进程:运行中的程序
线程:进程中的进程
线程的最大数量取决于CPU的核心数
一、将两个函数添加到不同线程中
demo:两个函数test01()和test02(),实现将用户输入的参数进行打印输出1000次
将这两个函数均放到独立的线程t1和t2中,可实现独立的运作,与主函数独立执行
#include <thread>线程头文件
std::thread t1(test01, 10);创建线程t1,第一个参数为函数名,第二个参数为对应函数的参数;若函数没有参数,则不需要填入
if (t1.joinable())判断线程t1是否可以加入到主线程中,若可以加入,t1.join();则加入到主线程中
子线程加入到主线程可以保证主线程会等待子线程运行完毕之后再结束
t1.join();是将子线程t1则加入到主线程中
t1.detach();是将主线程main和子线程t1分离,确保主线程结束后,子线程仍可以再后台执行
t1.join();较为常用
#include <iostream>
#include <thread>
#include <string>
void test01(int num)
{
for (int i = 0; i < 1000; i++)
{
std::cout << "test01 " << num << " " << i << std::endl;
// test01 10 0
// test01 10 1
// test01 10 2
//...
}
}
void test02(std::string str)
{
for (int i = 0; i < 1000; i++)
{
std::cout << "test02 " << str << " " << i << std::endl;
// test02 hello beyond 0
// test02 hello beyond 1
// test02 hello beyond 2
// ...
}
}
int main(int argc, char* argv[])
{
//创建线程,把函数名和参数传递给线程
std::thread t1(test01, 10);//第一个参数是函数名,第二个参数是该函数所需要的参数
std::thread t2(test02, "hello beyond");//第一个参数是函数名,第二个参数是该函数所需要的参数
if (t1.joinable()) //判断线程是否还在运行
{
//若没有将t1线程加入到主线程,则主线程结束时,t1线程也会结束,导致程序崩溃
t1.join(); //等待线程结束;若不把线程t1加入到主进程中,则主进程不会等待t1进程结束之后再结束,若主进程结束了,项目结束
//t1.detach(); //分离线程,主线程结束时,t1线程也会结束,不会导致程序崩溃;
//join()和detach()的区别在于:join()等待线程结束,detach()分离线程,主线程结束时,t1线程不会结束,可以继续运行
}
if (t2.joinable())
{
t2.join(); //等待线程结束;若不把线程t2加入到主进程中,则主进程不会等待t2进程结束之后再结束,若主进程结束了,项目结束
}
//主线程
for (int i = 0; i < 1000; i++)
{
std::cout << "main " << i << std::endl;
}
//就此开了三个线程(main()、t1、t2),三个线程并发执行
return 0;
}
运行效果

可以看到线程t1和t2是并发执行的,执行完之后,主线程main才进行执行
这说明,在主线程main中,程序是按顺序执行的;而相互独立的线程是并行执行的
二、引用类型传入线程中
若要操作同一个变量,在函数中需要传入该变量的引用
若要加入到线程中,则需要通过std::ref(a)将变量a的引用加入到线程中,操作的都是该变量a,共享同一个变量a
#include <iostream>
#include <thread>
#include <string>
void test01(int& num1) //引用传递
{
for (int i = 0; i < 10; i++)
{
num1++;
}
}
void test02(int num2) //值传递
{
for (int i = 0; i < 10; i++)
{
num2++;
}
}
int main(int argc, char* argv[])
{
int num1 = 0;
int num2 = 0;
std::thread t1(test01, std::ref(num1));//引用传递
std::thread t2(test02, num2);//值传递
if (t1.joinable())
{
t1.join();
}
if (t2.joinable())
{
t2.join();
}
std::cout << "num1 = " << num1 << std::endl;// 输出结果为10
std::cout << "num2 = " << num2 << std::endl;// 输出结果为0
return 0;
}
三、锁和死锁
1,现象分析:

俩线程都对num进行自加10000次,期间会出现t1和t2线程同时拿到num,并自加,导致结果会重复多次,出现无效的自加效果
#include <iostream>
#include <thread>
#include <string>
void test01(int& num) //引用传递
{
for (int i = 0; i < 100000; i++)
{
num++;
}
}
void test02(int& num) //值传递
{
for (int i = 0; i < 100000; i++)
{
num++;
}
}
int main(int argc, char* argv[])
{
int num = 0;
std::thread t1(test01, std::ref(num));//引用传递
std::thread t2(test02, std::ref(num));//引用传递
if (t1.joinable())
{
t1.join();
}
if (t2.joinable())
{
t2.join();
}
//按理说num应该是200000,但是由于线程并发执行,导致结果可能是100000,也可能是200000
std::cout << "num = " << num << std::endl;
return 0;
}
运行结果:
实际效果并不是20000

2,解决方法:加锁
#include <mutex>互斥锁头文件
std::mutex mtx;定义互斥锁
mtx.lock();加锁
mtx.unlock();解锁
在加锁和解锁之间的数据是不允许多个线程进行操作
当线程t1拿到num之后立马加锁,线程t2就无法获取num,直到线程t1解锁后,线程t2才可以拿到num
加锁操作保证多线程安全
#include <iostream>
#include <thread>
#include <string>
#include <mutex>
std::mutex mtx;//定义互斥锁
void test01(int& num) //引用传递
{
for (int i = 0; i < 1000000; i++)
{
mtx.lock();//加锁
num++;
mtx.unlock();//解锁
}
}
void test02(int& num) //值传递
{
for (int i = 0; i < 1000000; i++)
{
mtx.lock();//加锁
num++;
mtx.unlock();//解锁
}
}
int main(int argc, char* argv[])
{
int num = 0;
std::thread t1(test01, std::ref(num));//引用传递
std::thread t2(test02, std::ref(num));//引用传递
if (t1.joinable())
{
t1.join();
}
if (t2.joinable())
{
t2.join();
}
//按理说num应该是200000,但是由于线程并发执行,导致结果可能是100000,也可能是200000
std::cout << "num = " << num << std::endl;
return 0;
}
运行效果:

3,死锁现象

#include <iostream>
#include <thread>
#include <string>
#include <mutex>
std::mutex mtx1, mtx2;//定义互斥锁
void test01(int& num1,int &num2) //引用传递
{
for (int i = 0; i < 10000; i++)
{
mtx1.lock();//加锁
num1++;
mtx2.lock();//加锁
num2++;
mtx2.unlock();//解锁
mtx1.unlock();//解锁
}
}
void test02(int& num1,int &num2) //值传递
{
for (int i = 0; i < 10000; i++)
{
mtx2.lock();//加锁
num2++;
mtx1.lock();//加锁
num1++;
mtx1.unlock();//解锁
mtx2.unlock();//解锁
}
}
int main(int argc, char* argv[])
{
int num1 = 0;
int num2 = 0;
std::thread t1(test01, std::ref(num1), std::ref(num2));//引用传递
std::thread t2(test02, std::ref(num1), std::ref(num2));//引用传递
if (t1.joinable())
{
t1.join();
}
if (t2.joinable())
{
t2.join();
}
//按理说num应该是200000,但是由于线程并发执行,导致结果可能是100000,也可能是200000
std::cout << "run is over"<< std::endl;//死锁,永远不会执行
std::cout << "num1=" << num1 << std::endl;
std::cout << "num2=" << num2 << std::endl;
return 0;
}
运行效果:
陷入死锁

