首发公众号:【赵侠客】
引言
在前面《释放你九成的带宽和内存:GZIP在解决Redis大Key方面的应用》一文中我使用GZIP算法可以将JSON格式数据的大小缩小88%从而节省了大量的存储和带宽资源,本文介绍另一种JAVA对象序列化神器——ProtoBuf(Protocol Buffers(),它是由 Google 开发的一种用于序列化结构化数据的高效、灵活且语言中立的协议。它被广泛用于数据通信、数据存储、RPC(远程过程调用)等场景,特别是在分布式系统和微服务架构中。Protobuf 序列化后的数据体积通常比 JSON、XML 小很多,而且占用更少的带宽和存储空间,且解析速度更快。但是相对于 JSON、XML 等文本格式可读性差,使用比较麻烦,最主要是增加了开发和编译的步骤(需要使用 protoc 编译 .proto 文件),本文介绍JProtoBuf神器,像使用JSON一样使用Protobuf。
二、Quick Start
JProtobuf 是一个基于Java的Protobuf序列化与反序列化工具,它由百度开发并开源的,旨在简化 Protobuf 在 Java 项目中的使用门槛。JProtobuf提供了一种更符合Java开发者习惯的方式来定义和操作Protobuf数据,无需使用.proto 文件和编译工具,项目GitHub地址:
JProtobuf:https://github.com/jhunters/jprotobuf
使用JProtobuf只需要三步就能完成JAVA对象和Protobuf数据之间的相互转换:
- 第一步,添加Maven依赖:
<dependency>
<groupId>com.baidu</groupId>
<artifactId>jprotobuf</artifactId>
<version>2.4.23</version>
</dependency>
- 第二步,对象添加@ProtobufClass注解
@Data
@ProtobufClass
public class User {
private Long id;
private String name;
private String trueName;
private Integer age;
private String sex;
private Date createTime;
}
- 第三步,创建ProtobufProxy创建代理并使用
User user = new User();
user.setId(1L);
user.setName("赵侠客");
user.setAge(29);
user.setSex("男");
user.setTrueName("公众号");
user.setCreateTime(new Date());
//创建JProtobuf代理
Codec<User> codec = ProtobufProxy.create(User.class);
//使用Protobuf序列化
byte[] bytes = codec.encode(user);
System.out.println(bytes.length); //38
//使用Protobuf反序列化
User user1 = codec.decode(bytes);
通过上面的代码可以看出使用JProtobuf来完成对象的序列化和使用JSON序列化对象是一样的简单,其中Protobuf序列化后的字节长度是38,JSON的字节长度为98,足足节省了61%。当然并不是所有对象使用Protobuf后大小和JSON都会有这么大的差距,接下来我们对比一下中JSON和大JSON序列化后大小差距。
三、大小对比
3.1 中JSON大小对比
这里我们参考前面一文《FastJson、Jackson、Gson、Hutool,JSON解析哪家强?JMH基准测试来排行》对 小JSON、中JSON、大JSON的定义。这里我定义中JSON为20个用户数组,由于JProtobuf不能直接支持List对象,所以要封装成一个Users对像:
@Data
@ProtobufClass
public class Users {
List<User> users;
private Long id;
}
使用上面的20个小JSON创建出一个中JSON:
//20个用户模拟中JSON
List<User> userList = new ArrayList<>();
IntStream.range(0, 20).forEach(i -> {
