- 论文题目:PointCAT:Cross-Attention Transformer for Point Cloud
- 通讯地址:南京理工大学
- 代码地址:https://github.com/xincheng-yang/PointCAT

- . PointCAT架构:PointCAT提出了一种基于交叉注意力机制的Transformer网络,专门用于点云表示。它通过两个不同的多尺度特征分支,利用交叉注意力机制来交换信息。通过这种方式,模型能够有效捕获点云中的长程依赖和多层次特征。
- . 计算效率优化:为了降低模型的计算复杂度,PointCAT只使用一个分支的单类token作为查询,计算与另一个分支的注意力图,从而减少多分支结构带来的计算开销。
- 实验结果:通过广泛的实验,论文证明了PointCAT在形状分类、部分分割和语义分割任务上取得了优异或可比的性能。模型在ModelNet40、ShapeNetPart和S3DIS等数据集上表现良好,尤其是在分类任务中取得了93.5%的整体精度。
- 创新点:
- 提出了一个高效的层次结构,用于提取3D点云中的多尺度特征。
- 基于这种结构,设计了一种双分支交叉注意力Transformer架构,结合了位置和内容特征,适用于点云学习任务。
- 实验表明,PointCAT在多个任务上都能提供更加精确和可区分的特征表示。
PointCAT 核心思想
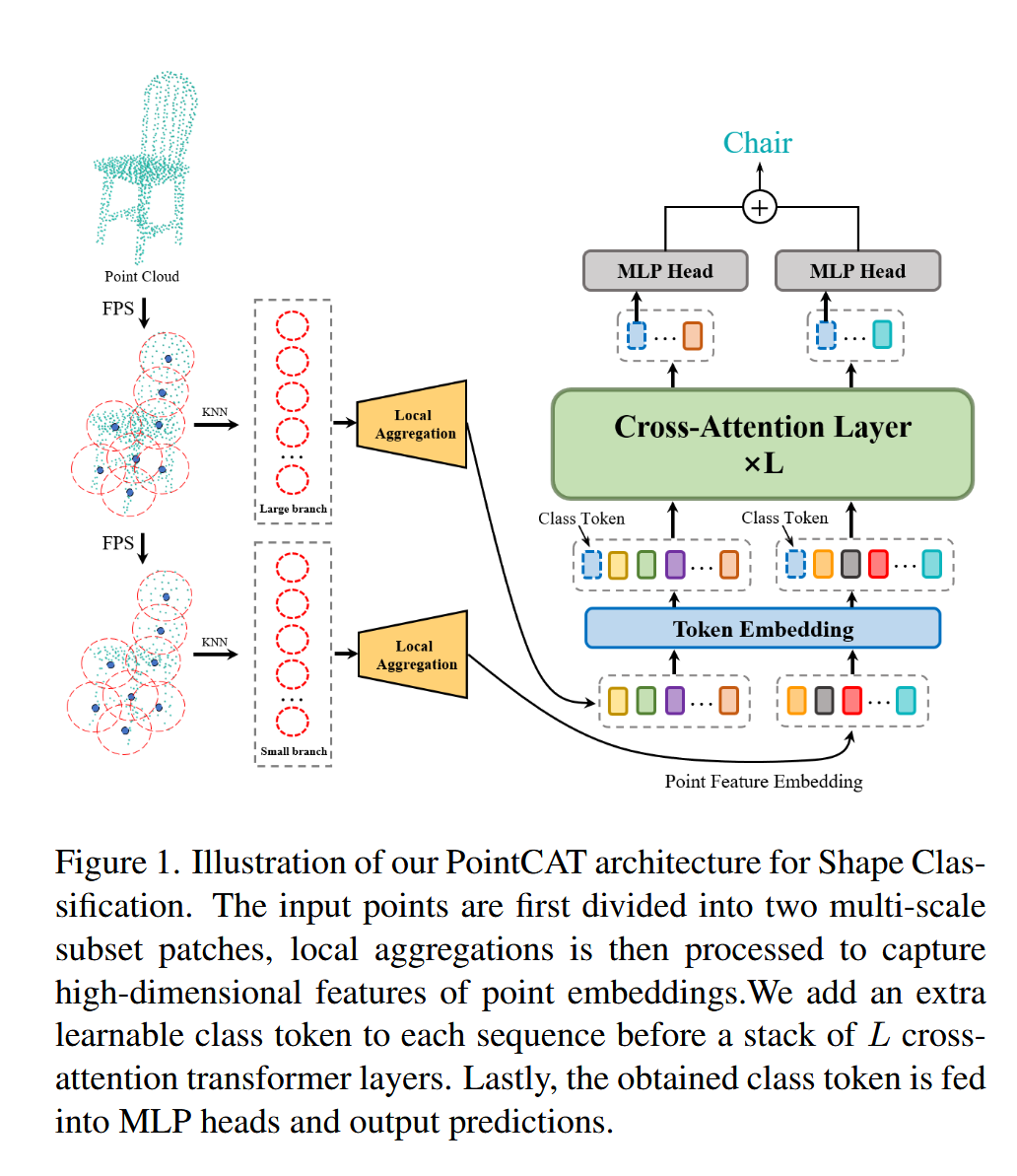
图 1. 用于形状分类的 PointCAT 架构图示。输入点首先被分为两个多尺度子集补丁,然后处理局部聚合以捕获点嵌入的高维特征。我们在 L 个交叉注意力变换层的堆栈之前向每个序列添加一个额外的可学习类标记。最后,将获得的类别标记输入 MLP 头并输出预测。
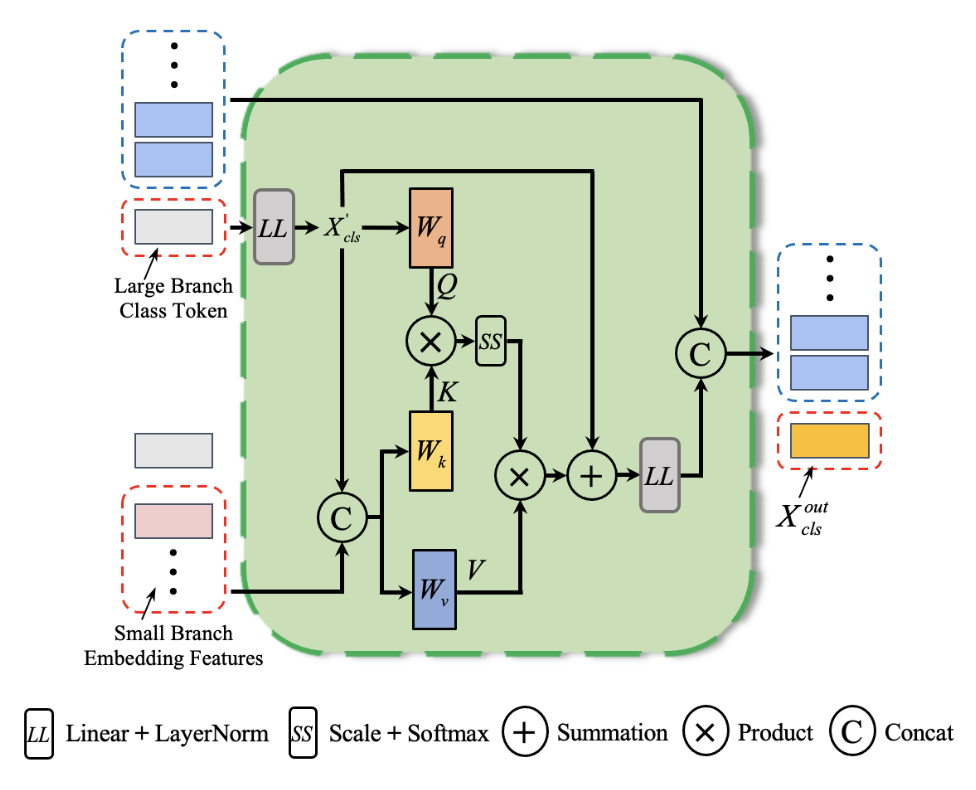
图 2. 大点分支的交叉注意力层。大分支的xcls被投影到小分支的特征维度,并作为交叉注意力的Query来与小分支的嵌入特征标记生成的Key和Value进行交互。我们通过另一个使用 Layernorm 的线性投影将尺寸对齐回大分支。最终,我们将处理后的类标记与原始补丁标记连接起来。
PointCAT的核心思想是通过 双分支跨注意力机制(Cross-Attention Mechanism) 来有效处理三维点云数据,克服其不规则和无序的特点,进而捕捉点云中的 长程依赖性 和 多尺度特征。具体来说,PointCAT的核心理念包括以下几个关键点:
- 双分支架构:
- PointCAT引入了两个独立的Transformer分支,每个分支处理不同尺度的点云特征。这两个分支分别聚合局部和全局的几何信息,能够捕捉到点云在不同层级上的细节和全局结构。
- 跨注意力层:
- 跨注意力机制是该模型的核心创新之一。它允许两个分支之间的信息交互,即通过一个分支的特征作为查询,另一个分支的特征作为键和值,从而实现信息的互换和融合。这样既能保持局部特征的独立性,又能增强全局特征的表达能力。
- 层次结构与计算效率:
- 为了避免由于多分支结构带来的计算负担,PointCAT设计了一个高效的层次结构。这种设计通过对点云进行分组和降采样,减少了需要处理的点的数量,同时保持了模型的计算效率和表达能力。
- 位置和内容特征结合:
- 在跨注意力机制中,PointCAT不仅处理点云的位置信息,还处理点之间的内容特征。这使得模型可以更加准确地理解点云的空间布局和几何关系,提升了点云表示的精度。
通过这种双分支跨注意力架构,PointCAT能够有效地捕捉点云中的长距离依赖关系和多尺度信息,并且能够在形状分类、部件分割和语义分割等任务中实现高效且准确的表现。
核心代码实现讲解
它的核心思想是通过 跨注意力机制(Cross-Attention Mechanism) 来融合多尺度特征,从而高效地捕捉点云数据中的局部和全局几何信息。这种机制能在点云分类或分割任务中取得较好的性能表现。
1. 模型架构 (PointCAT 类)
PointCAT 类是 PointCATCross 的主体结构,负责将点云数据输入网络,并输出分类结果。主要组成部分包括:
- 嵌入层 (
Embedding_Layer):将输入点云的坐标嵌入到高维特征空间。 - 多尺度分组与聚合 (
Multi_Grouping):逐层对点云进行分组采样和特征聚合,生成多尺度的局部特征。 - 跨注意力模块 (
CrossAttBlock):在大尺度和小尺度的特征之间进行信息交互。 - 分类器 (
mlp_head_large和mlp_head_small):将处理后的特征通过多层感知机(MLP)输出分类结果。
class PointCAT(nn.Module):
def __init__(self, small_dim=1024, large_dim=512, k=16, class_num=40):
super(PointCAT, self).__init__()
self.embedding = Embedding_Layer(in_channel=3, embedding_channel=64)
self.sample_1 = Multi_Grouping(channel=64, groups=512, kneighbors=k, use_xyz=False, normalize="center")
self.sample_2 = Multi_Grouping(channel=128, groups=256, kneighbors=k, use_xyz=False, normalize="center")
self.sample_3 = Multi_Grouping(channel=256, groups=128, kneighbors=k, use_xyz=False, normalize="center")
self.sample_4 = Multi_Grouping(channel=512, groups=64, kneighbors=k, use_xyz=False, normalize="center")
self.class_token_small = nn.Parameter(torch.randn(1, 1, small_dim))
self.class_token_large = nn.Parameter(torch.randn(1, 1, large_dim))