4,死锁解决方法
方法一:要锁谁都锁谁
也就是互斥锁的先后顺序要一致,要都先锁num1就都先锁num1
#include <iostream>
#include <thread>
#include <string>
#include <mutex>
std::mutex mtx1, mtx2;//定义互斥锁
void test01(int& num1,int &num2) //引用传递
{
for (int i = 0; i < 10000; i++)
{
mtx1.lock();//加锁
num1++;
mtx2.lock();//加锁
num2++;
mtx2.unlock();//解锁
mtx1.unlock();//解锁
}
}
void test02(int& num1,int &num2) //值传递
{
for (int i = 0; i < 10000; i++)
{
mtx1.lock();//加锁
num1++;
mtx2.lock();//加锁
num2++;
mtx2.unlock();//解锁
mtx1.unlock();//解锁
}
}
int main(int argc, char* argv[])
{
int num1 = 0;
int num2 = 0;
std::thread t1(test01, std::ref(num1), std::ref(num2));//引用传递
std::thread t2(test02, std::ref(num1), std::ref(num2));//引用传递
if (t1.joinable())
{
t1.join();
}
if (t2.joinable())
{
t2.join();
}
std::cout << "run is over"<< std::endl;
std::cout << "num1=" << num1 << std::endl;
std::cout << "num2=" << num2 << std::endl;
return 0;
}
运行效果:

方法二:使用智能互斥锁
四、智能互斥锁
1,lock_guard
lock_guard会在其构造函数中自动加锁,在其析构函数中自动解锁
无需人为的去加锁解锁操作
std::mutex mtx1;定义互斥锁
std::lock_guard<std::mutex> lock1(mtx1);将互斥锁升级为智能互斥锁,是一个函数模板
#include <iostream>
#include <thread>
#include <string>
#include <mutex>
std::mutex mtx1, mtx2;//定义互斥锁
void test01(int& num1,int &num2) //引用传递
{
for (int i = 0; i < 10000; i++)
{
std::lock_guard<std::mutex> lock1(mtx1);
num1++;
num2++;
}
}
void test02(int& num1,int &num2) //值传递
{
for (int i = 0; i < 10000; i++)
{
std::lock_guard<std::mutex> lock1(mtx1);
num1++;
num2++;
}
}
int main(int argc, char* argv[])
{
int num1 = 0;
int num2 = 0;
std::thread t1(test01, std::ref(num1), std::ref(num2));//引用传递
std::thread t2(test02, std::ref(num1), std::ref(num2));//引用传递
if (t1.joinable())
{
t1.join();
}
if (t2.joinable())
{
t2.join();
}
std::cout << "run is over"<< std::endl;
std::cout << "num1=" << num1 << std::endl;
std::cout << "num2=" << num2 << std::endl;
return 0;
}
运行效果:

2,unique_lock(推荐使用)
lock_guard只支持自动加锁解锁操作
unique_lock不仅仅支持自动加锁解锁操作,还支持超时处理、延迟加锁、达到某些条件后进行加锁等操作
①将unique_lock直接替换lock_guard效果是一样的
自动加锁,自动解锁
#include <iostream>
#include <thread>
#include <string>
#include <mutex>
std::mutex mtx1, mtx2;//定义互斥锁
void test01(int& num1,int &num2) //引用传递
{
for (int i = 0; i < 10000; i++)
{
std::unique_lock<std::mutex> lock1(mtx1);
num1++;
num2++;
}
}
void test02(int& num1,int &num2) //值传递
{
for (int i = 0; i < 10000; i++)
{
std::unique_lock<std::mutex> lock1(mtx1);
num1++;
num2++;
}
}
int main(int argc, char* argv[])
{
int num1 = 0;
int num2 = 0;
std::thread t1(test01, std::ref(num1), std::ref(num2));//引用传递
std::thread t2(test02, std::ref(num1), std::ref(num2));//引用传递
if (t1.joinable())
{
t1.join();
}
if (t2.joinable())
{
t2.join();
}
std::cout << "run is over"<< std::endl;
std::cout << "num1=" << num1 << std::endl;
std::cout << "num2=" << num2 << std::endl;
return 0;
}
运行效果:

