随着OpenAI o1发布,进一步激发了产业与学术各界对AGI的期待以及new scaling law下的探索热情,也看到来自社区和专业机构对o1的阐释,但总感觉还差点什么,因此决定以自己的角度分篇幅梳理下,并分享给大伙:
OpenAI o1在训练过程所采用的RL实际上可以理解为对long reasoning chain(长程推理链&步骤)的某种迭代式泛化能力探索explore,在这种探索下也很自然的形成了对模型从训练到推理两个阶段的动态渐进与平衡,而这当然也来源于强化学习RL中的R与L两者组合的结构范式本身,从而直观上形成了从training from real world data → influence to synthetis data的scaling law扩展与转移,且在这种新的scaling law下尝试性的铺设了一条通往AGI的相对平坦的“临时阶段性”道路。
ps:某种程度上,我想其也源于对人类system2·慢思考行为的形式化模拟。
而之所以称之为“临时阶段性”,我想表达的核心观点在于:o1的这种范式也许与像Alphazero那种传统的RL+E2E相对暴力一点的认知推理范式有着些许的不同或不得不的改良。
而导致LLM(或者直接称为AGI)与AlphaGo间两种范式不同之处的本质也许在于两者所承载的完整认知流形空间分布的复杂程度上的差别(有关认知流形分布的内容请大家参考置顶笔记或之前写的10万字文章):
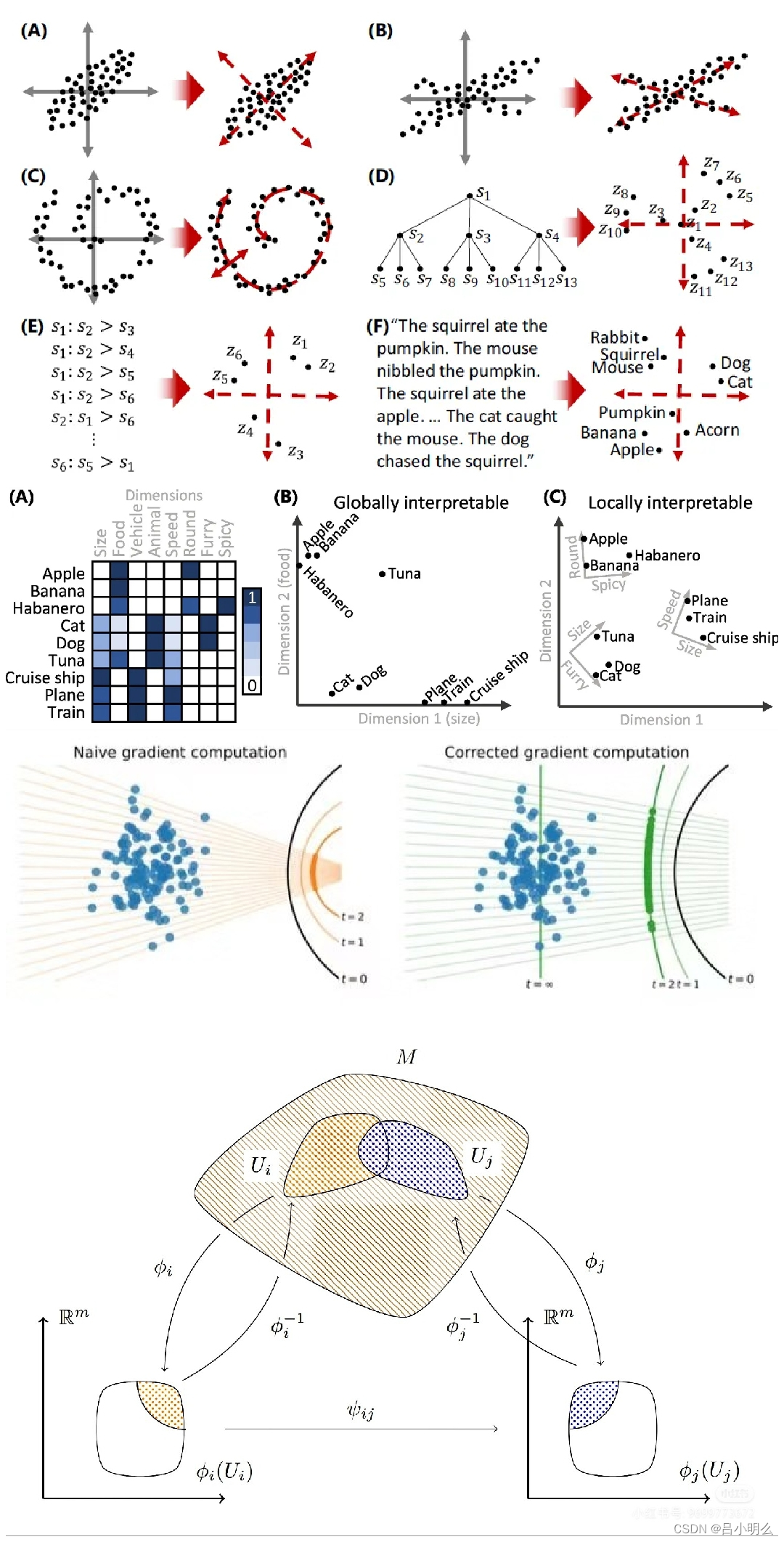
拿围棋来讲,其策略网络下的行动探索和决策空间被局限在棋盘的落子位置上,而相比于LLM的tokenize世界中的next token prediction所囊括的探索空间及推理路径在pattern映射精细度、空间维度的大小以及形成的流形表征分布下所涵盖的泛化尺度有着天壤之别。
而这也为LLM与RL的思想范式融合带来了极大的挑战(当然挑战不局限于此,还包括self play机制与RM奖励信号反馈稀疏性等挑战,这里先暂且按下不表,属于另一相对独立的问题,后续单独阐述)。
因此,我想OpenAI的o1在当前阶段为了尽量逼近AlphaGo那样的E2E(端到端)RL下的极致落子策略效果,且避免直面硬刚上述复杂的结构性挑战,同时必要性的考虑并借鉴拟人类system2慢思考思维模式,采用了一种折中或也许是过渡性策略,从而将long chain reasoning与RL training放在模型网络信号传播与计算中的统一视角来看待,即实现了两种传播策略间计算的平衡与统一,从而衍生出了new scaling law下的扩展和转移的观念...
