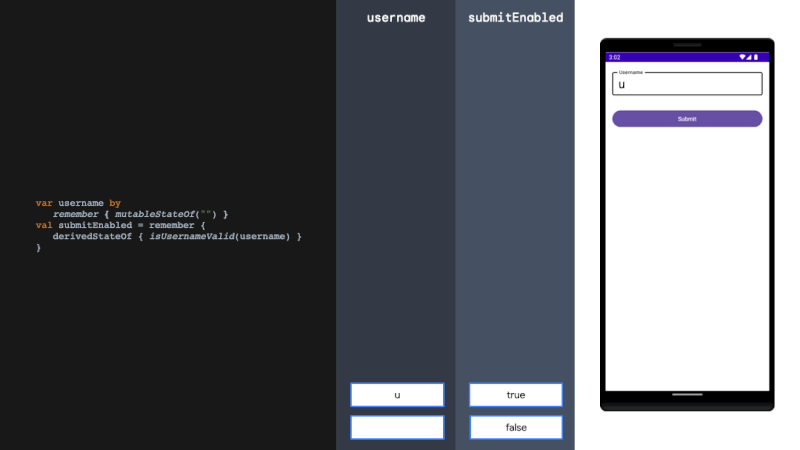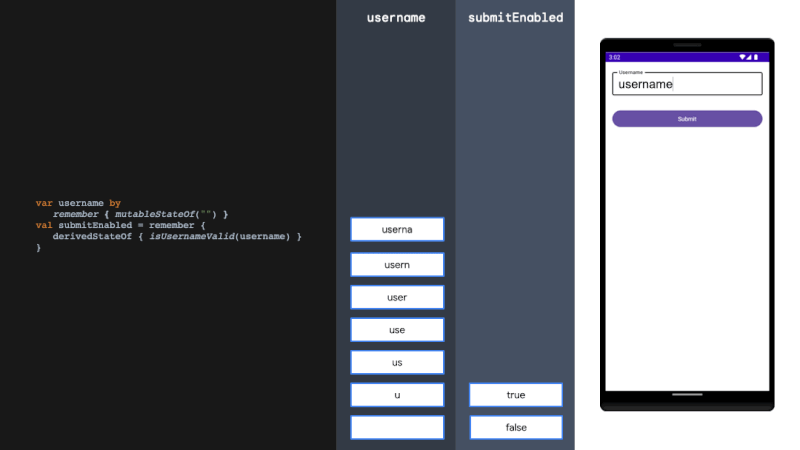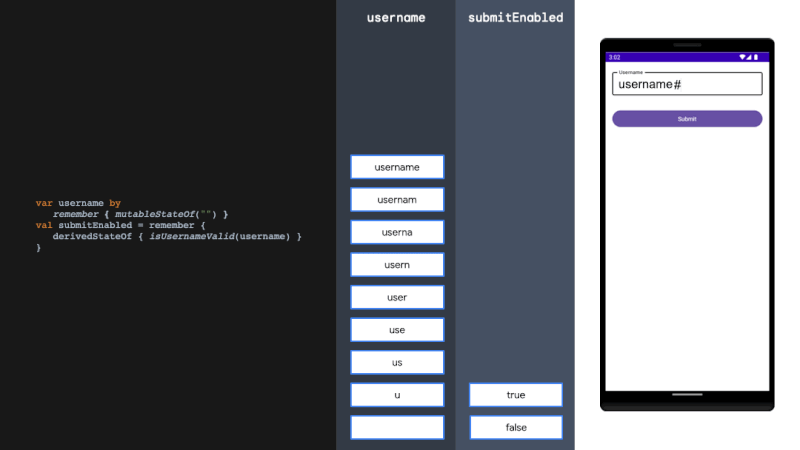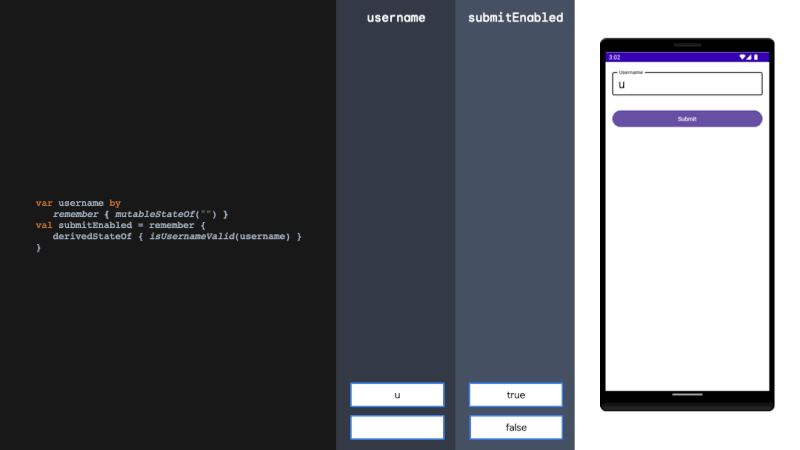
引言:感觉这篇文章,对 LLMs 的新闻编辑能力做了一个详细的实验和分析,而且还贡献了一个宝贵的中文新闻数据集,蛮不错的,后面或许可以用起来,就拜读了一下。
这篇博客的题目说是解读,其实大部分都是翻译哈哈哈,不过是经过俺这🍉脑子的翻译
✅ NLP 研 1 选手的学习笔记
简介:Wang Linyong,NPU,2023级,计算机技术
研究方向:文本生成、大语言模型
论文链接:https://aclanthology.org/2024.acl-long.538/,2024 ACL(CCF A) 长文
项目链接:https://github.com/IAAR-Shanghai/NewsBench
中文标题:《NewsBench:一个评估中文新闻大型语言模型编辑能力的系统评估框架》

文章目录
- 0 摘要(Abstract)
- 1 前言(Introduction)
- 2 相关工作(Related Word)
- 3 评估框架(The Evaluation Framework)
- 3.1 写作和安全的评估方面(Evaluation Facets for Writing and Safety)
- 3.2 测试样本的问题类型(Question Types of Test Samples)
- 4 基准数据集构建(Benchmark Dataset Construction)
- 4.1 测试样本的提示格式(Prompt Formats for Test Samples)
- 4.2 人类专家构建数据集(Dataset Construction by Human Experts)
- 4.3 数据集统计与特征(Dataset Statistics and Features)
- 5 简答问题的评估协议(Evaluation Protocols for Short Answer Questions)
- 5.1 写作能力标准(Protocols for Writing Proficiency)
- 5.2 安全遵守协议(Protocols for Safety Adherence)
- 5.3 GPT-4分数的人工验证(Human Validation of GPT-4 Scores)
- 6 LLMs的系统评估(Systematic Evaluations of LLMs)
- 6.1 实验设置(Experimental Settings)
- 6.2 LLMs的比较结果(Comparison Results of LLMs)
- 6.3 具有挑战性的测试样本分析(Analysis on Challenging Test Samples)
- 7 结论(Conclusion)
- 8 限制(Limitations)
- 9 道德声明(Ethics Statement)
- 8 参考文献(References)
0 摘要(Abstract)