User user2=new User();
BeanUtil.copyProperties(user,user2);
userList.add(user2);
});
users.setUsers(userList);
使用JProtobuf序列化中JSON:
Codec<Users> userListCodec = ProtobufProxy.create(Users.class);
String mediumJson = JSON.toJSONString(users);
byte[] mediumProtobuf = userListCodec.encode(users);
mediumJson.getBytes().length+"\t"+mediumProtobuf.length;
//1991 800
在中JSON方面Protobuf序列化后的长度为800,JSON序列化后的长度为1991,Protobuf比JSON小了60%。
3.2 大JSON大小对比
大JSON我们定义为稿件正文富文本HTMl数据:
@Data
@ProtobufClass
public class Article {
private Long id;
private String author;
private Long tenantId;
private String title;
private String subTitle;
private String htmlContent;
private Date publishTime;
}
Mock大JSON数据:
//稿件正文模拟大JSON
article.setId(10000L);
article.setTenantId(10000L);
article.setAuthor("公众号:赵侠客");
article.setPublishTime(new Date());
article.setTitle(RandomUtil.randomString("主标题", 100));
article.setSubTitle(RandomUtil.randomString("副标题", 50));
//公众号文章字符串长度为89544
article.setHtmlContent(new String(Files.readAllBytes(Paths.get("article.html"))));
使用JProtobuf序列化大JSON:
Codec<Article> articleCodec = ProtobufProxy.create(Article.class);
String bigJson = JSON.toJSONString(article);
byte[] bigProtobuf= articleCodec.encode(article);
bigJson.getBytes().length+"\t"+bigProtobuf.length;
//94595 92826
对于大JSON使用Protobuf只比JSON小了2%,可能是大数据量JSON格式中的冗余信息占总信息大小非常小了,所以大数据量转成JSON和Protobuf差距也就不大了。
四、性能对比
性能对比我们参考前面一文《FastJson、Jackson、Gson、Hutool,JSON解析哪家强?JMH基准测试来排行》,为了准确我们使用JMH基准测试,还是从小JSON、中JSON、大JSON的序列化和反序列化6项指标做基准测试,我们就拿性能最炸裂了FastJson2和Protobuf对比。
百分制:我们以FastJson2跑分为100分做参考,比FastJson2快就大于100分
其中缩写定义:
- SS,小JSON序列化得分
- MS,中JSON序列化得分
- BS,大JSON序列化得分
- SDS,小JSON反序列化得分
- MDS,中JSON反序列化得分
- BDS,大JSON反序列化得分
- 变化,相对序列化得分变化
4.1 小JSON序列化
| Tool | Score | 百分制 |
|---|---|---|
| FastJson2 | 13561505 | 100 |
| Protobuf | 12858532 | 94.8 |
可以看出Protobuf小对象序列化性能可以媲美FastJson2,是非常快的。
4.12 中JSON序列化
| Tool | Score | 百分制 |
|---|---|---|
| FastJson2 | 825644 | 100 |