②手动上锁
std::unique_lock<std::mutex> lock1(mtx1,std::defer_lock);需要传入参数std::defer_lock
用户需要手动上锁,自动解锁
手动上锁是为了可以使用一些延迟上锁等互斥锁
之前的是常规互斥锁std::mutex mtx1;
例如:手动上锁的时候可以使用时间互斥锁std::timed_mutex mtx1;
std::timed_mutex mtx1;定义时间互斥锁
std::unique_lock<std::timed_mutex> lock1(mtx1, std::defer_lock);定义一个局部锁,使用defer_lock参数,表示不加锁,手动加锁,自动解锁
bool res = lock1.try_lock_for(std::chrono::milliseconds(100));尝试加锁,超时时间为100ms;如果加锁成功,则返回true,否则返回false
五、单例模式下的多线程使用
单例模式:全局只有一个实例,初始化操作只能执行一次
若在多线程中,就有可能被执行多次,此时需要使用call_once
常用的单例模式为日志类,只需要一次实例化对象
Singleton类实现了单例模式。通过std::call_once结合std::once_flag来保证Singleton类的构造函数只被调用一次,从而保证在多线程环境下只有一个Singleton实例被创建。在main函数中,创建了两个线程,这两个线程都调用Singleton::getInstance方法来获取单例实例,并调用showMessage方法。
#include <iostream>
#include <mutex>
#include <thread>
class Singleton {
private:
// 私有构造函数
Singleton() {
std::cout << "Singleton created." << std::endl;
}
static Singleton* instance;
static std::once_flag flag;
public:
// 获取单例实例的方法
static Singleton* getInstance() {
// 确保初始化只进行一次
std::call_once(flag, []() {
instance = new Singleton();
});
return instance;
}
void showMessage() {
std::cout << "Singleton is working." << std::endl;
}
};
// 静态成员变量初始化
Singleton* Singleton::instance = nullptr;
std::once_flag Singleton::flag;
// 线程函数
void threadFunction() {
Singleton* single = Singleton::getInstance();
single->showMessage();
}
int main() {
std::thread t1(threadFunction);
std::thread t2(threadFunction);
t1.join();
t2.join();
return 0;
}
六、条件变量的使用
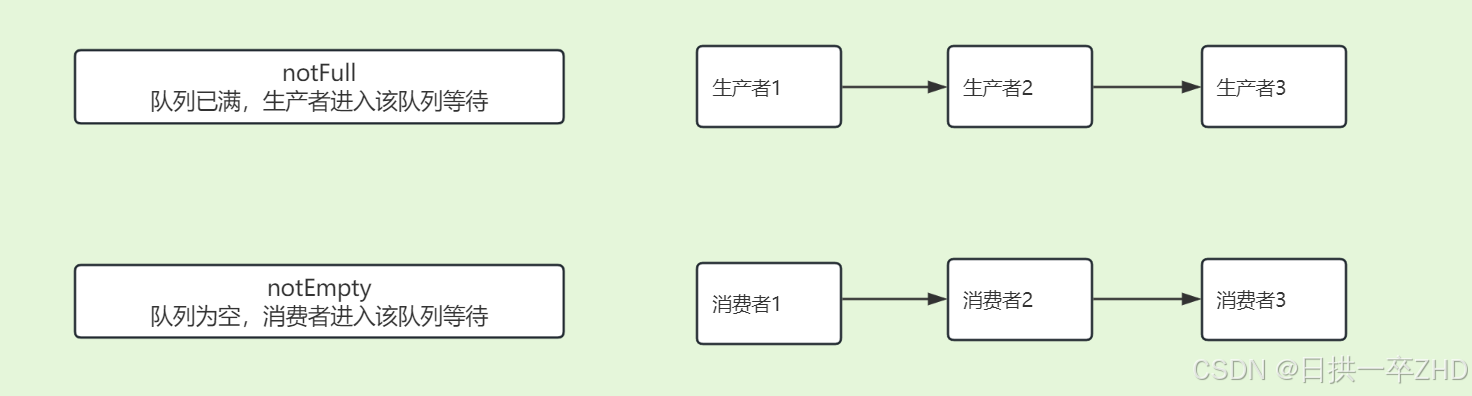
生产者与消费者模型:
生产者(导师),消费者(导师的学生)
一个导师一般情况下会招多个学生,导师申请到国家基金或横向课题,将课题任务分成多个小块,依次分配给学生A、学生B、学生C等进行完成
导师将任务放到任务队列中,学生从任务队列中取出任务并完成,若任务队列中没有任务了,学生就可以等待一会儿(摸会儿鱼)。等导师又有新任务了,放入到任务队列中,并通知学生;学生收到通知,就不需要再等待了,开始去任务队列中取任务。
导师往任务队列中加入一个任务,因为是一个任务,所以只通知一次(notify_once),至于哪个学生去完成,导师不关心,但需要一个学生来进行完成;
