本文所有的代码均基于 node.js 14 LTS 版本分析
概念
进程是对正在运行中的程序的一个抽象,是系统进行资源分配和调度的基本单位,操作系统的其他所有内容都是围绕着进程展开的
线程是操作系统能够进行运算调度的最小单位,其是进程中的一个执行任务(控制单元),负责当前进程中程序的执行
一个进程至少有一个线程,一个进程可以运行多个线程,这些线程共享同一块内存,线程之间可以共享对象、资源
单线程
require("http")
.createServer((req, res) => {
res.writeHead(200);
res.end("Hello World");
})
.listen(8000);
console.log("process id", process.pid);
top -pid 28840 查看线程数可见在这种情况下有 7 个线程

一个 node 进程通常包含:
- 1 个 Javascript 执行主线程
- 1 个 watchdog 监控线程用于处理调试信息
- 1 个 v8 task scheduler 线程用于调度任务优先级
- 4 个 v8 线程用于执行代码调优与 GC 等后台任务
- 异步 I/O 的 libuv 线程池(如果涉及文件读写,默认为 4 个,可通过
process.env.UV_THREADPOOL_SIZE进行设置。网络 I/O 不占用线程池)

事件循环
既然 js 执行线程只有一个,那么 node 还能支持高并发在于 node 进程中通过 libuv 实现了一个事件循环机制,当执主程发生阻塞事件,如 I/O 操作时,主线程会将耗时的操作放入事件队列中,然后继续执行后续程序。
事件循环会尝试从 libuv 的线程池中取出一个空闲线程去执行队列中的操作,执行完毕获得结果后,通知主线程,主线程执行相关回调,并且将线程实例归还给线程池。通过此模式循环往复,来保证非阻塞 I/O,以及主线程的高效执行
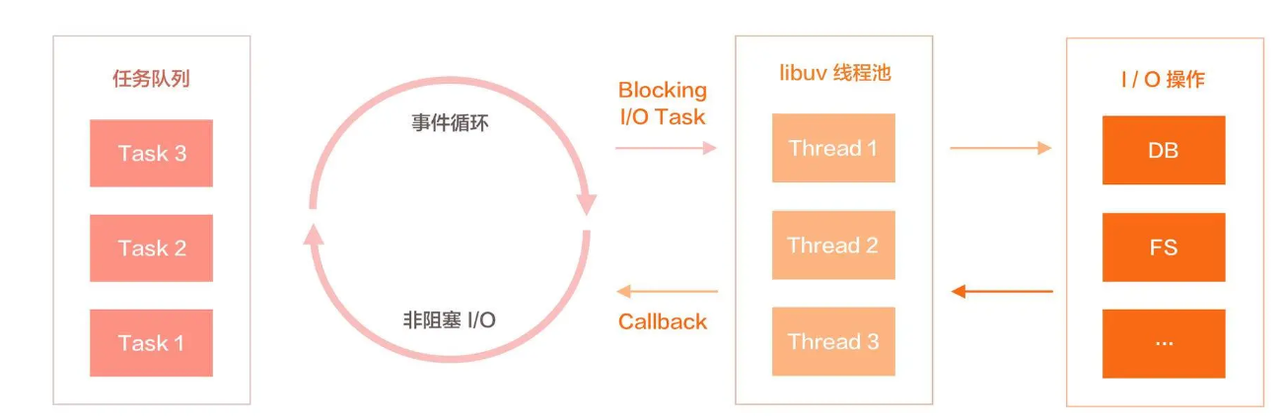
整个流程分为 2 个 while 循环
- 外层大循环,执行
uv_run+DrainVMTasks - 内层 libuv
uv_run事件循环
//src/node_main_instance.h
// ...
// Start running the node.js instances, return the exit code when finished.
int Run();
// ...