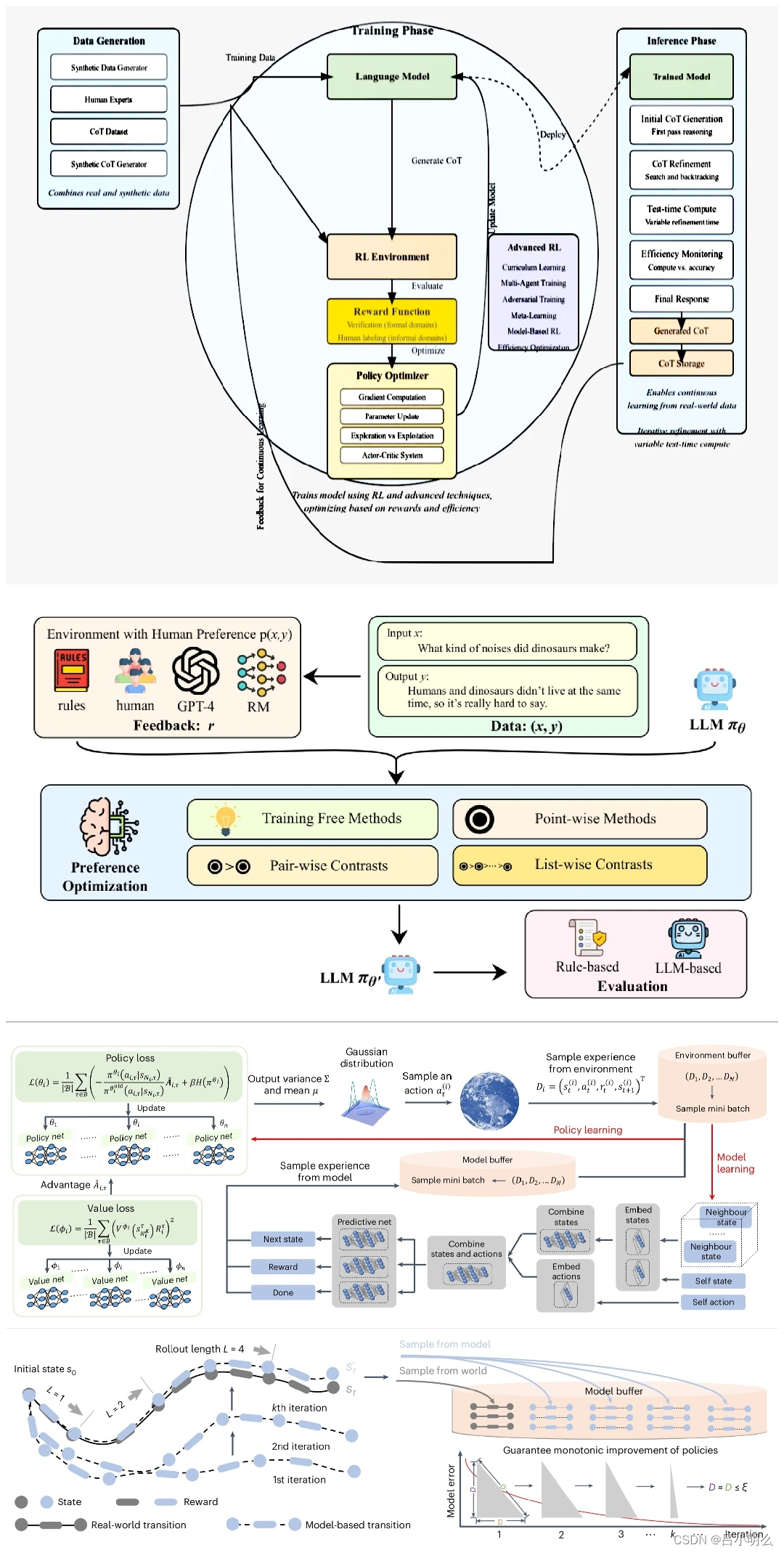
后续将继续尝试围绕上述两种传播与计算策略间微妙的平衡与隐含于其中的泛化能力动态演进进行阐释,期待与大家共同探讨~