| Protobuf | 436635 | 52.9 |
可以看出Protobuf数组对象序列化性能是FastJson2的一半,可能和JProtobuf不直接支持List对象有点关系,所以性能并没有那么的出众。
4.3 大JSON序列化
| Tool | Score | 百分制 |
|---|---|---|
| FastJson2 | 10086 | 100 |
| Protobuf | 21764 | 215.8 |
可以看出Protobuf大对象序列化性能比FastJson2快了一倍多,这性能是JSON工具望成莫及的。
4.4 小JSON反序列化
| Tool | 百分制 | 变化 | SDS | SS |
|---|---|---|---|---|
| FastJson2 | 100 | -41.7% | 7921069 | 13561505 |
| Protobuf | 185.3 | +14.1% | 14676712 | 12858532 |
小对象的反序列化Protobuf比FastJson2快了近一倍达到185.3,而且性能比序列化还要好14.1%,不像FastJson2反序列化比序列化性能低了41.7%,这性能是非常炸裂的。
4.5 中JSON反序列化
| Tool | 百分制 | 变化 | MDS | MS |
|---|---|---|---|---|
| FastJson2 | 100 | -53.3% | 385392 | 825644 |
| Protobuf | 79.4 | -29.9% | 306087 | 436635 |
数组对象反序列化和序列化一样,性能没有那么的出众,感觉数组对象序列化和反序列化是Protobuf的弱点
4.6 大JSON反序列化
| Tool | 百分制 | 变化 | BDS | BS |
|---|---|---|---|---|
| FastJson2 | 100 | -35.7% | 6487 | 10086 |
| Protobuf | 480.4 | +43.2% | 31163 | 21764 |
大对象反序列化性能是FastJson2的近5倍达到惊人的480.4,可能不是Protobuf反序列化性能太强,而是JSON这种数据结构就不太适合大数据量的转换。
总结
空间
Protobuf空间比JSON变化:
| 对象 | 相比JSON |
|---|---|
| 小JSON | -61% |
| 中JSON | -60% |
| 大JSON | -2% |
时间
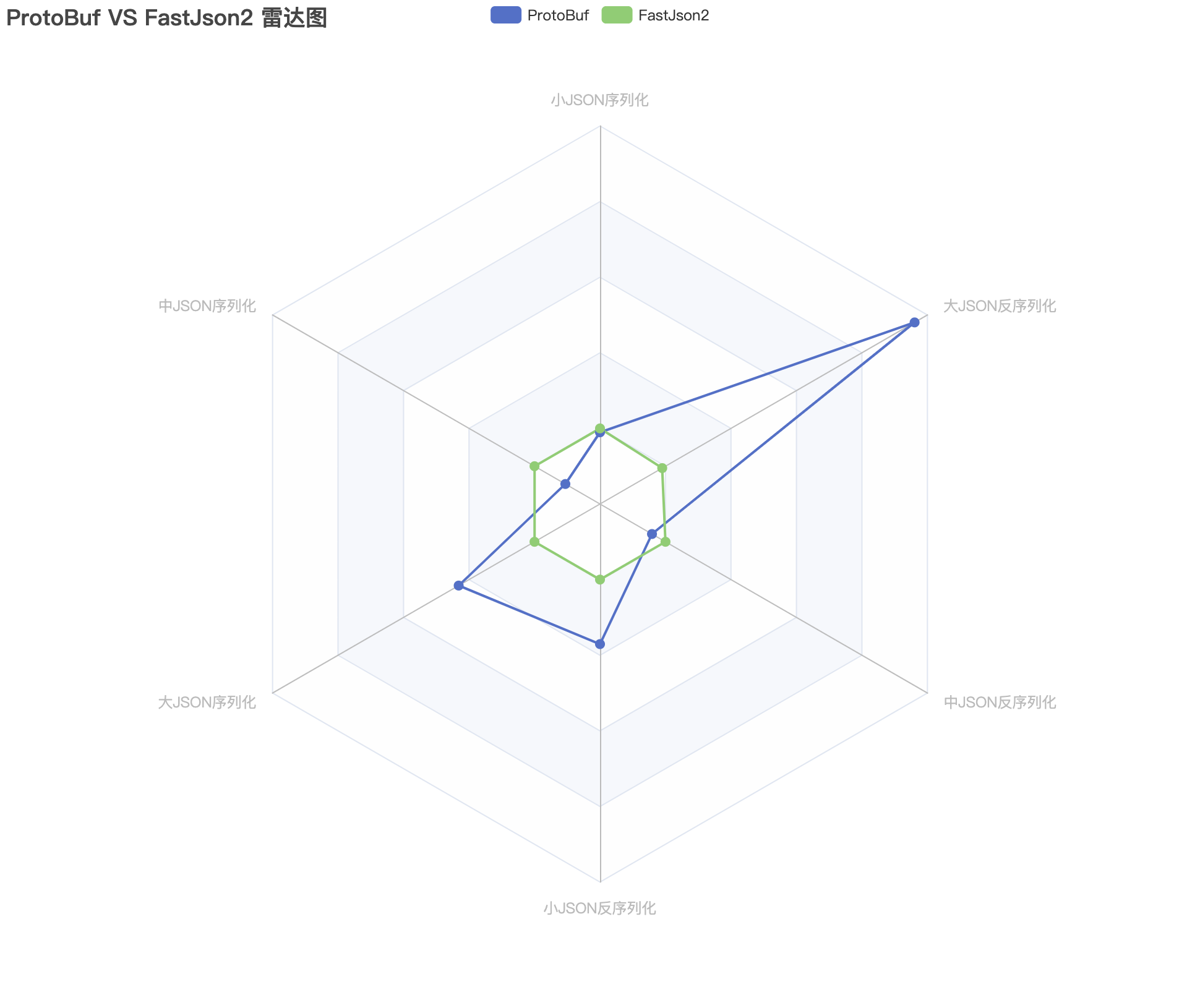
Protobuf对比JSON工具性能排行榜:
| Tool | 排名 | 总分 | 百分制 | SS | MS | BS | SDS | MDS | BDS |
|---|---|---|---|---|---|---|---|---|---|
| Protobuf | 王者 | 1108.6 | 195.5 | 94.8 | 52.9 | 215.8 | 185.3 | 79.4 | 480.4 |
| FastJson2 | 状元 | 567 | 100 | 100 | 100 | 72.0 | 100 | 100 | 95.0 |
| FastJson | 榜眼 | 394.2 | 69.5 | 62.3 | 73.2 | 35.8 | 51.3 | 71.6 | 100 |
| Jackson | 探花 | 342 | 60.3 | 42.3 | 89.7 | 100 | 27.4 | 31.3 | 51.3 |
| Gson | 进士 | 188.2 | 33.2 | 8.9 | 21.5 | 43.6 | 20.7 | 25.3 | 68.2 |
| Hutool | 孙山 | 42.2 | 7.4 | 3.2 | 4.6 | 7.7 | 7.3 | 5.5 | 13.9 |
结论
经过上面测试可以得出Protobuf以下结论:
- 在小数据情况下序列化空间比JSON大幅缩小,本文测试达到60%左右
- 在大数据情况下序列化空间和JSON相差无几
- 在小数据序列化性能媲美FastJson2
- 劣势是在数组序列化和反序列化性能都比FastJson2低很多
- 在大数据序列化和反序列化性能都秒杀所有JSON
综合在Protobuf序列化后的空间缩小和性能方面还是比JSON强的,所以如果在RPC中将序列化和反序列化从JSON改成Protobuf会给系统带来一定程度的性能提升。