这里写目录标题
- 1 makefile原理
- 2 MakeFile步骤
- 3 多文件多子目录Makefile实例
- 4 总结
- 附录一:常用Bash指令
- 附录二:常用批处理变量
- 附录三:常用makefile指令
1 makefile原理
编译过程是将高级语言(如C、C++等)源代码转换为可执行程序的过程。这个过程通常包括预处理、编译、汇编和链接四个主要阶段。下面将详细解释每个阶段的任务和过程:
-
预处理(Preprocessing)
预处理是编译过程的第一步,它主要处理源代码中的预处理指令,如宏定义(#define)、条件编译(#if、#elif、#else、#endif)和文件包含(#include)等。预处理器的输出是一个纯文本文件,通常具有.i或.ii扩展名,这个文件已经去除了注释、宏定义被展开、条件编译指令被处理,并且包含了所有被#include指令指定的文件内容。 -
编译(Compilation)
编译阶段将预处理后的源代码转换成汇编语言代码。这个过程可以分为几个子步骤:扫描(Scanning):将源代码分解成一系列的单词(tokens),如标识符、保留字、常数、运算符和界符。
语法分析(Parsing):根据语言的语法规则,将tokens组织成语法树(syntax tree)的形式,以表示源代码的语法结构。
语义分析(Semantic Analysis):检查语法树的语义正确性,包括类型检查、控制流检查等,并为语法树节点标注类型信息。
源代码优化(Source Code Optimization):对语法树进行优化,以提高代码的执行效率。
代码生成(Code Generation):将优化后的语法树转换成汇编代码。
目标代码优化(Target Code Optimization):对生成的汇编代码进行进一步的优化,以适应不同CPU架构的特性。 -
汇编(Assembly)
汇编阶段将编译生成的汇编代码转换成机器语言指令,即二进制代码。汇编器的输出是一个目标文件(object file),通常具有.o或.obj扩展名。这个文件包含了程序的二进制代码,但还不能直接执行,因为它可能还包含了未解析的外部引用(如对其他程序或库函数的调用)。 -
链接(Linking)
链接阶段将多个目标文件以及所需的库文件合并成一个可执行文件(executable file)。这个过程包括:
合并各个.obj文件的section:将不同目标文件中的代码段、数据段等合并到同一个可执行文件中。
合并符号表:将所有目标文件和库文件中的符号(如函数名、变量名)合并到一个统一的符号表中。
符号解析:解决目标文件中未解析的外部引用,即将符号表中的符号与实际的代码或数据地址关联起来。
符号地址重定位:调整程序中所有符号的地址,以确保它们在可执行文件中的位置是正确的。
最终,链接器生成一个可执行文件,该文件包含了程序运行所需的所有代码和数据,并且可以在目标操作系统上直接执行。
综上所述,编译过程是一个复杂而精细的过程,它涉及多个阶段和多个工具(如预处理器、编译器、汇编器和链接器)的协同工作。通过这个过程,高级语言的源代码被转换成机器可以直接执行的二进制代码。
2 MakeFile步骤
- 1 运行cygwin环境
- 2 运行make指令将搜索当前路径下makefile文件并执行第一个目标
- 3 预处理:生成预处理后的代码(可选地保存为.i文件)
- 4 编译+汇编(隐式):生成对象文件(.o或.obj)
- 5 链接:生成可执行文件(如.exe、.elf),然后可以转换为其他格式(如.hex)以用于特定目的
3 多文件多子目录Makefile实例
文件结构


其中OpenCygwin.bat用于再windows上运行unix环境,makefile文编译文件其中将会指定编译器路径,这里使用的是Gcc;bin 存放中间文件 inc存放代码头文件;src存放.c文件;main.c将会调用两个子文件中的函数
- OpenCygwin.bat
@echo off
:: 定义Cygwin bash的路径
set CYGWIN_BASH=E:\GRC\Tools\cywin64\cygwin64\cygwin64\bin\bash
:: 构造bash命令,切换到批处理文件所在的目录(转换为Cygwin路径)
:: 注意:%~dp0给出批处理文件的目录(不包括文件名),但需要转换为/cygdrive/e/形式
set CYGWIN_PATH='%~dp0'
:: 启动bash,以登录shell和交互式模式运行,并执行cd命令和exec bash
%CYGWIN_BASH% --login -i -c "cd %CYGWIN_PATH%; pwd; exec bash"
:: 注意:pwd命令用于显示当前目录,以验证是否成功切换
- makefile
# 定义编译器和编译选项
CXX=gcc
CXXFLAGS=-I./inc -Wall -g
# 定义目录
SRCDIR=src
BINDIR=bin
OBJDIR=$(BINDIR)/obj
# 创建目标文件夹
#$(shell mkdir -p $(OBJDIR) $(BINDIR) 2>/dev/null)
# 查找所有 .c 文件并生成对应的 .o 文件目标
SRCS=$(shell find $(SRCDIR) -name '*.c')
OBJS=$(SRCS:$(SRCDIR)/%.c=$(OBJDIR)/%.o)
CLEAN_OBJ =$(shell find $(SRCDIR) -name '*.o')
# 最终目标
TARGET=myapp
# 默认目标
all: $(TARGET)
# 链接目标
$(TARGET): $(OBJS)
@echo "build in $@ from $^... "
$(CXX) $(CXXFLAGS) -o $@ $^
# 编译规则(模式规则)
$(OBJDIR)/%.o: $(SRCDIR)/%.c
@echo "build in $@ ..."
