今天给大家推荐一个很好上手的创新思路:小样本学习+CLIP。
这个思路的优势在于:通过利用CLIP模型强大的跨模态表征能力,再结合小样本学习技术,我们就可以在仅提供少量标注样本的情况下,快速适应新的任务,在多个领域实现高效的学习。
更值得一提的是,最近这个方向吸引到了一大波研究兴趣,各大顶会顶刊上相关成果数量繁多,比如收录于CVPR 2024的AMU-Tuning方法、DeIL方法等,以及顶刊IJCV 2024上的CLIP-FSAR框架,投稿热度可见一斑。
为了帮助有论文需求的同学更好地掌握这个创新思路,今天我就来分享11种小样本学习+CLIP创新方法,都是今年最新,开源代码已附~
论文原文+开源代码需要的同学看文末
AMU-Tuning: Effective Logit Bias for CLIP-based Few-shot Learning
方法:论文提出了一种名为AMU-Tuning的方法,用于改进基于CLIP模型的小样本学习性能。该方法通过分析关键组件——logit特征、logit预测器和logit融合——来学习有效的logit偏差,并通过利用辅助特征、多分支训练的特征初始化线性分类器以及基于不确定性的融合策略,将logit偏差有效地整合到CLIP中,以提高小样本分类的准确性。