// src/node_main_instance.cc
namespace node {
// ...
int nodeMainInstance::Run() {
do {
// 执行一次libuv事件循环
uv_run(env->event_loop(), UV_RUN_DEFAULT);
// 执行v8中的一些挂起的任务队列的函数
per_process::v8_platform.DrainVMTasks(isolate_);
// 检查事件循环是否还有待处理
more = uv_loop_alive(env->event_loop());
// 继续
if (more && !env->is_stopping()) continue;
// 无待处理
if (!uv_loop_alive(env->event_loop())) {
// 检查process.on(beforeExit)事件,若无退出
if (EmitProcessBeforeExit(env.get()).IsNothing())
break;
}
// 若有继续下一轮循环处理一下
// Emit `beforeExit` if the loop became alive either after emitting
// event, or after running some callbacks.
more = uv_loop_alive(env->event_loop());
} while (more == true && !env->is_stopping());
//....
}
}
主要有 libuv 提供的两个函数uv_run 和 uv_loop_alive
uv_run(env->event_loop(), UV_RUN_DEFAULT)执行一轮事件循环 。UV_RUN_DEFAULT是 libuv 执行事件循环的执行模式,事件循环会一直运行直到没有更多的事件要处理或者程序被强制退出
typedef enum {
UV_RUN_DEFAULT = 0,// 默认模式。在该模式下,事件循环会一直运行,直到没有更多的事件要处理或者程序被强制退出
UV_RUN_ONCE,// 单次模式。在该模式下,事件循环只会运行一次,处理完所有当前已有的事件后立即退出。主要用于一些清理操作
UV_RUN_NOWAIT // 非阻塞模式。在该模式下,事件循环会轮询当前的 I/O 事件,如果没有 I/O 事件需要处理则立即退出。在node代码中用来写单测
} uv_run_mode;
uv_run代码如下,它的返回值是是否有活跃事件
int uv_run(uv_loop_t* loop, uv_run_mode mode) {
int timeout;
int r;
int ran_pending;
// 判断有没有活跃的事件(事件监听 I/O、定时器等)
r = uv__loop_alive(loop);
// 无活跃事件,更新时间 loop->time = uv__hrtime(UV_CLOCK_FAST) / 1000000
if (!r)
uv__update_time(loop);
// 若有活跃事件进进入
while (r != 0 && loop->stop_flag == 0) {
// 更新处理时间
uv__update_time(loop);
// 执行定时事件,从定时事件的最小堆里遍历出相较于loop->time 已过期的事件,并依次执行其回调
uv__run_timers(loop);
// ⭐️ 运行事件循环中当前已经被添加到队列中但还未执行的任务。如上次事件循环结束后进入的回调、IO结束的回调
ran_pending = uv__run_pending(loop);
// 遍历并执行空转(Idle)事件 ,内部的低优先级的任务或者清理工作等操作
uv__run_idle(loop);
// 遍历并执行准备(Prepare)事件,一些初始化工作或者准备工作,例如检查环境变量、加载配置文件等操作
uv__run_prepare(loop);
timeout = 0;
if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT)
// 获取尚未触发的离现在最近的定时器的时间间隔(uv_backend_timeout),即事件循环到下一次循环的最长时间
timeout = uv_backend_timeout(loop);
// ⭐️ 去监听等待 I/O 事件触发,并以timeout的时间间隔作为最大监听时间,若超时还未有事件触发,则直接取消此次等待,剩下的会在下轮的uv__run_pending处理,因为要去处理定时器事件
// timeout如果为0则马上进入下次循环不等待
uv__io_poll(loop, timeout);
// 更新一下mertic一些统计相关,和事件循环好像没啥关系