导师往任务队列中加入了很多个任务,因为任务比较多,需要所有的学生进行完成(notify_all),把所有的学生都通知一遍。
极端例子,任务队列为空,导师放任务到任务队列的同时,学生来任务队列中取任务,学生发现任务队列中没任务,开始摸鱼,其实导师已经放入了一个任务
此时就需要加锁,并引入条件变量,导师往任务队列中放任务的时候加锁,放完之后发通知
学生从任务队列中取任务之前先判断任务队列中是否为空,若为空等待,直到收到导师发的通知之后再开始从任务队列中取任务
g_cv.wait(lock, bool);
参数一:互斥锁
参数二:布尔值,若为true则执行下一行,若为false则等待
一般这个bool值用lambda表达式设置
#include <iostream>
#include <mutex>
#include <thread>
#include <condition_variable>//引入条件变量头文件
#include <queue>//任务对列头文件
std::queue<int> g_task_queue; //任务队列 导师将任务放到任务队列中,队列,先进先出,导师先放入的任务,学生先完成
std::condition_variable g_cv; //创建一个条件变量
std::mutex g_mutex; //创建一个互斥锁
void Teacher()//导师(生产者),负责产生任务,并通知学生
{
for (int i = 0; i < 10; i++) //导师将10个任务放入任务队列中
{
std::unique_lock<std::mutex> lock(g_mutex); //获取互斥锁
g_task_queue.push(i); //将任务放入队列
g_cv.notify_one();//通知学生,来一个学生完成这个任务
//g_cv.notify_all();//通知所有学生完成这个任务
std::cout << "Teacher produce task " << i << std::endl; //打印提示信息
}
//导师放任务到任务队列的速度别太快,睡个100ms
std::this_thread::sleep_for(std::chrono::milliseconds(100)); //等待100ms,模拟学生完成任务
}
void Students()//学生(消费者),负责消费任务,并等待通知
{
while (true) //学生一直等待通知
{
std::unique_lock<std::mutex> lock(g_mutex); //获取互斥锁
//等待通知,若队列为空,则阻塞等待
bool is_empty = g_task_queue.empty();//判断队列是否为空
//lambda表达式为ture,执行下一行;false,阻塞等待,直到条件变量调用notify_one来唤醒线程,该等待结束
g_cv.wait(lock, []()
{
return !g_task_queue.empty(); //队列不为空,则返回true,通知学生
}); //等待通知,若队列为空,则阻塞等待
int task; //定义一个任务变量
task = g_task_queue.front(); //取出队列头部的任务
g_task_queue.pop(); //从队列中删除任务
std::cout << "Student consume task " << task << std::endl; //打印提示信息
}
}
int main(int argc, char* argv[])
{
std::thread t1(Teacher); //创建导师线程
std::thread t2(Students); //创建学生线程
if (t1.joinable())
{
t1.join(); //等待导师线程结束
}
if (t2.joinable())
{
t2.join(); //等待学生线程结束
}
return 0;
}