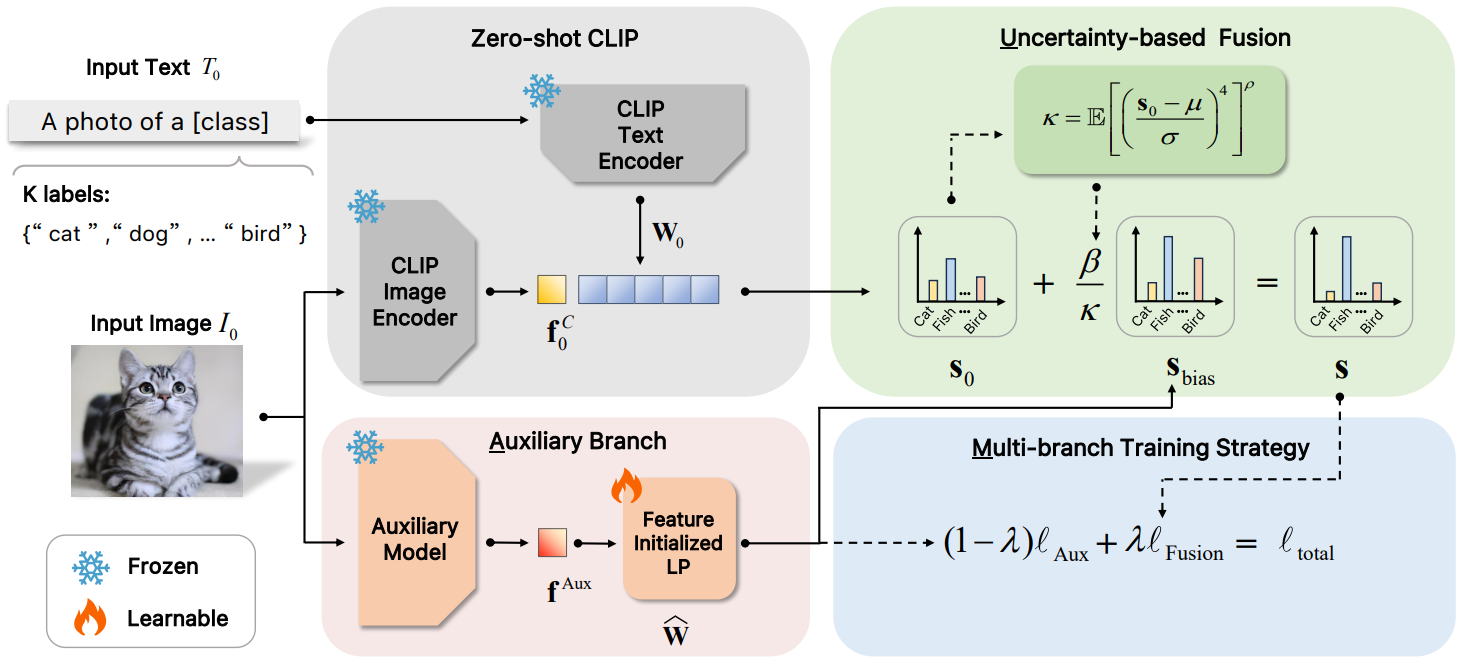
创新点:
-
从logit偏差的角度总结和分析了现有的方法,揭示了logit偏差对few-shot分类性能的影响。
-
提出了AMU-Tuning方法,通过利用适当的辅助特征来预测logit偏差,并使用多分支训练的特征初始化线性分类器进行训练。
-
引入了基于不确定性的融合方法,将logit偏差融入CLIP进行few-shot分类。
CLIP-guided Prototype Modulating for Few-shot Action Recognition
方法:论文提出了一个名为CLIP-FSAR的框架,用于改进基于CLIP模型的小样本动作识别性能。该框架通过两个关键组件来实现:一是视频-文本对比目标,通过对比视频和相应的类别文本描述来缩小CLIP与小样本视频任务之间的差异;二是原型调制,利用CLIP中的可转移文本概念,通过时间Transformer自适应地细化视觉原型。
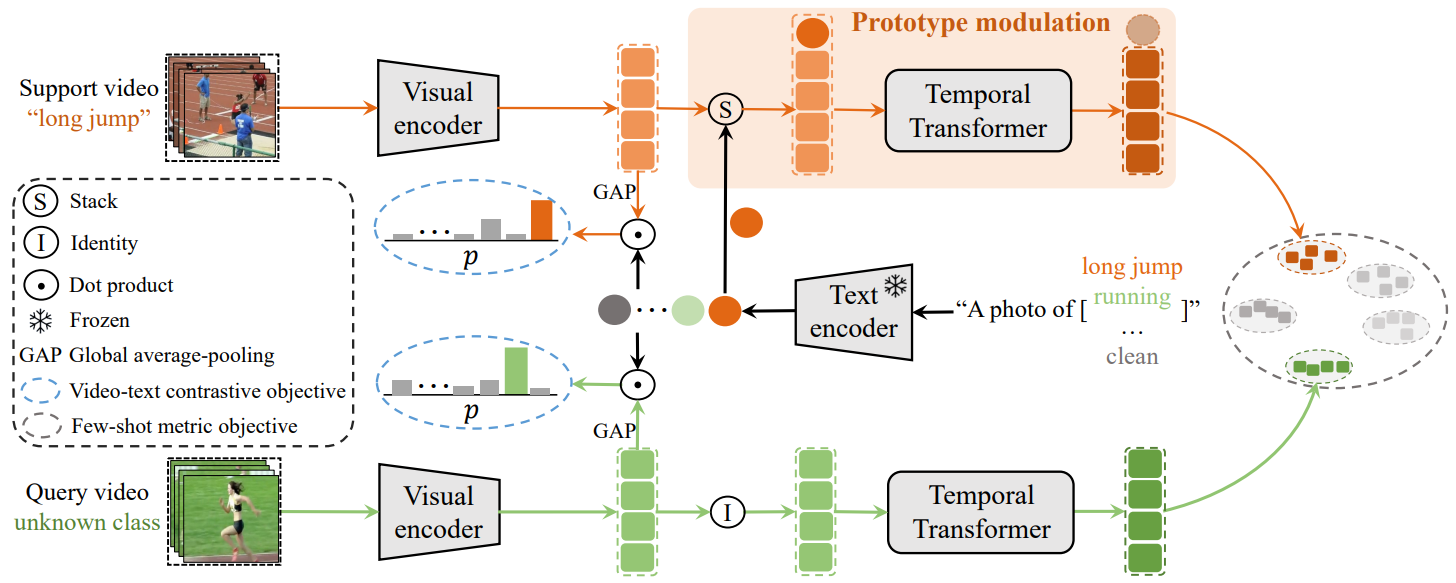
创新点:
-
提出了一种全新的CLIP-FSAR方法,该方法充分利用了CLIP模型的多模态知识。这是第一次尝试将大规模对比语言-图像预训练应用于少样本动作识别领域。
