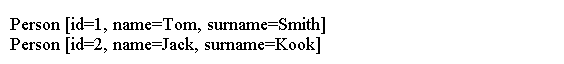自然语言处理
- 词嵌入和word2vec
- 词义搜索和句意表示
- 预训练模型
- Hugging Face库介绍
- 经典NLP数据集
- 代码案例-电影评论情感分析
词嵌入和word2vec
词嵌入是一种 将高维的数据表示映射到低维空间的方法
word embedding 是将语言中的词编码成向量便于后续的分析和处理
词嵌入和词向量基本上是同一个东西
独热编码 one hot
独热编码是一种对分类数据进行编码的方法
独热编码给每种类别分配了一列,属于该类别的该列为1,其他列为0

独热编码的缺陷
词袋模型,丢失了词的顺序信息
词间正交,难以表示词义
大词表导致矩阵稀疏

更好的词向量表示方法
Word2Vec 方法
《Efficient Estimation of Word Representations in Vector Space》

CBOW 是上下文预测当前词
Skip是当前词预测上下文
连续词袋模型!CBOW

跳元模型 Skip-Gram

近似训练技巧

代码实现





词义搜索和句意表示
文本搜索方法

正则搜索
优点
- 匹配精准
- 代码简洁
问题 - 难以理解语义·
- 可读性差
- 性能较低
- 维护困难
- 灵活性低

词义搜索
- 基于词嵌入
- 相似度搜索
- 类比搜索

相比传统关键词搜索,词义搜索可以更加准确理解文本的内容,无需人工配置规则或者 同义词典,可以很好实现信息的检索,文本分类 机器翻译等NLP任务
距离计算方法

句子向量 Doc2vec
加权平均法
PV-DM
PV-DBOW





按句号 叹号 问号来换行



训练代码看之前的博客







应用:
搜索引擎
推荐系统
机器翻译

预训练模型
word2vector和doc2vector并不是当前最佳解决方案
对一词多义 和上下文信息把握并不好
对长难句也难以学到全部信息
随着transformer的发展
效果更好的词嵌入训练方法更好
比如gpt、bert、t5模型
预训练和迁移学习
迁移学习
特征转移:将有效的特征表征引入到目标任务中
参数传递:将知识编码进共享模型参数中


自回归语言模型主要用于文本生成任务
根据上下文生成下一个词,从而实现对语言的理解和生成
自回归模型优势在于可以生成 流畅自然的文本适合于文本生成对话系统等任务
但生成时需要一步步生成每一个词,计算量比较大,不太适合实时应用场景
自编码语言模型主要用于文本编码和表示学习
将文本输入编码进行转化成固定维度向量从而实现对语言的理解和表示
优势在于可以捕获文本和句子的语义信息,适合文本分类、文本相似度的计算等任务
但不擅长生成任务
而且对于较长的文本输入可能出现信息损失的情况



GPT4 多模态

存在的问题
- 模型架构设计
- Finetune的知识迁移·
- 可解释性
- 结果可靠性

Hugging Face库介绍
方便调用预训练模型
Transformers 模型库·
- AutoModel模型库
- AutoTokenizer 工具库
Datasets 数据集库


一种代码直接调用,另一种克隆项目

数据集











经典NLP数据集
预训练语料集
- Penn Treebank
- WikiText
下游任务数据集 - Glue
- Super glue
- Kaggle数据集
Penn Treebank数据集
语料来源:华尔街日报(1989)·
语料规模:1M+
中文树库:
中文宾州树库
清华树库
台湾中研树库


代码案例-电影评论情感分析
情感分析
分类任务
负面·
正面
(中性 | 偏正面 | 偏负面)
用途
舆情监控
投资决策
产品口碑
电影评价

hugging face提供

预训练模型效果已经很不错
但一般还需要根据实际业务场景对模型进行加训或者微调