下一代 AI 搜索:多智能体 + 系统2,解决 AI 搜索在复杂信息性能下降问题
- AI 搜索:从搜索引擎到答案引擎
- ① AI 搜索市场现状(可跳过)
- ② 巨好用的 AI 工具推荐
- 程序员的垂直搜索引擎 devv.ai
- ③ 多智能体 + 系统2,实现下一代 AI 搜索(模拟人类认知过程的 ai 搜索引擎)
- 构建你自己的 AI 搜索引擎(Perplexity.ai 版本)
- 下一代 AI 搜索 设计思路
- 构建你自己的 AI 搜索引擎(MindSearch 版本)
- ④ AI 医疗搜索 设计思路
- 内科医生的局限
- 医疗搜索设计思路,怎么保证可靠性?
- 嘘,别人我不告诉 TA !!!
本文金手指:
- 怎么落地一款媲美付费 AI 搜索的产品?
- 医疗搜索、下一代 AI 搜索的创新思路?
- 怎么用 AI 读论文,几个提示词就读完?
- 怎么用大模型实现深度思考?让 AI 自己破解新知识!
AI 搜索:从搜索引擎到答案引擎
在当今信息爆炸的时代,你是否曾感到迷茫,面对海量数据却难以找到准确答案?
想象一下,如果有这样一个工具,它能够洞悉你的每一个搜索需求,将复杂问题迎刃而解,那将是多么令人惊喜的一件事。
传统的搜索工具不能深刻理解用户的需求,但 AI 搜索却能。
它不仅降低了对用户搜索技巧的高要求,更是将那些繁琐的步骤——翻阅几十个网页、自行筛选有效信息、自行归纳总结的麻烦,统统交给了AI助手。
传统搜索通过关键词搜索,只有你很有经验的时候,你去搜索才能得到最相关的结果,这很反搜索,因为你是不了解一个东西,你才去搜索的。
所以,我们搜索习惯带问题的语义搜索(找找反应底层小人物生活不堪的电影影评?、SpaceX迄今为止重复发射次数最多的火箭是那个,发射了多少次数?),AI 搜索直接让你语义搜索,就能找到最相关的答案。
传统搜索引擎,只给你 — 信息罗列。
AI 搜索优势:
- 符合搜索习惯,带问题的语义搜索(高水平的调研,不需要搜索技巧、精通各种语言、筛选日期远近,解决传统搜索难以处理的模糊、复杂的问题)
- 会把搜索的信息整理成,正面回应问题的准确答案(不用翻完所有相关链接,不用自己对比、总结归纳)
- 会附上所参考的具体网页、文献,同时已思维导图展示(资料有来源,可信)
- 会在答案后面,添加一组横向扩展、纵向深入的一组相关问题,方便追问和打开思路(启发思路很惊艳,好问题比答案值钱)
- 目前没有广告,传统搜索引擎近乎走到了搜索的反面,打开某度搜索,前面都是广告
- …
黄仁勋:我几乎每天都在用 Perplexity.ai (国外最火 AI 搜索)
Azeem Azhar:如果必须选择一个,我不会选 GPT、Claude、谷歌搜索,而是 Perplexity.ai。
① AI 搜索市场现状(可跳过)
微软:New Bing 的改造
- 技术引入:23年2月,微软将LLM技术应用于Bing和Edge搜索引擎,增强了复杂查询处理能力,提供了交互对话功能。
- 多模态搜索:引入OpenAI的Dell-E模型,实现视觉搜索和相关问题解答。
- 产品升级:Bing Chat更名为Microsoft Copilot,页面布局更新,增强了AI生成搜索结果和相关问题预测。
- 技术结合:结合大型和小型语言模型,优化搜索结果生成,满足用户查询意图。
谷歌:基于Gemini模型的AI搜索服务
- AI Overview服务:今年5月推出,允许简化语言搜索和调整搜索结果概述。
- 技术协同:Gemini模型与谷歌现有搜索系统结合,包括质量和排名系统,以及知识图谱。
- 质量与安全:尽管有详细的质量控制措施,AI Overview仍面临准确性问题。
OpenAI:SearchGPT搜索产品
- 产品演示:SearchGPT提供最新信息的快速回答和视觉答案功能。
- 技术支持:由GPT-4系列模型支持,计划集成到ChatGPT中,独立于生成式AI训练。
- 技术推测:可能采用检索增强生成方法,降低幻觉率,支持图片识别。
Perplexity:生成式AI搜索引擎
- 产品定位:被称为“答案引擎”,所有答案都有来源支持。
- 技术依赖:基于市面主流模型,Perplexity AI的思路是先产品后模型。