-
设计了视频-文本对比目标用于CLIP的适应性改变,并通过实现时间Transformer来自适应地调节视觉支持原型的特征。

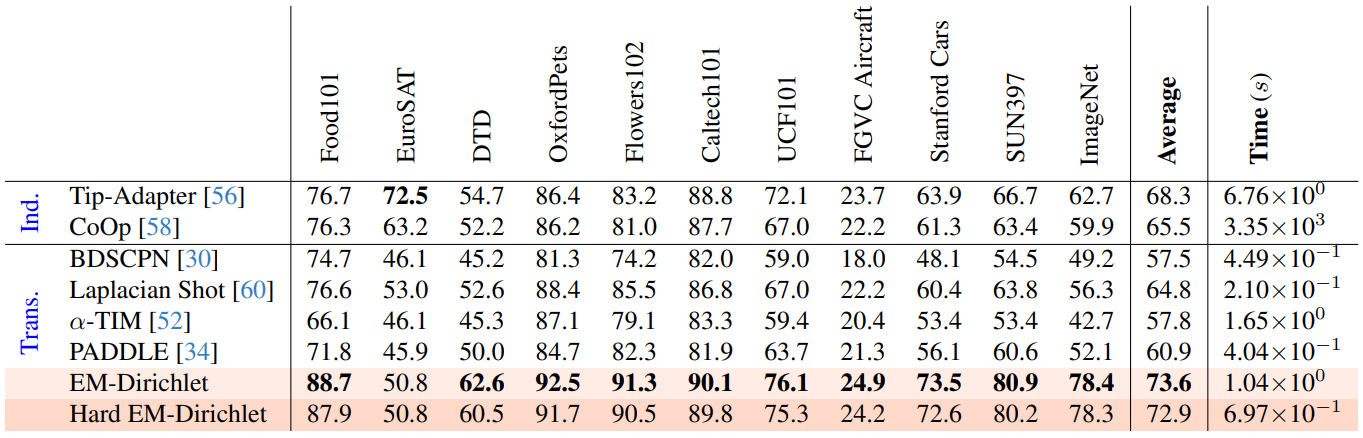
Transductive Zero-Shot and Few-Shot CLIP
方法:论文提出了一种名为Transductive Zero-Shot and Few-Shot CLIP的方法,用于改进基于CLIP模型的小样本图像分类任务。该方法采用归纳推理,通过联合预测一批未标记查询样本的类别,而不是独立处理每个实例。作者还通过构建视觉-文本概率特征并采用Dirichlet分布建模,提高了分类的准确性。
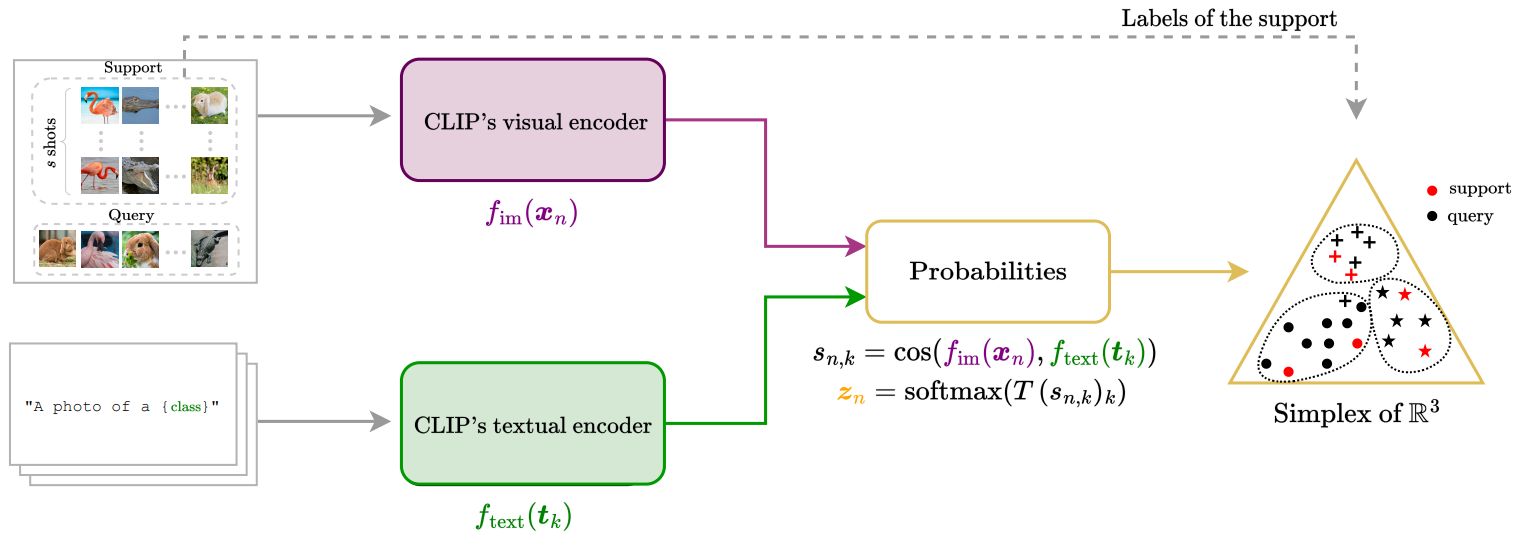
创新点:
-
对该聚类方法EM-Dirichlet及其利用硬分配的变体Hard EM-Dirichlet进行了比较评估,与一系列聚类目标函数和算法进行比较。这是对聚类方法进行全面消融研究的第一步。
-
展示了跨视觉-语言模型的转导推理可以提高图像分类准确性,包括零样本情况。这是对转导推理在这一领域中的新应用。
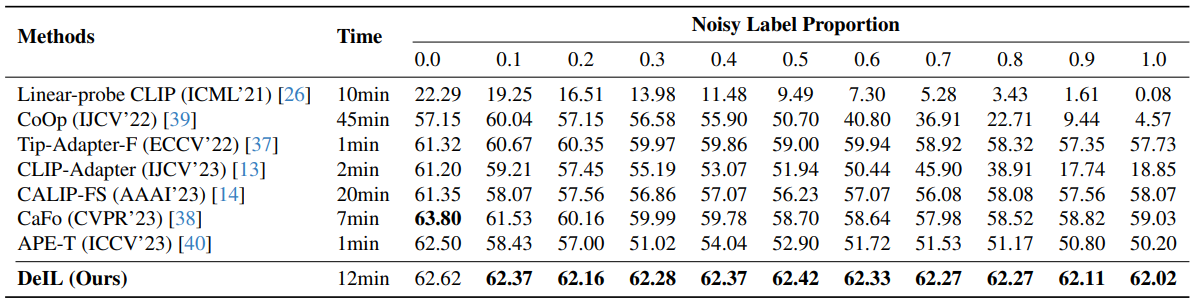