七、跨平台线程池

现准备好线程池,包括线程数组和任务队列,等待用户放任务到任务队列中,现场数组分配线程去任务队列中取任务完成
#include <iostream>
#include <mutex>
#include <thread>
#include <condition_variable>//引入条件变量头文件
#include <queue>//任务对列头文件
#include <vector>
#include <functional>//引入函数对象头文件
class ThreadPool
{
public:
ThreadPool(int num_threads) :m_stop(false)
{
//往线程数组中添加num_threads个线程
for (int i = 0; i < num_threads; ++i)
{
// push_back()函数向线程数组中添加一个线程的时候会进行一个拷贝,因此这里使用emplace_back()函数,直接调用成员构造函数,避免拷贝
// 比push_back()函数效率高,更加节省资源,避免了构造函数的调用
m_threads.emplace_back([this]()
{
while (true)
{
std::unique_lock<std::mutex> lock(m_mutex);//加锁
//条件变量等待,直到有任务需要处理
m_cv.wait(lock, [this]()
{
//如果线程池需要停止,或者任务对列为空,则返回false,通知线程等待
//否则返回true,通知线程继续执行下一行代码
return m_stop ||!m_tasks.empty();
});
//如果线程池需要停止,并且任务对列为空,则退出线程
if (m_stop && m_tasks.empty())
{
return;
}
//线程池没有停止,任务对列不为空,则取出一个任务
std::function<void()> task = m_tasks.front();//取出任务列表中的第一个任务
m_tasks.pop();//取出任务列表中的第一个任务
//取到任务之后解锁,让其他线程有机会去取任务
lock.unlock();//解锁
task();//执行任务
}
});
}
}
~ThreadPool()
{
//指定锁的作用域
{
std::unique_lock<std::mutex> lock(m_mutex);//加锁
//因为m_stop是多个线程共享的,所以在析构函数中需要加锁,确保线程安全
m_stop = true;//设置线程池停止标志
}
m_cv.notify_all();//通知所有线程,线程池需要停止
for (std::thread &t: m_threads)
{
if (t.joinable())//如果线程还没有结束,则等待线程结束
{
t.join();
}
}
}
//向任务对列中添加任务
template<typename F, typename... Args>//函数模板,可变参数模板
void enqueue(F&& f, Args&&... args)
{
//&& 右值引用,可以避免拷贝,提高效率
//& 左值引用,可以传引用,避免拷贝,提高效率
//在函数模板里面,&& 表示万能引用(在函数模板中,&& 右值引用就是万能引用)
//std::forward<F>(f) 转发函数对象,避免拷贝,提高效率
std::function<void()> task = std::bind(std::forward<F>(f), std::forward<Args>(args)...);//使用bind函数,将任务封装成函数对象
//对共享变量操作需要加锁,确保线程安全,指定锁的作用域
{
std::unique_lock<std::mutex> lock(m_mutex);
m_tasks.emplace(std::move(task));//向任务对列中添加任务
}
//通知线程数组中的一个线程去取任务
m_cv.notify_one();
}
private:
std::vector<std::thread> m_threads;//线程数组
std::queue<std::function<void()>> m_tasks;//任务对列
std::mutex m_mutex;//互斥锁
//生产者生产任务,去通知线程数组,线程数组去指派线程去完成任务
std::condition_variable m_cv;//条件变量 线程池符合生产者消费者模型,故需要条件变量;
bool m_stop = false;//线程池是否停止
};
int main(int argc, char* argv[])
{
//10个任务(0-9),由3个线程去完成
ThreadPool pool(3);//创建线程池,线程数为3
//向任务对列中添加任务
for (int i = 0; i < 10; ++i)
{
pool.enqueue([i]()
{
std::cout << "Task " << i << " running on thread " << std::this_thread::get_id() << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));//休眠1秒,模拟任务执行时间
std::cout << "Task " << i << " finished on thread " << std::this_thread::get_id() << std::endl;
});
}
return 0;
}
运行效果:

八、异步并发
1,async
无需手动去创建线程,当运行到std::future<int> f1 = std::async(std::launch::async, func);时,自动会有个异步线程去调用func函数,同时开启一个线程立马执行,通过f1.get()取到函数返回的结果
#include <iostream>
#include <future>
int func()
{
int num = 0;
for (int i = 0; i < 10000; i++)
{
num++;
}
return num;
}
int main(int argc, char* argv[])
{
//主线程和子线程同步,只不过主线程执行完func函数后,会直接输出结果
//子线程执行完func函数后,会将结果存入f中,主线程通过f.get()获取结果
//子线程执行func函数
std::future<int> f1 = std::async(std::launch::async, func);//执行到这行代码时,func函数已经开始执行,但是并不等待func函数的结果,而是返回一个future对象,通过这个future对象可以获取func函数的结果
std::cout << "main thread result:" << func() << std::endl;//主线程执行func函数,并打印结果
//以上两者是同时执行的,主线程和子线程同步
std::cout<< "async result:" << f1.get() << std::endl;//会将return的结果存放到f1中,通过f1.get()获取结果
return 0;
}
运行效果:

2,future
async会立马自动调用线程执行,而future需要手动创建线程执行
std::packaged_task<int()> task(func);创建packaged_task对象task,包装func函数
std::future<int> f = task.get_future();创建future对象f,用于获取func函数的结果
std::thread t(std::move(task));将task的控制权移交给t线程,t线程负责执行task函数,并将结果存入f中
#include <iostream>
#include <future>
int func()
{
int num = 0;
for (int i = 0; i < 10000; i++)
{
num++;
}
return num;
}
int main(int argc, char* argv[])
{
std::packaged_task<int()> task(func);//创建task对象,包装func函数
std::future<int> f = task.get_future();//创建future对象f,用于获取func函数的结果
std::thread t(std::move(task));//将task的控制权移交给t线程,t线程负责执行task函数,并将结果存入f中;子线程t执行func函数,与主线程同步
std::cout << "main thread result:" << func() << std::endl;//主线程执行func函数,并打印结果
if (t.joinable())
{
t.join();//等待子线程t线程结束
}
std::cout << "packaged_task result:" << f.get() << std::endl;//获取f中存放的func函数的结果
return 0;
}
运行效果:

3,promise
场景:在主线程中获取子线程中通过promise所设置的值
#include <iostream>
#include <future>
void func(std::promise<int>& prom)
{
prom.set_value(42);//设置promise的值
}
int main(int argc, char* argv[])
{
std::promise<int> prom;//声明一个promise对象
std::future<int> fut = prom.get_future();//promise对象会返回一个future对象,用于获取promise的值
std::thread t(func, std::ref(prom));启动一个线程,并传入promise对象作为参数
if (t.joinable())
{
t.join();
}
std::cout << fut.get() << std::endl;//获取得到promise所设置的值
return 0;
}
运行效果:

九、原子操作
atomic原子操作是一个模板类,用于在多线程中访问和修改共享变量,避免多线程中所出现的数据竞争现象的发生
原子操作和锁所处理的都是同一类问题
把变量设置为atomc类型,该变量自身自带线程安全操作,会自动加锁和解锁,且要比手动加锁解锁的速度更快
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<int> g_num_atomic = 0;//原子变量
int g_num = 0;//非原子变量
void func()
{
for (int i = 0; i < 1000000; ++i)
{
g_num_atomic++;
g_num++;
}
}
int main(int argc, char* argv[])
{
std::thread t1(func);
std::thread t2(func);
if (t1.joinable()) t1.join();
if (t2.joinable()) t2.join();
std::cout << "g_num = " << g_num << std::endl;//输出非原子变量的值,因为g_num是非原子变量,所以可能出现数据竞争,导致结果不准确
std::cout << "g_num_atomic = " << g_num_atomic << std::endl;//输出原子变量的值
return 0;
}
运行效果:
全局变量g_num是一个int,由于是多线程操作,故出现了数据竞争问题,导致数据不对
全局变量g_num_atomic是一个int型的原子变量,该变量会自动加锁和解锁,不会发生数据竞争问题

学习笔记参考来源:陈子青——C++11 多线程编程-小白零基础到手撕线程池
若有侵权联系立删