- 工作原理:结合传统搜索和大语言模型,生成格式良好的答案并附上引用。
浏览器插件:基于自研大模型技术
- 月之暗面:推出Kimi浏览器插件,具备点问笔和总结器功能,处理长文本数据。
- 字节跳动:AI助手豆包提供浏览器插件,具备网页视频总结、写作和文本修改功能。
- 其他插件:包括基于GPT、Claude等模型的“套壳”插件,提供搜索、写作、总结、翻译功能。
- Elmo插件:支持端侧模型,即使断网也能使用,具备多种文本处理功能。
我们可以看到AI搜索市场正朝着更加智能化、个性化和多模态化的方向发展,同时各大公司也在不断探索和优化自己的技术和产品,以满足用户的需求并保持市场竞争力。
成本分析:
传统搜索,如谷歌搜索一次的成本是 0.2 美分(0.014人民币)。
AI 搜索,如果用闭源模型的 Token 计费就贵了,具体看 Token。
现在 AI 搜索都是用开源模型,或者自家练的大模型,主要是成本就是推理成本。
- 自己的大模型,4000亿参数(400B)是 盈亏持平的极限,越上,用户越多,越亏损
- 最好控制在 1000亿(100B)以下,才能自己造血
之前 Perplexity 也有用 GPT4,但发现只要一个用户每月提问超过 20 次,就亏本了,立马退回 3.5。
Perplexity并不提供直接的搜索能力,而是获取了谷歌搜索引擎检索的内容之后,再通过大模型将答案进行总结,最终整理成固定的格式呈现给用户,帮用户省去了逐页查看和总结的时间。
如果谷歌觉得,自己被白嫖了,而且还对自己主营业务造成很大损失,采取对 AI 搜索收费,那 AI 搜索的成本就会显著提升。
最后 AI 搜索没有哪家能做过谷歌,AI 搜索只适合有自己垂直内容的平台。
② 巨好用的 AI 工具推荐
秘塔 搜索:很牛逼的搜索神器
秘塔官网:https://metaso.cn/(免费使用)
我主要用于找论文,不像以前只能模糊搜索,然后一篇篇找是不是,免去 99.99% 无用功。

AI 搜索,我比较喜欢秘塔,因为其他 AI 搜索可能会给出错误的回答。
- AI 搜索测评对比:秘塔 AI 搜索:颠覆搜索的常态体验,强大+惊艳
- 秘塔效果好,除了使用 搜索引擎的 API,还花了巨资,对播客、文库建立了自己的索引库
Kimi :读论文神器
链接:https://kimi.moonshot.cn/
Kimi 的论文理解能力,我自己用感觉比 GPT4 强多了。
我将一些复杂的英文论文输入Kimi,它不仅能够理解论文的主旨,还能捕捉到所有细微的逻辑关系和专业术语。
- 长文档输入,可以直接扔一本书
- 还能做到把里面所有的逻辑细节,都讲清楚
- 每次回答后,都会推荐下一步的问题,很多问题开发我的思路,是我完全想不到的
- 对各种提示词,遵守和回答的比 GPT4 好
- 中文输出比 GPT4 强,如果是翻译,会符合中文习惯的意译
- 我输入的提示词很复杂,GPT4理解好,但ta输出格式不咋地,Kimi指令遵循和上下文好的一匹
但 Kimi 不适合写论文,比如给的参考文献,大部分都是胡编乱造的。
- 第一次胡编乱造,我更正后,ta突然从自己的训练数据中调出正确参考 — 我直接懵了,你训练数据有,为啥不给,还要自己造
Kimi 最大优势就是读论文,好到居然能把所有的逻辑细节都说清楚。
为了能精读好论文,我写了一个配套的提示词,确保你能完全看懂每一篇论文:
- 让 Kimi 思考提示词:https://blog.csdn.net/qq_41739364/article/details/141409380
- 希望深入全面的理解,同时花的时间最少,半小时就能读完并写完一篇论文,而不是要读一个礼拜。
你用的提示词越多,你对这篇的论文理解程度就越深,比如使用:
- 让 Kimi 逐字中文意译
- 让 Kimi 画出论文大纲
- 让 Kimi 做解法的拆解
- 让 Kimi 做全流程分析
- 让 Kimi 寻找创新点
- 让 Kimi 根据你的理解提问,给你提供最直接的反馈,你听不懂还可以要求举例子、类比对比、按流程拆解
- 让 Kimi 推荐下一步问题(Kimi 会自动推荐)
- …
Kimi 读论文的局限
学习到底在学什么?