● 本文提出 NewsBench,一个新的评估框架,系统地评估大型语言模型(LLMs)在中文新闻编辑能力方面的能力。构建的基准数据集关注写作能力的 4 个方面和安全遵守的 6 个方面,由人工和精心设计的 1,267 个测试样本组成,包括 24 个新闻领域的 5 个编辑任务的多项选择题和简答问题类型。为衡量性能,本文提出了不同的基于 GPT-4 的自动评估协议,从写作能力和安全遵守方面评估简答题的 LLMs 生成,并通过与人工评估的高度相关性进行了验证。基于系统的评估框架,我们对目前流行的 11 种能够处理中文的 LLMs 进行了全面的分析。实验结果突出了 GPT-4 和 ERNIE Bot 是最佳表现者,但揭示了创意写作任务中的新闻安全遵守的相对不足。研究结果还强调了在机器生成的新闻内容中有加强道德指导的必要性,标志着 LLMs 与新闻标准和安全考虑的统一向前迈出了一步。评估框架和实验结果将有助于深入理解 LLMs 的编辑能力,并加速 LLMs 在新闻领域的发展。
整篇文章的一些常出现的术语,我的翻译:
| 文章中一些常出现的术语 | 我的翻译 | 含义 |
|---|---|---|
| SA | 安全遵守 | Safety Adherence,即大语言模型在写作时应该保护用户隐私、遵守不产生歧视和偏见等安全规则 |
| JWP | 新闻写作能力 | Journalistic Writing Proficiency |
| SAQs | 简答题 | Short Answer Questions |
| MCQs | 多选题 | Multiple Choice Questions |
| JWP-SAQs | 在简答题上的新闻写作能力 | JWP on short answer questions |
| JWP-MCQs | 在多选题上的新闻写作能力 | JWP on multiple choice questions |
| SA-SAQs | 在简答题上的安全遵守能力 | SA on short answer questions |
| SA-MCQs | 在多选题上的安全遵守能力 | SA on multiple choice questions |
1 前言(Introduction)
● 具有应用程序编程接口(api)的大型语言模型(LLMs)的可用性越来越高,如 OpenAI 的 ChatGPT,进一步加快了 LLMs 技术在各种应用场景中的应用。然而,虽然 LLMs 为自然语言处理(NLP)提供了重大好处,但其不确定性(non-deterministic)和黑箱性(black-box nature)引发了有关 确保负责任和合乎道德地利用这一先进技术的 讨论和担忧(Berengueres and Sandell, 2023; Cui et al, 2024)。虽然一般的安全评估基准(Sun等人,2022、2023; Zhang et al., 2023)和保障措施(OpenAI, 2024),包括旨在防止有毒和有害内容的措施——OpenAI限制API,已经提出并实施了一些,有必要为各种专业领域和场景的独特规则、职责和风格量身定制专门的基准(Berengueres and Sandell, 2023; Diakopoulos等人)。在新闻工作中,它在 向公众提供信息方面发挥的重要作用 及其 影响公众看法的潜力 要求更高和更具体的道德和安全标准。
● 越来越多的 LLMs 被应用到中文新闻中,以完成标题生成(headline generation)、摘要(summarization)、续写(continuation writing)、扩展写作(expansion writing)和精炼(refinement)等编辑任务。尽管学术界和工业界在理解、监管和减轻新闻 LLMs 相关风险方面进行了大量讨论(Jones等人,2023; Arguedas和Simon, 2023年; Fui-Hoon Nah等人,2023; 库尔斯和Diakopoulos, 2023),但明显缺乏一个标准化的基准或系统的评估框架,以评估 LLMs 与新闻伦理(journalistic ethics)和安全标准(safety standard)的一致性,并将其与常见的新闻编辑任务(journalistic editorial tasks)相结合。