uv__metrics_update_idle_time(loop);
// ⭐️ 遍历并执行复查(Check)事件
uv__run_check(loop);
// ⭐️ 对于正在关闭的句柄(一些异步操作引用的底层资源释放)对其进行清理工作,如close事件
uv__run_closing_handles(loop);
if (mode == UV_RUN_ONCE) {
// 单次模式下更新下最新更新时间,再把定时器清理完下面就break,确保退出时没有一些定时器到期没执行
uv__update_time(loop);
uv__run_timers(loop);
}
// 又检查一遍是否还有活跃事件,因为在上述一系列操作,有可能一些事件已经处理了
r = uv__loop_alive(loop);
// 只执行一次的退出
if (mode == UV_RUN_ONCE || mode == UV_RUN_NOWAIT)
break;
}
if (loop->stop_flag != 0)
// 重置flag便于下次事件循环
loop->stop_flag = 0;
return r;
}
uv_backend_timeout 正常是查询最近的定时器间隔,有几种情况返回 0,即有一些更重要的事要做而不是同步等待 io 事件
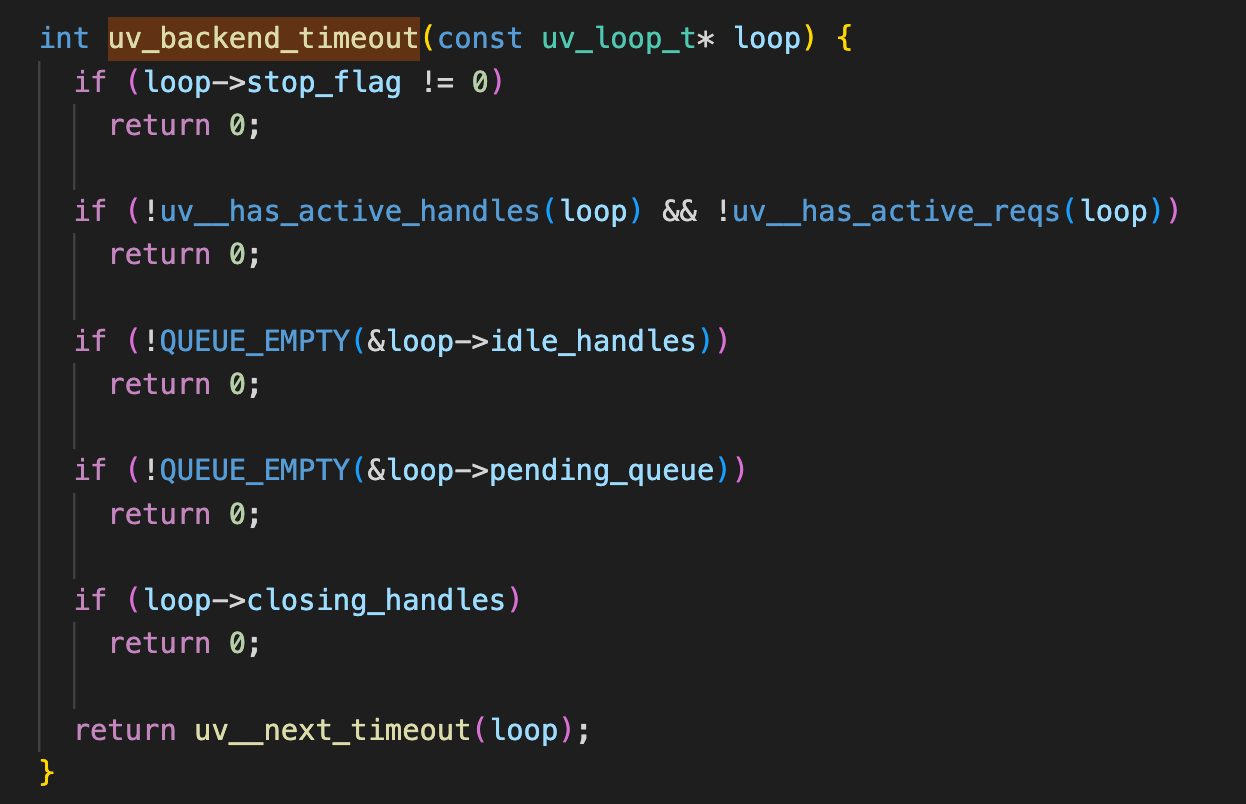
其中idle_handles 由setImmediate 设置执行一些高优任务,马上进入下一次循环处理setImmediate回调
一次事件循环总结

uv_loop_alive(env->event_loop())
即上面提到的 uv__loop_alive, 判断有没有活跃的事件(事件监听 I/O、定时器等)
总结
严格意义上来说对开发者写代码来说是单线程的,但是对于底层来说是多线程(例如源码中会有 SafeMap 这种线程安全的 map)。由于对于开发者来说是单线程,所以在 Node.js 日程开发中通常不会存在线程竞争的问题和线程锁的一些概念
子进程
从上面的单线程机制可知 Node.js 使用事件循环机制来实现高并发的 I/O 操作。但是如果代码中遇到 CPU 密集型场景,主线程将会长时间阻塞,无法处理额外的请求。为了解决这个问题,并充分发挥多核 CPU 的性能,Node 提供了 child_process 模块用于创建子进程。通过将 CPU 密集型操作分配给子进程处理,主线程可以继续处理其他请求,从而提高性能
主要提供了 4 个方法
spawn(command[, args][, options]):以指定的命令及参数数组创建一个子进程。可以通过流来处理子进程的输出和错误信息,大数据量
const { spawn } = require("child_process");
const ls = spawn("ls", ["-lh", "/usr"]);
ls.stdout.on("data", (data) => {
console.log(`stdout: ${data}`);
});
ls.stderr.on("data", (data) => {
console.error(`stderr: ${data}`);
});
ls.on("close", (code) => {
console.log(`子进程退出码:${code}`);
});
exec(command[, options][, callback]):对spawn()函数的封装,可以直接传入命令行执行,并以回调函数的形式返回输出和错误信息
const { exec } = require("child_process");
exec("ls -lh /usr", (error, stdout, stderr) => {
if (error) {
console.error(`exec error: ${error}`);
return;
}
console.log(`stdout: ${stdout}`);
console.error(`stderr: ${stderr}`);
});
execFile(file[, args][, options][, callback]):类似于exec()函数,但默认不会创建命令行环境(相应的无法使用一些 shell 的操作符),而是直接以传入的文件创建新的进程,性能略微优于exec()。
const { execFile } = require("child_process");
execFile("ls", ["-lh", "/usr"], (error, stdout, stderr) => {
if (error) {
console.error(`execFile error: ${error}`);
return;
}
console.log(`stdout: ${stdout}`);