模型类型:
-
关键字提取:凝练语言,三庭五眼,简单压缩,四字归纳
-
经验技巧型:深入思考,唇亡齿寒,痛苦后反思获得
-
方法流程型:套路提炼,分析方法,不断追问获得
-
学科原理型:科学验证,能量守恒,重要理论获得
-
哲学视角型:思维方式,演化思维,思考思路获得
像 经验技巧型 大模型学不到的,只能跟大佬学习、或者自己的问题+反思。
一键尽揽所有搜索结果:https://seekall.ai/zh/index.html
程序员的垂直搜索引擎 devv.ai
链接:https://devv.ai/zh(需梯子)
Dewey:AI 论文搜索神器
链接:https://x.com/itsandrewgao/status/1814105998128558216(需梯子)
该工具可以帮助科研人员回答以下问题:
🤔 谁也在做这个研究?
🤔 我的研究是否具有原创性?
🤔 有哪些类似的研究方法?
🤔 该领域还有哪些研究方向?
Dewey 的嵌入式搜索功能可以帮助科研人员快速找到更多相关的论文,从而提高科研效率。
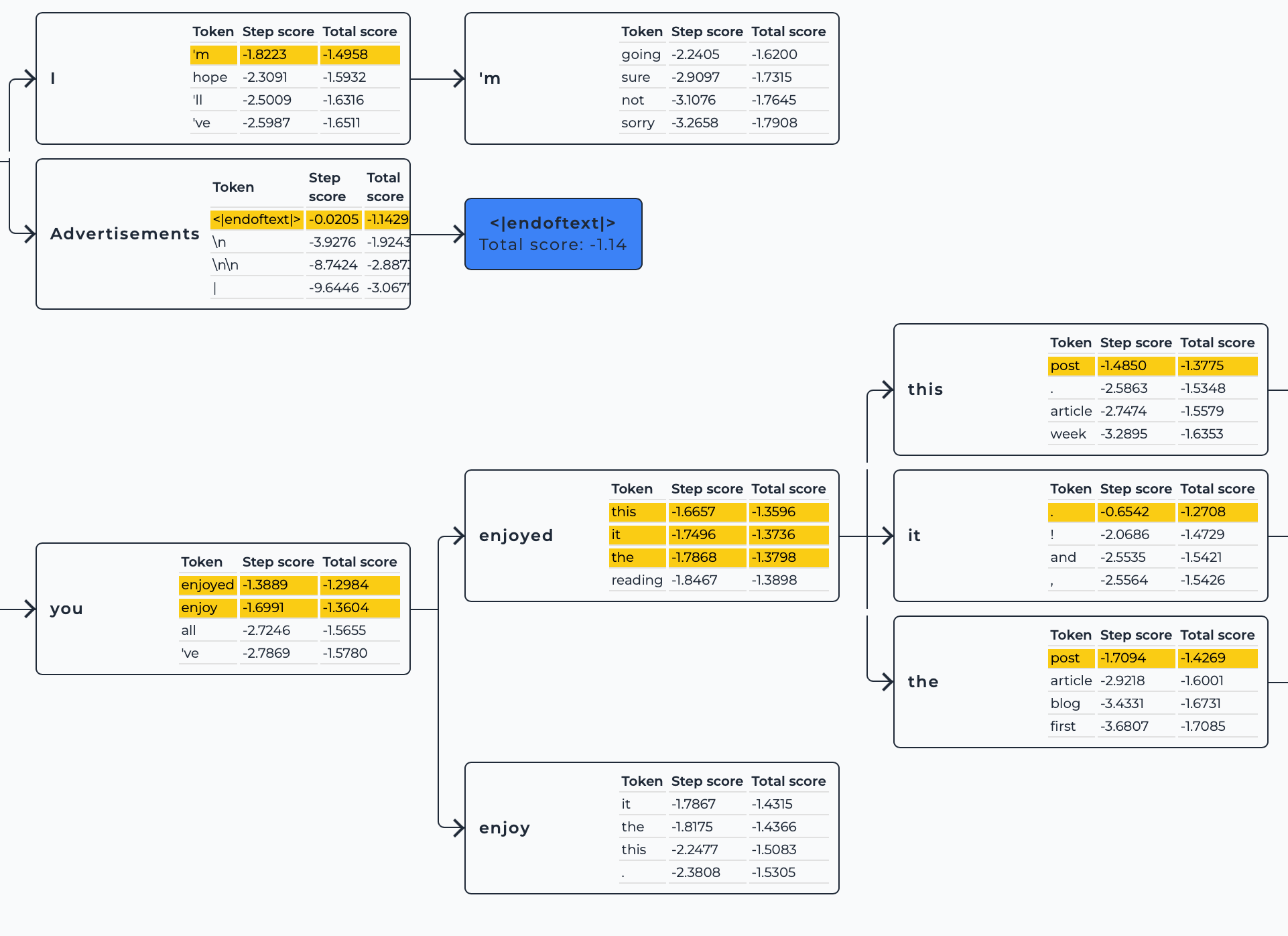
③ 多智能体 + 系统2,实现下一代 AI 搜索(模拟人类认知过程的 ai 搜索引擎)
构建你自己的 AI 搜索引擎(Perplexity.ai 版本)
Perplexity.ai 实现思路:
-
Query意图理解:首先需要对用户的查询进行分析,这包括去除常见的停用词(的、和、是)、识别查询中的实体(如人名、地点等)、提取关键词以及进行文本归一化(统一小写、词干提取或词形还原,以及标准化日期、数字等),确保查询的准确性和一致性。
-
Query扩展:通过扩展原始查询,生成多个子查询(subquery),这样做可以增加搜索的覆盖面,提高检索结果的多样性和全面性。
-
并发检索:使用并发技术同时对多个子查询进行检索,可以提高检索效率,快速返回结果。
-
粗排与精排:在检索结果返回后,通常需要进行排序。粗排是初步筛选,快速剔除明显不相关的结果;精排则是更细致的排序,根据相关性、权威性等因素对结果进行排序。
-
文档追加与总结回答:将筛选后的网页文档追加到prompt中,利用大型语言模型进行阅读和理解,然后生成总结性的回答,并提供相应的链接。
代码:https://github.com/Yusuke710/nanoPerplexityAI/
一个开源的实现,模仿了perplexity.ai。
这个项目没有复杂的图形用户界面(GUI)或语言模型代理,仅仅是大约100行Python代码。
- 安装必要的库:
pip install googlesearch-python requests beautifulsoup4 lxml openai
- 设置你的 OpenAI API 密钥:
export OPENAI_API_KEY=<Your OpenAI API KEY>
- 运行脚本:
python nanoPerplexityAI.py
脚本会提示你输入问题,然后生成答案并保存在 <query>.md 文件中。