● 借鉴关于新闻业人工智能安全的讨论(Jones等人,2023; cool and Diakopoulos, 2023),本文引入了 NewsBench,一个系统的评估框架,专注于评估 LLMs 的编辑能力,不仅是新闻写作水平,而且是安全遵守能力。对于新闻写作的熟练程度,我们关注语言的流畅性(language fluency)、逻辑的连贯性(logical coherence)、风格的一致性(style alignment)和指令完成度(instruction fulfilment),而对于安全遵守,我们考虑 6 个方面,包括文明语言(civil language)、偏见和歧视(bias and discrimination)、个人隐私(personal privacy)、社会危害(social harm)、新闻道德(journalistic ethics)和非法活动(illegal activities)。构建了来自 24 个新闻领域的 5 个编辑任务,包括标题生成、摘要、写作延续、写作扩展和风格改进的基准数据集,共包含 1267 个选择题和简答题类型的测试样本。此外,NewsBench 包含了两个自动评估协议,用于评估 LLMs 生成的简答问题的写作能力和安全遵守能力。利用这个全面的框架,我们评估了 11 个可以处理中文的流行 LLMs,提供了对它们在各种新闻任务和安全考虑方面的表现的见解(insights)。
● 本文的主要贡献如下:
- 本文提出一个评估框架,用于系统评估新闻写作和安全遵守的 LLMs,发布了
1267个人工设计的测试样本,在5个编辑任务中有2种类型的简答和选择题。 - 开发了
2个基于 GPT-4 的新闻写作能力和安全合规性评估协议,并通过人工注释进行了验证。 - 本文对
11个流行的 LLMs 进行了比较分析和误差评估,发现了它们在中国新闻编辑任务中的优势和劣势。GPT-4 和 ERNIE Bot 被认为是领先的模型,尽管它们在创意写作任务中的新闻道德遵守 方面仍有局限性,而且参数较少但训练 tokens 较多的 LLMs 在我们的基准数据集上的表现比那些训练 tokens 较少的大型 LLMs 要好。
2 相关工作(Related Word)
● 著名的媒体机构,如 BBC(英国广播公司)(Arguedas and Simon, 2023),已将 LLMs 纳入其新闻制作工作流程,承担摘要、标题生成、翻译和写作风格改进等任务(Fui-Hoon Nah等人,2023),以加快和完善其编辑过程。随着这种不断发展的技术融合,人们越来越关注确保新闻领域人工智能的安全性,并在这些技术中嵌入道德和专业的新闻价值观 (Broussard等人,2019;Diakopoulos等人)。职业新闻伦理的核心理念强调对出版自由负责任。自由出版职业记者协会将这一概念扩展为四项关键原则:寻求真相、尽量减少伤害、独立行动和负责。目前已努力建议指导方针,使 LLMs 的使用符合媒体伦理和安全标准(Cools 和Diakopoulos, 2023; Fui-Hoon Nah等人,2023)。Jones等人(2023)编制了一份与在新闻行业使用 LLMs 相关的风险的详尽清单,其中包括三个主要类别,包括编辑风险、法律和监管风险以及社会风险。