console.error(`stderr: ${stderr}`);
});
fork(modulePath[, args][, options]):内部使用spawn()实现 ,只能用于创建 node.js 程序的子进程,默认会建立父子进程之间的 IPC 信道来传递消息
const { fork } = require("child_process");
const lsProcess = fork("./test.js");
lsProcess.on("message", (msg) => {
console.log(`收到子进程的消息:${msg}`);
});
lsProcess.on("close", (code) => {
console.log(`子进程退出码:${code}`);
});
- js -
lib/child_process.js
const child_process = require("internal/child_process");
const { ChildProcess } = child_process;
function spawn(file, args, options) {
//...
const child = new ChildProcess();
//....
return child;
}
module.exports = {
_forkChild,
ChildProcess,
exec,
execFile,
execFileSync,
execSync,
fork,
spawn: spawnWithSignal,
spawnSync,
};
lib/internal/child_process.js
const { Process } = internalBinding("process_wrap");
this._handle = new Process();
ChildProcess.prototype.spawn = function (options) {
//..
const err = this._handle.spawn(options);
//..
};
- c++ -
src/node_binding.cc

src/process_wrap.cc

Cluster
基于child_process node 提供了专门用于创建多进程网络服务的[cluster](https://nodejs.org/api/cluster.html)模块
创建多个子进程,并在每个子进程中启动一个独立的 HTTP 服务器进行监听和处理客户端请求
const cluster = require("cluster");
const http = require("http");
const numCPUs = require("os").cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
// 创建多个子进程
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
// 监听子进程退出事件,自动重启
cluster.on("exit", (worker, code, signal) => {
console.log(`Worker ${worker.process.pid} died`);
cluster.fork();
});
} else {
console.log(`Worker ${process.pid} started`);
// 每个子进程的pid是不一样
// 在每个子进程中启动 HTTP 服务器
http
.createServer((req, res) => {
res.writeHead(200);
res.end("Hello, world!");
})
.listen(8000);
}
如何解决多个工作进程监听一个端口的问题
从 js 层面分析
- 入口区分 - 子进程环境变量含
NODE_UNIQUE_ID,在创建子进程时传入
// lib/cluster.js
const childOrMaster = "NODE_UNIQUE_ID" in process.env ? "child" : "master";
module.exports = require(`internal/cluster/${childOrMaster}`);
http.createServer->lib/_http_server.js#Server-lib/_http_server.js#Server继承于 TCP 的lib/net.js#Serverlisten方法调用的是lib/net.js#Server
// lib/net.js
Server.prototype.listen = function (...args) {
// ....