$(CXX) $(CXXFLAGS) -c $< -o $@
# 清理
clean:
rm -f $(CLEAN_OBJ) $(TARGET)
.PHONY: all clean
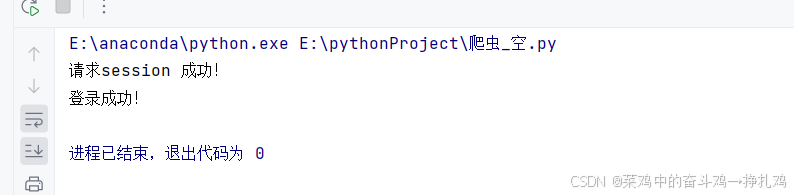
运行结果



4 总结
本文为博主个人学习总结记录,如有不正,欢迎指正
附录一:常用Bash指令
Bash(Bourne Again SHell)是Linux系统中最常用的命令行解释器,提供了丰富的命令和功能,帮助用户有效管理和操作Linux系统。以下是一些常用的Bash指令及其简要说明:
- 文件和目录操作
ls:列出目录内容。常用选项包括-l(长格式显示)、-a(显示所有文件,包括隐藏文件)、-h(以易读方式显示文件大小)。
cd:切换当前工作目录。例如,cd /path/to/dir切换到指定目录,cd …切换到上级目录。
pwd:显示当前工作目录的路径。
mkdir:创建新目录。使用-p选项可以递归创建多层目录。
rm:删除文件或目录。使用-r选项递归删除目录,-f选项强制删除不提示确认。
cp:复制文件或目录。使用-r选项递归复制目录。
mv:移动或重命名文件或目录。
touch:创建新文件或修改文件的时间戳。 - 文件查看和编辑
cat:查看文件内容。对于较长的文件,可以配合-n选项显示行号。
less:分页显示文件内容,比cat更适合查看大文件。
head:显示文件的前几行。使用-n选项指定行数。
tail:显示文件的后几行。使用-n选项指定行数,-f选项实时查看文件更新。
grep:在文件中搜索指定的文本或模式。常用选项包括-i(不区分大小写)、-r(递归搜索)。
vi/vim:文本编辑器,用于创建和编辑文件。 - 系统管理
ps:显示当前运行的进程。
top:实时显示系统资源的使用情况,包括CPU、内存等。
kill:终止正在运行的进程。通过进程ID(PID)来指定要终止的进程。
reboot:重启系统。
shutdown:关闭系统。
uname:显示系统信息,如内核名称、主机名等。 - 网络管理
ping:测试与目标主机的网络连通性。
ssh:远程登录到其他主机,进行远程管理或操作。
scp:在本地和远程系统间复制文件。
curl:发送HTTP请求并获取网页内容。
wget:从网络上下载文件。 - 权限管理
chmod:修改文件或目录的权限。通过指定权限模式(如755)来改变文件或目录的访问权限。
chown:修改文件或目录的所有者。需要超级用户权限来更改其他用户的文件所有者。
chgrp:修改文件或目录的所属组。 - 其他常用命令
man:查看命令的手册页,获取命令的详细说明和用法。
info:查看命令的信息页,提供另一种获取命令帮助的方式。
history:显示最近执行过的命令历史记录。
find:根据特定条件查找文件或目录。
du:显示目录或文件的磁盘使用情况。
df:显示文件系统的磁盘空间使用情况。
附录二:常用批处理变量
在批处理(Batch)脚本中,变量是一种重要的元素,用于存储和引用数据。常用的批处理变量主要分为两类:系统变量和用户自定义变量。以下是对这两类变量的详细介绍:
1.系统变量
系统变量是由系统根据其定义的条件自动赋值的变量,用户无需手动为它们赋值即可直接使用。系统变量包括多种类型,如硬件类、操作系统类、文件路径类、系统时间类等。以下是一些常用的系统变量:
%CD%:扩展到当前目录的字符串。
%DATE%:用与DATE命令相同的格式扩展到当前日期。
%TIME%:用与TIME命令相同的格式扩展到当前时间。
%RANDOM%:扩展到0和32767之间的任意十进制数字。
%ERRORLEVEL%:扩展到当前ERRORLEVEL数值,用于表示上一个命令的退出代码。
%CMDEXTVERSION%:扩展到当前命令处理器扩展名版本号。
%CMDCMDLINE%:扩展到调用命令处理器的原始命令行。
%0:批处理文件的完整路径名。
%1 至 %9:批处理文件的参数,%1代表第一个参数,%2代表第二个参数,依此类推。注意,批处理文件最多可以有9个参数。
%*:返回所有参数的值,而不需要一个个输入%1、%2等。
2.用户自定义变量
用户自定义变量是由用户根据需要自行定义的变量。它们只在定义它们的批处理程序中有效。用户自定义变量通常使用set命令来定义和赋值。以下是一些使用set命令定义和使用用户自定义变量的示例:
定义变量:set 变量名=变量值。例如,set myVar=Hello World。
引用变量:在需要引用变量的地方,使用%变量名%的格式。例如,echo %myVar%将输出Hello World。
取消变量:通过为变量赋值一个空字符串来取消变量,但请注意,这并不会从内存中删除变量,只是使其值变为空。要真正释放变量所占用的内存空间,需要考虑批处理脚本的执行环境和上下文。