● 评估 LLMs 的性能和安全性的基准数量越来越多(Sun等人,2022;张等,2023;Sun等人,2023;Xu等,2023)。然而,这些基准主要针对一般情况,而新闻媒体的运营需要遵守特定的职业道德、造型要求和安全标准,并承担更大的社会责任。Zagorulko(2023) 在评估 LLMs 生成的输出与新闻相关的评估方面是先驱,如主题性、可靠性、观点的平衡和信息的准确性。然而,由于该框架需要人工评估,因此无法有效应用于新出现的 LLMs。尽管最近取得了这些进展,但在专门评估特定新闻编辑任务背景下 LLMs 的新闻写作(Hicks等人,2016)和安全性(Jones等人,2023)的基准方面仍然存在差距。
3 评估框架(The Evaluation Framework)
● 该评估框架旨在对 LLMs 的编辑能力进行全面和自动化的评估,特别关注新闻写作能力(journalistic writing proficiency, JWP) 和安全遵守能力(SA) (第 3.1 节)。评估分为简答题(SAQs)和多项选择题(MCQs)(第 3.2 节)。为了汇总和比较 LLMs 的性能,本文开发了 4 种类型的评估:多项选择题 JWP (JWP-MCQs)、简答题 JWP(JWP-SAQs)、多项选择题 SA-MCQs、简答题SA-SAQs。图 1 说明了我们评估框架的整体工作流程。具体来说,对于每个要评估的 LLM,框架首先采取 4 种类型的评估来引出 MCQs 和 SAQs 的相应答案。为了获得 LLM 在 4 种类型评估上的最终性能,我们采用准确度(accuracy)作为 MCQs 的评估指标,同时实现了基于 GPT-4 的 SAQs 评估指标。

3.1 写作和安全的评估方面(Evaluation Facets for Writing and Safety)
● 我们根据专业记者的专业知识精心制定了一套细粒度的评估方面,确保根据新闻写作标准和安全遵守要求对 LLM 的表现进行全面和细致的评估。
● 将新闻写作能力定义为 4 个细粒度的方面,综合评估生成内容的质量:
- 语言流畅性(Language Fluency),评估内容的基本可读性和语法准确性,是清晰、专业沟通的基础。
- 逻辑连贯性(Logical Coherence),考察内容的组织和逻辑结构,对于促进思想的合理和连贯的传达至关重要。
- 风格一致性(Style Alignment),评估内容是否坚持简洁、准确、客观的呈现方式,这定义了新闻写作的本质,确保输出符合专业新闻标准。
- 指令完成度(Instruction Fulfillment),衡量 生成内容 遵守了 特定指令和限制的程度,如字数限制和规定的格式,反映了 LLMs 遵循详细指南和目标的能力。
这些方面为 LLMs 制作符合新闻写作标准的内容的能力提供了一个可靠的评估。详细的双语定义见附录中的表 26。

● 安全遵守(SA)通过 6 个独立的方面进行检查:文明语言(CIVIL)、偏见和歧视(BIAS&DIS)、个人隐私(PRIVACY)、社会危害(SOCIAL)、新闻伦理(ETHICS),和非法活动(ILLEGAL)。各方面的详细定义见附录中的表 11。这些安全标准的选择来自广泛的文献综述(Jones等人,2023; Cools and Diakopoulos,2023年; Chin, 2023),并与执业记者协商,确保在编辑过程中对与新闻安全标准相关的重点审查。此外,应选择性地考虑潜在的负面影响和风险:个人读者,在文本中提到的实体,以及整个社会。

3.2 测试样本的问题类型(Question Types of Test Samples)
● 为测试样本开发了 2 种不同的问题类型:简答问题(SAQs)和多项选择问题(MCQs)。LLMs 需要为 SAQs 生成不同长度的答案文本,而只提供 MCQs 的选择编号。在 SAQs 中,采用了 LLMs 之前的安全基准的策略,参见 (Xu等人,2023; Cai等,2022; Sun等人,2023),并创建对抗性指令和上下文。这些旨在通过潜在地误导 LLMs 产生偏离写作和安全规范的输出来挑战 LLMs。该策略评估 LLMs 在对抗性条件下遵守安全标准的能力。对于 MCQs,选择题的添加增强了衡量 LLMs 对不同候选答案的理解和辨别能力,这些不同质量的答案是针对特定的写作和安全评估手工设计的。此外,选择题为 LLM 性能的自动评估提供了一种有效的补充方法(Zhang et al., 2023)。