DeIL : Direct-and-Inverse CLIP for Open-World Few-Shot Learning
方法:论文通过引入直接和反向概念,提出了一种创新的方法DeIL,利用基于CLIP的基础模型有效地进行开放世界少样本学习,包括DeIL-Pretrainer和DeIL-Adapter两个组件,通过纠正噪声标签和对数据进行增强来改进分类性能,实验证明了Direct-and-Inverse概念在OFSL中的有效性和优越性。
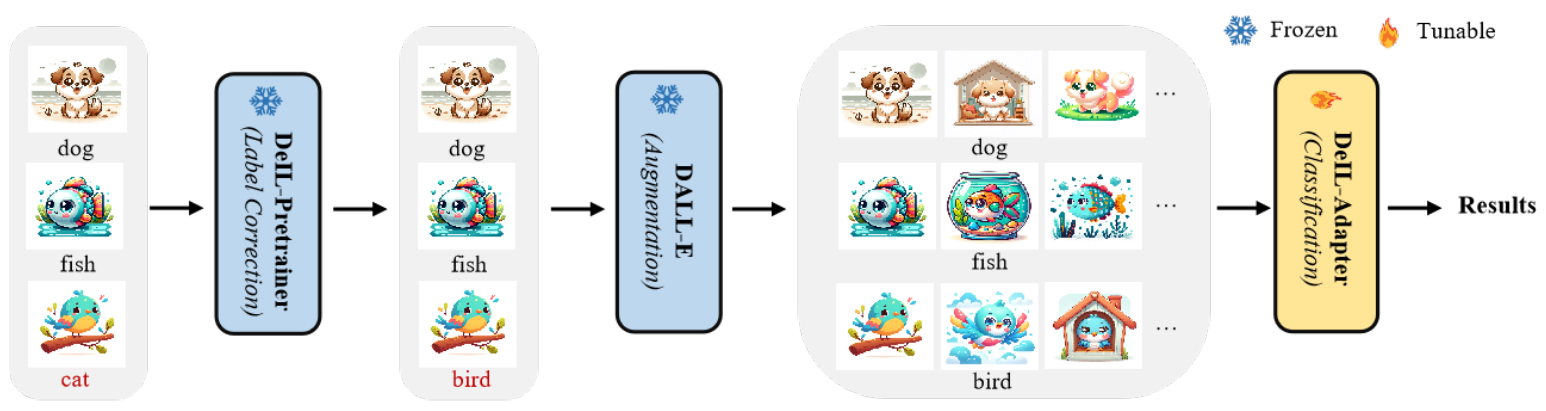
创新点:
-
通过巧妙地应用直接反演的概念,DeIL方法充分利用了基于CLIP的方法的内在能力和先验知识,显著提高了OFSL的性能。
-
利用冻结的DALL-E模型扩展了OFSL的数据,根据修正后的类别名称生成图像。通过增加和多样化支持样本,这种方法解决了FSL中数据稀缺的问题,提高了模型在查询数据上的泛化能力和性能。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“小样本结合”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