self.cross_attn_layer = CrossAttBlock(large_dim=large_dim, small_dim=small_dim, cross_attn_depth=2,
cross_attn_heads=8, channels=large_dim)
...
在这里:
sample_1到sample_4分别用于将输入点云降采样至不同的分辨率,同时提取相应的几何特征。class_token_small和class_token_large用作跨注意力机制中的分类 token,分别对应小尺度和大尺度特征。cross_attn_layer是跨注意力层,负责将大尺度和小尺度特征进行交互。
2. 多尺度特征提取与聚合 (Multi_Grouping 类)
每个 Multi_Grouping 模块负责逐层降采样点云,并提取局部的几何特征。通过 K 近邻算法(KNN)查找点的局部邻域,然后对其进行特征聚合。
class Multi_Grouping(nn.Module):
def __init__(self, channel, groups, kneighbors, use_xyz, normalize="center"):
super(Multi_Grouping, self).__init__()
self.grouper = LocalGrouper(channel=channel, groups=groups, kneighbors=kneighbors, use_xyz=use_xyz,
normalize=normalize)
self.net = Local_Aggregation(2 * channel, 2 * channel)
def forward(self, xyz, x): # B, N, C
new_xyz, new_feature = self.grouper(xyz, x)
x = self.net(new_feature)
return new_xyz, x
在 forward 函数中:
LocalGrouper通过 KNN 对点进行分组,找到局部邻域的点。Local_Aggregation对这些局部特征进行聚合,以提取出更加紧凑的局部表示。
3. 跨注意力机制 (CrossAttBlock 和 CrossAttEncoder)
跨注意力机制负责在大尺度和小尺度的特征之间进行交互。该模块的作用是增强全局与局部特征的联系。
class CrossAttBlock(nn.Module):
def forward(self, xl, xs):
xl, xs = self.cross_att1(xl, xs)
xl, xs = self.cross_att2(xl, xs)
return xl, xs
CrossAttBlock 包含两个 CrossAttEncoder,通过多层次的注意力计算对不同分支的特征进行多次交互。具体的注意力计算由 CrossAttEncoder 完成:
class CrossAttEncoder(nn.Module):
def forward(self, l, s):
...