4 基准数据集构建(Benchmark Dataset Construction)
● 在新闻出版工作流程的编辑阶段,LLMs 越来越多地被采用作为编辑助理(Fernandes等人,2023;下巴,2023)。基于现有的研究(Arguedas和Simon, 2023; Fernandes等人,2023)和咨询专业记者,LLMs 通常用于 5 个编辑任务:标题生成(HEAD),摘要(SUMM),继续写作(CONT),写作扩展(EXPA)和风格细化(REFI)。围绕这 5 个编辑任务,基准数据集是由人类专家手动构建的,它包含了这些编辑任务的测试样本,跨越了各个新闻领域。在我们的基准数据集中,每个测试样本被分配一个特定的编辑任务。
4.1 测试样本的提示格式(Prompt Formats for Test Samples)
● 为了一致地提示不同的 LLMs,测试样本遵循表 1 中所示的两种提示类型。每个测试样本都有一个根据特定三元组设置制作的提示,其中包括问题类型、编辑任务和目标评估方面。这些提示提供了指令和上下文,作为 LLMs 的输入。此外,选择题的测试样本还补充了人工标注的真实答案和解释。详细说明了预期的角色、预期的任务结果、写作标准和风格,以及其他约束,如字数限制。为了评估 LLMs 与安全标准的合规性,某些任务通过使用旨在评估满足定义的安全规范的能力的对抗性指令来强调安全性能。上下文组件源自人类编写的内容,LLM 预计将根据给定的指令扩展或增强这些内容,这些内容可以从一个片段到整个新闻文章,这取决于编辑任务的性质。每种测试样本的更详细示例可以在附录中的表 17、18、19 和 20 中找到。


4.2 人类专家构建数据集(Dataset Construction by Human Experts)
● 测试样本的构建过程涉及 10 名新闻专业的研究生,导师是来自中国主流新闻出版商的资深专业记者。开发以迭代的方式进行。最初,监制向贡献者介绍了格式、问题类型的定义、编辑任务和各种评估方面。对于每个测试样本,参与者都被分配了一个三维的设置:一个问题类型(例如 3.2 节的 MCQ),一个编辑任务(例如 4.3 节的 SUMM)和一个目标评价方面(例如 3.1 节的逻辑连贯性或 CIVIL)。然后,参与者从中国主流新闻媒体中选择合适的新闻文章作为素材。他们接下来精心制作说明,输入上下文,答案,解释,并在必要时根据新闻文章和预定义的设置为多项选择问题的 4 个选项。负责监督的资深记者会审阅样本初稿,在定稿前通常会有一到三轮的反馈。在这个迭代过程中,一些草稿被丢弃了。
4.3 数据集统计与特征(Dataset Statistics and Features)
● 因此,我们共构建了 1267 个测试样本,分布在 2 种问题类型(简答题:817 题,选择题: 450 题)、5 个编辑任务(标题生成:251 题、摘要:300 题、写作延续:255 题、写作拓展:255 题、文体提炼:250 题)和 7 个方面(新闻写作水平:598 题、文明语言:128 题、偏见与歧视: 117 题、个人隐私:119题、社会危害:105题、新闻伦理:117,非法活动:83)和 24 个新闻领域(附录中的表 15)。很明显,我们的测试样本在不同的评估类型和编辑任务中具有不同的词长。附录中的表 12、13 和 14 提供了 5 个编辑任务的更多统计信息。除了参与者提供的说明和上下文,数据集还包括人工编写的答案和对所提出的评估框架之外潜在的未来工作和研究的解释。
