【混淆矩阵】Confusion Matrix!定量评价的基础!
如何计算全面、准确的定量指标去衡量模型分类的好坏??
文章目录
- 【混淆矩阵】Confusion Matrix!定量评价的基础!
- 1. 混淆矩阵
- 2.评价指标
- 3.混淆矩阵及评价指标的实现(Python代码示例)
- 4.多分类问题中的评价指标
- 5.总结
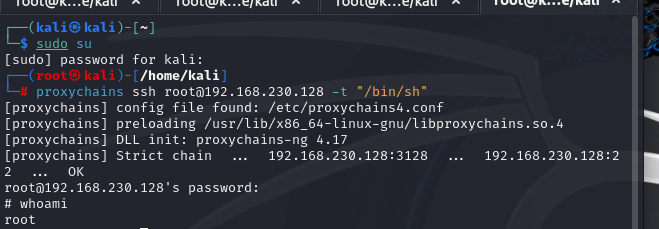
在深度学习的分类问题中,二分类和多分类的结果常用混淆矩阵(Confusion Matrix)来呈现。此外,还有许多评价指标用于衡量模型性能,比如精度(Accuracy)、查准率(Precision)、召回率(Recall)、F1值等。
1. 混淆矩阵
对于二分类问题,混淆矩阵通常是一个
2
×
2
2×2
2×2 的矩阵:

- TP(True Positive): 预测为正类,且实际为正类。
- FP(False Positive): 预测为正类,但实际为负类。
- FN(False Negative): 预测为负类,但实际为正类。
- TN(True Negative): 预测为负类,且实际为负类。
对于多分类问题,混淆矩阵的维度为 n × n n×n n×n,其中 n n n 是类别数量。每个元素 C i j C_{ij} Cij表示实际类别 i i i被预测为类别 j j j的次数。
2.评价指标
- 精度(Accuracy)
精度是所有预测正确的比例,计算公式为:

- 查准率(Precision)
查准率衡量的是模型在预测为正类的样本中,实际为正类的比例:

- 召回率(Recall)
召回率衡量的是在所有实际为正类的样本中,模型能正确预测为正类的比例:

- F1值(F1-Score)
F1值是 Precision 和 Recall 的调和平均数,用来平衡查准率和召回率:

- 特异度(Specificity)
特异度衡量的是在所有实际为负类的样本中,模型能正确预测为负类的比例:

- ROC曲线与AUC
ROC曲线: 以假正率(FPR)为横轴,真正率(TPR,即召回率)为纵轴的曲线。
AUC(Area Under Curve): ROC曲线下的面积,表示模型分类能力。
FPR 公式为:

3.混淆矩阵及评价指标的实现(Python代码示例)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score, roc_curve, auc
import seaborn as sns
# 模拟真实标签和预测标签
y_true = [0, 1, 1, 0, 1, 0, 1, 0, 0, 1]
y_pred = [0, 0, 1, 0, 1, 0, 1, 1, 0, 1]
# 计算混淆矩阵
cm = confusion_matrix(y_true, y_pred)
print("Confusion Matrix:\n", cm)
# 混淆矩阵的可视化
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
# 计算各项评价指标
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f'Accuracy: {accuracy}')
print(f'Precision: {precision}')
print(f'Recall: {recall}')
print(f'F1 Score: {f1}')
# 计算并绘制ROC曲线
fpr, tpr, thresholds = roc_curve(y_true, y_pred)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, color='blue', label=f'AUC = {roc_auc:.2f}')
plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend(loc="lower right")
plt.show()
4.多分类问题中的评价指标
在多分类问题中,Precision、Recall 和 F1值可以通过**微平均(micro average)和宏平均(macro average)**来计算:
- 微平均:对所有类的 TP、FP、FN 求和后再计算指标。
- 宏平均:分别计算每个类别的 Precision、Recall 和 F1,然后取平均。
你可以通过 average 参数在 sklearn 的 Precision_score、Recall_score 和 F1_score 中选择不同的方式:
# 多分类示例
y_true_multi = [0, 1, 2, 1, 2, 0, 1, 2, 0, 1]
y_pred_multi = [0, 2, 1, 1, 2, 0, 1, 2, 0, 2]
# 计算宏平均和微平均
precision_macro = precision_score(y_true_multi, y_pred_multi, average='macro')
precision_micro = precision_score(y_true_multi, y_pred_multi, average='micro')
print(f'Macro Average Precision: {precision_macro}')
print(f'Micro Average Precision: {precision_micro}')
5.总结
-
混淆矩阵提供了一个直观的工具来查看模型的预测效果。
-
评价指标如精度、查准率、召回率、F1值等用于量化模型性能。
-
多分类问题中,可以使用宏平均和微平均来评价模型在多个类别上的表现。








![[NSSRound#4 SWPU]hide_and_seek-用gdb调试](https://i-blog.csdnimg.cn/direct/64d705c03ef44f208a66d61e44dc4235.png)

![re题(25)BUUFCTF-[GUET-CTF2019]re](https://i-blog.csdnimg.cn/blog_migrate/05437e17bfb1189ab11a35ca9a1731a2.png)