# 大尺度分支
cal_q = conv1_l_s(large_class.unsqueeze(-1)).permute(0, 2, 1)
cal_q = self.ln_ls1(cal_q)
cal_qkv = torch.cat((cal_q, x_small), dim=1)
cal_out = cal_q + cross_attn_l(cal_qkv)
...
# 小尺度分支
cal_q = conv1_s_l(small_class.unsqueeze(-1)).permute(0, 2, 1)
cal_qkv = torch.cat((cal_q, x_large), dim=1)
cal_out = cal_q + cross_attn_s(cal_qkv)
...
return xl, xs
在这里,大尺度和小尺度的分类 token 被用作查询(query),另一个分支的特征被用作键和值,通过注意力机制来计算分支间的交互。这样,模型能够融合全局和局部的信息。
4. 特征分类与输出
经过多尺度特征提取和跨注意力交互后,模型将这些特征通过两个 MLP 头(mlp_head_large 和 mlp_head_small)进行分类:
class PointCAT(nn.Module):
def forward(self, x):
...
x1, x2 = self.cross_attn_layer(x1, x2)
x1 = self.mlp_head_large(x1)
x2 = self.mlp_head_small(x2)
x = x1 + x2
return x
最终的分类结果是通过大尺度和小尺度特征的分类结果相加得到的。这个设计可以确保不同分辨率的特征都对分类任务有所贡献。
总结
PointCATCross 的核心在于通过 多尺度特征提取 和 跨注意力机制 来融合不同分辨率下的几何信息。跨注意力机制能够在全局和局部特征之间建立联系,从而提升模型对复杂三维点云结构的理解能力。借鉴以上思路,可以进行如下改进来增强PointNet++ 对点云多尺度特征、全局信息以及复杂几何关系的捕捉能力,进一步提升了其在点云分类和分割任务中的表现。
- 引入跨尺度注意力机制:利用 PointCATCross 的跨注意力模块,实现多尺度特征的相互交互和增强。
- 引入分类 Token 和多层级特征交互:使用分类 Token 捕捉全局信息,并通过跨注意力机制增强局部和全局特征的交互。
- 增强全局上下文特征的捕捉:通过引入 Transformer 或自注意力机制,增强 PointNet++ 在全局上下文特征捕捉方面的能力。
如何改进PointNet++
要利用 PointCATCross 来改进 PointNet++,可以借鉴 PointCATCross 中的跨注意力机制、多尺度特征交互以及全局上下文特征融合等优点,从以下三个方面进行改进:
引入跨尺度注意力机制
在 PointNet++ 中的多尺度聚合(如 SA 模块)中加入跨尺度注意力机制。PointNet++ 通过半径搜索和 KNN 提取多层次的局部特征,但缺少不同尺度之间的联系和交互。通过引入 PointCATCross 的跨注意力机制,可以让不同尺度的特征相互交互,增强模型对点云全局和局部几何结构的捕捉能力。
优点:
- 跨尺度注意力机制增强了局部和全局特征的融合,能够提高模型在处理不同分辨率点云上的表现。
- 更好地利用多尺度信息,实现更精准的特征捕捉。
引入分类 Token 和多层级特征交互
PointCATCross 的一大特色是通过分类 Token 进行全局特征的交互与聚合。借鉴这一思路,可以在 PointNet++ 中引入类似的分类 Token 概念,在不同特征层之间使用全局 Token 来捕捉全局信息,并通过跨尺度交互让不同层的特征聚合。
优点:
- 引入分类 Token 可以在特征提取过程中捕捉全局信息,并有效提升最终的分类或分割性能。
- 通过多层次的特征交互,进一步增强模型对全局和局部几何关系的理解。
增强全局上下文特征的捕捉(使用 Transformer 模块)
PointNet++ 主要通过逐层局部特征提取来获取全局信息,但对长程依赖和全局上下文的捕捉较弱。可以借鉴 PointCATCross 中的全局特征融合机制,使用 Transformer 模块或全局注意力机制来增强全局特征的捕捉能力。
优点:
- 自注意力机制能够捕捉点云中的长程依赖,特别适用于具有复杂几何结构的场景。
- 通过 Transformer 模块,增强了模型的全局信息捕捉能力,提升了分类或分割任务的准确性。