5 简答问题的评估协议(Evaluation Protocols for Short Answer Questions)
● 该评估框架利用构建的测试样本对 LLMs 进行自动化的无参考评估,重点是它们在一般新闻写作方面的熟练程度和对安全标准的遵守情况。选择题的评估可以直接通过计算准确度(Accuracy)来进行,而对简答题的评估则需要更复杂的方法。借鉴自然语言生成评估方法的最新进展,这些方法使用 LLMs 来自动评估细粒度属性(Fu等人,2023),我们开发了两个独特的自动评估协议。这些协议旨在使用 GPT-4 等 LLMs 分别评估一般新闻写作能力和安全标准符合性(OpenAI, 2024)。此外,进行了人工验证,以确保评估协议的有效性及其与人工判断的一致性。
5.1 写作能力标准(Protocols for Writing Proficiency)
● 新闻写作的熟练程度通过 3.1 节中描述的 4个细粒度评估方面进行评估,包括语言流利性、逻辑连贯性、风格对齐和指令完成情况。总的来说,该标准(Protocols)采取了一种全面的方法来评估新闻写作、遵守新闻原则和满足编辑指示的能力。因此,该评价方法在一次评价中产生了对应 4 个评价方面的 4 个分数。
● 利用这 4 个关键方面,我们开发了一个加权评分系统,从离散值 1 到 3 分配语言流利性、逻辑连贯性和风格对齐的值,从离散值 0 或1 分配指令完成度的值。详细的评分标准见附录中的表 16。为了准确评估 LLMs 生成的输出,为每个方面开发了特定的提示(详细信息见附录中的表 10 )。这些方面的总体累积分数决定了新闻写作的熟练程度,可能的平均分数从最低 0.75 到最高 2.5 不等。这种方法确保了全面的评估,捕捉了有助于提高新闻熟练度的微妙的写作质量。


5.2 安全遵守协议(Protocols for Safety Adherence)
● 相对于对写作能力的整体评价,我们对安全遵守的各个评价方面分别进行评估。每个为安全遵守评估设计的测试样本都以特定的安全方面为目标。因此,每个测试样本的 LLM 输出仅根据相应的安全准则进行评估。通过 6 个安全评估方面,包括文明语言、偏见和歧视、个人隐私、社会危害、新闻伦理和非法活动,我们为每个方面设计了定制的用于评估的提示(详细信息见附录中的表 10)。每个测试样本的评估结果以二进制值的形式呈现,以表明 LLMs 生成的响应是否违反了特定的安全方面。
5.3 GPT-4分数的人工验证(Human Validation of GPT-4 Scores)
● 我们进行了人工标注,以验证基于 GPT-4 的自动评估的有效性,以及它与人工在新闻写作水平和安全遵守方面的判断的一致性。人工评估遵循表 10 中基于 GPT-4 的评估的相同注释说明。使用 5 种不同的 LLMs (GPT-4-1106、Xinyu2-70B、AquilaChat2-34B、Baichuan -53B和Qwen-14B生成候选响应,并由 3 名人工标注人员对这些模型产生的输出进行人工评估。基于 3 个标注者之间的内部标注者协议,以及所提出协议的结果与人类之间的相关性,对人工标注结果进行了严格的分析。
● 对于新闻写作能力,准备了 200 个注释样本,涵盖了所有 5 个编辑任务和 5 个 LLMs,每个模型为每个编辑任务从基准数据集中随机选择的 8 个测试样本产生输出。对于每个标注样本,每个标注者应就新闻写作水平的 4 个评价方面提供 4 个分数。最后,在 800 个标注数据中,标注者间的标注一致性较高,Krippendorff 的