// 关键逻辑
if (typeof options.port === "number" || typeof options.port === "string") {
validatePort(options.port, "options.port");
backlog = options.backlog || backlogFromArgs;
// start TCP server listening on host:port
if (options.host) {
lookupAndListen(
this,
options.port | 0,
options.host,
backlog,
options.exclusive,
flags
);
} else {
// Undefined host, listens on unspecified address
// Default addressType 4 will be used to search for master server
listenInCluster(
this,
null,
options.port | 0,
4,
backlog,
undefined,
options.exclusive
);
}
return this;
}
//....
};
lookupAndListen内部其实也是对option.host进行调dns模块查询host后调的listenInCluster
// 工作进程
function listenInCluster(
server,
address,
port,
addressType,
backlog,
fd,
exclusive,
flags
) {
exclusive = !!exclusive;
if (cluster === undefined) cluster = require("cluster");
// isMaster是通过NODE_UNIQUE_ID是否存在判断
// 非cluster的http模块直接起服务NODE_UNIQUE_ID是空
if (cluster.isMaster || exclusive) {
server._listen2(address, port, addressType, backlog, fd, flags);
return;
}
const serverQuery = {
address: address,
port: port,
addressType: addressType,
fd: fd,
flags,
};
cluster._getServer(server, serverQuery, listenOnMasterHandle);
function listenOnMasterHandle(err, handle) {
// 获取handler后挂载到子进程server上
server._handle = handle;
server._listen2(address, port, addressType, backlog, fd, flags);
}
}
在 listenInCluster 函数中,会判断当前的进程是否是主进程,
- 如果是则直接进行调用
_listen2监听server。_listen2就是 cluster 出现之前的监听函数
Server.prototype._listen2 = setupListenHandle; // legacy alias
- 如果不是,则通过工作进程查询到主进程的
handle(const { TCP } = internalBinding('tcp_wrap');,c++层暴露的用于处理 TCP 的对象),然后在主进程的 handle 上进行监听
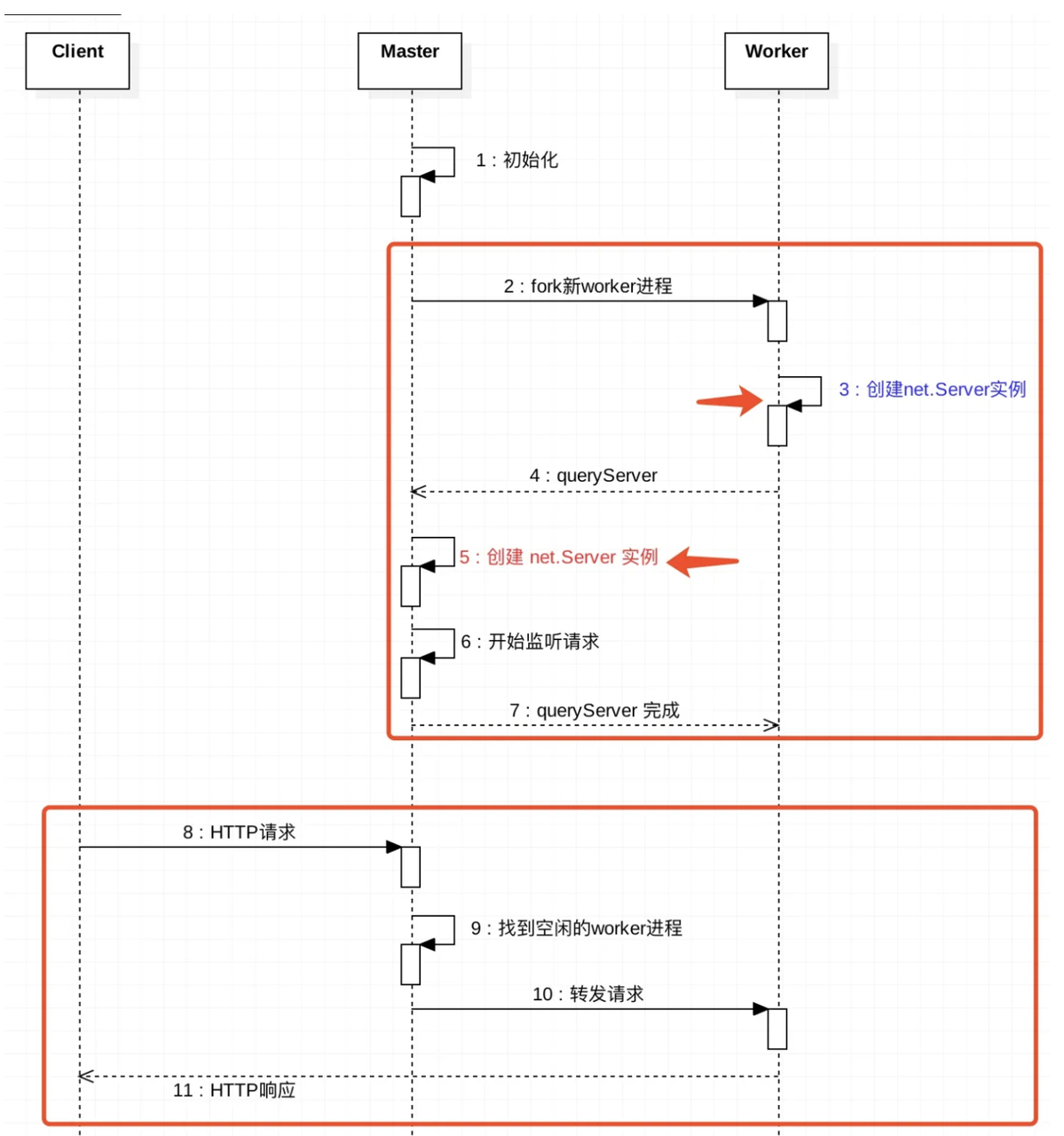
cluster._getServer实现
主要逻辑是向当前工作进程发送一个类型为 queryServer 的消息,这个消息会被处理成 cluster 内部消息后发送给主进程
// lib/internal/cluster/child.js
cluster._getServer = function(obj, options, cb) {
// ...