下一代 AI 搜索 设计思路
论文:https://arxiv.org/pdf/2407.20183(有开源代码)

MindSearch 解决在 AI 复杂搜索任务中,Perplexity.ai 性能下降问题。
综合性能超过 Perplexity.ai Pro 版本,以及带有搜索插件的 ChatGPT。
详细分析:下一代 AI 搜索引擎 MindSearch:多智能体 + 系统2,模拟人类认知过程的 AI 搜索引擎
综合来看,核心在于 计划 部分,模拟人类的计划过程,这种方式不仅可以用于搜索 Agent,还可以迁移到其他 Agent。
构建你自己的 AI 搜索引擎(MindSearch 版本)
代码:https://github.com/InternLM/MindSearch(上周开源)
步骤1:依赖安装
pip install -r requirements.txt
步骤2:设置MindSearch API
设置FastAPI服务器。
python -m mindsearch.app --lang en --model_format internlm_server
--lang: 模型的语言,en代表英文,zh代表中文。
--model_format: 模型的格式。
步骤3:设置MindSearch前端
提供以下前端界面:React
安装Node.js和npm
对于Ubuntu
sudo apt install nodejs npm
对于Windows
从Node.js — 下载 Node.js®下载
安装依赖
cd frontend/React
npm install
npm start
Gradio
python frontend/mindsearch_gradio.py
Streamlit
streamlit run frontend/mindsearch_streamlit.py
本地调试
python -m mindsearch.terminal
AI 视频搜索 RAG:https://twitter.com/LangChainAI/status/1822431990039077308
④ AI 医疗搜索 设计思路
AI 搜索的神奇之处,更偏需求
Perplexity 很火,但 ta 用的只是 GPT 3.5,为了节省成本,如果是用 GPT4,只有一个用户每个月提问 20 次以上,ta 就会亏本。
- 技术上,并没有很大变革,甚至为成本智能程度还倒退了
- 但把【搜索引擎】变成【答案引擎】(更傻瓜化),更接近需求,顾客就觉得比 GPT4 好用
- 直接就能回答复杂问题,不需要用户想来想去(每个关键词都搜索),翻来翻去(每篇都读)
然后他们还想到新的赚钱方法,把【相关问题】变成广告位。

因为我是医疗行业,我看到任何好东西,我都想迁移到医疗行业。
内科医生的局限
我一直以为,医生是越老越有经验,治疗效果越好。
结果据统计,内科医生年龄越大,他的病人的死亡率就越高,外科则相反。
知识要越新越好,技能要越熟练越好。
内科医生负责诊断和开药,他们给病人提供综合治理;外科医生负责手术和手术相关的护理事物。