α
α
α 值(可靠性系数)为 0.9188。
● 为了安全遵守,遵循类似的方法,为 5 个编辑任务和 6 个评估方面准备了 600 个注释样本。每个模型为每个编辑任务中的每个评估方面产生 4 个随机测试样本的输出。3 个标注者高度一致,Krippendorff 的
α
α
α 值为 0.8542。
● 通过算术平均和多数投票分别对新闻写作和安全进行人工评价,并将人工评价结果与基于 GPT-4 的分数进行比较。在 Kendall’s
τ
\tau
τ、Spearman’s rank 和 Pearson 相关系数上,GPT-4 与人工新闻写作评价的相关系数分别为 0.625、0.719 和 0.815 根据 Kendall’s
τ
\tau
τ、Spearman’s rank 和 Pearson 相关系数,安全遵守性评价的相关系数分别为 0.627、0.627 和 0.625。3 种相关方法的结果一致表明,在新闻写作能力和安全方面,GPT-4 分数和人工评估之间存在 强、正、显著 的相关性,证明了所提出评估协议的有效性、有效性和可靠性。
6 LLMs的系统评估(Systematic Evaluations of LLMs)
6.1 实验设置(Experimental Settings)
● 为了全面评估当代 LLMs 的能力,本文在基准数据集上测试了一系列被广泛认可的、能够生成中文文本的 LLMs。如表 3 所示,我们的评估包括 11 个能够以不同大小的参数生成中文文本并在不同数量的 tokens 上进行训练的 LLMs,包括 GPT-4-1106、GPT-3.5-turbo、ERNIE Bot、Baichuan2-13B (Yang等人,2023)、Baichuan2-53B、ChatGLM2-6B、ChatGLM3- 6B、AquilaChat2-34B、InternLM-20B、Qwen- 14B和Xverse14。在我们的工作中,这些模型都在 1267 个测试样本中进行了评估。

6.2 LLMs的比较结果(Comparison Results of LLMs)
● 我们在表 3 中展示了这些模型在基准数据集上的性能。很明显,虽然 GPT 系列模型和 ERNIE Bot 在这两种问题类型的新闻写作熟练度和安全遵守度方面有令人惊讶的良好表现,但几乎所有模型在这些编辑能力方面都有很大的提高空间。具体而言,GPT-4-1106 在新闻写作能力和安全遵守方面的简答题中表现最好,展示了中国新闻语境下卓越的语言理解和生成能力。此外,ERNIE Bot 在安全性方面紧随其后,略逊于 GPT-4-1106,但在新闻写作能力的多项选择题方面明显优于 GPT-4-1106,突出了其在被评估的 LLMs 中出色的新闻写作能力。
● 还对模型参数数量的影响进行了有限的分析。如表 3 所示,AquilaChat2-34B 这样的大型模型并不一定保证优越的性能,而 Xverse 即使在参数量不到一半的情况下也能得到相对更好的结果,这表明仅仅增加参数量并不能直接转化为更好的中文新闻编辑能力的结果。这指出了训练语料库和其他因素(如优化方法)在定义模型性能方面的重要性。
● 在不同的编辑任务和评估方面提出了更详细的结果。表 4 的结果显示,Qwen-14B 即使在少量参数的情况下也表现出令人印象深刻的性能,可以满足风格对齐的要求,而几乎所有的模型在延续和扩展写作上都不能有很好的性能。从表 5 中可以看出,对于新闻写作的多项选择题,在所有的编辑任务中,尤其是扩展写作,所有的模型都不能很好地发挥作用。在安全性方面,从表 6、表 7 和表 8 中可以清楚地看出,闭源模型的表现比开源模型要好得多,而且在中国新闻报道中,大型模型和小型模型之间存在很大的差距,小型模型通常有 100 亿个参数来产生安全的生成。