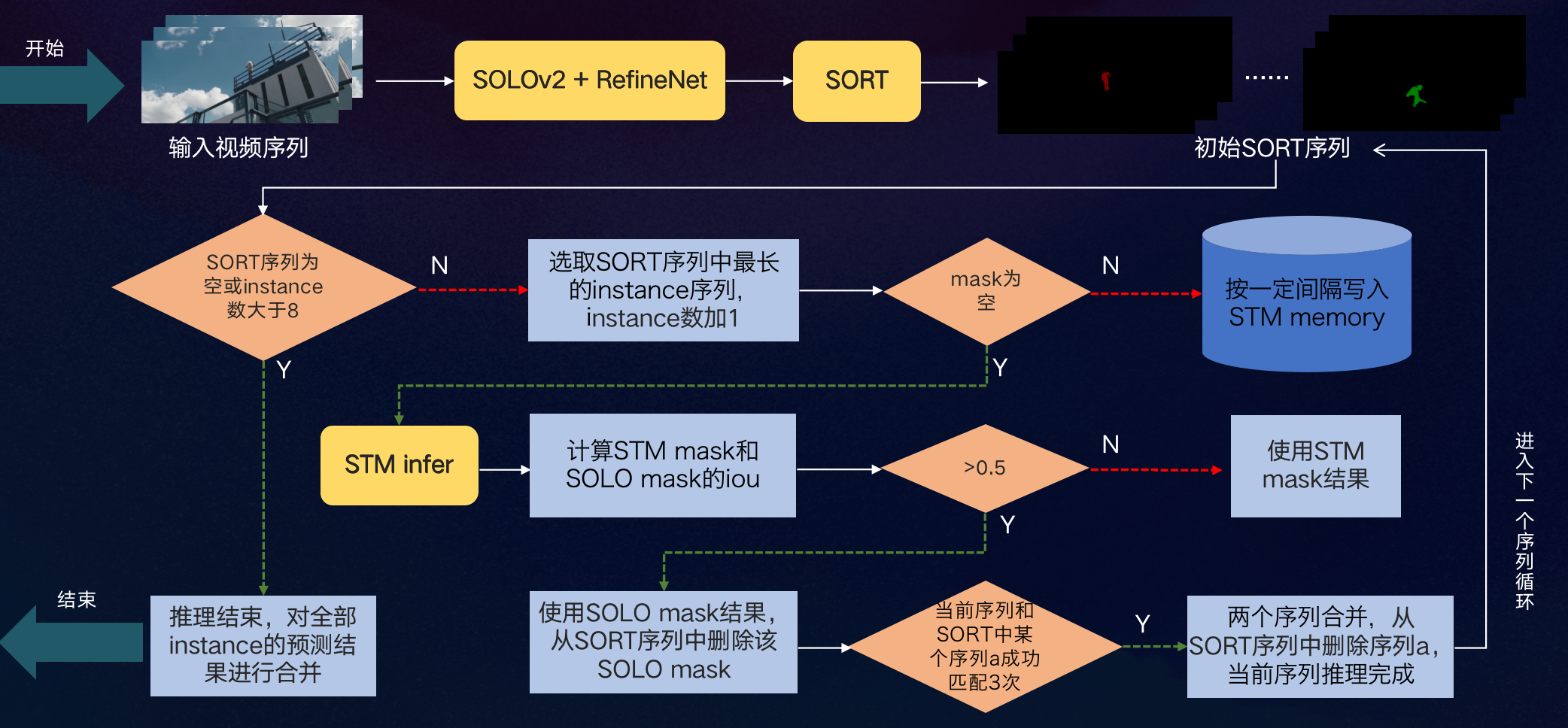
通过STM mask和SOLOv2 mask的融合,进行SORT序列之间的关联匹配,能够纠正同一个instance序列被SORT算法分成多段及检测丢帧等情况,同时极大地缩短了STM的运行时间。复赛200段测试视频在CPU上的全流程推理时间只需2小时!
比赛总结
算法优点
- 使用single-shot的实例分割算法SOLOv2,推理速度快、精度高;
- Motion-Guided STM算法学习了运动的连续性,提高了小目标的分割效果;
- 初赛提出的Dynamic Fusion模块缓解了时序分割的误差累积现象,可应用于较长视频片段,并可以模块化地替换实例分割和半监督VOS使用的模型;
- 复赛提出的SORT + STM两阶段跟踪算法,在保证模型效果的同时,极大地减少STM的运行时间。
优化方向
- 引入光流、ReID等模块;
- 改进STM算法,设计更轻量的Memory机制;
- 尝试基于Transformer的视频实例分割算法,如VisTR等。
查看更多内容,欢迎访问天池技术圈官方地址:eggtart队比赛攻略_天池技术圈-阿里云天池