const message = {
act: 'queryServer',
index,
data: null,
...options
};
message.address = address;
send(message, (reply, handle) => {
else
// 进这个分支
rr(reply, indexesKey, cb); // Round-robin.
//...
});
obj.once('listening', () => {
//..
send(message);
//...
});
};
主进程有相应的响应 queryServer 消息的地方
// lib/internal/cluster/master.js
function onmessage(message, handle) {
//...
else if (message.act === 'queryServer')
queryServer(worker, message);
//...
}
function queryServer(worker, message) {
//....
// 唯一标识
const key = `${message.address}:${message.port}:${message.addressType}:` +
`${message.fd}:${message.index}`;
let handle = handles.get(key);
if (handle === undefined) {
let address = message.address;
//第一次进入时,会创建RoundRobinHandle,RoundRobinHandle内部有实际监听端口的逻辑
let constructor = RoundRobinHandle;
handle = new constructor(key, address, message);
//....
handles.set(key, handle);
}
if (!handle.data)
handle.data = message.data;
// 添加当前工作进程加入到RoundRobinHandle工作队列
handle.add(worker, (errno, reply, handle) => {
const { data } = handles.get(key);
send(worker, {
errno,
key,
ack: message.seq,
data,
...reply
}, handle);
});
}
// lib/internal/cluster/round_robin_handle.js
function RoundRobinHandle(key, address, { port, fd, flags }) {
//...
this.server = net.createServer(assert.fail);
//...
this.server.listen(address);
// 主进程处理请求分发
this.server.once('listening', () => {
this.handle = this.server._handle;
this.handle.onconnection = (err, handle) => this.distribute(err, handle);
});
}
RoundRobinHandle 也会覆盖主进程的Server.handle 的 onconnection 逻辑,将其替换成 round-robin 逻辑,即this.handle.onconnection = (err, handle) => this.distribute(err, handle);
再回到这个代码
// 工作进程
cluster._getServer(server, serverQuery, listenOnMasterHandle);
// _getServer实现
send(message, (reply, handle) => {
// ....
else
// 进这个分支
// reply
rr(reply, indexesKey, cb); // Round-robin.