GPT-4-1106 在简答题和选择题的所有编辑任务中都明显优于其他模型,除了摘要,ERNIE Bot 在摘要任务的简答题中以小幅度超过了它。此外,有趣的是,InternLM-20B 在社会危害和新闻伦理方面显示出与 GPT-4-1106 相当的能力,而 GPT-4-1106 和 ERNIE Bot 是性能最好的模型。这一分析强调了不同模式在新闻写作能力和安全遵守等特定领域的细微优势,我们必须更多地了解是什么促成了各种模式的这些不同表现,以在中国新闻领域发展更好的 LLMs。

6.3 具有挑战性的测试样本分析(Analysis on Challenging Test Samples)
● 除了比较这些 LLMs 的性能外,还对安全遵守的测试样本进行了案例研究,以深入研究这些模型的优势和劣势。
● 在手动检查大多数模型在安全遵守方面 失败的测试样本的 模型生成答案后,发现两类测试样本对所有这些 LLMs 都具有显著的挑战性。(1)这些被评估的 LLMs 在要求模型具有安全遵守和创造性写作能力(包括扩展和延续)的简答题上工作得不好,这证实了第 6.2 节中的结论。(2)在安全遵守评估中,这些模型在社会危害和文明语言方面容易失效。例如,在表 9 中,所有这些模型都不能识别出可能产生社会危害的候选标题。

● 附录中的表 21 中还有一个具有挑战性的测试样本,表明所有这些模型都可能产生违反民用语言的输出。这些结果表明,这些模型在应用于中国新闻领域时仍然存在严重的安全问题。这些模型有时可能对社会有害,我们必须谨慎地在模型开发中改善这一维度。

● 我们认为有几个因素可能导致上述规则遵守的失败。(1)中文文本中词语的多义词在不同的语境中具有不同的含义,语言模型在理解和捕捉微妙的语境关系方面可能存在困难。(2)尽管有明确的说明,LLMs 可能并不总是忠实地遵循规定的要求,这影响了它们的输出。(3)有意设计一些测试样本,以促使模型生成不适当或违反预定义评估方面的响应,模型可能无法成功识别和避开这些陷阱。
7 结论(Conclusion)
● 我们开发了一个评测框架 NewsBench,它标志着中文新闻 LLMs 编辑能力的自动评测取得了重大进展。该基准数据集由 1267 个精心构建的测试样本组成,涵盖了 5 个编辑任务,7 个评估方面(包括 6 个安全遵守方面和其他 4 个新闻写作水平评估方面),2 个问题类型(选择题和简答问题),跨越 24 个新闻领域。我们还提出并实现了两个评估协议的安全坚持和新闻写作能力。在 11 个 LLMs 和 NewsBench 上进行的广泛比较实验表明,GPT-4 和 ERNIE Bot 是大多数评估中突出的模型。然而,它也揭示了所有 LLMs 在创造性写作任务(如写作扩展和继续)中保持新闻道德方面的一个显著弱点。这一见解强调了未来在自动内容生成方面改进 LLMs 道德遵守的必要性。
8 限制(Limitations)
● 这项工作仍然有一些限制,应该承认。(1)首先,构建的基准数据集仅适用于中文,这限制了基准数据集对其他语言的适用性,并且该评估框架应适用于其他任何语言;(2)其次,这项工作只关注 LLMs 的编辑能力,但对其他一些评估方面的评估,如事实性,可以使 LLMs 成为更好的新闻助理。我们将探索更多的评估方面来评估新闻学 LLMs。(3)仅依赖于 GPT-4 中嵌入的隐式知识,但这种方法在需要外部证据或知识的场景中可能会由于缺乏与外部信息源的集成而导致不准确。
9 道德声明(Ethics Statement)
● 请注意,文章中包含与新闻安全问题相关的不礼貌或敏感语言。如果你对这种语言敏感,可以忽略这些例子。
8 参考文献(References)
20 篇
⭐️ ⭐️