年龄越大,对于探索新知的渴望和能力逐渐减弱,这种趋势在医学界尤为显著,因为医学是一个不断进步和发展的领域。
对内科来说,最新知识比传统经验更有用。
高精度医学大模型引入 AI 医疗搜索,不是这个医生在给你看病,而是医学界的「当前科学理解」在给你看病。
医疗搜索设计思路,怎么保证可靠性?
我们就可以改进 MindSearch,往 AI 医疗上迁移:
- 比如设置权重,越是权威的医学期刊,权重就越高
因为网络上医疗健康的信息,绝大多数都不靠谱,患者的烦恼不是信息太少了,而是信息太多了,必须判断信息的可靠性。
学术论文是最过硬的参考文献,因为学术界说话非常负责任。
论文里就算是有争议的地方也会明白地讨论,让你知道这个问题目前还有争议 —— 而不会各说各话。
- 比如交叉验证,对最关键的信息,给至少俩个不同的来源,甚至从反面考虑,假设这个信息不对,我怎么推翻ta?
AI 搜索适合做这个事情,因为 AI 以问题为核心,ta 在调研过程中的每一步都知道自己在做什么,出报告的时候也知道自己在说什么。
- 比如情境化,我们不能只调研到直接的答案,还要调研周边的情境。
在AI医疗搜索中,情境化意味着除了寻找直接的治疗方案外,还需评估与该方案相关的多个维度,包括患者个体差异、疾病阶段、治疗的潜在风险与益处、成本效益分析、患者偏好、社会文化背景、医疗资源可用性、最新医学研究、统计数据、患者相似案例、以及政策和法规等,以确保治疗方案的全面性和适用性。
在AI医疗搜索领域,情境化意味着不仅要关注直接的治疗方案,还需要综合考虑与治疗相关的各种因素,以获得更全面和深入的理解。
这包括:
- 治疗方案的适用性:评估该治疗方案适用于哪些特定类型的患者(如年龄、性别、疾病阶段等)。
- 治疗效果的背景对比:了解该治疗方案的效果如何,与其他可用的治疗方法相比如何,包括治愈率、缓解症状的速度、副作用等。
- 科学证据和临床试验:考虑支持该治疗方案的科学研究和临床试验数据,这些数据的质量和可靠性如何。
- 患者的反馈和经历:收集实际使用该治疗方案的患者的反馈,了解他们的治疗经验和满意度。
- 成本效益分析:分析治疗方案的成本效益,包括治疗费用、所需时间以及可能的长期健康效益。
- 法规和政策环境:了解相关的法律法规和政策背景,这些因素可能影响治疗方案的实施和患者的接受程度。
通过情境化这些相关的信息,可以更全面地评估AI医疗搜索得到的治疗方案的适用性和有效性,帮助医疗专业人员和患者做出更好的治疗决策。
具体实现,我们可以在 MindSearch 版本上,加上这些设计。
各位大佬可以精细分析,怎么把这些设计转换为具体实现!
嘘,别人我不告诉 TA !!!
被绿的时候我忍气吞声!!!
被甩的时候我一言不发!!!
被渣的时候我不为所动!!!
但看见关注我泪如泉涌!!!

文字看累了,看美女放松一下,顺便点个关注!!!
因为这里是连续剧,后面还有更多美女和干货!!!
我要让高难度知识落地!!!
我要让高精尖科学流传!!!
我要在高逼格的干货上!!!
我要给出最有用的心得!!!
和全球顶级科学家同步!!!