//...
});
function listenOnMasterHandle(err, handle) {
// 获取handler后挂载到子进程server上
server._handle = handle;
server._listen2(address, port, addressType, backlog, fd, flags);
}
在 rr 函数中创建一个 fake handler 返回
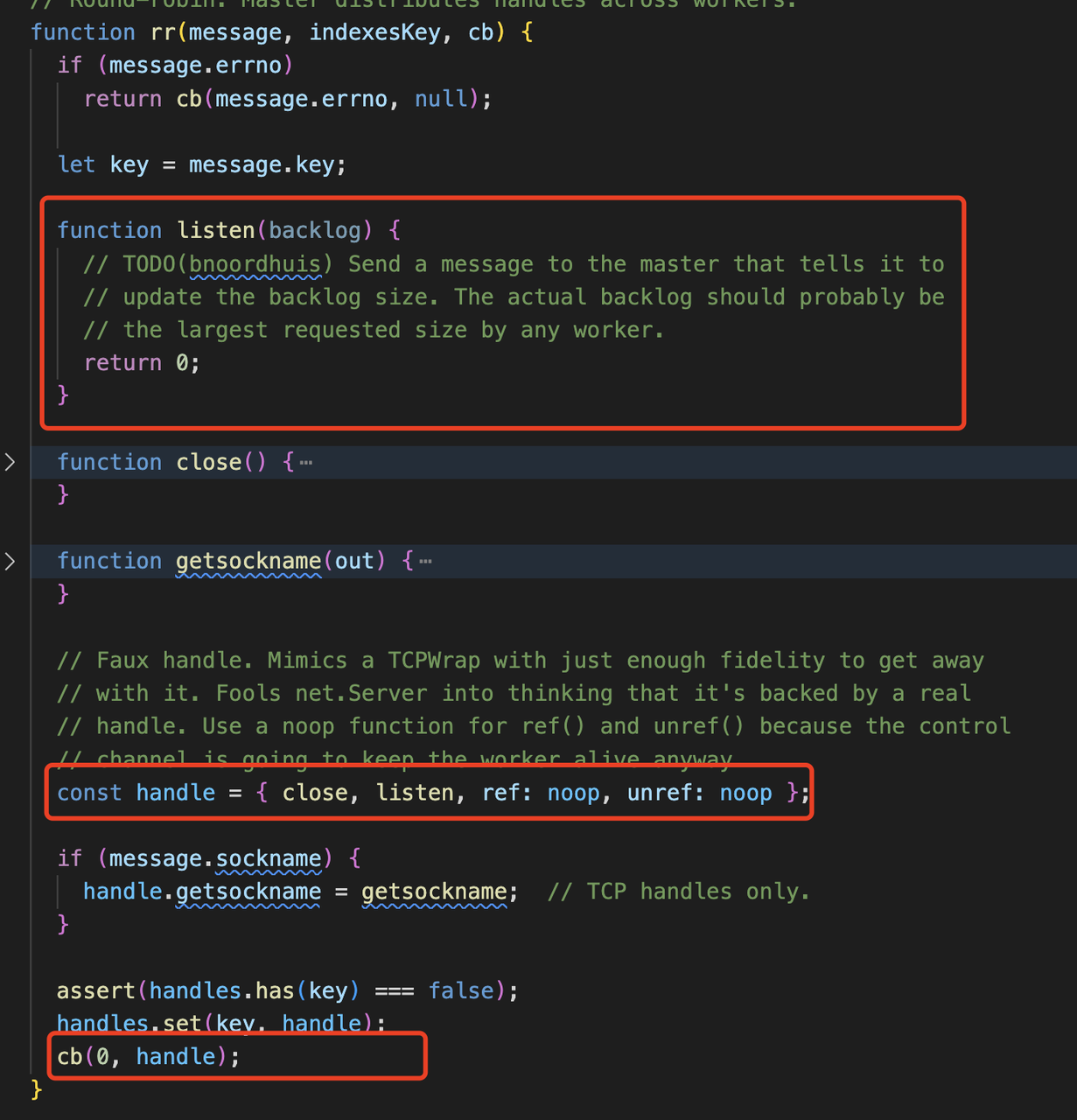

这个 handler 就是上面 rr 函数中获取的 handler,而_listen2内部调用的实际是 fake handler 中的 listen 空函数,实际上工作进程并没有对端口进行监听
RoundRobinHandle 的distribute实现
// lib/internal/cluster/round_robin_handle.js
RoundRobinHandle.prototype.distribute = function (err, handle) {
ArrayPrototypePush(this.handles, handle);
const [workerEntry] = this.free; // this.free is a SafeMap
// 选择一个空闲的进程处理
if (ArrayIsArray(workerEntry)) {
const { 0: workerId, 1: worker } = workerEntry;
this.free.delete(workerId);
this.handoff(worker);
}
};
RoundRobinHandle.prototype.handoff = function (worker) {
//...