可选参数:
set /p 变量名=提示信息:允许用户通过键盘输入来为变量赋值。
set /a 变量名=表达式:用于执行算术运算,并将结果赋值给变量。例如,set /a count=1+2将变量count的值设置为3。
附录三:常用makefile指令
- 打印信息
#期望打印的数据
ifeq ($(DIR),)
DIR := $(shell cygpath -m "$(COMPONENT_DIR)\DEMO")
endif
#方式一 任意位置打印
$(info CDD_DIR is $(CDD_DIR)) # 使用 GNU Make 的 $(info) 函数来打印信息
#方式二 再构建目标中打印
all:
@echo "CDD_DIR is $(CDD_DIR)"
- 调用其他文件
include $(MAKE_DIR)/rules_iar.mak //将对应位置的文件内容拷贝到此处
- 定义宏(也称为函数或模板)
define ADD_COMPONENT
$(info Adding component: $1) //$1 表示调用ADD_COMPONENT时传入的第一个参数 $2则是第二个参数
-include $2/$1_cfg.mak
-include $2/$1_check.mak
-include $2/$1_defs.mak
include $2/$1_rules.mak
endef
- $(foreach …) 函数
$(foreach var,list,text)
var 是临时变量名,它在循环的每次迭代中都会被赋予 list 中的一个元素值。
list 是要遍历的元素列表,元素之间通常由空格分隔。
text 是每次迭代中要执行的Makefile语句或文本,其中可以引用 var 来获取当前迭代的元素值。
可以理解为用var去遍历list,并再text中对var操作
eg:
FILES = foo.c bar.c baz.c
all:
@echo "Processing files:"
$(foreach file,$(FILES),$(info Processing $(file)))
@echo "Done processing files."
#在这个例子中,$(foreach ...) 遍历 FILES 列表中的每个文件名,并使用 $(info ...) 打印正在处理的文件名
- $(Call …) 函数
$(call variable,param,param,...)
variable 是你之前已经定义的一个变量,它包含了要执行的Makefile代码(通常是一个宏或模板)。这个变量应该被定义为一个字符串,其中包含了你想要执行的命令或规则,以及占位符(如$(1)、$(2)等)来代表传递给call函数的参数。
param,param,... 是传递给variable中定义的宏的参数列表。在宏内部,你可以通过$(1)、$(2)等方式来引用这些参数,其中$(1)代表第一个参数,$(2)代表第二个参数,依此类推
eg:
#定义一个宏,用于编译C文件,并接受额外的编译选项
define compile_c_with_opts
$(CC) $(CFLAGS) $(1) -c -o $@ $<
endef
#调用宏来编译main.c,并传递额外的编译选项-O2
main.o: main.c
$(call compile_c_with_opts,-O2)
#假设CC和CFLAGS已经在其他地方被定义了
CC=gcc
CFLAGS=-Wall
- $(eval …)函数
$(eval text)
text 是要动态执行的Makefile代码
可以理解为 任何text都会为eval函数转换为makefile代码
eg:
# 假设我们有一个组件列表
COMPONENTS = comp1 comp2 comp3
# 定义一个宏来生成构建规则
define generate_rule
$(1)_obj = $(1).o
$(1)_obj: $(1).c
$(CC) $(CFLAGS) -c -o $$@ $$<
endef
#遍历组件列表,并为每个组件调用generate_rule宏
$(foreach comp,$(COMPONENTS),$(eval $(call generate_rule,$(comp))))
#假设CC和CFLAGS已经在其他地方被定义了
CC=gcc
CFLAGS=-Wall -g
#现在我们可以构建所有组件的对象文件了
all: $(foreach comp,$(COMPONENTS),$(comp)_obj)
@echo "All objects built successfully."