const handle = ArrayPrototypeShift(this.handles);
const message = { act: "newconn", key: this.key };
//...
// 取出handler分发给子进程,消息的act为newconn
sendHelper(worker.process, message, handle, (reply) => {
// 使用轮询进行分发
if (reply.accepted) handle.close();
else this.distribute(0, handle); // Worker is shutting down. Send to another.
this.handoff(worker);
});
};
工作进程处理newconn消息
// lib/internal/cluster/child.js
// sendHelper分发的事件会带上cmd: 'NODE_CLUSTER',NODE_前缀的会触发internalMessage
process.on("internalMessage", internal(worker, onmessage));
send({ act: "online" });
function onmessage(message, handle) {
if (message.act === "newconn") onconnection(message, handle);
else if (message.act === "disconnect")
ReflectApply(_disconnect, worker, [true]);
}
function onconnection(message, handle) {
// 在子进程接收到handle引用后,它会重新创建一个与主进程相对应的 handle 对象,从而实现对共享资源的访问
const key = message.key;
const server = handles.get(key);
const accepted = server !== undefined;
send({ ack: message.seq, accepted });
if (accepted)
// lib/net.js里面tcp server的onconnection处理
server.onconnection(0, handle);
}
总结
当主进程的 RoundRobinHandle 接收到一个监听请求时,它会调用distribute函数将客户端的 handle(socket 对象) 传递给工作进程。具体的逻辑为:将这个 handle 保存到队列中,并从工作进程队列中获取一个空闲的工作进程。如果存在空闲的工作进程,则从队列中取出一个工作进程并向其发送act: "newconn" 消息,以将 handle 传递给工作进程。工作进程会使用此 handle 与客户端建立连接,并向主进程发送一条消息表示是否接受了请求。主进程通过 accepted 属性来判断工作进程是否已经接受了请求。如果是则关闭与客户端的连接,并让其与工作进程进行通信。最后,主进程会不断地轮询上述过程以处理更多的客户端请求
多线程
为了降低 js 对于 CPU 密集型任务计算的负担,node.js v10 之后引入了 worker_threads。可以在 nodejs 进程内可以创建多个线程。主线程和 worker 线程之间可以通过parentPort实现通信,worker 线程之间可以使用 MessageChannel 进行通信。多个线程之间可以使用SharedArrayBuffer实现共享内存,无需序列化
const {
Worker,
isMainThread,
parentPort,
workerData,
} = require("worker_threads");
if (isMainThread) {
// 主线程创建共享内存
const sharedBuffer = new SharedArrayBuffer(1024);
const worker = new Worker(__filename, { workerData: sharedBuffer });
// 向子线程发送共享内存的引用
worker.postMessage(sharedBuffer);
// 接收子线程发送的消息
worker.on("message", (data) => {
console.log("sharedBuffer", sharedBuffer);
});
} else {
// 子线程接收主线程发送的共享内存引用,并使用Atomics操作进行读写
const sharedBuffer = workerData;
const sharedArray = new Int32Array(sharedBuffer);
setInterval(() => {
const oldValue = Atomics.load(sharedArray, 0);
const newValue = oldValue + 1;
Atomics.store(sharedArray, 0, newValue);
parentPort.postMessage(`Current value in shared memory: ${newValue}`);
}, 1000);
}
多线程下共享内存为避免者竞态条件。node.js 也提供了Atomics对象用于执行原子操作,可以保证多个线程对共享内存的读写操作原子性